易车网实战+【保姆级】:Feapder爬虫框架入门教程
今天辰哥带大家来看看一个爬虫框架:Feapder,看完本文之后,别再说你不会Feapder了。本文辰哥将带你了解什么是Feapder?、如何去创建一个Feapder入门项目(实战:采集易车网轿车数据)。
其中实战部分包括爬虫数据和存储到Mysql数据库,让大家能够感受一下,数据从网页经框架Feapder采集后,直接存储到数据库的过程。
之前我们已经用了Scrapy爬虫框架来爬取数据(以『B站』为实战案例!手把手教你掌握爬虫必备框架『Scrapy』),今天来试试使用Feapder写爬虫是一种怎么样的体验,请往下看!!!!!
01、Feapder框架
1.Feapder框架介绍
Feapder 是一款上手简单、功能强大、快速、轻量级的爬虫框架的Python爬虫框架。支持轻量爬虫、分布式爬虫、批次爬虫、爬虫集成,以及完善的爬虫报警机制。
具体feapder项目结构每一块的功能是什么?怎么样用?接着往下看,下面的实战中有详细的讲解。
2.Feapder的安装
feapder的安装很简单,通过下面的命令安装即可!
pip install feapder
出现下面的界面说明feapder成功安装!

feapder的介绍和环境安装就完成了,下面开始真正去使用fepader来爬取易车网数据,并存储到mysql数据库。
02、实战
1.新建feapder项目
通过下方的命令去创建一个名为:chenge_yc_spider的的爬虫项目
feapder create -p chenge_yc_spider

创建好之后,我们看一下项目结构

2.编写爬虫
在终端中进入到项目(chenge_yc_spider)下的spiders文件夹下,通过下面的命令创建一个目标爬虫文件(target_spider)
feapder create -s target_spider

此刻项目结构如下:

编辑target_spider.py文件
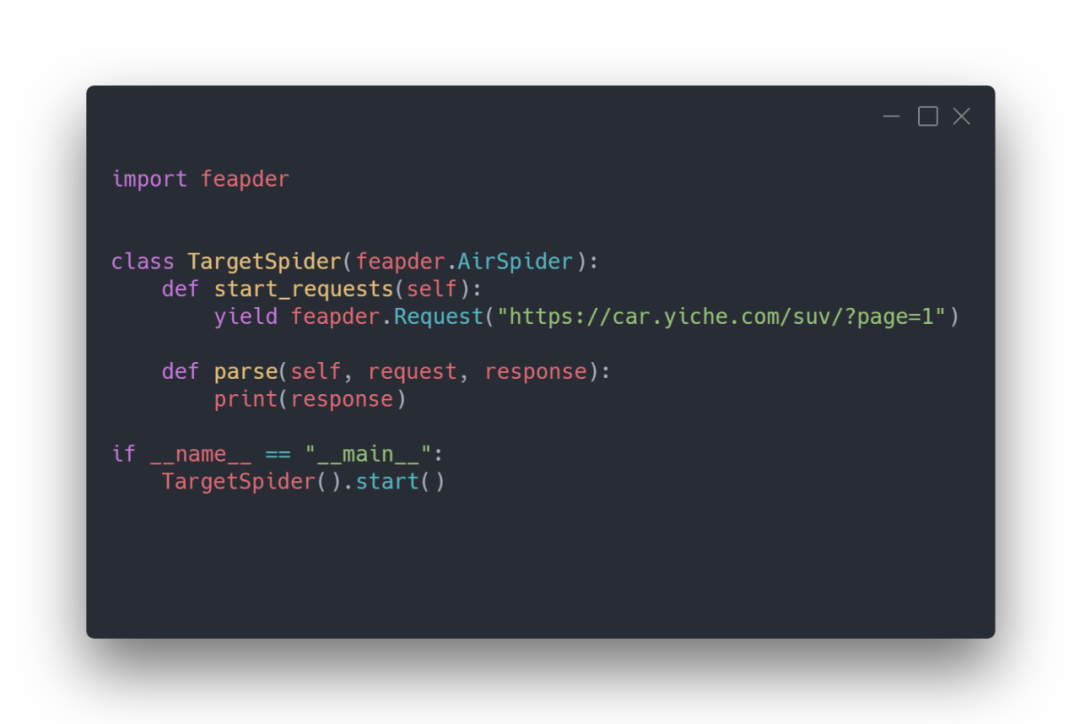
这里实战案例:采集易车网数据。直接执行这个py文件,先看一下请求有没有没问题。
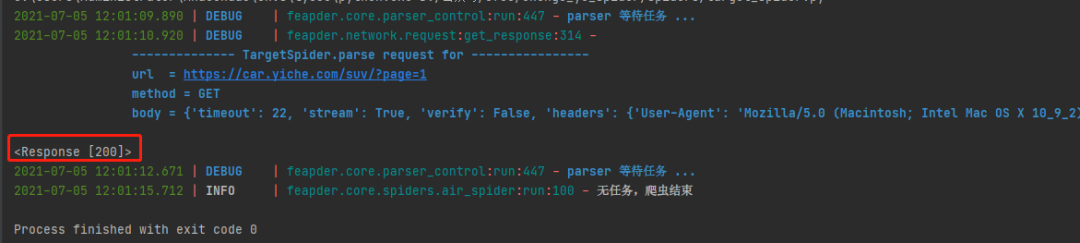
可以看到请求返回响应200,说明请求成功。下一步我们开始解析网页数据并设置爬虫框架自动采集下一页数据。
3.解析网页
网页结果(待采集的数据)如下:

通过查看源代码,分析数据所对应的网页标签
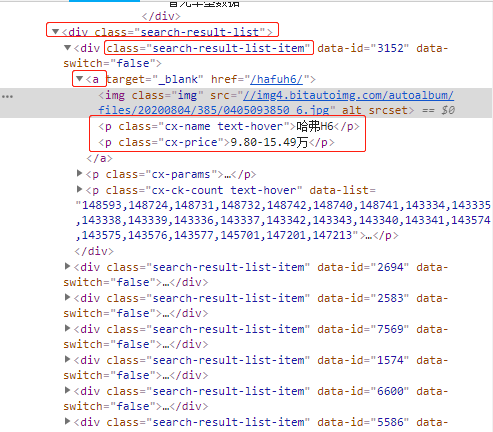
通过网页源码可以分析,汽车列表数据都是在class为search-result-list下。每一个class为search-result-list-item表示一条数据,每一条数据下都有汽车对应的属性(如:汽车名称、价格等)
这里仅作为实战案例去学习feapder爬虫框架,因此这里就只爬取汽车名称、价格;这两个字段属性。
4.创建Mysql数据库
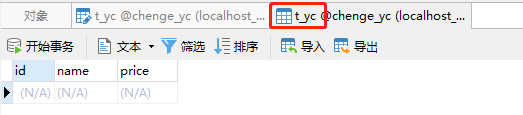
采集的数据需要存储到数据库(mysql)中,因此我们先来定义好数据库和表
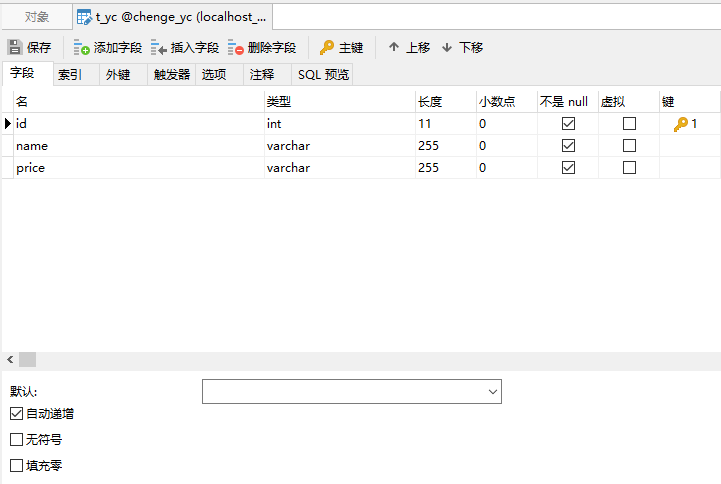
这里辰哥创建了一个数据库:chenge_yc,并在里面建了应该表:t_yc,其表结构如上图,这里如果不不熟悉mysql如何建立数据库表的可以参考辰哥的这篇文章(实战|教你用Python玩转Mysql)
在爬虫项目中配置数据库,打开根目录下的setting.py文件
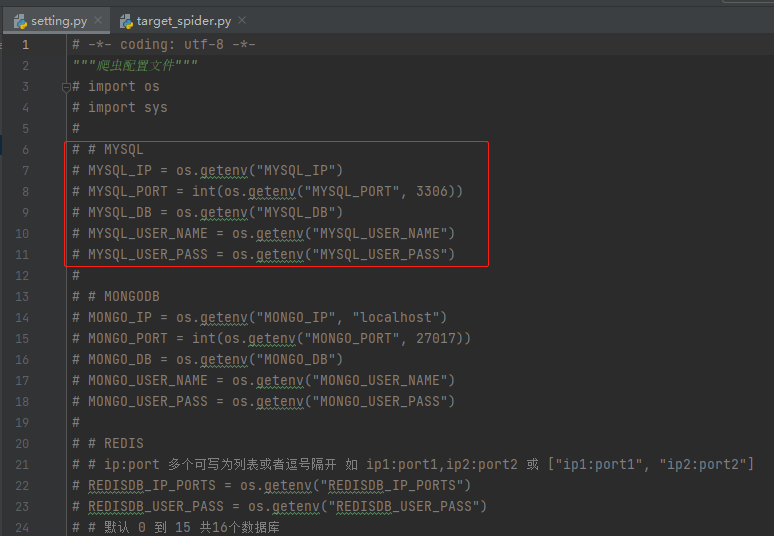
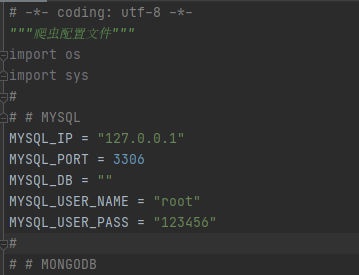
可以看到feapder支持多种数据库的对接,咱们这里使用的是mysql,其配置如下:
接着在终端下,进入到根目录下的items文件夹,执行下面命令生成数据库表对于的item
feapder create -i t_yc

请注意:命令中的t_yc是对于数据库表中的t_yc
最后生成 t_yc_item.py 文件:
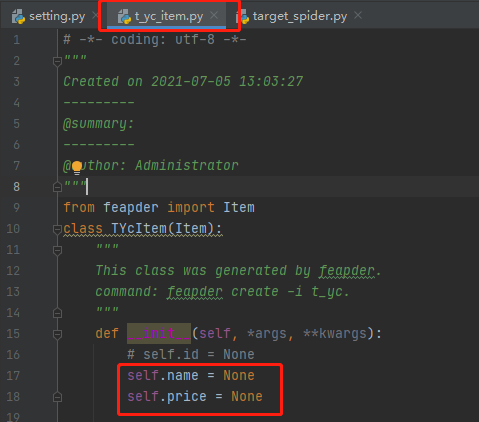
里面的name和price则是对应数据库中的字段。
5.提取网页字段
上面已经获取到网页源码,也知道数据所在的标签,现在开始编写代码进行解析。

执行结果:

可以看到数据已经成功提出来,下一步将这些数据存储到数据库中。
6.存储到数据库
import feapder
引入刚刚的 t_yc_item.py,并创建对象TycItem。把爬取的name和price初始化到对象中。最后yieId TycItem,实际上就直接存储到数据库了(因为数据库表和item是对应连接关系,这样就直接存储到数据库了)。
这太方便了,连sql语句都省了,6666666666
执行结果如下:

查看数据库:
同样可以看到数据直接就存储到数据库中。大功告成!!!!!!
03、小结
相信看到这里的你已经完完全全掌握了 爬虫框架: Feapder ,你不仅知道了什么是feapder,同时还学会了如何使用feapder。
此外实战部分包括 爬虫数据和存储到Mysql数据库,让大家能够感受一下,数据从网页经框架Feapder采集后,直接存储到数据库的过程。
一定要 动手尝试 ! 一定要 动手尝试 ! 一定要 动手尝试!
易车网实战+【保姆级】:Feapder爬虫框架入门教程的更多相关文章
- scrapy爬虫框架入门教程
scrapy安装请参考:安装指南. 我们将使用开放目录项目(dmoz)作为抓取的例子. 这篇入门教程将引导你完成如下任务: 创建一个新的Scrapy项目 定义提取的Item 写一个Spider用来爬行 ...
- Python爬虫框架Scrapy教程(1)—入门
最近实验室的项目中有一个需求是这样的,需要爬取若干个(数目不小)网站发布的文章元数据(标题.时间.正文等).问题是这些网站都很老旧和小众,当然也不可能遵守 Microdata 这类标准.这时候所有网页 ...
- CodeIgniter框架入门教程——第一课 Hello World!
本文转载自:http://www.softeng.cn/?p=45 今天开始,我将在这里连载由我自己编写的<CodeIgniter框架入门教程>,首先,这篇教程的读着应该是有PHP基础的编 ...
- Java - Struts框架教程 Hibernate框架教程 Spring框架入门教程(新版) sping mvc spring boot spring cloud Mybatis
https://www.zhihu.com/question/21142149 http://how2j.cn/k/hibernate/hibernate-tutorial/31.html?tid=6 ...
- Go-Micro框架入门教程(一)---框架结构
Go语言微服务系列文章,使用golang实现微服务,这里选用的是go-micro框架,本文主要是对该框架的一个架构简单介绍. 1. 概述 go-micro是go语言下的一个很好的微服务框架. 1.服务 ...
- 『Scrapy』爬虫框架入门
框架结构 引擎:处于中央位置协调工作的模块 spiders:生成需求url直接处理响应的单元 调度器:生成url队列(包括去重等) 下载器:直接和互联网打交道的单元 管道:持久化存储的单元 框架安装 ...
- 【python】Scrapy爬虫框架入门
说明: 本文主要学习Scrapy框架入门,介绍如何使用Scrapy框架爬取页面信息. 项目案例:爬取腾讯招聘页面 https://hr.tencent.com/position.php?&st ...
- [Python] Scrapy爬虫框架入门
说明: 本文主要学习Scrapy框架入门,介绍如何使用Scrapy框架爬取页面信息. 项目案例:爬取腾讯招聘页面 https://hr.tencent.com/position.php?&st ...
- Scrapy 框架 入门教程
Scrapy入门教程 在本篇教程中,我已经安装好Scrapy 本篇教程中将带您完成下列任务: 创建一个Scrapy项目 定义提取的Item 编写爬取网站的 spider 并提取 Item 编写 Ite ...
随机推荐
- [DB] mysql windows 安装
参考 mysql安装 https://www.cnblogs.com/zhangkanghui/p/9613844.html navicat for mysql 中文破解版(无需激活码) https: ...
- 小米华为vivooppo手机记录隐私证据查询
1.在拨号界面输入:*#*#4636#*#* 2.在输入代码之后 手机会自动跳转到下面这个页面 就可以查看她到底拿着手机在干嘛 2 输入下面代码可以检测小米手机的各种信息 *#*#64663#*#*
- 凯撒密码Caesar
//@132屋里上课群 #include<stdio.h>#include<stdlib.h>//颜色using namespace std;int jiami();int j ...
- 。 (有些情况下通过 lsof(8) 或 fuser(1) 可以 找到有关使用该设备的进程的有用信息)
umount时目标忙解决办法 标签(空格分隔): ceph ceph运维 osd 在删除osd后umount时,始终无法umonut,可以通过fuser查看设备被哪个进程占用,之后杀死进程,就可以顺利 ...
- Linux中级之负载均衡(lvs,nginx,haproxy)、中间件
一.负载均衡的概念 1.系统的扩展方式: scale up:向上扩展 scale out:向外扩展 2.集群类型: LB(Load Balancing).HA(high availability) ...
- windows server 2008 rdp停止服务 - windows server 2012 R2 远程桌面授权模式尚未配置,远程桌面服务将在120天内停止工作
目录 问题现象 增长rdp服务可使用时长的配置 Via & reference: 问题现象 windows server 2008作为测试环境跳板机,但是没有配置官方的rdp授权,限制用户登录 ...
- SpringMVC学习笔记-REST风格请求实现
RESTful概念及功能 RESTful的概念:RESTful是 一种资源定位及资源操作的风格,其本身既不是标准也不是协议,而是一种设计风格,可以使得软件整体层次更加分明.代码更加简洁,并且有利于实现 ...
- Amazon SageMaker和NVIDIA NGC加速AI和ML工作流
Amazon SageMaker和NVIDIA NGC加速AI和ML工作流 从自动驾驶汽车到药物发现,人工智能正成为主流,并迅速渗透到每个行业.但是,开发和部署AI应用程序是一项具有挑战性的工作.该过 ...
- NVIDIA GPU的神经网络自动调度
NVIDIA GPU的神经网络自动调度 针对特定设备和工作负载的自动调整对于获得最佳性能至关重要.这是一个关于如何使用自动调度器为NVIDIA GPU调整整个神经网络的资料. 为了自动调整一个神经网络 ...
- 【译】.NET 5 中的诊断改进
基于我们在 .NET Core 3.0 中引入的诊断改进,我们一直在努力进一步改进这个领域.我很高兴介绍下一波诊断改进. 诊断工具不再需要 .NET SDK 直到最近,.NET 诊断工具套件还只能作为 ...