Apache Storm技术实战之3 -- TridentWordCount
欢迎转载,转载请注明出处。
介绍TridentTopology的使用,重点分析newDRPCStream和stateQuery的实现机理。
使用TridentTopology进行数据处理的时候,经常会使用State来保存一些状态,这些保存起来的State通过stateQuery来进行查询。问题恰恰在这里产生,即对state进行更新的Stream和尔后进行stateQuery的Stream并非同一个,那么它们之间是如何关联起来的呢。
在TridentTopology中,有一些Processor可能会同处于一个Bolt中,这些Processor形成一个processing chain, 那么Tuple又是如何在这些Processor之间进行传递的呢。
TridentWordCount
编译和运行
lein compile storm.starter.trident.TridentWordCount
java -cp $(lein classpath) storm.starter.trident.TridentWordCount
main函数
public static void main(String[] args) throws Exception {
Config conf = new Config();
conf.setMaxSpoutPending(20);
if (args.length == 0) {
LocalDRPC drpc = new LocalDRPC();
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("wordCounter", conf, buildTopology(drpc));
for (int i = 0; i < 100; i++) {
System.out.println("DRPC RESULT: " + drpc.execute("words", "cat the dog jumped"));
Thread.sleep(1000);
}
}
else {
conf.setNumWorkers(3);
StormSubmitter.submitTopology(args[0], conf, buildTopology(null));
}
}
buildTopology
public static StormTopology buildTopology(LocalDRPC drpc) {
FixedBatchSpout spout = new FixedBatchSpout(new Fields("sentence"), 3, new Values("the cow jumped over the moon"),
new Values("the man went to the store and bought some candy"), new Values("four score and seven years ago"),
new Values("how many apples can you eat"), new Values("to be or not to be the person"));
spout.setCycle(true);
TridentTopology topology = new TridentTopology();
TridentState wordCounts = topology.newStream("spout1", spout).parallelismHint(16).each(new Fields("sentence"),
new Split(), new Fields("word")).groupBy(new Fields("word")).persistentAggregate(new MemoryMapState.Factory(),
new Count(), new Fields("count")).parallelismHint(16);
topology.newDRPCStream("words", drpc).each(new Fields("args"), new Split(), new Fields("word")).groupBy(new Fields(
"word")).stateQuery(wordCounts, new Fields("word"), new MapGet(), new Fields("count")).each(new Fields("count"),
new FilterNull()).aggregate(new Fields("count"), new Sum(), new Fields("sum"));
return topology.build();
}
示意图
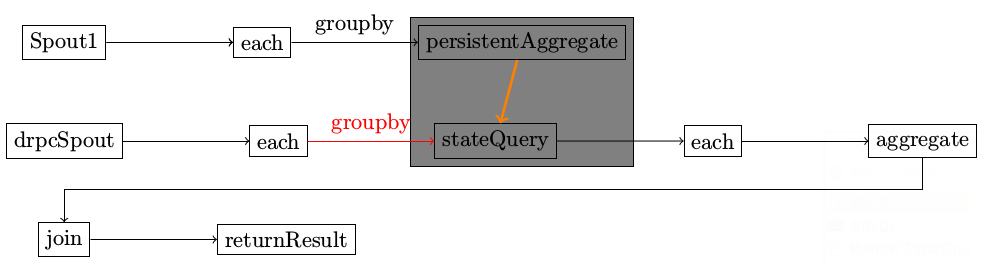
在整个topology中,有两个不同的spout。
运行结果该如何理解
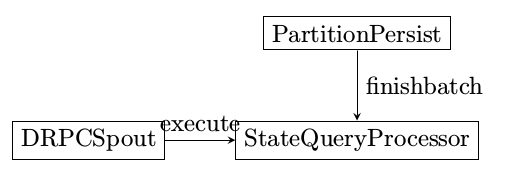
此图有好几个问题
- PartitionPersistProcessor和StateQueryProcessor同处于一个bolt,该bolt为SubtopologyBolt
- SubtopologyBolt有来自多个不同Stream的输入,根据不同的Streamid找到对应的InitialReceiver
- drpcspout在执行的时候,是一直不停的emit消息到SubtopologyBolt,还是发送完一次消息就停止发送
不同的tuple,其sourcestream不一样,根据SourceStream,找到对应的InitialReceiver
Map<String, InitialReceiver> _roots = new HashMap();
状态更新
进行状态更新的Processor名为PartitionPersistProcessor
execute
记录哪些tuple需要进行状态更新
finishBatch
状态真正更新是发生在finishBatch阶段
persistentAggregate
PartitionPersistProcessor
- SubtopologyBolt::execute
- PartitionPersistProcessor::finishBatch
- _updater::updateState
- Snapshottable::update
- _updater::updateState
- PartitionPersistProcessor::finishBatch
当状态更新的时候,状态查询是否会发生?
状态查询
进行状态查询的Processor名为StateQueryProcessor
execute
finishBatch
查询的时候,首先调用batchRetrieive来获得最新的状态更新结果,再对每个最新的结果使用_function来进行处理。
调用层次
- SubtopologyBolt::finishBatch
- StateQueryProcessor::finishBatch
- _function.batchRetrieve
- _function.execute 将处理过的结果发送给下一跳进行处理
- StateQueryProcessor::finishBatch
消息的传递
TridentTuple
如何决定bolt内部的哪个processor来处理接收到的消息,这个是根据不同的Stream来判断InitialReceiver完成。
当SubtopologyBolt接收到最原始的tuple时,根据streamid找到InitialReceiver后,InitialReceiver在receive函数中作的第一件事情就是根据tuple来创建一个tridenttuple,tridenttuple会被处在同一个SubtopologyBolt中的processor一一处理,处理的结果是保存在tridenttuple和processorcontext中。
ProcessorContext
ProcessorContext记录两个重要的信息,即当前的batchId和batchState.
public class ProcessorContext {
public Object batchId;
public Object[] state;
public ProcessorContext(Object batchId, Object[] state) {
this.batchId = batchId;
this.state = state;
}
}
TridentCollector
tridentcollector在emit的时候将消息由各个TupleReceiver进行处理。目前仅有BridgeReceiver实现了该接口。
BridgeReceiver负责将消息发送给另外的Bolt进行处理。这里说的“另外的Bolt”是指Vanilla Topology中的Bolt.
Apache Storm技术实战之3 -- TridentWordCount的更多相关文章
- Apache Storm技术实战之1 -- WordCountTopology
欢迎转载,转载请注意出处,徽沪一郎. “源码走读系列”从代码层面分析了storm的具体实现,接下来通过具体的实例来说明storm的使用.因为目前storm已经正式迁移到Apache,文章系列也由twi ...
- Apache Storm技术实战之2 -- BasicDRPCTopology
欢迎转载,转载请注明出处,徽沪一郎. 本文通过BasicDRPCTopology的实例来分析DRPCTopology在提交的时候, Topology中究竟含有哪些内容? BasicDRPCTopolo ...
- Apache Spark技术实战之6 --Standalone部署模式下的临时文件清理
问题导读 1.在Standalone部署模式下,Spark运行过程中会创建哪些临时性目录及文件? 2.在Standalone部署模式下分为几种模式? 3.在client模式和cluster模式下有什么 ...
- Apache Spark技术实战之4 -- 利用Spark将json文件导入Cassandra
欢迎转载,转载请注明出处. 概要 本文简要介绍如何使用spark-cassandra-connector将json文件导入到cassandra数据库,这是一个使用spark的综合性示例. 前提条件 假 ...
- Apache Spark技术实战之3 -- Spark Cassandra Connector的安装和使用
欢迎转载,转载请注明出处,徽沪一郎. 概要 前提 假设当前已经安装好如下软件 jdk sbt git scala 安装cassandra 以archlinux为例,使用如下指令来安装cassandra ...
- Apache Spark技术实战之9 -- 日志级别修改
摘要 在学习使用Spark的过程中,总是想对内部运行过程作深入的了解,其中DEBUG和TRACE级别的日志可以为我们提供详细和有用的信息,那么如何进行合理设置呢,不复杂但也绝不是将一个INFO换为TR ...
- Apache Spark技术实战之8:Standalone部署模式下的临时文件清理
未经本人同意严禁转载,徽沪一郎. 概要 在Standalone部署模式下,Spark运行过程中会创建哪些临时性目录及文件,这些临时目录和文件又是在什么时候被清理,本文将就这些问题做深入细致的解答. 从 ...
- Apache Spark技术实战之7 -- CassandraRDD高并发数据读取实现剖析
未经本人同意,严禁转载,徽沪一郎. 概要 本文就 spark-cassandra-connector 的一些实现细节进行探讨,主要集中于如何快速将大量的数据从cassandra 中读取到本地内存或磁盘 ...
- Apache Spark技术实战之6 -- spark-submit常见问题及其解决
除本人同意外,严禁一切转载,徽沪一郎. 概要 编写了独立运行的Spark Application之后,需要将其提交到Spark Cluster中运行,一般会采用spark-submit来进行应用的提交 ...
随机推荐
- ASP.Net核心对象之HttpResponse
简介: HttpResponse是对响应报文进行设置的一个对象.通过context. Response 能够得到HttpResponse对象. context.Response.Charset;//获 ...
- JS生成某个范围的随机数(四种情况)
前言: JS没有现成的函数,能够直接生成指定范围的随机数. 但是它有个函数:Math.random() 这个函数可以生成 [0,1) 的一个随机数. 利用它,我们就可以生成指定范围内的随机数. 而涉 ...
- 通过扩展让ASP.NET Web API支持W3C的CORS规范(转载)
转载地址:http://www.cnblogs.com/artech/p/cors-4-asp-net-web-api-04.html CORS(Cross-Origin Resource Shari ...
- 电赛总结(二)——AD芯片总结之AD7715
一.特性参数 1.16位无失真AD转换器 2.增益可调,在1,2,32,128可切换. 3.数字地和模拟地分开,可以减少噪声. 4.具有较大的输出电流,有比较好的带载能力. 二.管脚排列 三.引脚功能 ...
- 2016.7.7 计算机网络复习要点第四章之网际协议IP
1.与IP协议配套使用的还有三个协议: **地址解析协议ARP: **网际控制报文协议ICMP: **网际组管理协议IGMP: 2.虚拟互连网络: **没有一种单一的网络能够适应所有用户的需求: ** ...
- Kali Linux 2016.2初体验使用总结
Kali Linux 2016.2初体验使用总结 Kali Linux官方于8月30日发布Kali Linux 2016的第二个版本Kali Linux 2016.2.该版本距离Kali Linux ...
- 判断 Gym 100502K Train Passengers
题目传送门 /* 题意:几个判断,车上的人不能 <0 或 > C:车上初始和结束都不能有人在 (为0):车上满员时才有等候的人 水题:难点在于读懂题目意思,状态不佳,一直没搞懂意思,在这题 ...
- 【Linux/unix网络编程】之使用socket进行TCP编程
实验一 TCP数据发送与接收 [实验目的] 1.熟练掌握套接字函数的使用方法. 2.应用套接字函数完成基本TCP通讯,实现服务器与客户端的信息交互. [实验学时] 4学时 [实验内容] 实现一个服务器 ...
- POJ 2217 (后缀数组+最长公共子串)
题目链接: http://poj.org/problem?id=2217 题目大意: 求两个串的最长公共子串,注意子串是连续的,而子序列可以不连续. 解题思路: 后缀数组解法是这类问题的模板解法. 对 ...
- JAVA计算文件大小
File f = new File(save_path+File.separator + resouce_id+".zip"); FileInputStream fis = new ...