通过helm部署EFK收集应用日志,ingress-nginx日志解析。
前段时间看了马哥的k8s新书,最后几章讲了下EFK,尝试部署了下,很多问题, 这里改进下,写个笔记记录下吧。
准备工作
所有组件都通过helm3部署,选添加几个仓库。
helm repo add bitnami https://charts.bitnami.com/bitnami
helm repo add fluent https://fluent.github.io/helm-charts
存储用的nfs的sc,自行解决。
三个4G内存工作节点的k8s集群。
部署es
[root@bjzb-lecar-ops-jenkins-master-33 cluster-log]# cat bitnami-elasticsearch-values.yaml
clusterDomain: cluster.local # Kubernetes集群域名;
name: elasticsearch # Elasticsearch集群名称; master: # 准主节点相关的配置;
name: master
replicas: 2 # 实例数量;
heapSize: 512m # 堆内存大小;
resources:
limits: {}
# cpu: 1000m
# memory: 2048Mi
requests:
cpu: 200m
memory: 512Mi
persistence: # 持久卷相关的配置;
enabled: true # 禁用时将自动使用emptyDir存储卷;
storageClass: "managed-nfs-storage" # 从指定存储类中动态创建PV;
# existingClaim: my-persistent-volume-claim # 使用现有的PVC;
# existingVolume: my-persistent-volume # 使用现有的PV;
accessModes:
- ReadWriteOnce
size: 8Gi
service: # 服务配置
type: ClusterIP
port: 9300 # 节点间的transport流量使用端口; coordinating: # 仅协调节点相关的配置;
replicas: 2 # 实例数量;
heapSize: 128m
resources:
requests:
cpu: 250m
memory: 512Mi
service: # 仅协调节点相关的服务,这也是接收Elasticsearch客户端请求的入口;
type: ClusterIP
port: 9200
# nodePort:
# loadBalancerIP: data: # 数据节点相关的配置;
name: data
replicas: 2
heapSize: 512m
resources: # 数据节点是CPU密集及IO密集型的应用,资源需求和限制要谨慎设定;
limits: {}
# cpu: 100m
# memory: 2176Mi
requests:
cpu: 250m
memory: 512Mi
persistence:
enabled: true
storageClass: "managed-nfs-storage"
# existingClaim: my-persistent-volume-claim
# existingVolume: my-persistent-volume
accessModes:
- ReadWriteOnce
size: 10Gi ingest: # 摄取节点相关的配置;
enabled: false # 默认为禁用状态;
name: ingest
replicas: 2
heapSize: 128m
resources:
limits: {}
# cpu: 100m
# memory: 384Mi
requests:
cpu: 500m
memory: 512Mi
service:
type: ClusterIP
port: 9300 curator: # curator相关的配置;
enabled: false
name: curator
cronjob: # 执行周期及相关的配置;
# At 01:00 every day
schedule: "0 1 * * *"
concurrencyPolicy: ""
failedJobsHistoryLimit: ""
successfulJobsHistoryLimit: ""
jobRestartPolicy: Never metrics: # 用于暴露指标的exporter;
enabled: true
name: metrics
service:
type: ClusterIP
annotations: # 指标采集相关的注解信息;
prometheus.io/scrape: "true"
prometheus.io/port: "9114"
resources:
limits: {}
# cpu: 100m
# memory: 128Mi
requests:
cpu: 100m
memory: 128Mi
podAnnotations: # Pod上的注解,用于支持指标采集;
prometheus.io/scrape: "true"
prometheus.io/port: "8080"
serviceMonitor: # Service监控相关的配置
enabled: false
namespace: monitoring
interval: 10s
scrapeTimeout: 10s
helm install es -f bitnami-elasticsearch-values.yaml bitnami/elasticsearch -n logging
哎,这一步各种问题,会遇到镜像下载慢,k8s集群资源不够(我已经把yml里申请的资源调的很低了),存储权限问题,反正大家注意点就行。
部署fluent-bit
[root@bj-k8s-master efk]# cat fluent-fluent-bit-values.yaml
# kind -- DaemonSet or Deployment
kind: DaemonSet image:
repository: fluent/fluent-bit
pullPolicy: IfNotPresent service:
type: ClusterIP
port: 2020
annotations:
prometheus.io/path: "/api/v1/metrics/prometheus"
prometheus.io/port: "2020"
prometheus.io/scrape: "true" resources: {}
# limits:
# cpu: 100m
# memory: 128Mi
#requests:
# cpu: 100m
# memory: 128Mi tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule config:
service: |
[SERVICE]
Flush 3
Daemon Off
#Log_Level info
Log_Level debug
Parsers_File custom_parsers.conf
Parsers_File parsers.conf
HTTP_Server On
HTTP_Listen 0.0.0.0
HTTP_Port 2020 inputs: |
[INPUT]
Name tail
Path /var/log/containers/*.log
Parser docker
Tag kube.*
Mem_Buf_Limit 5MB
Skip_Long_Lines On
Refresh_Interval 10
[INPUT]
Name tail
Path /var/log/containers/nginx-demo*.log
Parser docker
Tag nginx-demo.*
Mem_Buf_Limit 5MB
Skip_Long_Lines On
Refresh_Interval 10
[INPUT]
Name tail
Path /var/log/containers/ingress-nginx-controller*.log
Parser docker
Tag ingress-nginx-controller.*
Mem_Buf_Limit 5MB
Skip_Long_Lines On
Refresh_Interval 10 filters: |
[FILTER]
Name kubernetes
Match kube.*
Kube_URL https://kubernetes.default.svc:443
Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token
Kube_Tag_Prefix kube.var.log.containers.
Merge_Log On
Keep_Log Off
K8S-Logging.Exclude On
K8S-Logging.Parser On
[FILTER]
Name kubernetes
Match ingress-nginx-controller.*
Kube_URL https://kubernetes.default.svc:443
Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token
Kube_Tag_Prefix kube.var.log.containers.
Merge_Log On
Merge_Parser ingress-nginx
Keep_Log Off
K8S-Logging.Exclude On
K8S-Logging.Parser On outputs: |
[OUTPUT]
Name es
Match kube.*
Host es-elasticsearch-coordinating-only.logging.svc.cluster.local.
Logstash_Format On
Logstash_Prefix k8s-cluster
Type flb_type
Replace_Dots On [OUTPUT]
Name es
Match nginx-demo.*
Host es-elasticsearch-coordinating-only.logging.svc.cluster.local.
Logstash_Format On
Logstash_Prefix nginx-demo
Type flb_type
Replace_Dots On
[OUTPUT]
Name es
Match ingress-nginx-controller.*
Host es-elasticsearch-coordinating-only.logging.svc.cluster.local.
Logstash_Format On
Logstash_Prefix ingress-nginx-controller
Type flb_type
Replace_Dots On customParsers: |
[PARSER]
Name docker_no_time
Format json
Time_Keep Off
Time_Key time
Time_Format %Y-%m-%dT%H:%M:%S.%L [PARSER]
Name ingress-nginx
Format regex
Regex ^(?<message>(?<remote>[^ ]*) - (?<user>[^ ]*) \[(?<time>[^\]]*)\] "(?<method>\S+)(?: +(?<path>[^\"]*?)(?: +\S*)?)?" (?<code>[^ ]*) (?<size>[^ ]*) "(?<referer>[^\"]*)" "(?<agent>[^\"]*)" (?<request_length>[^ ]*) (?<request_time>[^ ]*) \[(?<proxy_upstream_name>[^ ]*)\] \[(?<proxy_alternative_upstream_name>[^ ]*)\] (?<upstream_addr>[^ ]*) (?<upstream_response_length>[^ ]*) (?<upstream_response_time>[^ ]*) (?<upstream_status>[^ ]*) (?<req_id>[^ ]*).*)$
Time_Key time
Time_Format %d/%b/%Y:%H:%M:%S %z
helm install fb -f fluent-fluent-bit-values.yaml fluent/fluent-bit -n logging
注意下es的host地址,如果跟我不是一样的namespace记得改下,吃过亏。这个书里提供的都写一个index里,nginx-ingress日志也不解析,fluent-bit研究了半天,大概就这程度吧,通过docker不同的log名字打上tag,这样每个应用在es里单独的index。当然量不大都写进一个index,通过label字段查询某应用的日志也行。
部署kibana
[root@bj-k8s-master efk]# cat bitnami-kibana-values.yaml
replicaCount: 1 updateStrategy:
type: RollingUpdate plugins:
- https://github.com/pjhampton/kibana-prometheus-exporter/releases/download/7.8.1/kibana-prometheus-exporter-7.8.1.zip persistence:
enabled: true
storageClass: "managed-nfs-storage"
# existingClaim: your-claim
accessMode: ReadWriteOnce
size: 10Gi service:
port: 5601
type: ClusterIP
# nodePort:
externalTrafficPolicy: Cluster
annotations: {}
# loadBalancerIP:
# extraPorts: ingress:
enabled: true
certManager: false
annotations:
kubernetes.io/ingress.class: nginx
hostname: kibana.ilinux.io
path: /
tls: false
# tlsHosts:
# - www.kibana.local
# - kibana.local
# tlsSecret: kibana.local-tls configuration:
server:
basePath: ""
rewriteBasePath: false metrics:
enabled: true
service:
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "80"
prometheus.io/path: "_prometheus/metrics" serviceMonitor:
enabled: false
# namespace: monitoring
# interval: 10s
# scrapeTimeout: 10s
# selector:
# prometheus: my-prometheus elasticsearch:
hosts:
- es-elasticsearch-coordinating-only.logging.svc.cluster.local.
# - elasticsearch-2
port: 9200
helm install kib -f bitnami-kibana-values.yaml bitnami/kibana -n logging
同上如果跟我namespace不一样记得改下es地址。 这地方书里有坑,把charts pull下来看了下,values.yml文件有出入,估计是写书的时候chart版本不一样导致的。
配置kibana
自己改下hosts解析到ingress地址,访问kibana
添加匹配的索引
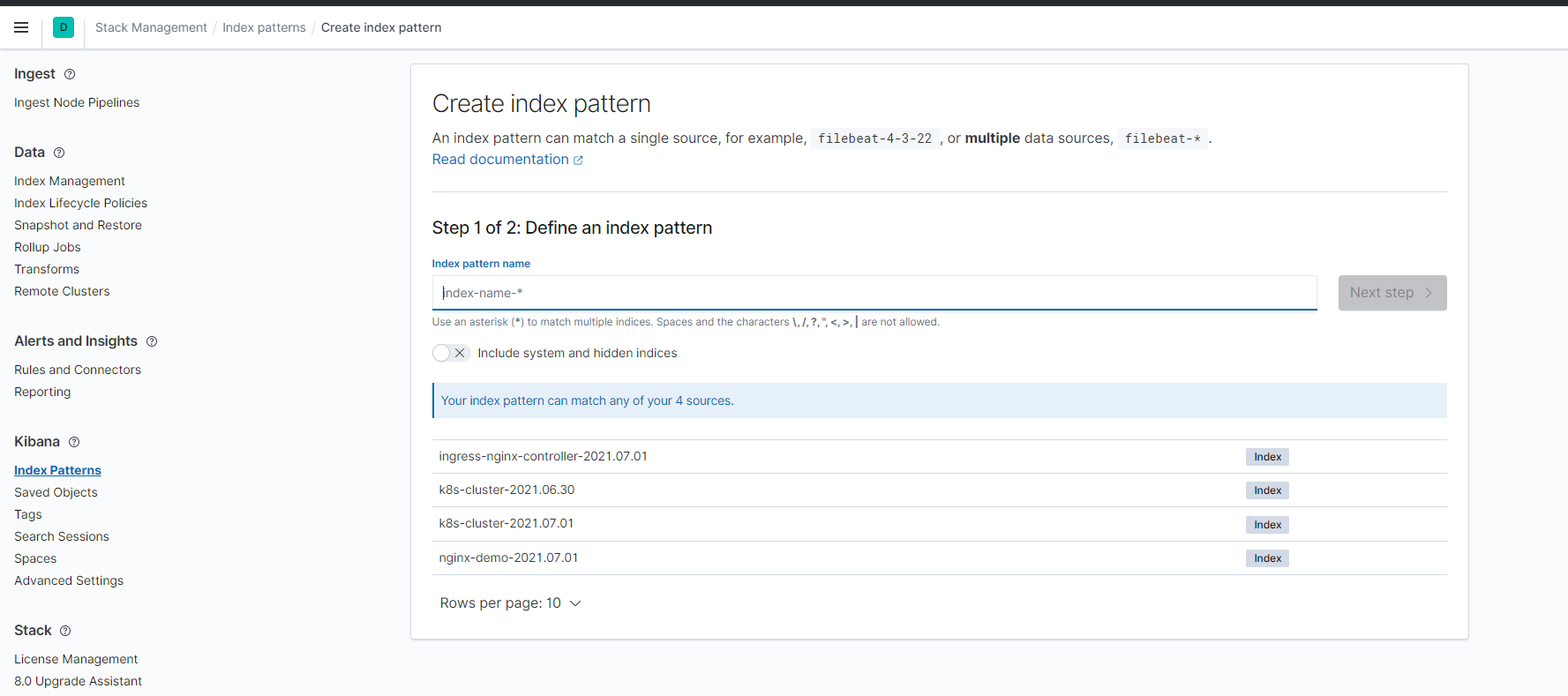
每个应用日志独立的index
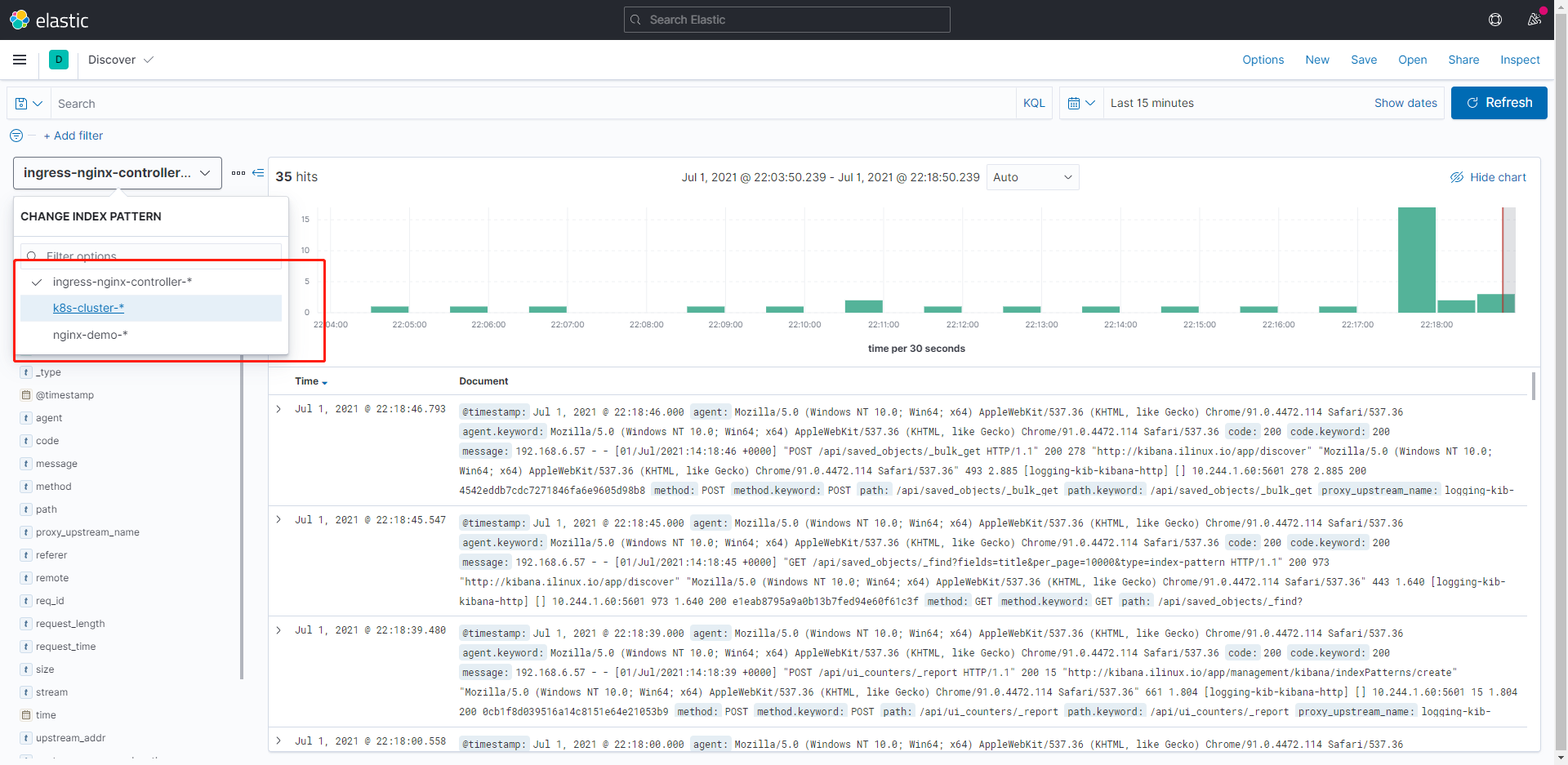
ingress-nginx日志已解析
fluentbit官方文档
https://docs.fluentbit.io/
在线正则匹配
https://rubular.com/
通过helm部署EFK收集应用日志,ingress-nginx日志解析。的更多相关文章
- Nginx访问日志、 Nginx日志切割、静态文件不记录日志和过期时间
1.Nginx访问日志 配制访问日志:默认定义格式: log_format combined_realip '$remote_addr $http_x_forwarded_for [$time_loc ...
- rsyslog服务器同步其他服务器上面应用日志(如mysql审计日志 、nginx日志)
**环境说明**系统:ubuntu 14.04 (CentOS可以参考http://www.cnblogs.com/hanyifeng/p/5463338.html) rsyslog版本 :8.16. ...
- Linux centosVMware Nginx访问日志、Nginx日志切割、静态文件不记录日志和过期时间
一.Nginx访问日志 vim /usr/local/nginx/conf/nginx.conf //搜索log_format 日至格式 改为davery格式 $remote_addr 客户端IP ...
- nginx日志、nginx日志切割、静态文件不记录日志和过期时间
2019独角兽企业重金招聘Python工程师标准>>> 12.10 Nginx访问日志 日志格式 vim /usr/local/nginx/conf/nginx.conf //搜索l ...
- elk 日志收集 filebeat 集群搭建 php业务服务日志 nginx日志 json 7.12版本 ELK 解决方案
难的不是技术,难的是业务.熟悉业务流程才是最难的. 其实搜索进来的每一个人的需求不一样,希望你能从我的这篇文章里面收获到. 建议还是看官方文档,更全面一些. 一.背景 1,收集nginx acces ...
- 第七章·Logstash深入-收集NGINX日志
1.NGINX安装配置 源码安装nginx 因为资源问题,我们先将nginx安装在Logstash所在机器 #安装nginx依赖包 [root@elkstack03 ~]# yum install - ...
- 利用ELK分析Nginx日志生产实战(高清多图)
本文以api.mingongge.com.cn域名为测试对象进行统计,日志为crm.mingongge.com.cn和risk.mingongge.com.cn请求之和(此二者域名不具生产换环境统计意 ...
- 利用ELK分析Nginx日志
本文以api.mingongge.com.cn域名为测试对象进行统计,日志为crm.mingongge.com.cn和risk.mingongge.com.cn请求之和(此二者域名不具生产换环境统计意 ...
- elk系列3之通过json格式采集Nginx日志
preface 公司采用的LNMP平台,跑着挺多nginx,所以可以利用elk好好分析nginx的日志.下面就聊聊它吧. 下面的所有操作都在linux-node2上操作 安装Nginx nginx是开 ...
随机推荐
- CocoaPods 构建自己的 Pod 库
构建一个自己的库供其它人使用是不是一件很酷(苦)的事情,通过CocoaPods 可以快捷的构建自己库,并向全世界分享你的成果 一.创建 Podspec 有两种方式: 使用命令 pod lib crea ...
- [c++] 常犯错误
更改变量值时想清楚对后面程序的影响 scnaf & == 数组下标从0开始 不赋初值导致的垃圾数据 全局flag和局部flag
- 寻找CPU使用率高的进程方法
寻找CPU使用率高的进程方法 发布时间: 2017-07-13 浏览次数: 1362 下载次数: 0 问题描述 节点报CPU使用率高,甚至出现"ALM-12016 CPU使用率超过阈值 ...
- CentOS 7网络配置
修改配置文件 CentOS 7下的网络配置文件路径为:/etc/sysconfig/network-scripts/ifcfg-interfacename 配置文件ifcfg-interface-na ...
- redis 基本操作命令
redis 基本操作 String 操作字符串 1 SET key value 设置指定 key 的值 2 GET key 获取指定 key 的值. 3 GETRANGE key start ...
- UEFI和Legacy兼容启动U盘制作
应用场景 自己有一个可启动移动硬盘,是属于老式的BIOS启动方式,最近换了新电脑,因为电脑只支持uefi的启动方式,所以决心为移动硬盘增加uefi启动支持,如何将一个只支持BIOS启动(或者 Lega ...
- VirtualBox安装配置CentOS7(含网络连接配置)
最近需要用到CentOS7,特地在虚拟机上安装一遍,中间走了很多弯路,特地在此处进行记录 前置条件: 1.本地完成Oracle VM VirtualBox,我安装的是6.1版本 2.下载CentOS安 ...
- .NET Core HttpClient请求异常详细情况分析
前言 最近项目上每天间断性捕获到HttpClient请求异常,感觉有点奇怪,于是乎观察了两三天,通过日志以及对接方沟通确认等等,查看对应版本源码,尝试添加部分配置发布后,观察十几小时暂无异常情况出现, ...
- js--手动实现一个常见的短信验证码输入框
前言 本文记录一下自己手动实现的一个前端常见的短信验证码输入组件,从需求到实现逐步优化的过程. 正文 1.需求分析 首先看一下效果图. 首先页面加载的时候,输入框获取焦点,当用户输入一个数字后,焦点自 ...
- Go语言网络通信---连续通信的UDP编程
Server: package main import ( "fmt" "net" ) func main() { //创建udp地址 udpAddr, _ : ...