常见内部排序算法对比分析及C++ 实现代码
内部排序是指在排序期间数据元素全部存放在内存的排序。外部排序是指在排序期间全部元素的个数过多,不能同时存放在内存,必须根据排序过程的要求,不断在内存和外存之间移动的排序。本次主要介绍常见的内部排序算法。
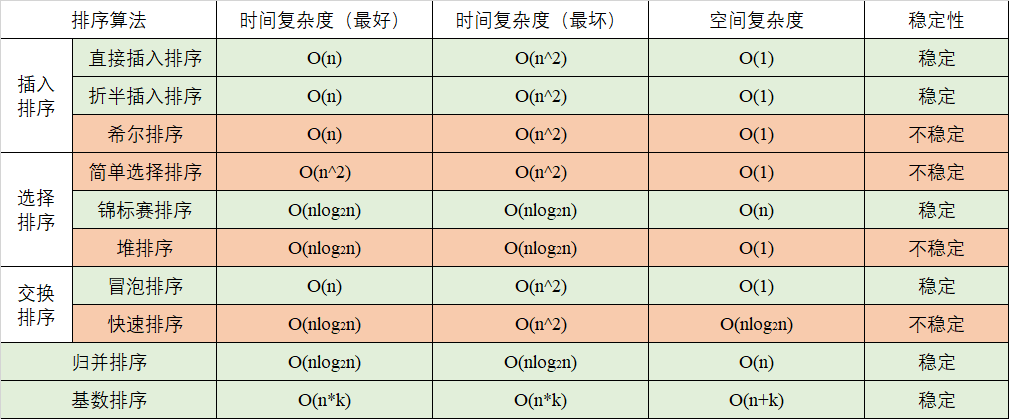
1. 直接插入排序
直接插入排序的算法思想是把待排序序列a[n]中的n个元素看作是一个有序表和无序表。开始时有序表中只包含第一个元素a[0],无序表中包含n-1个元素a[1]~a[n-1],排序过程中每次从无序表中拿出第一个元素,把它插入有序表的适当位置,使之成为新的有序表,有序表中的元素个数加1。这样经过n-1次插入后,无序表变成空表,有序表中包含了全部n个元素,排序完毕。直接插入排序算法的实现代码如下:
void DirectInsertSort(vector<int>& arr)
{
int i, j;
for (i = 1; i < arr.size(); i++)
{
if (arr[i] < arr[i - 1]) //判断是否需要重新排序,否则保留原位置
{
int temp = arr[i]; //待插入元素
for (j = i - 1; j >= 0 && temp < arr[j]; j--) arr[j + 1] = arr[j]; //逆序寻找插入位置,同时将大于待插入元素右移
arr[j + 1] = temp;
}
}
}
2. 折半插入排序
折半插入排序也称二分法排序,其算法思想是设数据表中有一个元素序列a[0],a[1],...,a[n-1]。其中,a[0],a[1],...,a[i-1]已经排好序。在插入a[i]时,利用折半查找寻找在有序表a[0]~a[i-1]内a[i]的插入位置。折半插入排序算法的实现代码如下:
void BinaryInsertSort(vector<int>& arr)
{
int i, j, low, high, mid;
for (i = 1; i < arr.size() - 1; i++) //逐渐扩大有序表
{
int temp = arr[i];
low = 0, high = i - 1;
while (low <= high) //利用二分查找寻找插入位置
{
mid = (low + high) / 2;
if (temp < arr[mid])
{
high = mid - 1; //小于中间值区间向左缩小
}
else
low = mid + 1; //否则区间向右缩小
}
for (j = i - 1; j >= low; j--) arr[j + 1] = arr[j]; //将大于待插入元素右移
arr[low] = temp;
}
}
3. 希尔排序
希尔排序也称缩小增量排序,其算法思想是设待排序元素序列有n个元素,首先取一个整数gap<n作为间隔,将全部元素分为gap个子序列,所有距离为gap的元素放入同一个子序列中,对每个子序列分别进行直接插入排序。然后缩小gap,如gap取gap/2.重复上述子序列的划分和排序操作,直到gap取1,将所有元素放在同一个子序列中为止。希尔排序算法的实现代码如下:
void InsertSort_gap(vector<int>& arr, int start, int gap)
{
int i, j, temp;
for (i = start + gap; i <= arr.size() - 1; i = i + gap)
{
if (arr[i - gap] > arr[i]) //存在逆序
{
temp = arr[i]; //在有序表中寻找插入位置
j = i;
do {
arr[j] = arr[j - gap]; //间隔为gap反向做排序码的比较
j = j - gap;
} while (j - gap > 0 && arr[j - gap] > temp);
arr[j] = temp;
}
}
} void ShellSort(vector<int>& arr, int d[], int m)
{ //对arr中的元素进行希尔排序,d[]中存放增量,m为d[]大小
int i, start, gap;
for (i = m - 1; i >= 0; i--)
{
gap = d[i];
for (start = 0; start < gap; start++)
{
InsertSort_gap(arr, start, gap);
} //直到gap = d[0] = 1时停止迭代
}
}
4. 简单选择排序
简单选择排序也称直接选择排序,其主要算法思想是设待排序元素序列有n个元素,第一趟排序从待排序序列中选取排序码最小的元素,若它不是第一个元素,则与待排序序列的第一个元素交换,并将它从待排序序列中删除,第二趟排序从剩下的待排序序列中再次选取排序码最小的元素,重复上述过程,总共通过n-1趟排序,得到一个有序序列。简单选择排序算法的实现代码如下:
void SelectSort(vector<int>& arr)
{
int i, j, k, temp;
for (i = 0; i < arr.size() - 1; i++)
{
k = i; //在[i]~[n-1]中记录当前排序码最小的元素
for (j = i + 1; j <= arr.size() - 1; j++) //查找实际具有最小排序码的元素
{
if (arr[j] < arr[k]) k = j;
}
if (k != i)
{
temp = arr[i];
arr[i] = arr[k]; //将实际具有最小排序码的元素和当前最小排序码的元素交换
arr[k] = temp;
}
}
}
5. 锦标赛排序
锦标赛排序是一种树形选择排序,按照锦标赛的思想进行选择排序,其算法思想是首先对n个元素的排序码进行两两比较,得到n/2个优胜者(排序码较小者),作为第一步比较的结果保留下来,然后对这n/2个元素再进行两两比较。如此重复,直至选出具有最小排序码的元素为止。这个过程可以用一棵含有n个叶子结点的完全二叉树表示。底层相当于完全二叉树的叶节点,他们存放的是所有参加排序元素的排序码。非叶子节点存放的是叶子结点排序码进行两两比较后优胜者的叶节点编号。最顶层是树的根,存放的是最后选出的具有最小排序码的元素所在叶节点编号,这种树称为胜者树。锦标赛排序算法的实现代码如下:
vector<node> BuildTree(vector<int>& arr, int len)
{
int nodes = 1;
while (nodes < len) nodes <<= 1;
int treeSize = nodes * 2 + 1;
vector<node> trees;
for (int i = nodes - 1; i < treeSize; i++)
{
int index = i - (nodes - 1);
if (index < len) trees[i] = node(arr[index], i);
else trees[i] = node(MAX, -1);
}
for (int i = nodes - 2; i >= 0; i--)
{
if (trees[i * 2 + 1].val < trees[i * 2 + 2].val) trees[i] = trees[i * 2 + 1];
else trees[i] = trees[i * 2 + 2];
}
return trees;
} void Adjust(vector<node>& tree, int index)
{
while (index != 0)
{
if (index % 2 == 1)
{
if (tree[index].val < tree[index + 1].val) tree[(index - 1) / 2] = tree[index];
else tree[(index - 1) / 2] = tree[index + 1];
index = (index - 1) / 2;
}
else
{
if (tree[index - 1].val < tree[index].val) tree[index / 2 - 1] = tree[index - 1];
else tree[index / 2 - 1] = tree[index];
index = index / 2 - 1;
}
}
} void TournamentSort(vector<node>& tree, int len)
{
int dataLen = len / 2 + 1;
vector<int> data;
for (int i = 0; i < dataLen; i++)
{
data[i] = tree[0].val;
tree[tree[0].index].val = MAX;
Adjust(tree, tree[0].index);
}
}
6. 堆排序
堆排序的基本思想是:1、将带排序的序列构造成一个大顶堆,根据大顶堆的性质,当前堆的根节点(堆顶)就是序列中最大的元素;2、将堆顶元素和最后一个元素交换,然后将剩下的节点重新构造成一个大顶堆;3、重复步骤2,如此反复,从第一次构建大顶堆开始,每一次构建,我们都能获得一个序列的最大值,然后把它放到大顶堆的尾部。最后,就得到一个有序的序列了。堆排序算法的实现代码如下:
void Swap(vector<int>& arr, int i, int j)
{
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
} void AdjustHeap(vector<int>& arr, int i, int len)
{
int left = 2 * i + 1, right = 2 * i + 2, MaxIndex = i; //默认当前节点(父节点)是最大值。
if (left < len && arr[left] > arr[MaxIndex]) MaxIndex = left; //如果有左节点,并且左节点的值更大,更新最大值的索引
if (right < len && arr[right] > arr[MaxIndex]) MaxIndex = right; //如果有右节点,并且右节点的值更大,更新最大值的索引
if (MaxIndex != i)
{
Swap(arr, i, MaxIndex); //如果最大值不是当前非叶子节点的值,那么就把当前节点和最大值的子节点值互换
AdjustHeap(arr, MaxIndex, len); //因为互换之后,子节点的值变了,如果该子节点也有自己的子节点,仍需要再次调整
}
} void BuildMaxHeap(vector<int>& arr, int len)
{
for (int i = floor(len / 2) - 1; i >= 0; i--)
{ //从最后一个非叶节点开始向前遍历,调整节点性质,使之成为大顶堆
AdjustHeap(arr, i, len);
}
} void HeapSort(vector<int>& arr)
{
int len = arr.size();
BuildMaxHeap(arr, len); //构建大顶堆,这里其实就是把待排序序列,变成一个大顶堆结构的数组
for (int i = len - 1; i > 0; i--) //交换堆顶和当前末尾的节点,重置大顶堆
{
Swap(arr, 0, i);
len--;
AdjustHeap(arr, 0, len);
}
}
7. 冒泡排序
冒泡排序算法思想是比较相邻的元素,如果第一个比第二个大,就交换他们两个。对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对。所以,最后的元素应该会是最大的数。针对所有的元素重复以上的步骤,除了最后一个。持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。冒泡排序算法的实现代码如下:
void BubbleSort(vector<int>& arr)
{
int flag, i, j, temp;
for (i = 0; i < arr.size() - 1; i++)
{
flag = 0;
for (j = 0; j < arr.size() - i - 1; j++)
{
if (arr[j] > arr[j + 1])
{
Swap(arr, j, j + 1);
flag = 1;
}
}
if (!flag) return; //如果后面不存在逆序,则不用再循环判断
}
}
8. 快速排序
快速排序的基本思想是通过一趟排序将要排序的数据分割成独立的两部分:分割点左边都是比它小的数,右边都是比它大的数。然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。快速排序算法的实现代码如下:
int Partition(vector<int>& arr, int low, int high)
{
int i, k = low, pivot = arr[low]; //pivot为基准元素
for (i = low + 1; i <= high; i++) //从左向右扫描,比基准小的都划分到左边
{
if (arr[i] < pivot)
{
k++;
if (k != i) Swap(arr, i, k);
}
}
arr[low] = arr[k];
arr[k] = pivot; //将基准元素移到最终位置
return k;
} void QuickSort(vector<int>& arr, int left, int right)
{
if (left < right) //迭代终止条件:序列长度小于或等于1
{
int pivotpos = Partition(arr, left, right); //一趟划分
QuickSort(arr, left, pivotpos - 1); //左子序列迭代划分
QuickSort(arr, pivotpos + 1, right); //右子序列迭代划分
}
}
9. 归并排序
归并排序是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。进而将两个有序表合并成一个有序表,也被称为二路归并。归并排序算法的实现代码如下:
void Merge(vector<int>& sourceArr, vector<int>& tempArr, int startIndex, int midIndex, int endIndex)
{
int i = startIndex, j = midIndex + 1, k = startIndex;
while (i != midIndex + 1 && j != endIndex + 1)
{
if (sourceArr[i] > sourceArr[j])
tempArr[k++] = sourceArr[j++];
else
tempArr[k++] = sourceArr[i++];
}
while (i != midIndex + 1) tempArr[k++] = sourceArr[i++];
while (j != endIndex + 1) tempArr[k++] = sourceArr[j++];
for (i = startIndex; i <= endIndex; i++) sourceArr[i] = tempArr[i];
} //内部使用递归
void MergeSort(vector<int>& sourceArr, vector<int>& tempArr, int startIndex, int endIndex)
{
int midIndex;
if (startIndex < endIndex)
{
midIndex = startIndex + (endIndex - startIndex) / 2; //避免溢出
MergeSort(sourceArr, tempArr, startIndex, midIndex);
MergeSort(sourceArr, tempArr, midIndex + 1, endIndex);
Merge(sourceArr, tempArr, startIndex, midIndex, endIndex);
}
}
10. 基数排序
基数排序是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较。由于整数也可以表达字符串(比如名字或日期)和特定格式的浮点数,所以基数排序也不是只能使用于整数。基数排序算法的实现代码如下:
int maxbit(vector<int>& data, int n) //辅助函数,求数据的最大位数
{
int maxData = data[0]; //最大数
//先求出最大数,再求其位数,这样有原先依次每个数判断其位数,稍微优化点。
for (int i = 1; i < n; ++i)
{
if (maxData < data[i]) maxData = data[i];
}
int d = 1;
int p = 10;
while (maxData >= p)
{
maxData /= 10;
++d;
}
return d;
} void RadixSort(vector<int>& data, int n)
{
int d = maxbit(data, n);
int* tmp = new int[n];
int* count = new int[10]; //计数器
int i, j, k;
int radix = 1;
for (i = 1; i <= d; i++) //进行d次排序
{
for (j = 0; j < 10; j++)
count[j] = 0; //每次分配前清空计数器
for (j = 0; j < n; j++)
{
k = (data[j] / radix) % 10; //统计每个桶中的记录数
count[k]++;
}
for (j = 1; j < 10; j++)
count[j] = count[j - 1] + count[j]; //将tmp中的位置依次分配给每个桶
for (j = n - 1; j >= 0; j--) //将所有记录依次收集到tmp中
{
k = (data[j] / radix) % 10;
tmp[count[k] - 1] = data[j];
count[k]--;
}
for (j = 0; j < n; j++) //将临时数组的内容复制到data中
data[j] = tmp[j];
radix = radix * 10;
}
}
常见内部排序算法对比分析及C++ 实现代码的更多相关文章
- 常见排序算法总结分析之选择排序与归并排序-C#实现
本篇文章对选择排序中的简单选择排序与堆排序,以及常用的归并排序做一个总结分析. 常见排序算法总结分析之交换排序与插入排序-C#实现是排序算法总结系列的首篇文章,包含了一些概念的介绍以及交换排序(冒泡与 ...
- Java几种常见的排序算法
一.所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作.排序算法,就是如何使得记录按照要求排列的方法.排序算法在很多领域得到相当地重视,尤其是在大量数据的处理方面. ...
- Java实现各种内部排序算法
数据结构中常见的内部排序算法: 插入排序:直接插入排序.折半插入排序.希尔排序 交换排序:冒泡排序.快速排序 选择排序:简单选择排序.堆排序 归并排序.基数排序.计数排序 直接插入排序: 思想:每次将 ...
- 七种常见经典排序算法总结(C++实现)
排序算法是非常常见也非常基础的算法,以至于大部分情况下它们都被集成到了语言的辅助库中.排序算法虽然已经可以很方便的使用,但是理解排序算法可以帮助我们找到解题的方向. 1. 冒泡排序 (Bubble S ...
- 常见的排序算法总结(JavaScript)
引言 排序算法是数据结构和算法之中的基本功,无论是在笔试还是面试,还是实际运用中都有着很基础的地位.这不正直七月,每年校招的备战期,所以想把常见的排序算法记录下来.在本篇文章中的排序算法使用 Java ...
- 深入浅出数据结构C语言版(17)——有关排序算法的分析
这一篇博文我们将讨论一些与排序算法有关的定理,这些定理将解释插入排序博文中提出的疑问(为什么冒泡排序与插入排序总是执行同样数量的交换操作,而选择排序不一定),同时为讲述高级排序算法做铺垫(高级排序为什 ...
- java编程之常见的排序算法
java常见的排序算法 第一种:插入排序 直接插入排序 1, 直接插入排序 (1)基本思想:在要排序的一组数中,假设前面(n-1)[n>=2] 个数已经是排 好顺序的,现在要把第n个数插到前面的 ...
- Python全栈开发之5、几种常见的排序算法以及collections模块提供的数据结构
转载请注明出处http://www.cnblogs.com/Wxtrkbc/p/5492298.html 在面试中,经常会遇到一些考排序算法的题,在这里,我就简单了列举了几种最常见的排序算法供大家学习 ...
- java讲讲几种常见的排序算法(二)
java讲讲几种常见的排序算法(二) 目录 java讲讲几种常见的排序算法(一) java讲讲几种常见的排序算法(二) 堆排序 思路:构建一个小顶堆,小顶堆就是棵二叉树,他的左右孩子均大于他的根节点( ...
随机推荐
- 解决Error running 'Tomcat 9': Address localhost:8080 is already in use的问题
在我学习servlet的过程中遇到了tomacat端口8080被占用的情况,所以记录下来,毕竟以后还会碰见这种貌似情况 第一步,打开命令行界面,可快捷键window+R打开输入cmd进入 输入代码:n ...
- TVM性能评估分析(三)
TVM性能评估分析(三) Figure 1. TVM's WebGPU backend close to native GPU performance when deploying models to ...
- pytorch生成对抗示例
pytorch生成对抗示例 本文对ML(机器学习)模型的安全漏洞的认识,并将深入了解对抗性机器学习的热门话题.图像添加难以察觉的扰动会导致模型性能大不相同.通过图像分类器上的示例探讨该主题.使用第一种 ...
- CUDA 7 流并发性优化
异构计算是指高效地使用系统中的所有处理器,包括 CPU 和 GPU .为此,应用程序必须在多个处理器上并发执行函数. CUDA 应用程序通过在 streams 中执行异步命令来管理并发性,这些命令是按 ...
- 视频系列:RTX实时射线追踪(下)
视频系列:RTX实时射线追踪(下) Key things from part 4 光线有效载荷是从一个着色器传递到另一个着色器的结构. 这一切都发生在RTX的引擎下. 更小的有效载荷要好得多! 新的D ...
- 多核片上系统(SoC)架构的嵌入式DSP软件设计
多核片上系统(SoC)架构的嵌入式DSP软件设计 Multicore a System-on-a-Chip (SoC) Architecture SoCs的软件开发涉及到基于最强大的计算模型在各种处理 ...
- 35 张图带你 MySQL 调优
这是 MySQL 基础系列的第四篇文章,之前的三篇文章见如下链接 138 张图带你 MySQL 入门 47 张图带你 MySQL 进阶!!! 炸裂!MySQL 82 张图带你飞 一般传统互联网公司很少 ...
- 远程服务调用RMI框架 演示,和底层原理解析
远程服务调用RMI框架: 是纯java写的, 只支持java服务之间的远程调用,很简单, // 接口要继承 Remote接口 public interface IHelloService extend ...
- springmvc——基于xml的异常映射和基于注解的异常映射
SpringMVC提供了基于XML和基于注解两种异常映射机制.这两种异常映射不能够只使用一个,他们需要一起使用.因为有些异常是基于注解异常映射捕获不到的. 在springmvc中,一个请求如果是由&l ...
- Java如何利用for循环在控制台输出正方形对角线图形
1 /* 2 利用循环在控制台输出如下正方形对角线图形 3 * * * * * * * * * * * 4 * * * * 5 * * * * 6 * * * * 7 * * * * 8 * * * ...