在 kubernetes 环境下如何优雅扩缩容 Pulsar
背景
在整个大环境的降本增效的熏陶下,我们也不得不做好应对方案。
根据对线上流量、存储以及系统资源的占用,发现我们的 Pulsar 集群有许多的冗余,所以考虑进行缩容从而减少资源浪费,最终也能省一些费用。
不过在缩容之前很有必要先聊聊扩容,Pulsar 一开始就是存算分离的架构(更多关于 Pulsar 架构的内容本文不做过多介绍,感兴趣的可以自行搜索),天然就非常适合 kubernetes 环境,也可以利用 kubernetes 的能力进行快速扩容。
扩容
Pulsar 的扩容相对比较简单,在 kubernetes 环境下只需要修改副本即可。
Broker
当我们的 broker 层出现瓶颈时(比如 CPU、内存负载较高、GC 频繁时)可以考虑扩容。
计算层都扩容了,也需要根据流量计算下存储层是否够用。
如果我们使用的是 helm 安装的 Pulsar 集群,那只需要修改对于的副本数即可。
broker:
configuration
component: broker
replicaCount: 3->5
当我们将副本数从 3 增加到 5 之后 kubernetes 会自动拉起新增的两个 Pod,之后我们啥也不需要做了。
Pulsar 的负载均衡器会自动感知到新增两个 broker 的加入,从而帮我们将一些负载高的节点的流量迁移到新增的节点中。
Bookkeeper
在介绍 bookkeeper 扩容前先简单介绍些 Bookkeeper 的一些基本概念。
- Ensemble size (E):当前 Bookkeeper 集群的节点数量
- Write quorum size (QW):一条消息需要写入到几个 Bookkeeper 节点中
- ACK quorum size (QA):有多少个 Bookkeeper 节点 ACK 之后表示写入成功
对应到我们在 broker.conf 中的配置如下:
managedLedgerDefaultEnsembleSize: "2"
managedLedgerDefaultWriteQuorum: "2"
managedLedgerDefaultAckQuorum: "2"
这个三个参数表示一条消息需要同时写入两个 Bookkeeper 节点,同时都返回 ACK 之后才能表示当前消息写入成功。
从这个配置也可以看出,Bookkeeper 是多副本写入模型,适当的降低 QW 和 QA 的数量可以提高写入吞吐率。
大部分场景下 Bookkeeper 有三个节点然后 E/QW/QA 都配置为 2 就可以满足消息多副本写入了。
多副本可以保证当某个节点宕机后,这个节点的消息在其他节点依然有存放,消息读取不会出现问题。
那什么情况下需要扩容 Bookkeeper 了,当然如果单个 Bookkeeper 的负载较高也是可以扩容的。
但我们当时扩容 Bookkeeper 的场景是想利用 Pulsar 的资源隔离功能。
因为有部分业务的消息量明显比高于其他的 topic,这样会导致某个 Broker 的负载较高,同时也可能影响到其他正常的 topic。
最好的方式就将这部分数据用单独的 broker 和 Bookkeeper 来承载,从而实现硬件资源的隔离。
这样的需求如果使用其他消息队列往往不太好实现,到后来可能就会部署多个集群来实现隔离,但这样也会增加运维的复杂度。
好在 Pulsar 天然就支持资源隔离,只需要一个集群就可以实现不同 namespace 的流量隔离。
此时就可以额外扩容几个 Bookkeeper 节点用于特定的 namespace 使用。

从上图可以看到:我们可以将 broker 和 Bookkeeper 分别进行分组,然后再配置对应的 namespace,这样就能实现资源隔离了。
更多关于资源隔离的细节本文就不过多赘述了。
铺垫了这么多,其实 Bookkeeper 的扩容也蛮简单的:
bookkeeper:
component: bookie
metadata:
resources:
# requests:
# memory: 4Gi
# cpu: 2
replicaCount: 3->5
和 broker 扩容类似,提高副本数量后,Pulsar 的元数据中心会感知到新的 Bookkeeper 节点加入,从而更新 broker 中的节点数据,这样就会根据我们配置的隔离策略分配流量。
缩容
其实本文的重点在于缩容,特别是 Bookkeeper 的缩容,这部分内容我在互联网上很少看到有人提及。
Broker
Broker 的缩容相对简单,因为存算分离的特点:broker 作为计算层是无状态的,并不承载任何的数据。
其实是承载数据的,只是 Pulsar 会自动迁移数据,从而体感上觉得是无状态的。
只是当一个 broker 下线后,它上面所绑定的 topic 会自动转移到其他在线的 broker 中。
这个过程会导致连接了这个 broker 的 client 触发重连,从而短暂的影响业务。
正因为 broker 的下线会导致 topic 的归属发生转移,所以在下线前最好是先通过监控面板观察需要下线的 broker topic 是否过多,如果过多则可以先手动 unload 一些数据,尽量避免一次性大批量的数据转移。
观察各个broker 的 topic 数量
Bookkeeper
而 Bookkeeper 的缩容则没那么容易了,由于它是作为存储层,本身是有状态的,下线后节点上存储的数据是需要迁移到其他的 Bookkeeper 节点中的。
不然就无法满足之前提到的 Write quorum size (QW) 要求;因此缩容还有一个潜在条件需要满足:
缩容后的 Bookkeeper 节点数量需要大于broker 中的配置:
managedLedgerDefaultEnsembleSize: "2"
managedLedgerDefaultWriteQuorum: "2"
managedLedgerDefaultAckQuorum: "2"
不然写入会失败,整个集群将变得不可用。
Pulsar 提供了两种 Bookkeeper 的下线方案:
不需要迁移数据
其实两种方案主要区别在于是否需要迁移数据,第一种比较简单,就是不迁移数据的方案。
首先需要将 Bookkeeper 设置为 read-only 状态,此时该节点将不会接受写请求,直到这个 Bookkeeper 上的数据全部过期被回收后,我们就可以手动下线该节点。
使用 forceReadOnlyBookie=true 可以强制将 Bookkeeper 设置为只读。
但这个方案存在几个问题:
- 下线时间不确定,如果该
Bookkeeper上存储的数据生命周期较长,则无法预估什么时候可以下线该节点。 - 该配置修改后需要重启才能生效,在 kubernetes 环境中这些配置都是写在了 configmap 中,一旦刷新后所有节点都会读取到该配置,无法针对某一个节点生效;所以可能会出现将不该下线的节点设置为了只读状态。
但该方案的好处是不需要迁移数据,人工介入的流程少,同样也就减少了出错的可能。
比较适合于用虚拟机部署的集群。
迁移数据
第二种就是需要迁移数据的方案,更适用于 kubernetes 环境。
迁移原理
先来看看迁移的原理:
- 当 bookkeeper 停机后,AutoRecovery Auditor 会检测到 zookeeper 节点
/ledger/available发生变化,将下线节点的 ledger 信息写入到 zookeeper 的/ledgers/underreplicated节点中。 - AutoRecovery ReplicationWorker 会检测
/ledgers/underreplicated节点信息,然后轮训这些 ledger 信息从其他在线的 BK 中复制数据到没有该数据的节点,保证 QW 数量不变。- 每复制一条数据后都会删除
/ledgers/underreplicated节点信息。 - 所有
/ledgers/underreplicated被删除后说明迁移任务完成。
- 每复制一条数据后都会删除
- 执行
bin/bookkeeper shell decommissionbookie下线命令:- 会等待
/ledgers/underreplicated全部删除 - 然后删除 zookeeper 中的元数据
- 元数据删除后 bookkeeper 才是真正下线成功,此时 broker 才会感知到 Bookkeeper 下线。
- 会等待
AutoRecovery 是 Bookkeeper 提供的一个自动恢复程序,他会在后台检测是否有数据需要迁移。
简单来说就是当某个Bookkeeper 停机后,它上面所存储的 ledgerID 会被写入到元数据中心,此时会有一个单独的线程来扫描这些需要迁移的数据,最终将这些数据写入到其他在线的 Bookkeeper 节点。
Bookkeeper 中的一些关键代码:


下线步骤
下面来看具体的下线流程:
- 副本数-1
bin/bookkeeper shell listunderreplicated检测有多少 ledger 需要被迁移
- 执行远程下线元数据
nohup bin/bookkeeper shell decommissionbookie -bookieid bkid:3181 > bk.log 2>&1 &- 这个命令会一直后台运行等待数据迁移完成,比较耗时
- 查看下线节点是否已被剔除
bin/bookkeeper shell listbookies -a
- 循环第一步
第一步是检测一些现在有多少数据需要迁移:
bin/bookkeeper shell listunderreplicated 命令查看需要被迁移的 ledger 数据也是来自于 /ledgers/underreplicated节点

正常情况下是 0
第二步的命令会等待数据迁移完成后从 zookeeper 中删除节点信息,这个进程退出后表示下线成功。
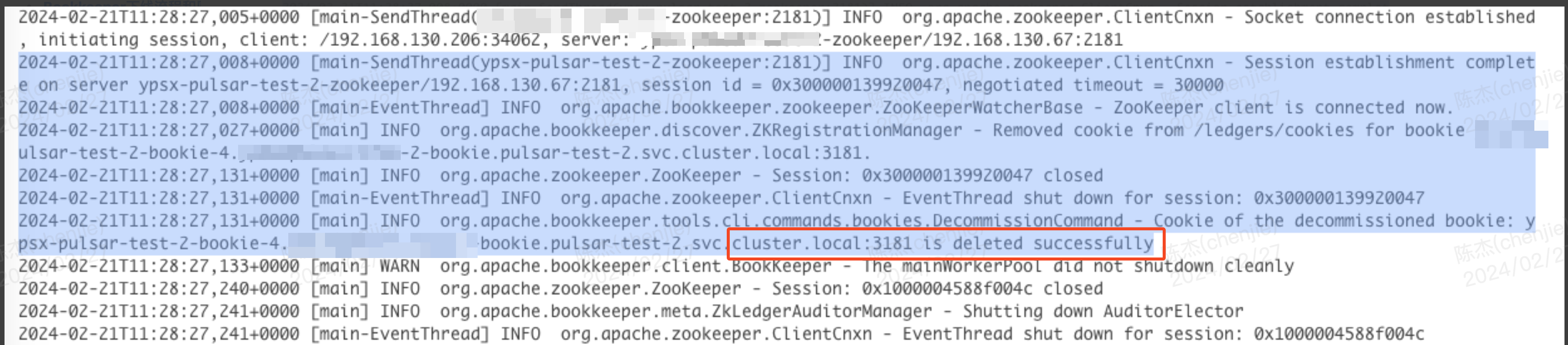
这个命令最好是后台执行,并输出日志到专门的文件,因为周期较长,很有可能终端会话已经超时了。
我们登录 zookeeper 可以看到需要迁移的 ledger 数据:
bin/pulsar zookeeper-shell -server pulsar-zookeeper:2181
get /ledgers/underreplication/ledgers/0000/0000/0000/0002/urL0000000002
replica: "pulsar-test-2-bookie-0.pulsar-test-2-bookie.pulsar-test-2.svc.cluster.local:3181"
ctime: 1708507296519
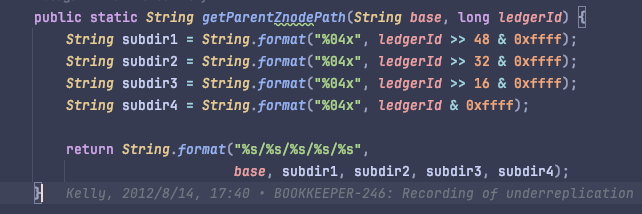
underreplication 的节点路径中存放了 ledgerId,通过 ledgerId 计算路径:

注意事项
下线过程中我们可以查看 nohup bin/bookkeeper shell decommissionbookie -bookieid bkid:3181 > bk.log 2>&1 &这个命令写入的日志来确认迁移的进度,日志中会打印当前还有多少数量的 ledger 没有迁移。
同时需要观察 zookeeper、Bookkeeper 的资源占用情况。
因为迁移过程中写入大量数据到 zookeeper 节点,同时迁移数时也会有大量流量写入 Bookkeeper。
不要让迁移过程影响到了正常的业务使用。
根据我的迁移经验来看,通常 2w 的ledger 数据需要 2~3 小时不等的时间,具体情况还得根据你的集群来确认。
回滚方案
当然万一迁移比较耗时,或者影响了业务使用,所以还是要有一个回滚方案:
这里有一个大的前提:
只要 BK 节点元数据、PVC(也就是磁盘中的数据) 没有被删除就可以进行回滚。
所以只要上述的 decommissionbookie 命令没有完全执行完毕,我们就可以手动 kill 该进程,然后恢复副本数据。
这样恢复的 Bookkeeper 节点依然可以提供服务,同时数据也还存在;只是浪费了一些 autorecovery 的资源。
最后当 bookkeeper 成功下线后,我们需要删除 PVC,不然如果今后需要扩容的时候是无法启动 bookkeeper 的,因为在启动过程中会判断挂载的磁盘是否有数据。
总结
总的来说 Pulsar 的扩缩容还是非常简单的,只是对于有状态节点的数据迁移稍微复杂一些,但只要跟着流程走就不会有什么问题。
参考链接:
- https://pulsar.apache.org/docs/next/administration-isolation/
- https://bookkeeper.apache.org/docs/4.13.0/admin/decomission
- https://bookkeeper.apache.org/docs/4.13.0/admin/autorecovery
Blog #Pulsar
在 kubernetes 环境下如何优雅扩缩容 Pulsar的更多相关文章
- Kubernetes的垂直和水平扩缩容的性能评估
Kubernetes的垂直和水平扩缩容的性能评估 译自:Performance evaluation of the autoscaling strategies vertical and horizo ...
- 从零入门 Serverless | Serverless Kubernetes 应用部署及扩缩容
作者 | 邓青琳(轻零) 阿里云技术专家 导读:本文分为三个部分,首先给大家演示 Serverless Kubernetes 集群的创建和业务应用的部署,其次介绍 Serverless Kuberne ...
- Airbnb的动态kubernetes集群扩缩容
Airbnb的动态kubernetes集群扩缩容 本文介绍了Airbnb的集群扩缩容的演化历史,以及当前是如何通过Cluster Autoscaler 实现自定义扩展器的.最重要的经验就是Airbnb ...
- Kubernetes 监控:Prometheus Adpater =》自定义指标扩缩容
使用 Kubernetes 进行容器编排的主要优点之一是,它可以非常轻松地对我们的应用程序进行水平扩展.Pod 水平自动缩放(HPA)可以根据 CPU 和内存使用量来扩展应用,前面讲解的 HPA 章节 ...
- Kubernetes环境下的各种调试方法
作者:Jack47 转载请保留作者和原文出处 欢迎关注我的微信公众账号程序员杰克,两边的文章会同步,也可以添加我的RSS订阅源. 本文介绍在Kubernetes环境下的调试方法,希望对读者有用.如果关 ...
- Kubernetes环境下如何运行Coherence缓存集群
Oracle官方出了一个如何在Docker环境下运行Coherence的技术文档,大家可以参考: https://github.com/oracle/docker-images/tree/master ...
- 如何根据不同业务场景调节 HPA 扩缩容灵敏度
背景 在 K8s 1.18 之前,HPA 扩容是无法调整灵敏度的: 对于缩容,由 kube-controller-manager 的 --horizontal-pod-autoscaler-downs ...
- 通过Dapr实现一个简单的基于.net的微服务电商系统(十一)——一步一步教你如何撸Dapr之自动扩/缩容
上一篇我们讲到了dapr提供的bindings,通过绑定可以让我们的程序轻装上阵,在极端情况下几乎不需要集成任何sdk,仅需要通过httpclient+text.json即可完成对外部组件的调用,这样 ...
- 三十三、HPA实现自动扩缩容
通过HPA实现业务应用的动态扩缩容 HPA控制器介绍 当系统资源过高的时候,我们可以使用如下命令来实现 Pod 的扩缩容功能 $ kubectl -n luffy scale deployment m ...
- Knative 基本功能深入剖析:Knative Serving 自动扩缩容 Autoscaler
Knative Serving 默认情况下,提供了开箱即用的快速.基于请求的自动扩缩容功能 - Knative Pod Autoscaler(KPA).下面带你体验如何在 Knative 中玩转 Au ...
随机推荐
- 为什么华为今年疯狂招od?
不知道的大家有没有发现 这两年市场不好公司用人需求紧缩 唯有华子疯狂招人 很多人都听过华为OD 但是具体是什么还是有很多人疑惑 总结以下三个部分: 1.为啥疯狂招od而不是之前的纯"外包&q ...
- 《深入理解Java虚拟机》(五) JVM调优案例
目录 问题 排查问题经过了如下的过程: 排除是否数据库卡顿造成 任务管理器 与客户沟通 至此开始通过JVM排查问题: JVM参数介绍 第一次Full GC 第二次Full GC截图 第三次Full G ...
- TCP/IP的确认号,序列号和超时重传的学习笔记
一:确认应答和序列号 在tcp中,发送端的数据到达主机时,接收端会返回一个已收到的通知.这个消息叫做确认应答(ACK). 当发送端发送数据后,会等待对端的确认应答.如果有确认应答,说明数据已经成功到达 ...
- 混合类Mixins介绍
介绍 混合类是封装了一些通用行为的基类,旨在重用代码.通常,混合类本身并没有什么用,仅扩展这种类也行不通 因为在大多数情况下,它都依赖于其它类中定义的方法和属性.通过多继承,可将混合类与其它类一起使用 ...
- SQL Server 连接数据库报错 (ObjectExplorer)
报错信息 无法访问数据库 ReportServer. (ObjectExplorer) 具体错误信息: 程序位置: 在 Microsoft.SqlServer.Management.UI.VSInte ...
- 任务系统之API子任务
日常运维工作中有许多的任务要执行,例如项目发布/数据备份/定时巡检/证书更新/漏洞修复等等,大部分的任务都会有多个步骤共同完成,例如一个发布任务会有拉代码.编译.分发.通知等等步骤,而不同的任务可能还 ...
- 详解SSL证书系列(3)如何选择SSL证书
我们知道了在网站部署 SSL 证书后,不管是对网站本身还是对网站的用户都能够带来许多好处.那么随着 HTTPS的普及,市面上也出现了各种不同的 SSL 证书.并且由于 SSL 证书的多样性,很多人对于 ...
- 【Azure Developer】PHP网站使用AAD授权登录的参考示例
问题描述 如果有个PHP网站,需要使用AAD授权登录,有没有PHP代码实例 可供参考呢? 参考代码 参考一篇博文(Single sign-on with Azure AD in PHP),学习使用SS ...
- 动态代码框架发布-CZGL.Roslyn
CZGL.Roslyn 开源项目位置:https://github.com/whuanle/CZGL.CodeAnalysis 基于 Roslyn 技术的 C# 动态代码构建器以及编译器,开发者可以使 ...
- 利用微软官方API实现Office文档的在线预览功能
随着互联网时代的飞速发展,越来越多的工作开始依赖于云端服务,我们的办公方式也逐渐发生了翻天覆地的变化.在这种背景下,急需一种无需本地安装Office软件,就能快速查看和共享Word.PowerPoin ...