浅谈Java正则表达式
正则表达式我们都知道,它定义了字符串的模式,可以用来搜索、编辑或处理文本。我们在某些特定场景中用起来是非常方便的。它等于是给我们划定了一个范围,让我们可以精准的匹配到我们想要的结果。比如我想判断一个几十页的文件中是不是含有邮箱地址,如果用传统的方法,我还要从头到尾遍历筛选一遍,工作量很大,但有了正则我们就可以划定模式去判断,非常之方便。正则表达式并不仅限于某一种语言,但是在每种语言中有细微的差别。下面我就正则表达式在Java中的应用来举例说明其基本用法。
浅谈正则表达式
1.正则表达式可以用来干什么
光说什么是正则表达式,有人就有疑问了。那他到底能用来干什么,现在我就先举一例,然后再慢慢给大家说:
就比如现在我判断一堆字符串中是不是包含有数字,那么就可以用正则来做:
@Test
public void test1(){
String s = "fsjkdhfgjh666hgdfshjhahaksgefj";
System.out.println(s.matches("^.*[\\d+].*$"));
}
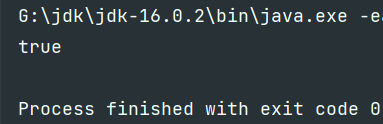
证明有数字,也确实有。
但你也许说了,我将字符串遍历一遍啊,然后逐个判断,不也能找到吗?当然能啊。对于这样一个字符串那当然可以这样做。但是如果我们面对的是一本书呢?我想判断一本书里有没有身份证号,首先我不确定这个身份证号是多少(当然肯定是18位),那你怎么稿?总不能将这本书从头到尾遍历一遍吧,那工作量相当大。而且你也不知道具体是多少,那这时候,正则表达式的优势就出来了。我可以划定一个规则去检索。这大大的提高了我们的开发效率。
2.如何使用正则表达式
那么正则表达式如何去使用呢。
首先我给大家列个表:
1.正则表达式元字符
| 字符 | 描述 |
|---|---|
| \ | 将下一个字符标记为一个特殊字符、或一个原义字符、或一个 向后引用、或一个八进制转义符。例如,‘n’ 匹配字符 “n”。’\n’ 匹配一个换行符。序列 ‘\’ 匹配 “” 而 “(” 则匹配 “(”。 |
| ^ | 匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 ‘\n’ 或 ‘\r’ 之后的位置。 |
| $ | 匹配输入字符串的结束位置。如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 ‘\n’ 或 ‘\r’ 之前的位置。 |
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 “z” 以及 “zoo”。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,‘zo+’ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z”。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,“do(es)?” 可以匹配 “do” 或 “does” 。? 等价于 {0,1}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,‘o{2}’ 不能匹配 “Bob” 中的 ‘o’,但是能匹配 “food” 中的两个 o。 |
| {n,} | n 是一个非负整数。至少匹配n 次。例如,‘o{2,}’ 不能匹配 “Bob” 中的 ‘o’,但能匹配 “foooood” 中的所有 o。‘o{1,}’ 等价于 ‘o+’。‘o{0,}’ 则等价于 ‘o*’。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,“o{1,3}” 将匹配 “fooooood” 中的前三个 o。‘o{0,1}’ 等价于 ‘o?’。请注意在逗号和两个数之间不能有空格。 |
| ? | 当该字符紧跟在任何一个其他限制符 (*, +, ?, {n}, {n,}, {n,m}) 后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串 “oooo”,‘o+?’ 将匹配单个 “o”,而 ‘o+’ 将匹配所有 ‘o’。 |
| . | 匹配除换行符(\n、\r)之外的任何单个字符。要匹配包括 ‘\n’ 在内的任何字符,请使用像"(.|\n)"的模式。 |
| (pattern) | 匹配 pattern 并获取这一匹配。所获取的匹配可以从产生的 Matches 集合得到,在VBScript 中使用 SubMatches 集合,在JScript 中则使用 $0…$9 属性。要匹配圆括号字符,请使用 ‘(’ 或 ‘)’。 |
| (?:pattern) | 匹配 pattern 但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用 “或” 字符 (|) 来组合一个模式的各个部分是很有用。例如, 'industr(?:y|ies) 就是一个比 ‘industry|industries’ 更简略的表达式。 |
| (?=pattern) | 正向肯定预查(look ahead positive assert),在任何匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如,“Windows(?=95|98|NT|2000)“能匹配"Windows2000"中的"Windows”,但不能匹配"Windows3.1"中的"Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
| (?!pattern) | 正向否定预查(negative assert),在任何不匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如"Windows(?!95|98|NT|2000)“能匹配"Windows3.1"中的"Windows”,但不能匹配"Windows2000"中的"Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
| (?<=pattern) | 反向(look behind)肯定预查,与正向肯定预查类似,只是方向相反。例如,"(?<=95|98|NT|2000)Windows“能匹配”2000Windows“中的”Windows",但不能匹配"3.1Windows“中的”Windows"。 |
| (?<!pattern) | 反向否定预查,与正向否定预查类似,只是方向相反。例如"(?<!95|98|NT|2000)Windows“能匹配”3.1Windows“中的”Windows",但不能匹配"2000Windows“中的”Windows"。 |
| x|y | 匹配 x 或 y。例如,‘z|food’ 能匹配 “z” 或 “food”。’(z|f)ood’ 则匹配 “zood” 或 “food”。 |
| [xyz] | 字符集合。匹配所包含的任意一个字符。例如, ‘[abc]’ 可以匹配 “plain” 中的 ‘a’。 |
| [^xyz] | 负值字符集合。匹配未包含的任意字符。例如, ‘[^abc]’ 可以匹配 “plain” 中的’p’、‘l’、‘i’、‘n’。 |
| [a-z] | 字符范围。匹配指定范围内的任意字符。例如,’[a-z]’ 可以匹配 ‘a’ 到 ‘z’ 范围内的任意小写字母字符。 |
| [^a-z] | 负值字符范围。匹配任何不在指定范围内的任意字符。例如,’[^a-z]’ 可以匹配任何不在 ‘a’ 到 ‘z’ 范围内的任意字符。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, ‘er\b’ 可以匹配"never" 中的 ‘er’,但不能匹配 “verb” 中的 ‘er’。 |
| \B | 匹配非单词边界。‘er\B’ 能匹配 “verb” 中的 ‘er’,但不能匹配 “never” 中的 ‘er’。 |
| \cx | 匹配由 x 指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 ‘c’ 字符。 |
| \d | 匹配一个数字字符。等价于 [0-9]。 |
| \D | 匹配一个非数字字符。等价于 [^0-9]。 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL。 |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \t | 匹配一个制表符。等价于 \x09 和 \cI。 |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
| \w | 匹配字母、数字、下划线。等价于’[A-Za-z0-9_]’。 |
| \W | 匹配非字母、数字、下划线。等价于 ‘[^A-Za-z0-9_]’。 |
| \xn | 匹配 n,其中 n 为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,’\x41’ 匹配 “A”。’\x041’ 则等价于 ‘\x04’ & “1”。正则表达式中可以使用 ASCII 编码。 |
| \num | 匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。例如,’(.)\1’ 匹配两个连续的相同字符。 |
| \n | 标识一个八进制转义值或一个向后引用。如果 \n 之前至少 n 个获取的子表达式,则 n 为向后引用。否则,如果 n 为八进制数字 (0-7),则 n 为一个八进制转义值。 |
| \nm | 标识一个八进制转义值或一个向后引用。如果 \nm 之前至少有 nm 个获得子表达式,则 nm 为向后引用。如果 \nm 之前至少有 n 个获取,则 n 为一个后跟文字 m 的向后引用。如果前面的条件都不满足,若 n 和 m 均为八进制数字 (0-7),则 \nm 将匹配八进制转义值 nm。 |
| \nml | 如果 n 为八进制数字 (0-3),且 m 和 l 均为八进制数字 (0-7),则匹配八进制转义值 nml。 |
| \un | 匹配 n,其中 n 是一个用四个十六进制数字表示的 Unicode 字符。例如, \u00A9 匹配版权符号 (?)。 |
转自原地址。表中已经列的挺详细了。那么在Java中我们应该如何使用呢,这里我就一些比较常用的再举例说明一下:
2.直接通过字符串方法去使用
目前String类支持正则的方法有以下几种:
.replaceAll() 替换全部
.replaceFirst() 替换第一个
.split() 将字符串劈分成数组
.matches() 判断字符串是否与给定的模式匹配
下面我顺便带着一些常用的元字符,一一举例:
@Test
public void test2(){
// . 一个 . 代表一个任意符号,所以四个点匹配四个
System.out.println("a4^-".matches("....")); //true 此句表示匹配四个任意字符
// - 表示范围 如 a-z 0-9
// [] 字符集 匹配里面包含的任意字符 如 [0-9]匹配从0-9之间任意数字一个
System.out.println("h".matches("a-z")); //false 此句直接写表示并列 a 或 - 或 z
System.out.println("h".matches("[a-z]")); //true 表示[] 内的字符任意一个
// ^ $ 表示开头和结尾
System.out.println("a4^-".matches("^....$")); //true
// * 取值长度范围 表示0个到多个 {0,} 属于量词
System.out.println("a4^-".matches(".*")); //true 此句表示匹配任意长度任意符号
// + 取值长度范围 表示0个到多个 {1,} 属于量词
System.out.println("123".matches("[0-9]+")); //true 此句表示最少匹配一个数字
System.out.println("abc".matches("[0-9]+")); //false
// ? 取值长度范围 表示0个到多个 {0,1} 属于量词
System.out.println("8".matches("[0-9]?")); //true 此句表示 匹配 0 个或者 1 个数字
System.out.println("88".matches("[0-9]?")); //false 两个,超出范围
// {m,n} 取值长度范围 m个到n个
System.out.println("12345".matches("[0-9]{4,8}")); // true表示数字长度在4-8之间
System.out.println("123".matches("[0-9]{4,8}")); // False 不在范围内
// \d 数字 与[0-9]相同
// \D 非数字
System.out.println("123".matches("\\d+")); //true 注意这里用两个\\是因为在Java中单个\是转义符
System.out.println("abc".matches("\\D+")); //true
//举例: 判断字符串中有没有数字
System.out.println("zdjghj9jd".matches(".*\\d+.*"));//true 前后.*是因为我们不确定前后字符数量
// | 或 前后跟要匹配的字符
//举例说明:判断字符串是不是以
System.out.println("123".matches("[0-9]+|[a-z]+")); //true
System.out.println("abc".matches("[0-9]+|[a-z]+")); //true
System.out.println("abc123".matches("[0-9]+|[a-z]+")); //false
// ^ 注意,放在字符集里面表示取反
System.out.println("abc".matches("[0-9]+")); //false
System.out.println("abc".matches("[^0-9]+")); //true 与\D+相同
// () 分组操作
System.out.println("food".matches("(f|z).*")); //true
System.out.println("zood".matches("(f|z).*")); //true
System.out.println("hood".matches("(f|z).*")); //false
//另外,需要记住汉字的格式 \u4e00-\u9fa5
//举例:判断字符串中有没有汉字
System.out.println("abhhj会更好hu".matches(".*[\\u4e00-\\u9fa5]+.*")); //true
}
上面的例子我都用了matches做例子,下面我再简单对另外三种方法举例:
@Test
public void test3() {
//split()
//举例:将下面字符串按数字劈分成数组,不保留数字
String s = "abc123hello6world101java";
String[] ss = s.split("\\d+");
System.out.println(Arrays.toString(ss)); //[abc, hello, world, java]
//replaceAll() 替换所有的
//举例:替换字符串中所有的连续数字为"java"
String s1 = "hello123c++456world789python";
System.out.println(s1.replaceAll("[\\d]+","java")); //hellojavac++javaworldjavapython
//replaceFirst() 替换第一个
String s2 = "javajavajava";
System.out.println(s2.replaceFirst("java","hello")); //hellojavajava
}
3.通过Pattern和Matcher类去使用
对于Java来说,使用正则肯定离不开类,我们一般用的多的就是Pattern和Matcher,通过这两个类我们可以很方便的去使用正则表达式。
他的一般使用格式如下:
@Test
public void test4() {
String s = "123abc";
Pattern p = Pattern.compile("[0-9a-z]+"); //编译一个正则
Pattern p2 = Pattern.compile("[0-9a-z]+", Pattern.CASE_INSENSITIVE); //编译一个正则 第二个参数表示不区分大小写
Matcher m = p.matcher(s); //传入一个字符串与正则进行匹配,结果存放在Matcher对象中,我们可以通过其方法去操作这个结果
}
其中若Pattern编译时传入第二个参数,则相当于我们指定了修饰符。可供我们选择的有(内容来自API文档):
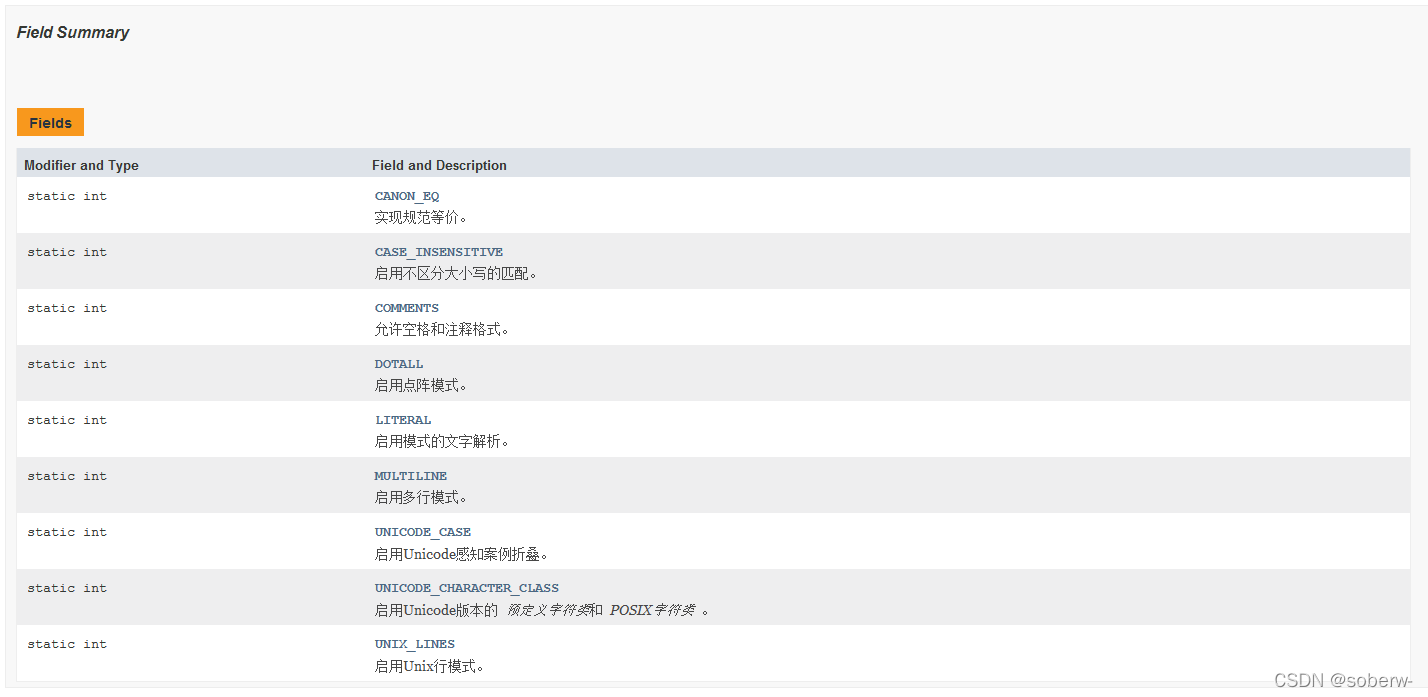
那么我们在通过Matcher类拿到结果后,其也给我们提供了一些方法供我们去使用,常用的有一下几种:
matches() 尝试将整个区域与模式进行匹配。
find() 尝试找到匹配模式的输入序列的下一个子序列。
group() 返回与上一个匹配匹配的输入子序列。
其中find()方法常与group()连用,下面一一举例使用:
@Test
public void test5() {
//matches() 尝试将整个输入序列与模式进行匹配
//例子:判断字符串是否存在数字,用法与String的matches()类似
String s = "abd56jgh";
Pattern p = Pattern.compile(".*\\d.*");
Matcher m = p.matcher(s);
System.out.println(m.matches()); //true
//find() 与 group()
//举例:在字符串中找到所有的连续字母并输出
String s1 = "123java%&^hello687*&^email _python";
Pattern p1 = Pattern.compile("[a-z]+", Pattern.CASE_INSENSITIVE);
Matcher m1 = p1.matcher(s1);
while (m1.find()) {
System.out.println(m1.group());
// java
// hello
// email
// python
}
}
4.贪婪模式与禁用贪婪
何谓贪婪模式呢?简单来说就是我们在匹配字符串的时候,尽可能的按照最大长度去匹配。一般默认的就是贪婪模式,比如我有这样一个字符串:
@Test
public void test6() {
//举例:筛选出<div></div>标签内包含的内容
String s = "<div>hello</div><html>hello</html><div>hello 15</div>";
Pattern p = Pattern.compile("<div>(.*)</div>");
Matcher m = p.matcher(s);
while(m.find()){
System.out.printf("%s\t",m.group(1));
// hello</div><html>hello</html><div>hello 15
}
}
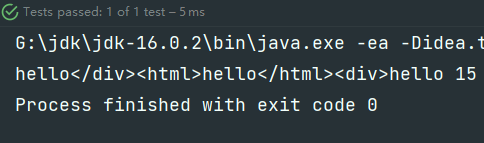
可以看到,程序直接把最外层的div截取了,可是这不是我们想要的,我们想要的是把里面的每一个小的div都截取出来。这是因为程序默认按照贪婪模式来走的,就是能截取大的,不截取小的。
那么如何禁用贪婪模式呢?
所谓禁用贪婪模式,就是非贪婪模式,有的地方也叫懒惰模式。但他所表达的意思都一样,就是能截取小的,不截取大的。
那么如何实现?我们还以上面例子举例:
@Test
public void test6() {
//举例:筛选出<div></div>标签内包含的内容
String s = "<div>hello</div><html>hello</html><div>hello 15</div>";
Pattern p = Pattern.compile("<div>(.*)</div>"); //贪婪模式
Matcher m = p.matcher(s);
while(m.find()){
System.out.printf("%s\t",m.group(1));
// hello</div><html>hello</html><div>hello 15
}
System.out.println();
Pattern p1 = Pattern.compile("<div>(.*?)</div>"); //禁用贪婪模式
Matcher m1 = p1.matcher(s);
while(m1.find()){
System.out.println(m1.group(1));
//hello
//hello 15
}
}
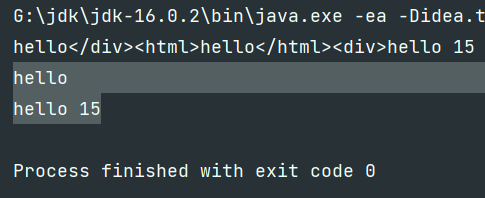
很简单,在想要匹配的长度后面加上?,就能禁用贪婪
注意:
?一定要加在量词后面,否则?表示的含义是{0,1}
5.利与弊
正则真的就如此万能吗?既然正则使用起来如此方便,那是不是以后在处理所有的有关字符串问题时,都优先考虑正则呢?
显然不是。
实际上随着系统的日益更新,有时候使用正则反而会拖慢我们程序的运行速度,像.*这种贪婪匹配符号很容易造成大量的回溯,性能有时候会有上百万倍的下降。
那么我们究竟应该在哪些情况下去使用呢?
我们知道,正则是给我们划定一个模式,我们可以通过这个模式去匹配字符串。比如我们想搜索一个姓名,我们只知道他姓李,叫啥不知道,这时候当然是使用正则方便,但如果我们明确的知道这个人叫“李四”,那通过indexOf()岂不是更方便一些吗?还不容易出错。
而且正则在有些情境下也不是很适用,比如我想判断一个人的年龄是不是在18~30岁之间,这通过正则就很麻烦了。
简而言之,正则只是给我们提供一种解决问题的思路,让我们在某些情境下可以出奇的高效,我们大可不必过度使用。具体问题还要具体分析。
本文仅发表个人看法,如有纰漏还请评论区指正。大家一起探讨学习。
浅谈Java正则表达式的更多相关文章
- 浅谈Java的throw与throws
转载:http://blog.csdn.net/luoweifu/article/details/10721543 我进行了一些加工,不是本人原创但比原博主要更完善~ 浅谈Java异常 以前虽然知道一 ...
- 浅谈Java中的equals和==(转)
浅谈Java中的equals和== 在初学Java时,可能会经常碰到下面的代码: 1 String str1 = new String("hello"); 2 String str ...
- 浅谈Java中的对象和引用
浅谈Java中的对象和对象引用 在Java中,有一组名词经常一起出现,它们就是“对象和对象引用”,很多朋友在初学Java的时候可能经常会混淆这2个概念,觉得它们是一回事,事实上则不然.今天我们就来一起 ...
- 浅谈Java中的equals和==
浅谈Java中的equals和== 在初学Java时,可能会经常碰到下面的代码: String str1 = new String("hello"); String str2 = ...
- 浅谈JAVA集合框架
浅谈JAVA集合框架 Java提供了数种持有对象的方式,包括语言内置的Array,还有就是utilities中提供的容器类(container classes),又称群集类(collection cl ...
- 浅谈java性能分析
浅谈java性能分析,效能分析 在老师强烈的要求下做了效能分析,对上次写过的词频统计的程序进行分析以及改进. 对于效能分析:我个人很浅显的认为就是程序的运行效率,代码的执行效率等等. java做性能测 ...
- 浅谈Java中的深拷贝和浅拷贝(转载)
浅谈Java中的深拷贝和浅拷贝(转载) 原文链接: http://blog.csdn.net/tounaobun/article/details/8491392 假如说你想复制一个简单变量.很简单: ...
- !! 浅谈Java学习方法和后期面试技巧
浅谈Java学习方法和后期面试技巧 昨天查看3303回复33 部落用户大酋长 下面简单列举一下大家学习java的一个系统知识点的一些介绍 一.java基础部分:java基础的时候,有些知识点是非常重要 ...
- 浅谈Java中的深拷贝和浅拷贝
转载: 浅谈Java中的深拷贝和浅拷贝 假如说你想复制一个简单变量.很简单: int apples = 5; int pears = apples; 不仅仅是int类型,其它七种原始数据类型(bool ...
随机推荐
- 2.HTML5基本标签
一.标题标签 h1-->h6 h1最大 h6最小 <body> <h1>一级标题</h1> <h2>二级标题</h2> ...
- rsync配置文件讲解
1.安装rysnc 一般在安装系统时rsync是安装上(yum安装) 2. vim /etc/xinetd.d/rsync 在这个路径下有配置文件 service rsync { disabl ...
- float类型数据精度问题:12.0f-11.9f=0.10000038,"减不尽"为什么?
现在我们就详细剖析一下浮点型运算为什么会造成精度丢失? 1.小数的二进制表示问题 首先我们要搞清楚下面两个问题: (1) 十进制整数如何转化为二进制数 算法很简单.举个例子,11表示成二进制数: 1 ...
- 苹果系统 的 qq浏览器 和 qq内置浏览器 无法使用 websocket 的 妥协方案
没错,就是用不了,js脚本不执行,更别说服务器运行 onopen函数了!!! 怎么办...搞了一天,仍然找不到连接的方法!!! 幸运的是仅仅苹果系统 的无法使用 ,安卓的却可以,奇了怪了 哈皮 ,那我 ...
- Go语言系列之性能调优
在计算机性能调试领域里,profiling 是指对应用程序的画像,画像就是应用程序使用 CPU 和内存的情况. Go语言是一个对性能特别看重的语言,因此语言中自带了 profiling 的库,这篇文章 ...
- FastDFSJava客户端使用
1.1.java客户端 余庆先生提供了一个Java客户端,但是作为一个C程序员,写的java代码可想而知.而且已经很久不维护了. 这里推荐一个开源的FastDFS客户端,支持最新的SpringBoot ...
- Metasploit生成木马入侵安卓手机
开始 首先你需要一个Metasploit(废话) Linux: sudo apt install metasploit-framework Termux: 看这里 指令 sudo su //生成木马文 ...
- 【练习】rust中的复制语义和移动语义
1.基本类型都是复制语义的 fn main(){ let a = 123; { #[allow(unused_variables)] let b = a; //如果是移动语义,那么后续的a将不再有效 ...
- golang中使用kafka客户端sarama消费时需要注意的一个点
kafka消费者的Consume()方法会阻塞: 当Consume()方法返回err时,不确定继续消费有没有问题:保险起见,退出进程,然后重新初始化. 当Consume()方法返回nil是,是可以继续 ...
- manjaro20安装teamviewer出现sudo teamviewer –daemon start无响应
问题 https://www.randomhacks.co.uk/the-teamviewer-daemon-is-not-running-please-start-the-daemon-ubuntu ...