高并发场景QPS等专业指标揭秘大全与调优实战
高并发场景QPS等专业指标揭秘大全与调优实战
最近经常有小伙伴问及高并发场景下QPS的一些问题,特意结合项目经验和网上技术贴做了一些整理和归纳,供大家参考交流。
一、一直再说高并发,多少QPS才算高并发?
高并发的四个角度
只说并发不提高可用就是耍流氓。可以从四个角度讨论这个问题。
首先是无状态前端机器不足以承载请求流量,需要进行水平扩展,一般QPS是千级。 然后是关系型数据库无法承载读取或写入峰值,需要数据库横向扩展或引入nosql,一般是千到万级。 之后是单机nosql无法承载,需要nosql横向扩展,一般是十万到百万QPS。 最后是难以单纯横向扩展nosql,比如微博就引入多级缓存架构,这种架构一般可以应对百万到千万对nosql的访问QPS。 当然面向用户的接口请求一般到不了这个量级,QPS递增大多是由于读放大造成的压力,单也属于高并发架构考虑的范畴。
PV和QPS
比如微博每天1亿多pv的系统一般也就1500QPS,5000QPS峰值。
比如有人说:
- 2C4G机器单机一般1000QPS。
- 8C8G机器单机可承受7000QPS。
脱离业务讨论技术都是耍流氓
具体多少QPS跟业务强相关,只读接口读缓存,将压力给到缓存单机3000+没问题,写请求1000+也正常,也复杂些可能也就几百+QPS。
所以QPS和业务场景和设计相关性很大,比如可以通过浏览器本地缓存,用缓存做热点数据查询,写事务MQ异步处理等方式提升QPS。
二、QPS高并发性能指标及其计算公式
QPS,每秒查询
QPS:Queries Per Second意思是“每秒查询率”,是一台服务器每秒能够相应的查询次数,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。
互联网中,作为域名系统服务器的机器的性能经常用每秒查询率来衡量。
并发数
并发数是指系统同时能处理的请求数量,这个也是反应了系统的负载能力。
RT,响应时间
响应时间:执行一个请求从开始到最后收到响应数据所花费的总体时间,即从客户端发起请求到收到服务器响应结果的时间。
响应时间RT(Response-time),是一个系统最重要的指标之一,它的数值大小直接反应了系统的快慢。
吞吐量
系统的吞吐量(承压能力)与request对CPU的消耗、外部接口、IO等等紧密关联。单个request 对CPU消耗越高,外部系统接口、IO速度越慢,系统吞吐能力越低,反之越高。
系统吞吐量几个重要参数:QPS(TPS)、并发数、响应时间。
QPS(TPS):(Query Per Second)每秒钟request/事务 数量
并发数: 系统同时处理的request/事务数
响应时间: 一般取平均响应时间
理解了上面三个要素的意义之后,就能推算出它们之间的关系:
QPS(TPS)= 并发数/平均响应时间
并发数 = QPS*平均响应时间
实际举例
我们通过一个实例来把上面几个概念串起来理解。按二八定律来看,如果每天 80% 的访问集中在 20% 的时间里,这 20% 时间就叫做峰值时间。
公式:( 总PV数 * 80% ) / ( 每天秒数 * 20% ) = 峰值时间每秒请求数(QPS)
机器:峰值时间每秒QPS / 单台机器的QPS = 需要的机器
1、每天300w PV 的在单台机器上,这台机器需要多少QPS?
( 3000000 * 0.8 ) / (86400 * 0.2 ) = 139 (QPS)
2、如果一台机器的QPS是58,需要几台机器来支持?
139 / 58 = 3
最佳线程数、QPS、RT
1、单线程QPS公式:QPS=1000ms/RT
对同一个系统而言,支持的线程数越多,QPS越高。假设一个RT是80ms,则可以很容易的计算出QPS,QPS = 1000/80 = 12.5
多线程场景,如果把服务端的线程数提升到2,那么整个系统的QPS则为 2*(1000/80) = 25, 可见QPS随着线程的增加而线性增长,那QPS上不去就加线程呗,听起来很有道理,公司也说的通,但是往往现实并非如此。
2、QPS和RT的真实关系
我们想象的QPS、RT关系如下,
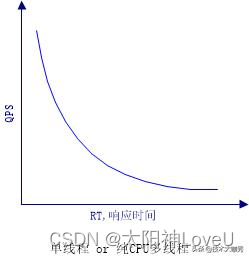
 编辑
编辑
实际的QPS、RT关系如下,
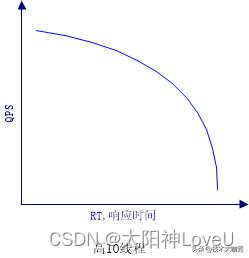
编辑
3、最佳线程数量
刚好消耗完服务器的瓶颈资源的临界线程数,公式如下
最佳线程数量=((线程等待时间+线程cpu时间)/线程cpu时间)* cpu数量
特性:
在达到最佳线程数的时候,线程数量继续递增,则QPS不变,而响应时间变长,持续递增线程数量,则QPS开始下降。
每个系统都有其最佳线程数量,但是不同状态下,最佳线程数量是会变化的。
瓶颈资源可以是CPU,可以是内存,可以是锁资源,IO资源:超过最佳线程数——导致资源的竞争,超过最佳线程数——响应时间递增。
三、一个QPS优化的案例(整理自互联网)
一次简单的Java服务性能优化,实现压测 QPS 翻倍
来源 | https://zhenbianshu.github.io/
背景
前段时间我们的服务遇到了性能瓶颈,由于前期需求太急没有注意这方面的优化,到了要还技术债的时候就非常痛苦了。
在很低的 QPS 压力下服务器 load 就能达到 10-20,CPU 使用率 60% 以上,而且在每次流量峰值时接口都会大量报错,虽然使用了服务熔断框架 Hystrix,但熔断后服务却迟迟不能恢复。每次变更上线更是提心吊胆,担心会成为压死骆驼的最后一根稻草,导致服务雪崩。
在需求终于缓下来后,leader 给我们定下目标,限我们在两周内把服务性能问题彻底解决。近两周的排查和梳理中,发现并解决了多个性能瓶颈,修改了系统熔断方案,最终实现了服务能处理的 QPS 翻倍,能实现在极高 QPS(3-4倍)压力下服务正常熔断,且能在压力降低后迅速恢复正常,以下是部分问题的排查和解决过程。
服务器高CPU、高负载
首先要解决的问题就是服务导致服务器整体负载高、CPU 高的问题。
我们的服务整体可以归纳为从某个存储或远程调用获取到一批数据,然后就对这批数据进行各种花式变换,最后返回。由于数据变换的流程长、操作多,系统 CPU 高一些会正常,但平常情况下就 CPU us 50% 以上,还是有些夸张了。
我们都知道,可以使用 top 命令在服务器上查询系统内各个进程的 CPU 和内存占用情况。可是 JVM 是 Java 应用的领地,想查看 JVM 里各个线程的资源占用情况该用什么工具呢?
jmc 是可以的,但使用它比较麻烦,要进行一系列设置。我们还有另一种选择,就是使用 jtop,jtop 只是一个 jar 包,它的项目地址在 yujikiriki/jtop, 我们可以很方便地把它复制到服务器上,获取到 java 应用的 pid 后,使用 java -jar jtop.jar [options] <pid> 即可输出 JVM 内部统计信息。
jtop 会使用默认参数 -stack n打印出最耗 CPU 的 5 种线程栈。
形如:
Heap Memory: INIT=134217728 USED=230791968 COMMITED=450363392 MAX=1908932608
NonHeap Memory: INIT=2555904 USED=24834632 COMMITED=26411008 MAX=-1
GC PS Scavenge VALID [PS Eden Space, PS Survivor Space] GC=161 GCT=440
GC PS MarkSweep VALID [PS Eden Space, PS Survivor Space, PS Old Gen] GC=2 GCT=532
ClassLoading LOADED=3118 TOTAL_LOADED=3118 UNLOADED=0
Total threads: 608 CPU=2454 (106.88%) USER=2142 (93.30%)
NEW=0 RUNNABLE=6 BLOCKED=0 WAITING=2 TIMED_WAITING=600 TERMINATED=0
main TID=1 STATE=RUNNABLE CPU_TIME=2039 (88.79%) USER_TIME=1970 (85.79%) Allocted: 640318696
com.google.common.util.concurrent.RateLimiter.tryAcquire(RateLimiter.java:337)
io.zhenbianshu.TestFuturePool.main(TestFuturePool.java:23)
RMI TCP Connection(2)-127.0.0.1 TID=2555 STATE=RUNNABLE CPU_TIME=89 (3.89%) USER_TIME=85 (3.70%) Allocted: 7943616
sun.management.ThreadImpl.dumpThreads0(Native Method)
sun.management.ThreadImpl.dumpAllThreads(ThreadImpl.java:454)
me.hatter.tools.jtop.rmi.RmiServer.listThreadInfos(RmiServer.java:59)
me.hatter.tools.jtop.management.JTopImpl.listThreadInfos(JTopImpl.java:48)
sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
... ...
通过观察线程栈,我们可以找到要优化的代码点。
在我们的代码里,发现了很多 json 序列化和反序列化和 Bean 复制耗 CPU 的点,之后通过代码优化,通过提升 Bean 的复用率,使用 PB 替代 json 等方式,大大降低了 CPU 压力。
熔断框架优化
服务熔断框架上,我们选用了 Hystrix,虽然它已经宣布不再维护,更推荐使用 resilience4j 和阿里开源的 sentinel,但由于部门内技术栈是 Hystrix,而且它也没有明显的短板,就接着用下去了。
先介绍一下基本情况,我们在控制器接口最外层和内层 RPC 调用处添加了 Hystrix 注解,隔离方式都是线程池模式,接口处超时时间设置为 1000ms,最大线程数是 2000,内部 RPC 调用的超时时间设置为 200ms,最大线程数是 500。
响应时间不正常
要解决的第一个问题是接口的响应时间不正常。在观察接口的 access 日志时,可以发现接口有耗时为 1200ms 的请求,有些甚至达到了 2000ms 以上。由于线程池模式下,Hystrix 会使用一个异步线程去执行真正的业务逻辑,而主线程则一直在等待,一旦等待超时,主线程是可以立刻返回的。所以接口耗时超过超时时间,问题很可能发生在 Hystrix 框架层、Spring 框架层或系统层。
这时候可以对运行时线程栈来分析,我使用 jstack 打印出线程栈,并将多次打印的结果制作成火焰图来观察。
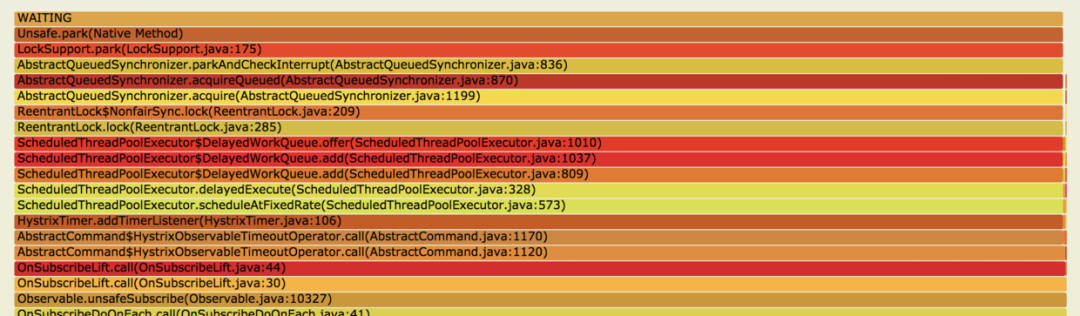
编辑
如上图,可以看到很多线程都停在 LockSupport.park(LockSupport.java:175) 处,这些线程都被锁住了,向下看来源发现是 HystrixTimer.addTimerListener(HystrixTimer.java:106), 再向下就是我们的业务代码了。
Hystrix 注释里解释这些 TimerListener 是 HystrixCommand 用来处理异步线程超时的,它们会在调用超时时执行,将超时结果返回。而在调用量大时,设置这些 TimerListener 就会因为锁而阻塞,进而导致接口设置的超时时间不生效。
接着排查调用量为什么 TimerListener 特别多。
由于服务在多个地方依赖同一个 RPC 返回值,平均一次接口响应会获取同样的值 3-5 次,所以接口内对这个 RPC 的返回值添加了 LocalCache。排查代码发现 HystrixCommand 被添加在了 LocalCache 的 get 方法上,所以单机 QPS 1000 时,会通过 Hystrix 调用方法 3000-5000 次,进而产生大量的 Hystrix TimerListener。
代码类似于:
@HystrixCommand(
fallbackMethod = "fallBackGetXXXConfig",
commandProperties = {
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "200"),
@HystrixProperty(name = "circuitBreaker.errorThresholdPercentage", value = "50")},
threadPoolProperties = {
@HystrixProperty(name = "coreSize", value = "200"),
@HystrixProperty(name = "maximumSize", value = "500"),
@HystrixProperty(name = "allowMaximumSizeToDivergeFromCoreSize", value = "true")})
public XXXConfig getXXXConfig(Long uid) {
try {
return XXXConfigCache.get(uid);
} catch (Exception e) {
return EMPTY_XXX_CONFIG;
}
}
复制
修改代码,将 HystrixCommand 修改到 localCache 的 load 方法上来解决这个问题。此外为了进一步降低 Hystrix 框架对性能的影响,将 Hystrix 的隔离策略改为了信号量模式,之后接口的最大耗时就稳定了。而且由于方法都在主线程执行,少了 Hystrix 线程池维护和主线程与 Hystrix 线程的上下文切换,系统 CPU 使用率又有进一步下降。
但使用信号量隔离模式也要注意一个问题:信号量只能限制方法是否能够进入执行,在方法返回后再判断接口是否超时并对超时进行处理,而无法干预已经在执行的方法,这可能会导致有请求超时时,一直占用一个信号量,但框架却无法处理。
服务隔离和降级
另一个问题是服务不能按照预期的方式进行服务降级和熔断,我们认为流量在非常大的情况下应该会持续熔断时,而 Hystrix 却表现为偶尔熔断。
最开始调试 Hystrix 熔断参数时,我们采用日志观察法,由于日志被设置成异步,看不到实时日志,而且有大量的报错信息干扰,过程低效而不准确。后来引入 Hystrix 的可视化界面后,才提升了调试效率。
Hystrix 可视化模式分为服务端和客户端,服务端是我们要观察的服务,需要在服务内引入 hystrix-metrics-event-stream 包并添加一个接口来输出 Metrics 信息,再启动 hystrix-dashboard 客户端并填入服务端地址即可。
编辑
注意!Apache下这些与Hadoop相关的开源项目要退休了!
通过类似上图的可视化界面,Hystrix 的整体状态就展示得非常清楚了。
由于上文中的优化,接口的最大响应时间已经完全可控,可以通过严格限制接口方法的并发量来修改接口的熔断策略了。假设我们能容忍的最大接口平均响应时间为 50ms,而服务能接受的最大 QPS 为 2000,那么可以通过 2000*50/1000=100 得到适合的信号量限制,如果被拒绝的错误数过多,可以再添加一些冗余。
这样,在流量突变时,就可以通过拒绝一部分请求来控制接口接受的总请求数,而在这些总请求里,又严格限制了最大耗时,如果错误数过多,还可以通过熔断来进行降级,多种策略同时进行,就能保证接口的平均响应时长了。
熔断时高负载导致无法恢复
接下来就要解决接口熔断时,服务负载持续升高,但在 QPS 压力降低后服务迟迟无法恢复的问题。
在服务器负载特别高时,使用各种工具来观测服务内部状态,结果都是不靠谱的,因为观测一般都采用打点收集的方式,在观察服务的同时已经改变了服务。例如使用 jtop 在高负载时查看占用 CPU 最高的线程时,获取到的结果总是 JVM TI 相关的栈。
不过,观察服务外部可以发现,这个时候会有大量的错误日志输出,往往在服务已经稳定好久了,还有之前的错误日志在打印,延时的单位甚至以分钟计。大量的错误日志不仅造成 I/O 压力,而且线程栈的获取、日志内存的分配都会增加服务器压力。而且服务早因为日志量大改为了异步日志,这使得通过 I/O 阻塞线程的屏障也消失了。
之后修改服务内的日志记录点,在打印日志时不再打印异常栈,再重写 Spring 框架的 ExceptionHandler,彻底减少日志量的输出。结果符合预期,在错误量极大时,日志输出也被控制在正常范围,这样熔断后,就不会再因为日志给服务增加压力,一旦 QPS 压力下降,熔断开关被关闭,服务很快就能恢复正常状态。
Spring 数据绑定异常
另外,在查看 jstack 输出的线程栈时,还偶然发现了一种奇怪的栈。
at java.lang.Throwable.fillInStackTrace(Native Method)
at java.lang.Throwable.fillInStackTrace(Throwable.java:783)
- locked <0x00000006a697a0b8> (a org.springframework.beans.NotWritablePropertyException)
...
org.springframework.beans.AbstractNestablePropertyAccessor.processLocalProperty(AbstractNestablePropertyAccessor.java:426)
at org.springframework.beans.AbstractNestablePropertyAccessor.setPropertyValue(AbstractNestablePropertyAccessor.java:278)
...
at org.springframework.validation.DataBinder.doBind(DataBinder.java:735)
at org.springframework.web.bind.WebDataBinder.doBind(WebDataBinder.java:197)
at org.springframework.web.bind.ServletRequestDataBinder.bind(ServletRequestDataBinder.java:107)
at org.springframework.web.method.support.InvocableHandlerMethod.getMethodArgumentValues(InvocableHandlerMethod.java:161)
...
at org.springframework.web.servlet.DispatcherServlet.doDispatch(DispatcherServlet.java:991)
复制
jstack 的一次输出中,可以看到多个线程的栈顶都停留在 Spring 的异常处理,但这时候也没有日志输出,业务也没有异常,跟进代码看了一下,Spring 竟然偷偷捕获了异常且不做任何处理。
List<PropertyAccessException> propertyAccessExceptions = null;
List<PropertyValue> propertyValues = (pvs instanceof MutablePropertyValues ?
((MutablePropertyValues) pvs).getPropertyValueList() : Arrays.asList(pvs.getPropertyValues()));
for (PropertyValue pv : propertyValues) {
try {
// This method may throw any BeansException, which won't be caught
// here, if there is a critical failure such as no matching field.
// We can attempt to deal only with less serious exceptions.
setPropertyValue(pv);
}
catch (NotWritablePropertyException ex) {
if (!ignoreUnknown) {
throw ex;
}
// Otherwise, just ignore it and continue...
}
... ...
}
复制
结合代码上下文再看,原来 Spring 在处理我们的控制器数据绑定,要处理的数据是我们的一个参数类 ApiContext。
控制器代码类似于:
@RequestMapping("test.json")
public Map testApi(@RequestParam(name = "id") String id, ApiContext apiContext) {}
复制
按照正常的套路,我们应该为这个 ApiContext 类添加一个参数解析器(HandlerMethodArgumentResolver),这样 Spring 会在解析这个参数时会调用这个参数解析器为方法生成一个对应类型的参数。可是如果没有这么一个参数解析器,Spring 会怎么处理呢?
答案就是会使用上面的那段”奇怪”代码,先创建一个空的 ApiContext 类,并将所有的传入参数依次尝试 set 进这个类,如果 set 失败了,就 catch 住异常继续执行,而 set 成功后,就完成了 ApiContext 类内一个属性的参数绑定。
而不幸的是,我们的接口上层会为我们统一传过来三四十个参数,所以每次都会进行大量的”尝试绑定”,造成的异常和异常处理就会导致大量的性能损失,在使用参数解析器解决这个问题后,接口性能竟然有近十分之一的提升。
小结
性能优化不是一朝一夕的事,把技术债都堆到最后一块解决绝不是什么好的选择。平时多注意一些代码写法,在使用黑科技时注意一下其实现有没有什么隐藏的坑才是正解,还可以进行定期的性能测试,及时发现并解决代码里近期引入的不安定因素。
四、性能调优测试相关的专业术语解说
QPS、TPS、并发用户数、吞吐量关系
1、QPS
QPS Queries Per Second 是每秒查询率 ,是一台服务器每秒能够相应的查询次数,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准, 即每秒的响应请求数,也即是最大吞吐能力。
2、TPS
TPS Transactions Per Second 也就是事务数/秒。(每秒处理的事务处理数量),即服务器每秒处理的事务数。TPS包括一条消息入和一条消息出,加上一次用户数据库访问。(业务TPS = CAPS × 每个呼叫平均TPS)。
例如,用户每分钟执行6个事务,TPS为6 / 60s = 0.10 TPS。同时我们会知道事务的响应时间(或节拍),以此例,60秒完成6个事务也同时代表每个事务的响应时间或节拍为10秒。
TPS是软件测试结果的测量单位,可基于测试周期内完成的事务数量计算得出。一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。客户机在发送请求时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数。
一般的,评价系统性能均以每秒钟完成的技术交易的数量来衡量。系统整体处理能力取决于处理能力最低模块的TPS值,TPS越高代表系统的性能越好,但同时服务器的压力也更大。
3、QPS和TPS区别
个人理解如下:
1、Tps即每秒处理事务数,包括了
- 用户请求服务器
- 服务器自己的内部处理
- 服务器返回给用户
这三个过程,每秒能够完成N个这三个过程,Tps也就是N;
2、Qps基本类似于Tps,但是不同的是,对于一个页面的一次访问,形成一个Tps;但一次页面请求,可能产生多次对服务器的请求,服务器对这些请求,就可计入“Qps”之中。
例子:
例如:访问一个页面会请求服务器3次,一次放,产生一个“T”,产生3个“Q”
例如:一个大胃王一秒能吃10个包子,一个女孩子0.1秒能吃1个包子,那么他们是不是一样的呢?答案是否定的,因为这个女孩子不可能在一秒钟吃下10个包子,她可能要吃很久。这个时候这个大胃王就相当于TPS,而这个女孩子则是QPS。虽然很相似,但其实是不同的。
4、并发数
并发数(并发度):指系统同时能处理的请求数量,同样反应了系统的负载能力。这个数值可以分析机器1s内的访问日志数量来得到
5、吐吞量
吞吐量是指系统在单位时间内处理请求的数量,TPS、QPS都是吞吐量的常用量化指标。
系统吞吐量要素
一个系统的吞吐量(承压能力)与request(请求)对cpu的消耗,外部接口,IO等等紧密关联。
单个request 对cpu消耗越高,外部系统接口,IO影响速度越慢,系统吞吐能力越低,反之越高。
重要参数
QPS(TPS),并发数,响应时间
- QPS(TPS):每秒钟request/事务 数量
- 并发数:系统同时处理的request/事务数
- 响应时间:一般取平均响应时间
关系
QPS(TPS)=并发数/平均响应时间
一个系统吞吐量通常有QPS(TPS),并发数两个因素决定,每套系统这个两个值都有一个相对极限值,在应用场景访问压力下,只要某一项达到系统最高值,系统吞吐量就上不去了,如果压力继续增大,系统的吞吐量反而会下降,原因是系统超负荷工作,上下文切换,内存等等其他消耗导致系统性能下降。
6、PV
PV(Page View):页面访问量,即页面浏览量或点击量,用户每次刷新即被计算一次。可以统计服务一天的访问日志得到。
7、UV
UV(Unique Visitor):独立访客,统计1天内访问某站点的用户数。可以统计服务一天的访问日志并根据用户的唯一标识去重得到。响应时间(RT):响应时间是指系统对请求作出响应的时间,一般取平均响应时间。可以通过Nginx、Apache之类的Web Server得到。
8、DAU
DAU(Daily Active User),日活跃用户数量。常用于反映网站、互联网应用或网络游戏的运营情况。DAU通常统计一日(统计日)之内,登录或使用了某个产品的用户数(去除重复登录的用户),与UV概念相似
9、MAU
MAU(Month Active User):月活跃用户数量,指网站、app等去重后的月活跃用户数量
10、系统吞吐量评估
我们在做系统设计的时候就需要考虑CPU运算,IO,外部系统响应因素造成的影响以及对系统性能的初步预估。
而通常情况下,我们面对需求,我们评估出来的出来QPS,并发数之外,还有另外一个维度:日pv。
通过观察系统的访问日志发现,在用户量很大的情况下,各个时间周期内的同一时间段的访问流量几乎一样。比如工作日的每天早上。只要能拿到日流量图和QPS我们就可以推算日流量。
通常的技术方法:
1、找出系统的最高TPS和日PV,这两个要素有相对比较稳定的关系(除了放假、季节性因素影响之外)
2、通过压力测试或者经验预估,得出最高TPS,然后跟进1的关系,计算出系统最高的日吞吐量。B2B中文和淘宝面对的客户群不一样,这两个客户群的网络行为不应用,他们之间的TPS和PV关系比例也不一样。
11、软件性能测试的基本概念和计算公式
软件做性能测试时需要关注哪些性能呢?
首先,开发软件的目的是为了让用户使用,我们先站在用户的角度分析一下,用户需要关注哪些性能。
对于用户来说,当点击一个按钮、链接或发出一条指令开始,到系统把结果已用户感知的形式展现出来为止,这个过程所消耗的时间是用户对这个软件性能的直观印 象。也就是我们所说的响应时间,当相应时间较小时,用户体验是很好的,当然用户体验的响应时间包括个人主观因素和客观响应时间,在设计软件时,我们就需要 考虑到如何更好地结合这两部分达到用户最佳的体验。如:用户在大数据量查询时,我们可以将先提取出来的数据展示给用户,在用户看的过程中继续进行数据检 索,这时用户并不知道我们后台在做什么。
用户关注的是用户操作的相应时间。
其次,我们站在管理员的角度考虑需要关注的性能点。
1、 响应时间
2、 服务器资源使用情况是否合理
3、 应用服务器和数据库资源使用是否合理
4、 系统能否实现扩展
5、 系统最多支持多少用户访问、系统最大业务处理量是多少
6、 系统性能可能存在的瓶颈在哪里
7、 更换那些设备可以提高性能
8、 系统能否支持7×24小时的业务访问
再次,站在开发(设计)人员角度去考虑。
1、 架构设计是否合理
2、 数据库设计是否合理
3、 代码是否存在性能方面的问题
4、 系统中是否有不合理的内存使用方式
5、 系统中是否存在不合理的线程同步方式
6、 系统中是否存在不合理的资源竞争
五、测试、分析和调优略说
测试分析及调优
本文通过编写性能测试分析及调优的相关流程和方法,帮助研发人员、性能测试人员或者运维人员快速地进行性能测试、瓶颈定位及调优。 系统的性能是由很多因素决定的,本文很难面面俱到,但是可以作为分析系统性能的一个指导。
适用对象和范围
适用于需要进行性能分析及调优的工作。 预期读者为测试管理人员、测试实施人员、技术支持人员、项目质量管理人员、项目管理人员等系统技术质量相关人员。
性能分析
前提
性能分析的前提除了需要丰富的性能测试监控(如PTS自身的客户侧监控、基础类监控-阿里云监控、应用类监控-ARMS监控等),还需要具备相关的技术知识(包括但不限于:操作系统、中间件、数据库、开发等)。
流程
- 很多情况下压测流量并没有完全进入到后端(服务端),在网络接入层(云化的架构,例如:SLB/WAF/高防IP,甚至是CDN/全站加速等)可能就会出现由于各种规格(带宽、最大连接数、新建连接数等)限制或者因为压测的某些特征符合CC和DDoS的行为而触发了防护策略导致压测结果达不到预期,详情请见为什么后端压力不大但压测时报错或超时?。
- 接着看关键指标是否满足要求,如果不满足,需要确定是哪个地方有问题,一般情况下,服务器端问题可能性比较大,也有可能是客户端问题(这种情况非常小)。
- 对于服务器端问题,需要定位的是硬件相关指标,例如CPU,Memory,Disk I/O,Network I/O,如果是某个硬件指标有问题,需要深入的进行分析。
- 如果硬件指标都没有问题,需要查看中间件相关指标,例如:线程池、连接池、GC等,如果是这些指标问题,需要深入的分析。
- 如果中间件相关指标没问题,需要查看数据库相关指标,例如:慢查SQL、命中率、锁、参数设置。
- 如果以上指标都正常,应用程序的算法、缓冲、缓存、同步或异步可能有问题,需要具体深入的分析。
具体如下图所示:
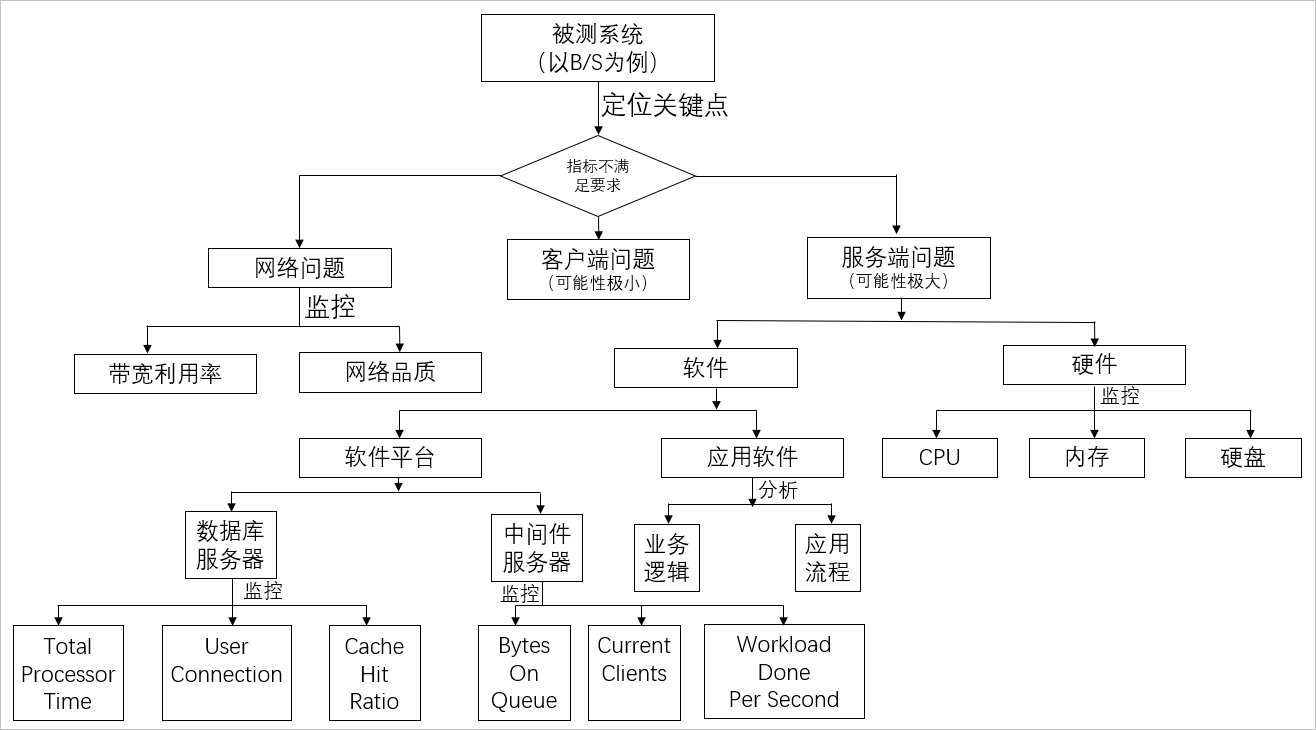 编辑
编辑可能瓶颈点
硬件、规格上的瓶颈
一般指的是CPU、内存、磁盘I/O方面的问题,分为服务器硬件瓶颈、网络瓶颈(对局域网可以不考虑)。
中间件上的性能瓶颈
一般指的是应用服务器、Web服务器等应用软件,还包括数据库系统。 例如:中间件Weblogic平台上配置的JDBC连接池的参数设置不合理,造成的瓶颈。
应用程序上的性能瓶颈
一般指的是开发人员开发出来的应用程序。 例如,JVM参数不合理,容器配置不合理,慢SQL(可使用阿里云APM类产品如ARMS协助定位),数据库设计不合理,程序架构规划不合理,程序本身设计有问题(串行处理、请求的处理线程不够、无缓冲、无缓存、生产者和消费者不协调等),造成系统在大量用户访问时性能低下而造成的瓶颈。
操作系统上的性能瓶颈
一般指的是Windows、UNIX、Linux等操作系统。 例如,在进行性能测试,出现物理内存不足时,虚拟内存设置也不合理,虚拟内存的交换效率就会大大降低,从而导致行为的响应时间大大增加,这时认为操作系统上出现性能瓶颈。
网络设备上的性能瓶颈
一般指的是防火墙、动态负载均衡器、交换机等设备。当前更多的云化服务架构使用的网络接入产品:包括但不限于SLB、WAF、高防IP、CDN、全站加速等等。 例如,在动态负载均衡器上设置了动态分发负载的机制,当发现某个应用服务器上的硬件资源已经到达极限时,动态负载均衡器将后续的交易请求发送到其他负载较轻的应用服务器上。在测试时发现,动态负载均衡器没有起到相应的作用,这时可以认为网络瓶颈。
方法
CPU
CPU资源利用率很高的话,需要看CPU消耗User、Sys、Wait哪种状态。
- 如果CPU User非常高,需要查看消耗在哪个进程,可以用top(Linux)命令看出,接着用top –H –p 看哪个线程消耗资源高。如果是Java应用,就可以用jstack看出此线程正在执行的堆栈,看资源消耗在哪个方法上,查看源代码就知道问题所在;如果是c++应用,可以用gprof性能工具进行分析。
- 如果CPU Sys非常高,可以用strace(Linux)看系统调用的资源消耗及时间。
- 如果CPU Wait非常高,考虑磁盘读写了,可以通过减少日志输出、异步或换速度快的硬盘。
Memory
操作系统为了最大化利用内存,一般都设置大量的Cache,因此,内存利用率高达99%并不是问题,内存的问题主要看某个进程占用的内存是否非常大以及是否有大量的Swap(虚拟内存交换)。
磁盘I/O
磁盘I/O一个最显著的指标是繁忙率,可以通过减少日志输出、异步或换速度快的硬盘来降低繁忙率。
网络I/O
网络I/O主要考虑传输内容大小,不能超过硬件网络传输的最大值70%,可以通过压缩减少内容大小、在本地设置缓存以及分多次传输等操作提高网络I/O性能。
内核参数
内核参数一般都有默认值,这些内核参数默认值对于一般系统没问题,但是对于压力测试来说,可能运行的参数将会超过内核参数,导致系统出现问题,可以用Sysctl来查看及修改。
JVM
JVM主要分析GC/FULL GC是否频繁,以及垃圾回收的时间,可以用jstat命令来查看,对于每个代大小以及GC频繁,通过jmap将内存转储,再借助工具HeapAnalyzer来分析哪地方占用的内存较高以及是否有内存泄漏可能。简单点可以使用APM工具,例如阿里云ARMS。
线程池
如果线程不够用,可以通过参数调整,增加线程;对于线程池中的线程设置比较大的情况,还是不够用可能的原因是:某个线程被阻塞来不及释放,可能在等锁、方法耗时较长、数据库等待时间很长等原因导致,需要进一步分析才能定位。
JDBC连接池
连接池不够用的情况下,可以通过参数进行调整增加;但是对于数据库本身处理很慢的情况下,调整没有多大的效果,需要查看数据库方面以及因代码导致连接未释放的原因。
SQL
SQL效率低下也是导致性能差的一个非常重要的原因,可以通过查看执行计划看SQL慢在哪里,一般情况,SQL效率低下原因主要有:
类别 子类 表达式或描述 原因 索引 未建索引 无 产生全表扫描 未利用索引 substring(card_no,1,4)=′5378′ 产生全表扫描 amount/30<1000 产生全表扫描 convert(char(10),date,112)=′19991201′ 产生全表扫描 where salary<>3000 产生全表扫描 name like '%张' 产生全表扫描 first_name + last_name ='beill cliton' 产生全表扫描 id_no in(′0′,′1′) 产生全表扫描 select id from t where num=@num 有参数也会产生全表扫描 使用效能低的索引 oder by非聚簇索引 索引性能低 username='张三'and age>20 字符串索引低于整形索引 表中列与空NULL值 索引性能低 尽量不要使用IS NULL或IS NOT NULL 索引性能低 数据量 所有数据量 select * 很多列产生大量数据 select id,name 表中有几百万行,产生大量数据 嵌套查询 先不过滤数据,后过滤数据 产生大量无用的数据 关联查询 多表进行关联查询,先过滤掉小部分数据,在过滤大部分数据 大量关联操作 大数据量插入 一次次插入 产生大量日志,消耗资源 锁 锁等待 update account set banlance=100 where id=10 产生行级锁,将会锁住整个表 死锁 A:update a;update b;B:update b;update a; 将会产生死锁 游标 Cursor Open cursor,fetch;close cursor 性能很低 临时表 create tmp table创建临时表 产生大量日志 drop table 删除临时表 需要显示删除,避免系统表长时间锁定 其他 exist代替IN select num from a where num in(select num from b) in会逐个判断,exist有一条就结束 exist代替select count(*) 判断记录是否存在 count(*) 将累加计算,exist有就结束 between代替IN ID in(1,2,3) IN逐个判断,between是范围判断 left outer join代替Not IN select ID from a where ID not in(select b.Mainid from b) NOT IN逐个判断,效率非常低 union all代替union select ID from a union select id from b union 删除重复的行,可能会在磁盘进行排序而union all只是简单的将结果并在一起 常用SQL尽量用绑定变量方法 insert into A(ID) values(1) 直接写SQL每次都要编译,用绑定变量的方法只编译一次,下次就可以用了
调优
调优步骤
确定问题
- 应用程序代码:在通常情况下,很多程序的性能问题都是写出来的,因此对于发现瓶颈的模块,应该首先检查一下代码。
- 数据库配置:经常引起整个系统运行缓慢,一些诸如大型数据库都是需要DBA进行正确的参数调整才能投产的。
- 操作系统配置:不合理就可能引起系统瓶颈。
- 硬件设置:硬盘速度、内存大小等都是容易引起瓶颈的原因,因此这些都是分析的重点。
- 网络:网络负载过重导致网络冲突和网络延迟。
分析问题
- 当确定了问题之后,我们要明确这个问题影响的是响应时间吞吐量,还是其他问题?
- 是多数用户还是少数用户遇到了问题?如果是少数用户,这几个用户与其它用户的操作有什么不同?
- 系统资源监控的结果是否正常?CPU的使用是否到达极限?I/O情况如何?
- 问题是否集中在某一类模块中?
- 是客户端还是服务器出现问题? 系统硬件配置是否够用?
- 实际负载是否超过了系统的负载能力? 是否未对系统进行优化?
通过这些分析及一些与系统相关的问题,可以对系统瓶颈有更深入的了解,进而分析出真正的原因。
确定调整目标和解决方案
高系统吞吐量,缩短响应时间,更好地支持并发。
测试解决方案
对通过解决方案调优后的系统进行基准测试。(基准测试是指通过设计科学的测试方法、测试工具和测试系统,实现对一类测试对象的某项性能指标进行定量的和可对比的测试)。
分析调优结果
系统调优是否达到或者超出了预定目标;系统是整体性能得到了改善,还是以系统某部分性能来解决其他问题;调优是否可以结束了。 最后,如果达到了预期目标,调优工作可以先告一段落。
调优注意事项
- 在应用系统的设计开发过程中,应始终把性能放在考虑的范围内,将性能测试常态化,日常化的内网的性能测试+定期的真实环境的业务性能测试,PTS都可以支持。
- 确定清晰明确的性能目标是关键,进而将目标转化为PTS中的压测场景并设置好需要的目标量级,然后视情况选择并发、TPS模式,自动递增/手工调速的组合进行流量控制。
- 必须保证调优后的程序运行正确。
- 系统的性能更大程度上取决于良好的设计,调优技巧只是一个辅助手段。
- 调优过程是迭代渐进的过程,每一次调优的结果都要反馈到后续的代码开发中去。
- 性能调优不能以牺牲代码的可读性和可维护性为代价。
其他测试分析
成功率
成功率是根据服务端的返回值以及断言来判断的,如果没有配置断言的情况下,后端服务返回错误响应码或服务端异常或超时都认为是失败。
日志
日志是关于每个请求的内容,采样率100%的话表示每个请求都会记录,采样率10%可以理解为100个请求采集10个请求的内容,但是会对施压机性能造成影响,也会增加计费,日志采样率不影响服务端的。
建立连接
建立连接就是HTTP建立TCP连接的耗时,超过设置的建立连接超时时间就认为这个请求超时了,请求超时时间为从DNS查询算起,到接收完响应内容整个时间的阈值,超过就认为这个请求超时了。
高并发场景QPS等专业指标揭秘大全与调优实战的更多相关文章
- 记一次高并发场景下.net监控程序数据上报的性能调优
最近在和小伙伴们做充电与通信程序的架构迁移.迁移前的架构是,通信程序负责接收来自充电集控设备的数据实时数据,通过Thrift调用后端的充电服务,充电服务收到响应后放到进程的Queue中,然后在管理线程 ...
- Qunar机票技术部就有一个全年很关键的一个指标:搜索缓存命中率,当时已经做到了>99.7%。再往后,每提高0.1%,优化难度成指数级增长了。哪怕是千分之一,也直接影响用户体验,影响每天上万张机票的销售额。 在高并发场景下,提供了保证线程安全的对象、方法。比如经典的ConcurrentHashMap,它比起HashMap,有更小粒度的锁,并发读写性能更好。线程安全的StringBuilder取代S
Qunar机票技术部就有一个全年很关键的一个指标:搜索缓存命中率,当时已经做到了>99.7%.再往后,每提高0.1%,优化难度成指数级增长了.哪怕是千分之一,也直接影响用户体验,影响每天上万张机 ...
- 高并发场景-请求合并(二)揭秘HystrixCollapser-利用Queue和线程池异步实现
背景 在互联网的高并发场景下,请求会非常多,但是数据库连接池比较少,或者说需要减少CPU压力,减少处理逻辑的,需要把单个查询,用某些手段,改为批量查询多个后返回. 如:支付宝中,查询"个人信 ...
- Java电商项目,秒杀,抢购等高并发场景的具体场景和一些概念以及处理思路
这里我借鉴了网上其他大佬的观点: 一:高并发带来的挑战 原因:秒杀抢购会经常会带来每秒几万的高并发场景,为了更快的返回结果给用户. 吞吐量指标QPS(每秒处理请求数),假设一个业务请求响应耗时为100 ...
- HttpClient在高并发场景下的优化实战
在项目中使用HttpClient可能是很普遍,尤其在当下微服务大火形势下,如果服务之间是http调用就少不了跟http客户端找交道.由于项目用户规模不同以及应用场景不同,很多时候可能不需要特别处理也. ...
- MySQL在大数据、高并发场景下的SQL语句优化和"最佳实践"
本文主要针对中小型应用或网站,重点探讨日常程序开发中SQL语句的优化问题,所谓“大数据”.“高并发”仅针对中小型应用而言,专业的数据库运维大神请无视.以下实践为个人在实际开发工作中,针对相对“大数据” ...
- C++高并发场景下读多写少的解决方案
C++高并发场景下读多写少的解决方案 概述 一谈到高并发的解决方案,往往能想到模块水平拆分.数据库读写分离.分库分表,加缓存.加mq等,这些都是从系统架构上解决.单模块作为系统的组成单元,其性能好坏也 ...
- C++高并发场景下读多写少的优化方案
概述 一谈到高并发的优化方案,往往能想到模块水平拆分.数据库读写分离.分库分表,加缓存.加mq等,这些都是从系统架构上解决.单模块作为系统的组成单元,其性能好坏也能很大的影响整体性能,本文从单模块下读 ...
- 高并发场景之RabbitMQ篇
上次我们介绍了在单机.集群下高并发场景可以选择的一些方案,传送门:高并发场景之一般解决方案 但是也发现了一些问题,比如集群下使用ConcurrentQueue或加锁都不能解决问题,后来采用Redis队 ...
- 【转】记录PHP、MySQL在高并发场景下产生的一次事故
看了一篇网友日志,感觉工作中值得借鉴,原文如下: 事故描述 在一次项目中,上线了一新功能之后,陆陆续续的有客服向我们反应,有用户的个别道具数量高达42亿,但是当时一直没有到证据表示这是,确实存在,并且 ...
随机推荐
- vscode+gitee+picgo实现稳定图床
目录: 目录 目录: 1. 为什么使用vscode+gitee+picgo实现完美图床 2. 安装VSCode 2.1 安装VSCode软件及相关插件 3. 安装picgo 4. 准备Gitee图床 ...
- C++socket服务器与客户端简单通信流程
服务器和客户端简单通信的流程,做一个简单的复习: 1.服务器创建的流程 代码如下,各个重要函数已经写注释: #include <iostream> // 推荐加上宏定义 #define W ...
- CPNtools协议建模安全分析---实例变迁标记(五)
之前的说了库所的标记,现在我们开始加讲变迁标记 1.描述变迁的标记有四种类型,分别是变迁的标记,门卫的标记,世间的标记,代码片段的标记. 咋变迁中限制更严格的输入token,其中Code Segeme ...
- 海词 dict.cn 有 词义饼状分布图 和 词性饼状分布图 - 词典推荐
海词 dict.cn 有 词义饼状分布图 和 词性饼状分布图 http://dict.cn/like
- 别名路径跳转 - vscode 插件
别名路径跳转 - vscode 插件
- Docker 安装成功(win10家庭版)
https://desktop.docker.com/win/stable/Docker Desktop Installer.exe 安装遇到了 然后 更新 这个 https://wslstorest ...
- pip 安装requirements.txt 的问题
用新环境 在进行pip 安装的时候, 如果出现不进行安装 ,但是不报错就是满足条件,这个时候重新起一个shell,然后进行pip的安装.
- Navicat 15 最新破解版下载_永久激活注册码(附图文安装教程)
Navicat 15 最新破解版下载_永久激活注册码(附图文安装教程) 欢迎关注博主公众号「java大师」, 专注于分享Java领域干货文章, 关注回复「资源」, 免费领取全网最热的Java架构师学习 ...
- JB一键重置
版本名 版本号 更新时间 更新内容 更新地址 v1.1 2 2020-12-26 在线下载失败的请访问shop.stars-one.site,使用软件找回手动下载\n1.修复bug\n2.修复在线更新 ...
- Google Chart API学习(三)
书接上回: maps-charts: <html> <head> <script type="text/javascript" src="h ...