Python练习1-文档格式化成html
文档格式化成HTML
把文档格式化成了THML,并没有处理所有thml规则,只是处理了一部分,功能不重要,重要的是复习熟悉下Python对文档的处理细节。毕竟Python大多数给我的印象都是处理文档。代码里有很多逻辑可能不严谨,这里再次强调只是为了复习字符串以及文档操作。
同时提醒一下,如果运行失败,请删除注释,我是用vs2015编写的,返现当时中文注释导致编码错误运行失败。一共四个文档:

入口文档是markup.py。
参数 python markup.py < xxx.txt > xxx.html
执行效果和代码如下:
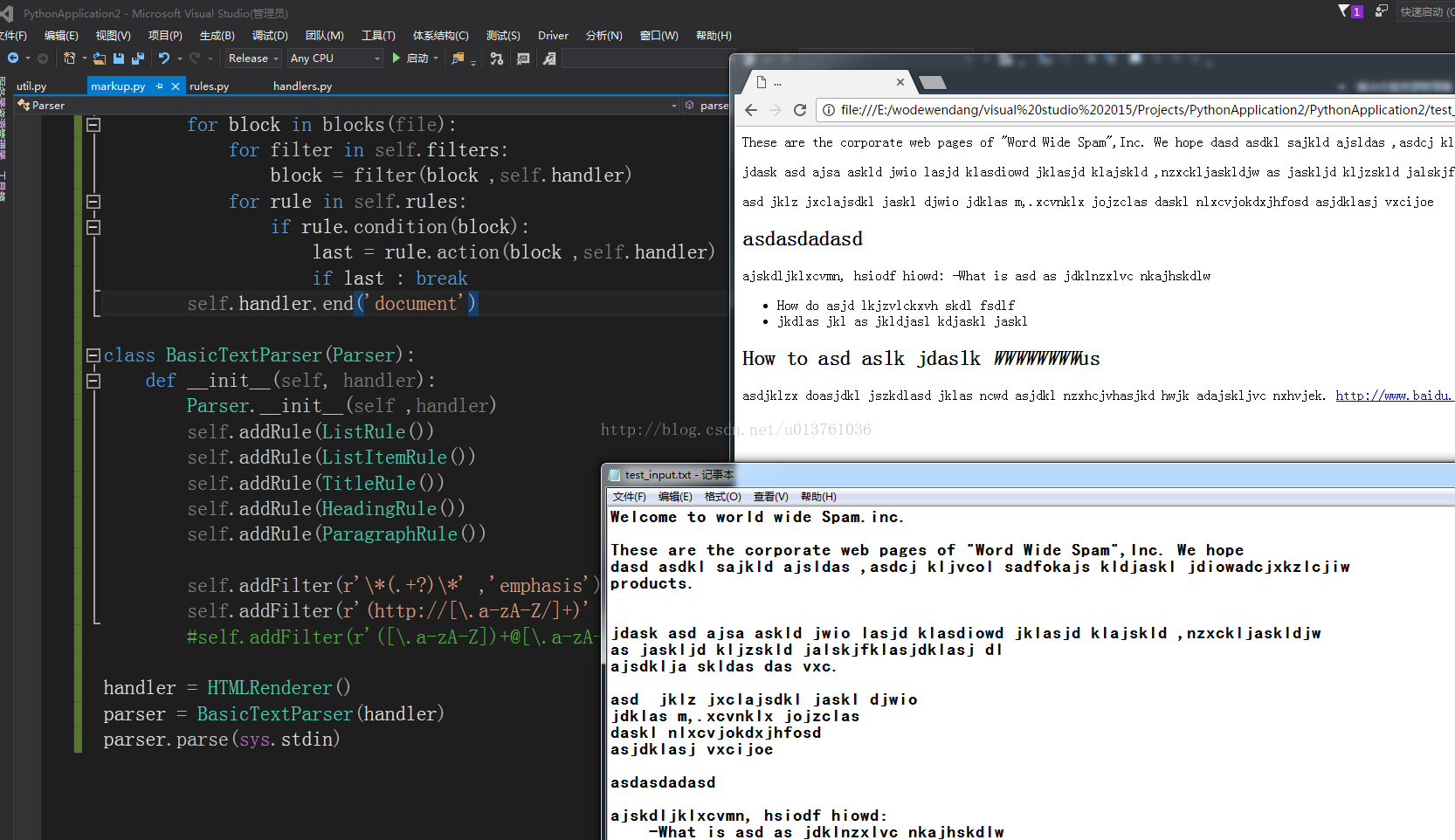
Util.py
def lines(file):
for line in file:yield line
yield '\n'
def blocks(file):
block = []
for line in lines(file):
if line.strip(): #'\n','\r','\t',' '
block.append(line);
elif block:
yield ''.join(block).strip()
block = []
Handlers.py
class Handler:
"""
处理从Parser调用的方法的对象。
这个解析器会在每个块的开始部分调用start()和end()方法,使用合适的
块名作为参数,sub()方法会用于正则表达式替换中。当使用了'emphasis'
这样的名字调用时,它会返回合适的替换函数。
"""
def callback(self ,prefix ,name ,*args):
method = getattr(self ,prefix + name ,None)
if callable(method) : return method(*agrs)
def start(self ,name):
self.callback('start_',name);
def end(self ,name):
self.callback('end_',name);
def sub(self ,name):
def substitution(match):
result = self.callback('sub_' ,name ,match)
if result is None: match.group(0)
return result
return substitution
class HTMLRenderer(Handler):
"""
用于生成HTML的具体处理程序
THMLRenderer内容的方法都是可以通过超类处理程序的start()、
end()和sub()方法来访问。他们实现了用于HTRML文档的基本标签。
"""
def start_document(self):
print('<html><head><title>...</title></head><body>')
def end_document(self):
print('</body></html>')
def start_paragraph(self):
print('<p>')
def end_paragraph(self):
print('</p>')
def start_heading(self):
print('<h2>')
def end_heading(self):
print('</h2>')
def start_list(self):
print('<ul>')
def end_list(self):
print('</ul>')
def start_listitem(self):
print('<li>')
def end_listitem(self):
print('</li>')
def start_title(self):
print('<title>')
def end_title(self):
print('</title>')
def sub_emphasis(self ,match):
return ('<em>%s</em>' % match.group(1))
def sub_url(self ,match):
return ('<a href = "%s">%s</a>' % (match.group(1),match.group(1)))
def sub_mail(self ,match):
return ('<a href="mailto:%s">%s</a>' % (match.group(1),match.group(1)))
def feed(self ,data):
print(data)
Rules.py
class Rule:
"""
所有规则的基类。
"""
def action(self ,block ,handler):
handler.start(self.type)
handler.feed(block)
handler.end(self.type)
return True
class HeadingRule(Rule):
"""
标题占一行,最多70个字符,并且不以冒号结尾。
"""
type = 'heading'
def condition(self ,block):
return not '\n' in block and len(block) <= 70 and not block[-1] == ':'
class TitleRule(HeadingRule):
"""
题目是文档的第一个块,但前提它是大标题。
"""
type = 'title'
first = True
def condition(self, block):
if not self.first:return False
self.first = HeadingRule.condition(self ,block)
class ListItemRule(Rule):
"""
列表项是以连字符开始的段落。作为格式化的一部分,要移除连字符。
"""
type = 'listitem'
def condition(self ,block):
return block[0] == '-'
def action(self, block, handler):
handler.start(self.type)
handler.feed(block[1:].strip())
handler.end(self.type)
return True
class ListRule(ListItemRule):
"""
列表从不是列表项的块和岁以后的列表项之间。在最后一个连续的列表项之后结束。
"""
type = 'list'
inside = False
def condition(self ,block):
return True
def action(self, block, handler):
if not self.inside and ListItemRule.condition(self ,block):
handler.start(self.type)
self.inside = True
elif self.inside and not ListItemRule.condition(self ,block):
handler.end(self.type)
self.inside = False
return False
class ParagraphRule(Rule):
"""
段落只是其他规则并没有覆盖到的块
"""
type = 'paragraph'
def condition(self ,block):
return TrueMarkup.py
import sys,re
from handlers import *
from util import *
from rules import *
class Parser:
#"""
#语法分析器读取文本文件、应用规则并且控制处理程序
# """
def __init__(self ,handler):
self.handler = handler
self.rules = []
self.filters = []
def addRule(self ,rule):
self.rules.append(rule)
def addFilter(self ,pattern ,name):
def filter(bolck ,handler):
return re.sub(pattern ,handler.sub(name),bolck)
self.filters.append(filter)
def parse(self ,file):
self.handler.start('document')
for block in blocks(file):
for filter in self.filters:
block = filter(block ,self.handler)
for rule in self.rules:
if rule.condition(block):
last = rule.action(block ,self.handler)
if last : break
self.handler.end('document')
class BasicTextParser(Parser):
"""
在构造函数中添加规则和过滤器的具体语法分析器
"""
def __init__(self, handler):
Parser.__init__(self ,handler)
self.addRule(ListRule)
self.addRule(ListItemRule)
self.addRule(TitleRule)
self.addRule(HeadingRule)
self.addRule(ParagraphRule)
self.addFilter(r'\*(.+?)\*' ,'emphasis')
self.addFilter(r'(http://[\.a-zA-Z/]+)' ,'url')
self.addFilter(r'([\.a-zA-Z])+@[\.a-zA-Z]+[a-zA-Z]+)' ,'mail')
handler = HTMLRenderer()
parser = BasicTextParser(handler)
parser.parse(sys.stdin)Python练习1-文档格式化成html的更多相关文章
- Python之word文档模板套用 - 真正的模板格式套用
Python之word文档模板套用: 1 ''' 2 #word模板套用2:套用模板 3 ''' 4 5 #导入所需库 6 from docx import Document 7 ''' 8 #另存w ...
- Python中定义文档字符串__doc__需要注意格式对齐的处理
Python中的文档字符串是个很不错的提升代码交付质量.编写文档方便的特征,但是需要注意在使用文档字符串时,将文档字符串标识的引号对必须遵守缩进的规则,否则Python语法检查时会无法通过,而引号内的 ...
- Python处理Excel文档(xlrd, xlwt, xlutils)
简介 xlrd,xlwt和xlutils是用Python处理Excel文档(*.xls)的高效率工具.其中,xlrd只能读取xls,xlwt只能新建xls(不可以修改),xlutils能将xlrd.B ...
- 【好文翻译】一步一步教你使用Spire.Doc转换Word文档格式
背景: 年11月,微软宣布作为ECMA国际主要合作伙伴,将其开发的基于XML的文件格式标准化,称之为"Office Open XML" .Open XML的引进使office文档结 ...
- python 解析docx文档的方法,以及利用Python从docx文档提取插入的文本对象和图片
首先安装docx模块,通过pip install docx或者在docx官方链接上下载安装都可以 下面来看下如何解析docx文档:文档格式如下 有3个部分组成 1 正文:text文档 2 一个表格. ...
- 【转】Python之xml文档及配置文件处理(ElementTree模块、ConfigParser模块)
[转]Python之xml文档及配置文件处理(ElementTree模块.ConfigParser模块) 本节内容 前言 XML处理模块 ConfigParser/configparser模块 总结 ...
- python操作docx文档(转)
python操作docx文档 关于python操作docx格式文档,我用到了两个python包,一个便是python-docx包,另一个便是python-docx-template;,同时我也用到了很 ...
- python实用小技能分享,教你如何使用 Python 将 pdf 文档进行 加密 解密
上次说了怎么将word转换为pdf格式 及 实现批量将word转换为pdf格式(点击这里),这次我又get到一个新技能–使用 Python 将 pdf 文档进行 加密 解密,哈哈哈 希望帮到更多人! ...
- Python中的文档字符串作用
文档字符串是使用一对三个单引号 ''' 或者一对三个双引号 """来包围且没有赋值给变量的一段文字说明(如果是单行且本身不含引号,也可以是单引号和双引号), 它在代码执行 ...
随机推荐
- CF1149C Tree Generator™
一.题目 点此看题 二.解法 话说老师给的课件是错的啊,把我坑了好久,我手玩样例才玩出来,最后只能去看洛谷题解了. 本题是树是用一个括号序列给出的,你要知道的是:( 代表递归下去到一个新节点,) 表示 ...
- List的主要实现类
//ArrayList:List的主要实现类 /* * List中相对于Collection,新增加的方法 * void add(int index, Object ele):在指定的索引位置inde ...
- Matplotlib图例中文乱码
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签 plt.rcParams['axes.unicode_minus']=False #用来正 ...
- 2019第十届蓝桥杯省赛及国赛个人总结(java-B组)
省赛: 今年省赛的题目比18年简单的多,基本都是暴力枚举.BFS之类.还记得去年在山师考蓝桥杯,我这种辣鸡连题目都没看懂.本以为蓝桥会变得越来越难,没想到今年就被打脸了.今年省赛后面三个编程大题一个没 ...
- 「免费开源」基于Vue和Quasar的前端SPA项目crudapi后台管理系统实战之自定义组件(四)
基于Vue和Quasar的前端SPA项目实战之序列号(四) 回顾 通过上一篇文章 基于Vue和Quasar的前端SPA项目实战之布局菜单(三)的介绍,我们已经完成了布局菜单,本文主要介绍序列号功能的实 ...
- (二)SpringBoot启动过程的分析-环境信息准备
-- 以下内容均基于2.1.8.RELEASE版本 由上一篇SpringBoot基本启动过程的分析可以发现在run方法内部启动SpringBoot应用时采用多个步骤来实现,本文记录启动的第二个环节:环 ...
- Spring与Mybatis整合配置
Mybatis核心配置文件: 配置文件内可以不写内容 <?xml version="1.0" encoding="UTF-8" ?> <!DO ...
- Hibernate的Dao层通用设计
hibernate作为一款优秀的数据库持久化框架,在现实的运用中是非常广泛的.它的出现让不熟悉sql语法的程序员能开发数据库连接层成为一种可能,但是理想与现实永远是有差距的.开发过程中如果只使用hql ...
- Android Studio详解项目中的资源
•目录结构 •作用 所有以 drawable 开头的文件都是用来放图片的: 所有以 mipmap 开头的文件都是用来放应用图标的: 所有以 value 开头的文件夹都是用来放字符串.样式.颜色等配置的 ...
- Android Studio 如何在TextView中设置图标并按需调整图标大小
•任务 相信大家对这张图片都不陌生,没错,就是 QQ动态 向我们展示的界面. 如何实现呢? •添加文字并放入图标 新建一个 Activity,取名为 QQ,Android Studio 自动为我们生成 ...