神经网络入门篇:详解多样本向量化(Vectorizing across multiple examples)
多样本向量化
- 与上篇博客相联系的来理解
逻辑回归是将各个训练样本组合成矩阵,对矩阵的各列进行计算。神经网络是通过对逻辑回归中的等式简单的变形,让神经网络计算出输出值。这种计算是所有的训练样本同时进行的,以下是实现它具体的步骤:
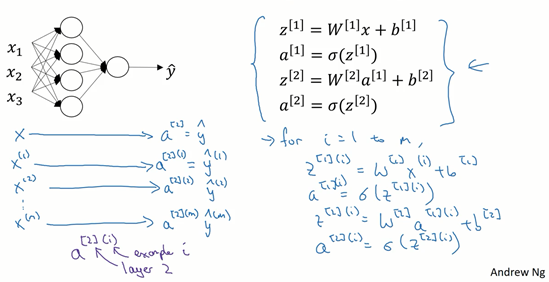
图1.4.1
上篇博客中得到的四个等式。它们给出如何计算出\(z^{[1]}\),\(a^{[1]}\),\(z^{[2]}\),\(a^{[2]}\)。
对于一个给定的输入特征向量\(X\),这四个等式可以计算出\(\alpha^{[2]}\)等于\(\hat{y}\)。这是针对于单一的训练样本。如果有\(m\)个训练样本,那么就需要重复这个过程。
用第一个训练样本\(x^{[1]}\)来计算出预测值\(\hat{y}^{[1]}\),就是第一个训练样本上得出的结果。
然后,用\(x^{[2]}\)来计算出预测值\(\hat{y}^{[2]}\),循环往复,直至用\(x^{[m]}\)计算出\(\hat{y}^{[m]}\)。
用激活函数表示法,如上图左下所示,它写成\(a^{[2](1)}\)、\(a^{[2](2)}\)和\(a^{[2](m)}\)。
【注】:\(a^{[2](i)}\),\((i)\)是指第\(i\)个训练样本而\([2]\)是指第二层。
如果有一个非向量化形式的实现,而且要计算出它的预测值,对于所有训练样本,需要让\(i\)从1到\(m\)实现这四个等式:
\(z^{[1](i)}=W^{[1](i)}x^{(i)}+b^{[1](i)}\)
\(a^{[1](i)}=\sigma(z^{[1](i)})\)
\(z^{[2](i)}=W^{[2](i)}a^{[1](i)}+b^{[2](i)}\)
\(a^{[2](i)}=\sigma(z^{[2](i)})\)
对于上面的这个方程中的\(^{(i)}\),是所有依赖于训练样本的变量,即将\((i)\)添加到\(x\),\(z\)和\(a\)。如果想计算\(m\)个训练样本上的所有输出,就应该向量化整个计算,以简化这列。
这里需要使用很多线性代数的内容,重要的是能够正确地实现这一点,尤其是在深度学习的错误中。实际上我认真地选择了运算符号,这些符号只是针对于我所写神经网络系列的博客的,并且能使这些向量化容易一些。
所以,希望通过这个细节可以更快地正确实现这些算法。接下来讲讲如何向量化这些:
公式1.12:
\left[
\begin{array}{c}
\vdots & \vdots & \vdots & \vdots\\
x^{(1)} & x^{(2)} & \cdots & x^{(m)}\\
\vdots & \vdots & \vdots & \vdots\\
\end{array}
\right]
\]
公式1.13:
\left[
\begin{array}{c}
\vdots & \vdots & \vdots & \vdots\\
z^{[1](1)} & z^{[1](2)} & \cdots & z^{[1](m)}\\
\vdots & \vdots & \vdots & \vdots\\
\end{array}
\right]
\]
公式1.14:
\left[
\begin{array}{c}
\vdots & \vdots & \vdots & \vdots\\
\alpha^{[1](1)} & \alpha^{[1](2)} & \cdots & \alpha^{[1](m)}\\
\vdots & \vdots & \vdots & \vdots\\
\end{array}
\right]
\]
公式1.15:
\begin{array}{r}
\text{$z^{[1](i)} = W^{[1](i)}x^{(i)} + b^{[1]}$}\\
\text{$\alpha^{[1](i)} = \sigma(z^{[1](i)})$}\\
\text{$z^{[2](i)} = W^{[2](i)}\alpha^{[1](i)} + b^{[2]}$}\\
\text{$\alpha^{[2](i)} = \sigma(z^{[2](i)})$}\\
\end{array}
\right\}
\implies
\begin{cases}
\text{$A^{[1]} = \sigma(z^{[1]})$}\\
\text{$z^{[2]} = W^{[2]}A^{[1]} + b^{[2]}$}\\
\text{$A^{[2]} = \sigma(z^{[2]})$}\\
\end{cases}
\]
定义矩阵\(X\)等于训练样本,将它们组合成矩阵的各列,形成一个\(n\)维或\(n\)乘以\(m\)维矩阵。接下来计算见公式1.15:
以此类推,从小写的向量\(x\)到这个大写的矩阵\(X\),只是通过组合\(x\)向量在矩阵的各列中。
同理,\(z^{[1](1)}\),\(z^{[1](2)}\)等等都是\(z^{[1](m)}\)的列向量,将所有\(m\)都组合在各列中,就的到矩阵\(Z^{[1]}\)。
同理,\(a^{[1](1)}\),\(a^{[1](2)}\),……,\(a^{[1](m)}\)将其组合在矩阵各列中,如同从向量\(x\)到矩阵\(X\),以及从向量\(z\)到矩阵\(Z\)一样,就能得到矩阵\(A^{[1]}\)。
同样的,对于\(Z^{[2]}\)和\(A^{[2]}\),也是这样得到。
这种符号其中一个作用就是,可以通过训练样本来进行索引。这就是水平索引对应于不同的训练样本的原因,这些训练样本是从左到右扫描训练集而得到的。
在垂直方向,这个垂直索引对应于神经网络中的不同节点。例如,这个节点,该值位于矩阵的最左上角对应于激活单元,它是位于第一个训练样本上的第一个隐藏单元。它的下一个值对应于第二个隐藏单元的激活值。它是位于第一个训练样本上的,以及第一个训练示例中第三个隐藏单元,等等。
当垂直扫描,是索引到隐藏单位的数字。当水平扫描,将从第一个训练示例中从第一个隐藏的单元到第二个训练样本,第三个训练样本……直到节点对应于第一个隐藏单元的激活值,且这个隐藏单元是位于这\(m\)个训练样本中的最终训练样本。
从水平上看,矩阵\(A\)代表了各个训练样本。从竖直上看,矩阵\(A\)的不同的索引对应于不同的隐藏单元。
对于矩阵\(Z,X\)情况也类似,水平方向上,对应于不同的训练样本;竖直方向上,对应不同的输入特征,而这就是神经网络输入层中各个节点。
神经网络上通过在多样本情况下的向量化来使用这些等式。
神经网络入门篇:详解多样本向量化(Vectorizing across multiple examples)的更多相关文章
- PHP函数篇详解十进制、二进制、八进制和十六进制转换函数说明
PHP函数篇详解十进制.二进制.八进制和十六进制转换函数说明 作者: 字体:[增加 减小] 类型:转载 中文字符编码研究系列第一期,PHP函数篇详解十进制.二进制.八进制和十六进制互相转换函数说明 ...
- 走向DBA[MSSQL篇] 详解游标
原文:走向DBA[MSSQL篇] 详解游标 前篇回顾:上一篇虫子介绍了一些不常用的数据过滤方式,本篇详细介绍下游标. 概念 简单点说游标的作用就是存储一个结果集,并根据语法将这个结果集的数据逐条处理. ...
- java 日志体系(三)log4j从入门到详解
java 日志体系(三)log4j从入门到详解 一.Log4j 简介 在应用程序中添加日志记录总的来说基于三个目的: 监视代码中变量的变化情况,周期性的记录到文件中供其他应用进行统计分析工作: 跟踪代 ...
- Scala进阶之路-Scala函数篇详解
Scala进阶之路-Scala函数篇详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.传值调用和传名调用 /* @author :yinzhengjie Blog:http: ...
- (十八)整合Nacos组件,环境搭建和入门案例详解
整合Nacos组件,环境搭建和入门案例详解 1.Nacos基础简介 1.1 关键特性 1.2 专业术语解释 1.3 Nacos生态圈 2.SpringBoot整合Nacos 2.1 新建配置 2.2 ...
- es6入门4--promise详解
可以说每个前端开发者都无法避免解决异步问题,尤其是当处理了某个异步调用A后,又要紧接着处理其它逻辑,而最直观的做法就是通过回调函数(当然事件派发也可以)处理,比如: 请求A(function (请求响 ...
- Django入门基础详解
本次使用django版本2.1.2 安装django 安装最新版本 pip install django 安装指定版本 pip install django==1.10.1 查看本机django版本 ...
- 日志处理(一) log4j 入门和详解(转)
log4j 入门. 详解 转自雪飘寒的文章 1. Log4j 简介 在应用程序中添加日志记录总的来说基于三 个目的: 监视代码中变量的变化情况,周期性的记录到文件中供其他应用进行统计分析工作 ...
- JPA入门案例详解(附源码)
1.新建JavaEE Persistence项目
- 从零开始入门 K8s| 详解 Pod 及容器设计模式
作者|张磊 阿里云容器平台高级技术专家,CNCF 官方大使 一.为什么需要 Pod 容器的基本概念 我们知道 Pod 是 Kubernetes 项目里面一个非常重要的概念,也是非常重要的一个原子调度单 ...
随机推荐
- #Powerbi 1分钟学会利用AI,为powerbi报表进行高端颜色设计
在BI报表的设计中,配色方案往往成为一大难题,一组切合主题.搭配合理的颜色设计往往能为我们的报表,加分不少. 今天,就介绍一个AI配色的网站,利用AI为pbi报表进行配色设计. 一:网站网址 http ...
- 查看UUID
查看硬盘UUID: 1. ls -l /dev/disk/by-uuid 2. blkid /dev/sda5 修改硬盘UUID: 1.新建和改变分区的UUID sudo uuidgen | xarg ...
- QTextEdit的使用
import sys from PyQt5.QtWidgets import QApplication, QWidget, QTextEdit,QVBoxLayout, QPushButton cla ...
- trick : Trygub num
trick大意 我对于这个trick的理解为:支持位运算的高精度 维护一个以 \(b\)为基数的大数 \(N\),并支持以下功能: 给定(可能是负)整数 \(|x|, |y| \leqslant n\ ...
- msvc++工程之vs版本升级及工程目录规范
为什么要升级msvc++工程版本 对msvc++工程进行vs版本升级,一方面是可以使用较新的C++标准及对64位更好的支持. 首先你需要对msvc++ project文件有一定的了解,主要是vcxpr ...
- [Python]队列基础
关于队列 基本的队列是一种先进先出的数据结构. 一般的队列基本操作如下: create:创建空队列 add:将新数据加入队列的末尾.返回新队列. delete:删除队列头部的数据,返回新队列. fro ...
- 【动画进阶】神奇的 3D 磨砂玻璃透视效果
最近,群友分享了一个很有意思的效果: 原效果的网址:frosted-glass.该效果的几个核心点: 毛玻璃磨砂效果 卡片的 3D 旋转跟随效果 整体透明度和磨砂感.以及卡片的 3D 形态会随着用户移 ...
- 浅析三维模型OBJ格式轻量化处理常见问题与处理措施
浅析三维模型OBJ格式轻量化处理常见问题与处理措施 在三维模型OBJ格式轻量化处理过程中,可能会遇到一些问题.以下是一些常见问题以及相应的解决方法: 1.文件大小过大: OBJ格式的三维模型文件通常包 ...
- 文心一言 VS 讯飞星火 VS chatgpt (83)-- 算法导论8.1 4题
四.用go语言,假设现有一个包含n个元素的待排序序列.该序列由 n/k 个子序列组成,每个子序列包含k个元素.一个给定子序列中的每个元素都小于其后继子序列中的所有元素,且大于其前驱子序列中的每个元素. ...
- 拓展kmp的应用
Smiling & Weeping ---- 我与月亮,进行了一次深夜谈话 它与我谈论太阳,而我与它谈论你. 题目链接:P3435 [POI2006] OKR-Periods of Words ...