如何在 Serverless K8s 集群中低成本运行 Spark 数据计算?
作者 | 柳密 阿里巴巴阿里云智能 ** 本文整理自《Serverless 技术公开课》,关注“Serverless”公众号,回复“入门”,即可获取 Serverless 系列文章 PPT。
导读:本节课主要介绍如何在 Serverless Kubernetes 集群中低成本运行 Spark 数据计算。首先简单介绍下阿里云 Serverless Kubernetes 和 弹性容器实例 ECI 这两款产品;然后介绍 Spark on Kubernetes;最后进行实际演示。
产品介绍
阿里云弹性容器实例 ECI
ECI 提供安全的 Serverless 容器运行服务。无需管理底层服务器,只需要提供打包好的 Docker 镜像,即可运行容器,并仅为容器实际运行消耗的资源付费。 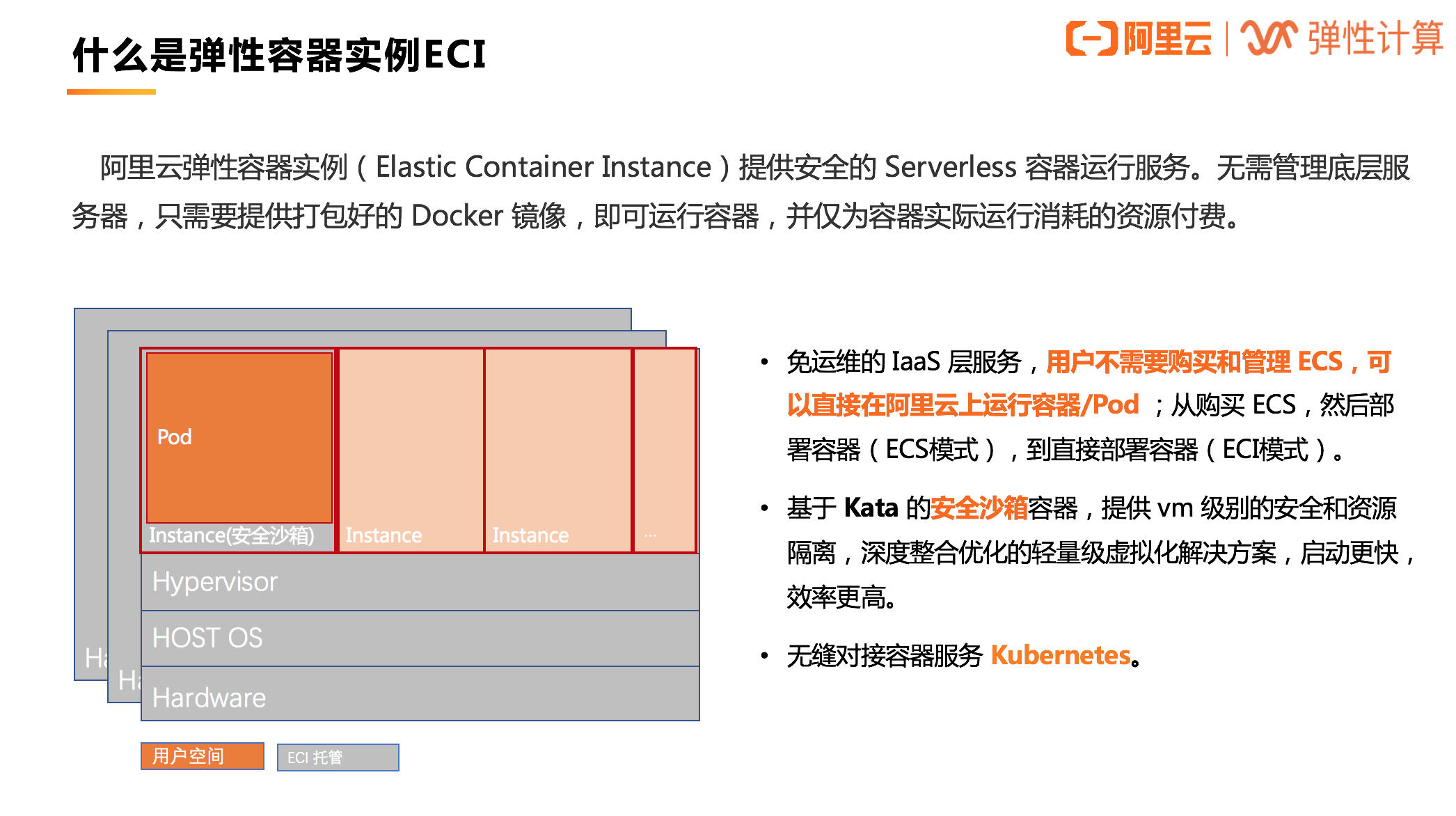
阿里云容器服务产品族
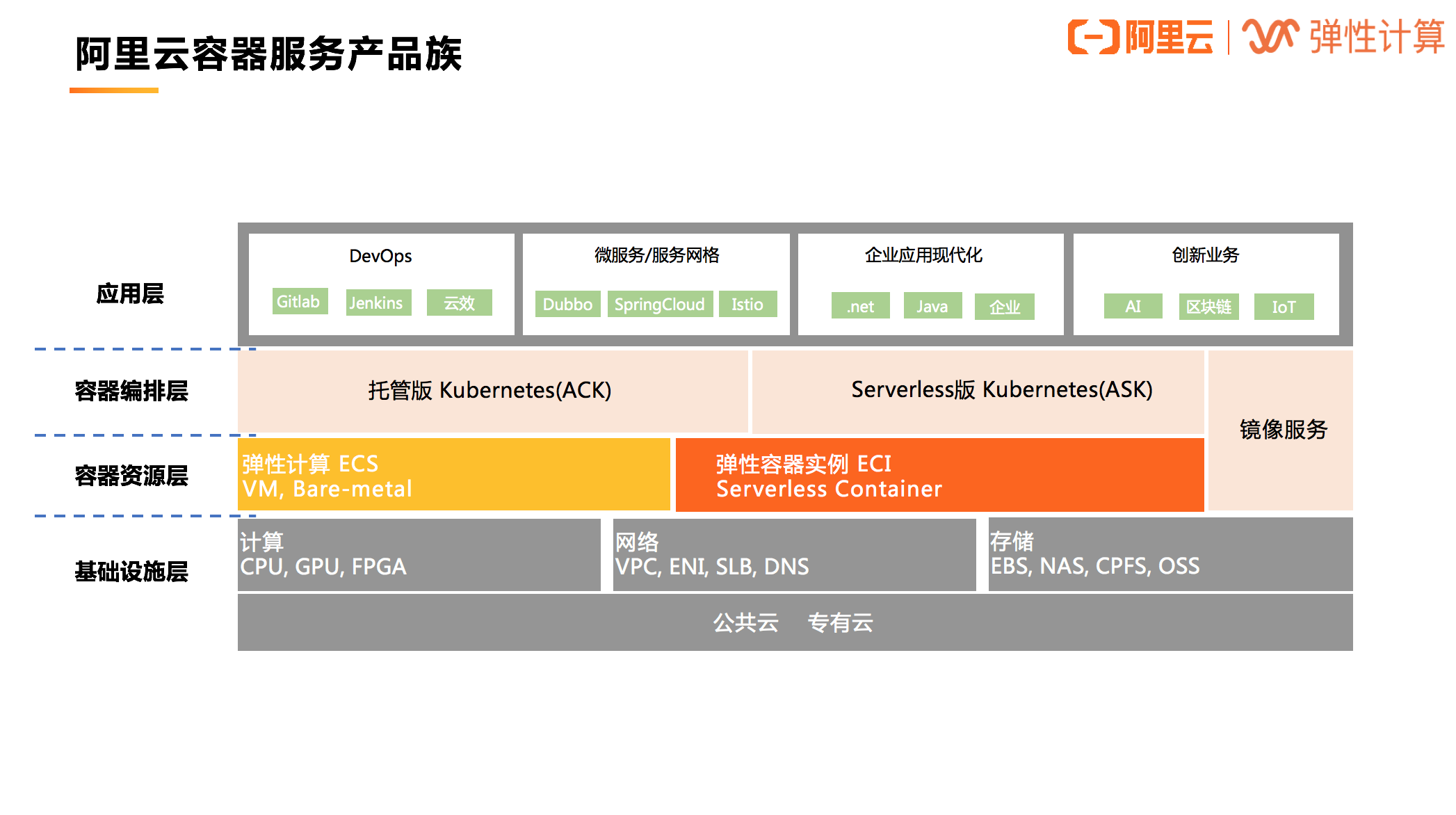 不论是托管版的 Kubernetes(ACK)还是 Serverless 版 Kubernetes(ASK),都可以使用 ECI 作为容器资源层,其背后的实现就是借助虚拟节点技术,通过一个叫做 Virtual Node 的虚拟节点对接 ECI。
不论是托管版的 Kubernetes(ACK)还是 Serverless 版 Kubernetes(ASK),都可以使用 ECI 作为容器资源层,其背后的实现就是借助虚拟节点技术,通过一个叫做 Virtual Node 的虚拟节点对接 ECI。 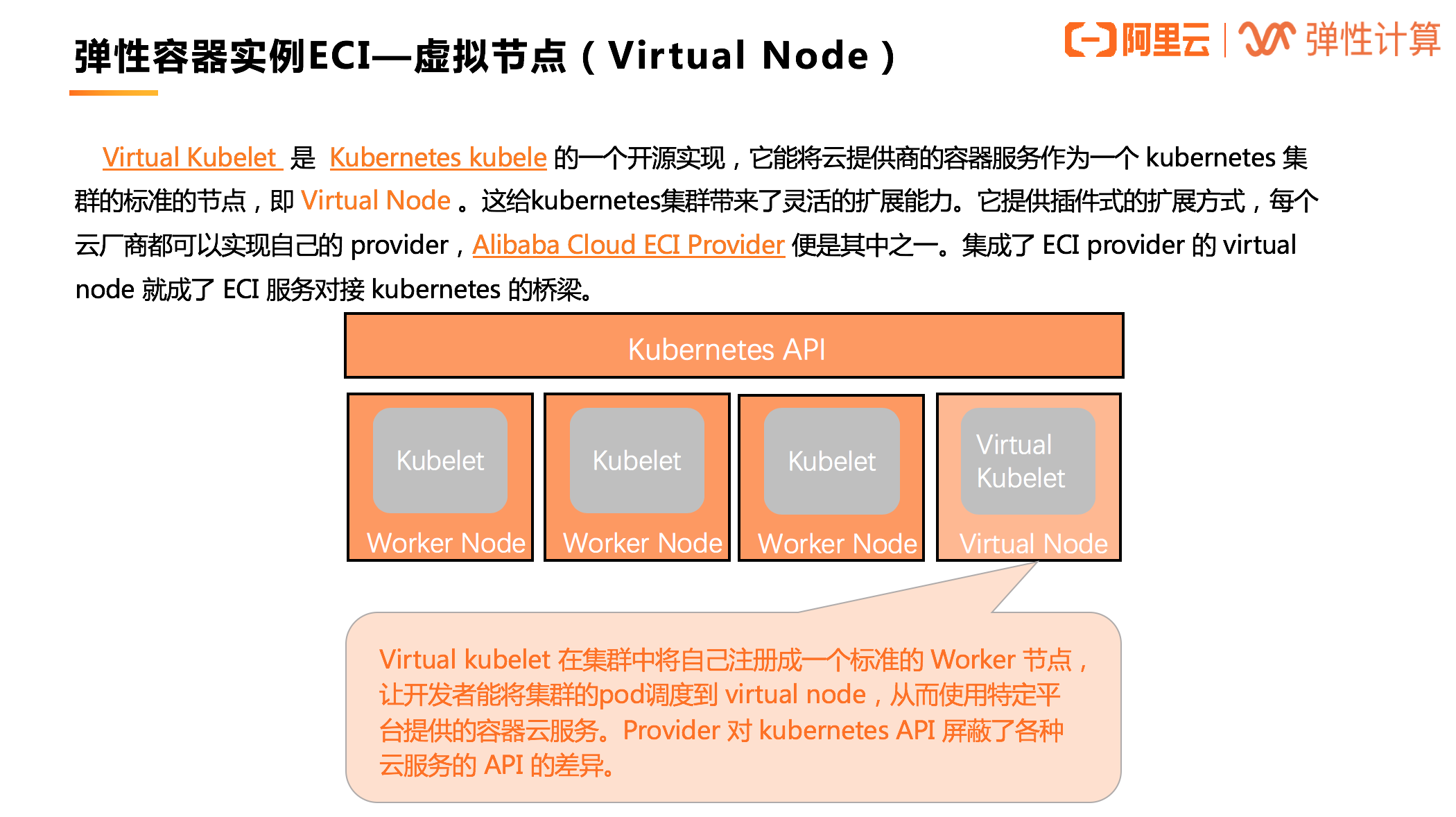
Kubernetes + ECI
有了 Virtual Kubelet,标准的 Kubernetes 集群就可以将 ECS 和虚拟节点混部,将 Virtual Node 作为应对突发流量的弹性资源池。 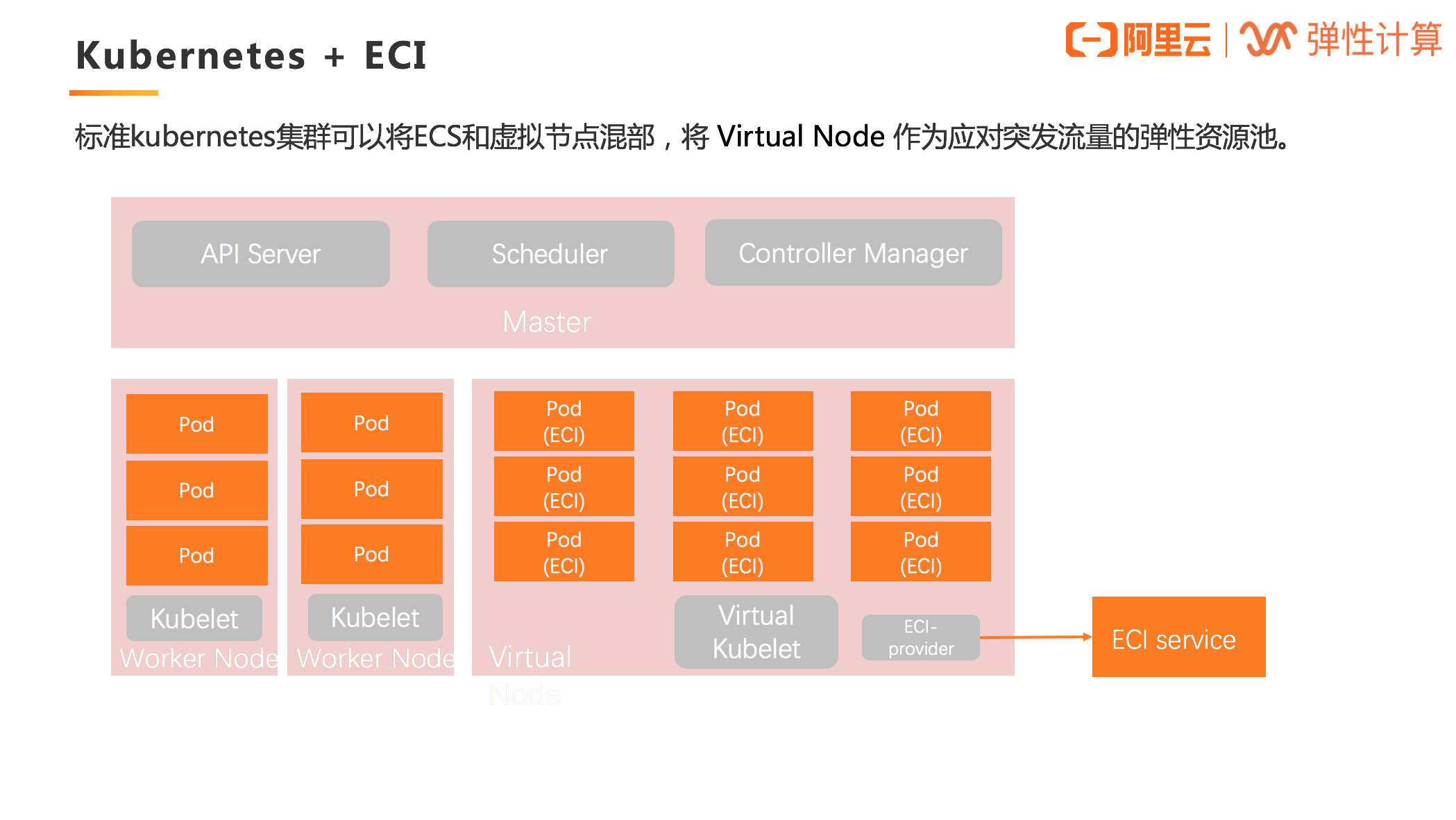
ASK(Serverless Kubernetes)+ ECI
Serverless 集群中没有任何 ECS worker 节点,也无需预留、规划资源,只有一个 Virtual Node,所有的 Pod 的创建都是在 Virtual Node 上,即基于 ECI 实例。 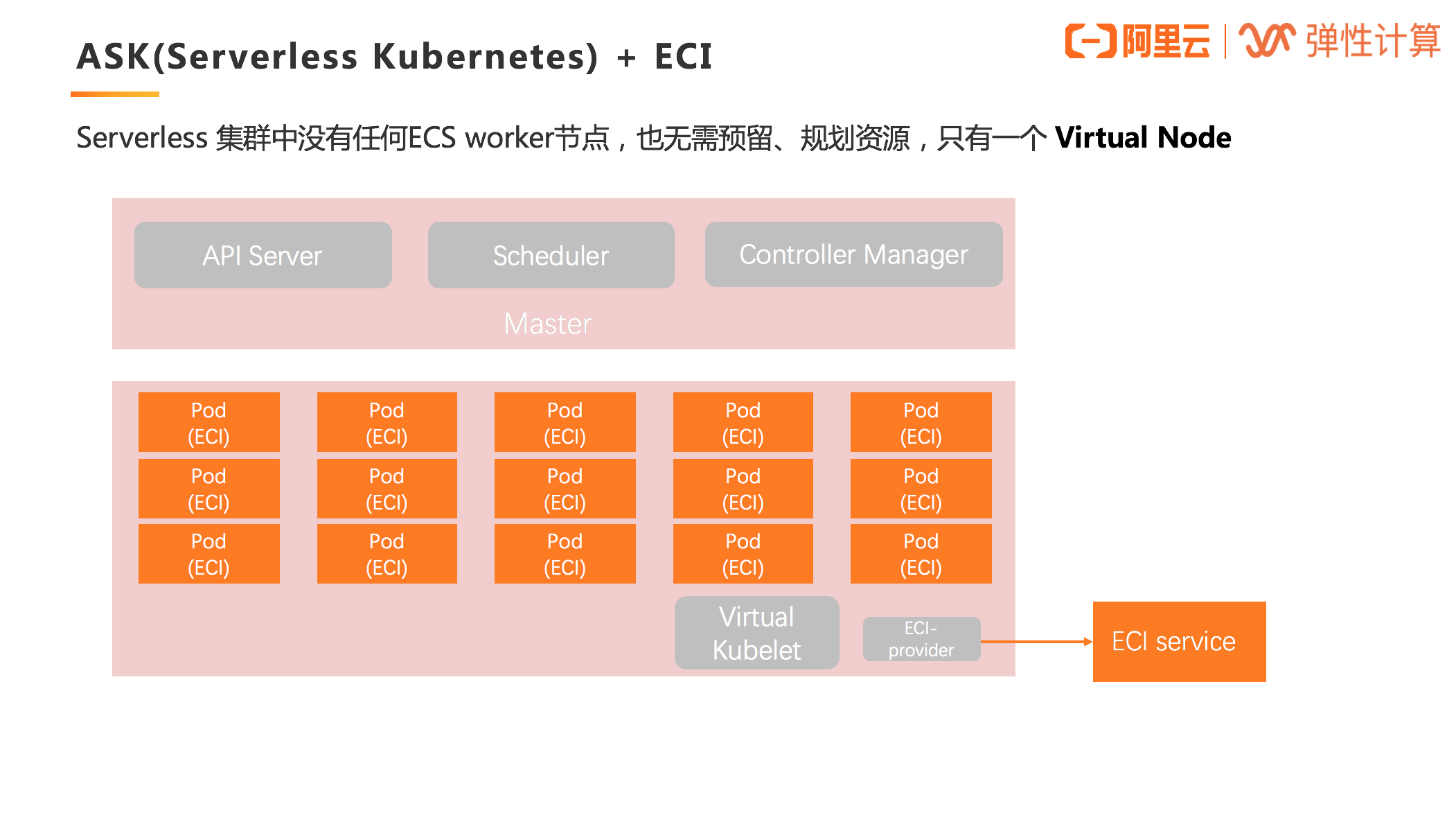 Serverless Kubernetes 是以容器和 Kubernetes 为基础的 Serverless 服务,它提供了一种简单易用、极致弹性、最优成本和按需付费的 Kubernetes 容器服务,其中无需节点管理和运维,无需容量规划,让用户更关注应用而非基础设施的管理。
Serverless Kubernetes 是以容器和 Kubernetes 为基础的 Serverless 服务,它提供了一种简单易用、极致弹性、最优成本和按需付费的 Kubernetes 容器服务,其中无需节点管理和运维,无需容量规划,让用户更关注应用而非基础设施的管理。
Spark on Kubernetes
Spark 自 2.3.0 开始试验性支持 Standalone、on YARN 以及 on Mesos 之外的新的部署方式:Running Spark on Kubernetes,如今支持已经非常成熟。
Kubernetes 的优势
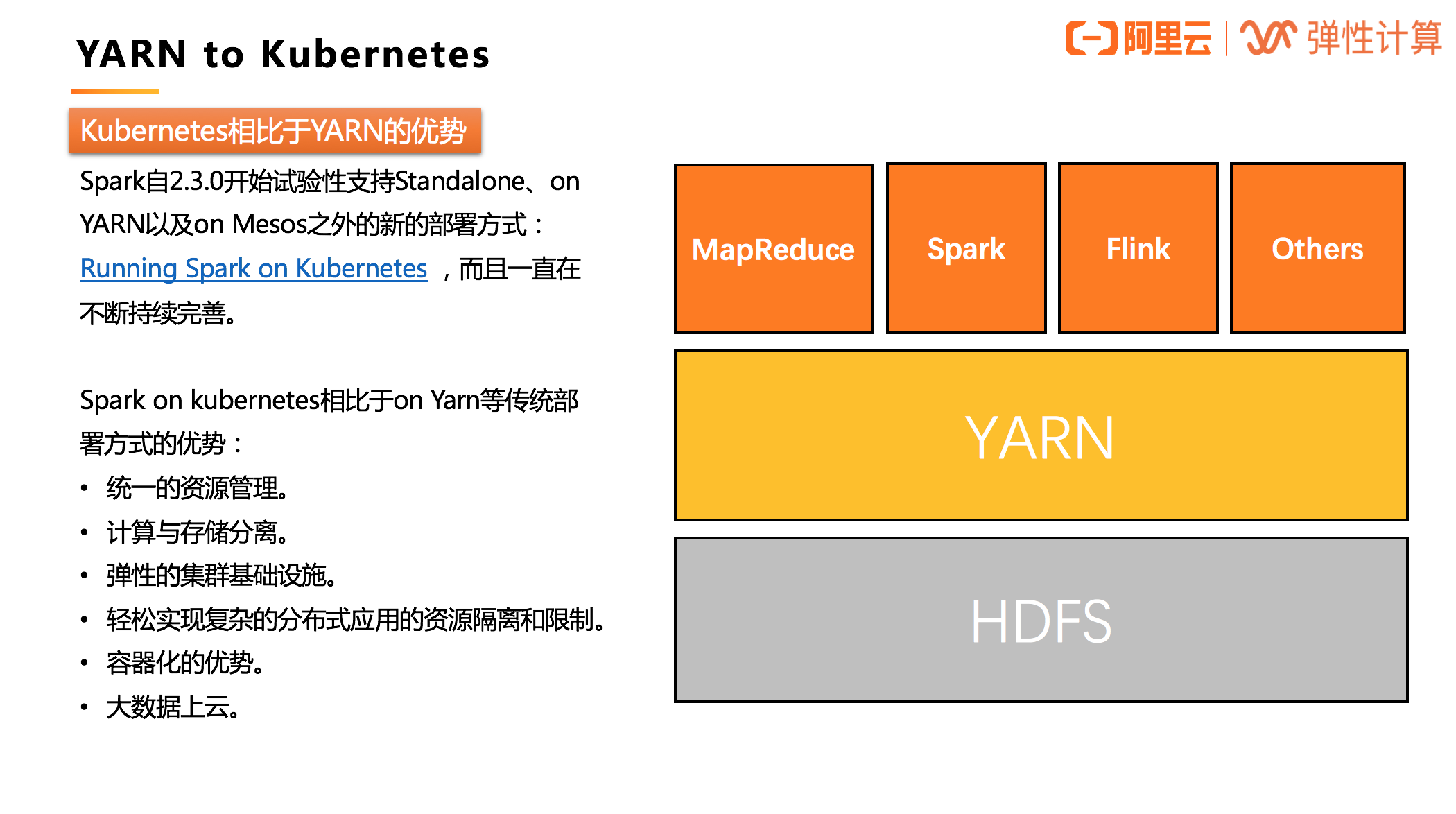 Spark on kubernetes 相比于 on Yarn 等传统部署方式的优势:
Spark on kubernetes 相比于 on Yarn 等传统部署方式的优势:
1、统一的资源管理。不论是什么类型的作业都可以在一个统一的 Kubernetes 集群中运行,不再需要单独为大数据作业维护一个独立的 YARN 集群。 2、传统的将计算和存储混合部署,常常会为了扩存储而带来额外的计算扩容,这其实就是一种浪费;同理,只为了提升计算能力,也会带来一段时期的存储浪费。Kubernetes 直接跳出了存储限制,将离线计算的计算和存储分离,可以更好地应对单方面的不足。 3、弹性的集群基础设施。 4、轻松实现复杂的分布式应用的资源隔离和限制,从 YRAN 复杂的队列管理和队列分配中解脱。 5、容器化的优势。每个应用都可以通过 Docker 镜像打包自己的依赖,运行在独立的环境,甚至包括 Spark 的版本,所有的应用之间都是完全隔离的。 6、大数据上云。目前大数据应用上云常见的方式有两种:1)用 ECS 自建 YARN(不限于 YARN)集群;2)购买 EMR 服务,目前所有云厂商都有这类 PaaS,如今多了一个选择——Kubernetes。
Spark 调度
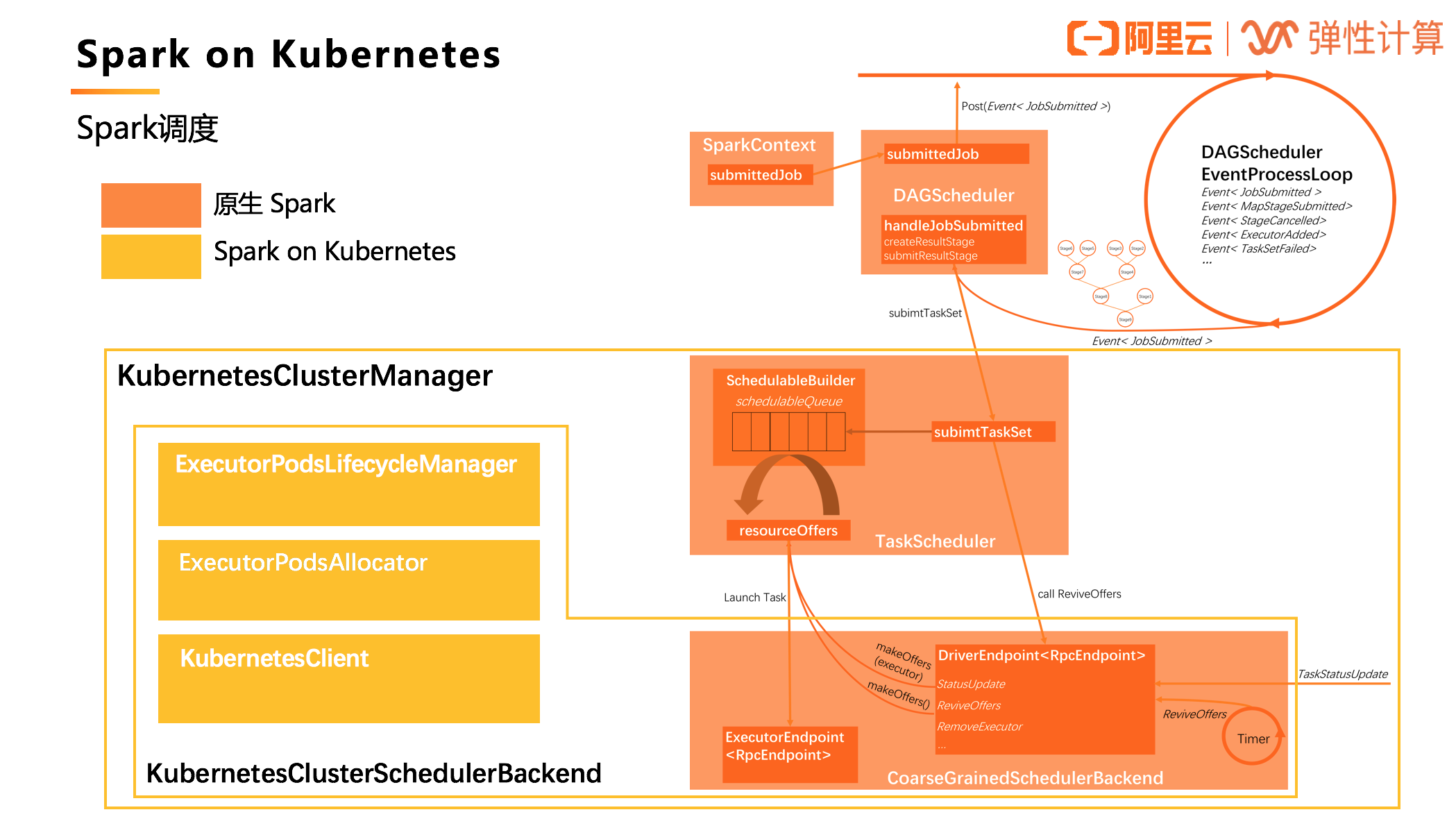 图中橙色部分是原生的 Spark 应用调度流程,而 Spark on Kubernetes 对此做了一定的扩展(黄色部分),实现了一个 KubernetesClusterManager。其中 KubernetesClusterSchedulerBackend 扩展了原生的CoarseGrainedSchedulerBackend,新增了 ExecutorPodsLifecycleManager、ExecutorPodsAllocator 和KubernetesClient 等组件,实现了将标准的 Spark Driver 进程转换成 Kubernetes 的 Pod 进行管理。
图中橙色部分是原生的 Spark 应用调度流程,而 Spark on Kubernetes 对此做了一定的扩展(黄色部分),实现了一个 KubernetesClusterManager。其中 KubernetesClusterSchedulerBackend 扩展了原生的CoarseGrainedSchedulerBackend,新增了 ExecutorPodsLifecycleManager、ExecutorPodsAllocator 和KubernetesClient 等组件,实现了将标准的 Spark Driver 进程转换成 Kubernetes 的 Pod 进行管理。
Spark submit
在 Spark Operator 出现之前,在 Kubernetes 集群提交 Spark 作业只能通过 Spark submit 的方式。创建好 Kubernetes 集群,在本地即可提交作业。 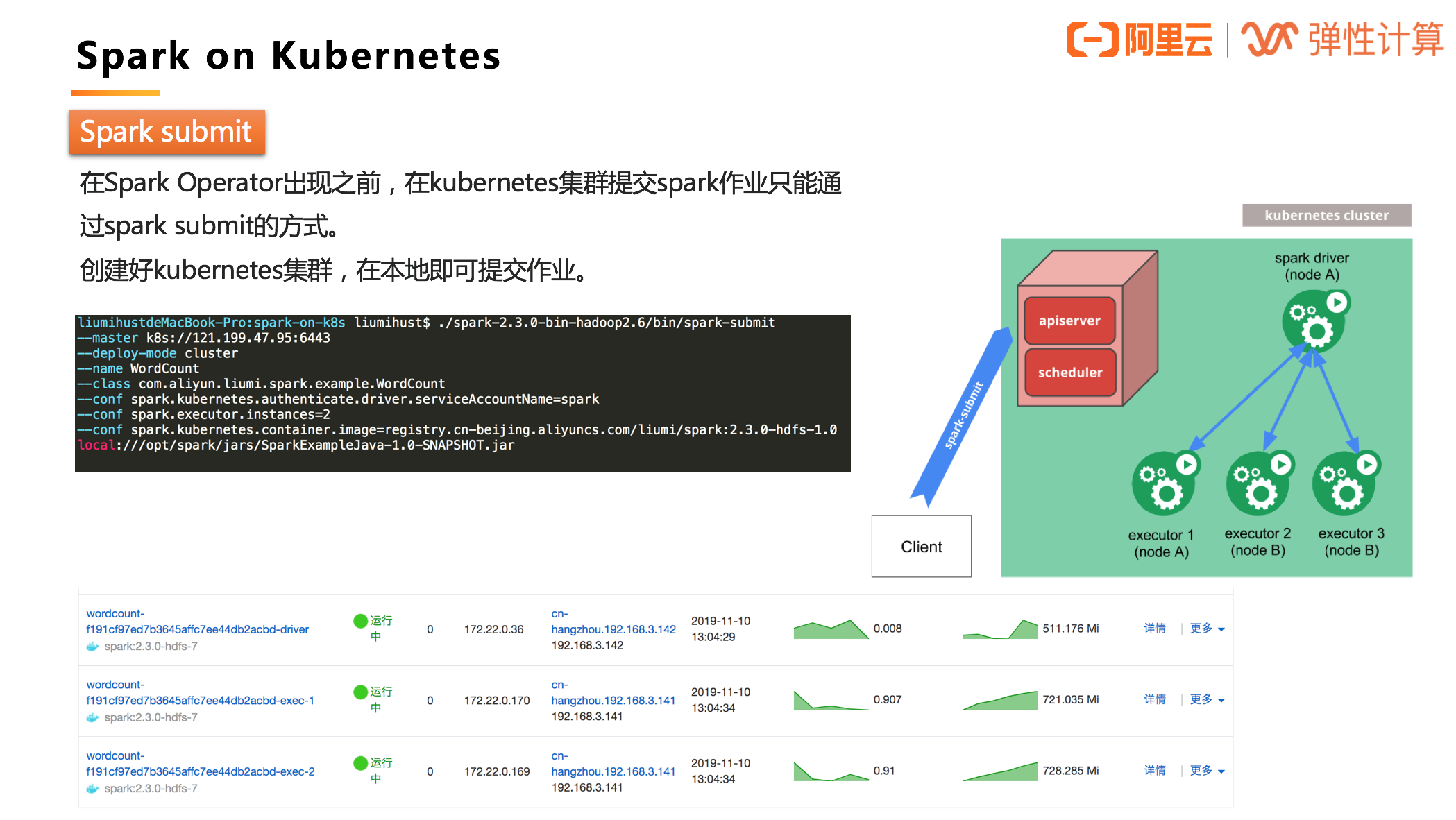 作业启动的基本流程:
作业启动的基本流程:
1、Spark 先在 K8s 集群中创建 Spark Driver(pod)。 2、Driver 起来后,调用 K8s API 创建 Executors(pods),Executors 才是执行作业的载体。 3、作业计算结束,Executor Pods 会被自动回收,Driver Pod 处于 Completed 状态(终态)。可以供用户查看日志等。 4、Driver Pod 只能被用户手动清理,或者被 K8s GC 回收。
直接通过这种 Spark submit 的方式,参数非常不好维护,而且不够直观,尤其是当自定义参数增加的时候;此外,没有 Spark Application 的概念了,都是零散的 Kubernetes Pod 和 Service 这些基本的单元,当应用增多时,维护成本提高,缺少统一管理的机制。
Spark Operator
Spark Operator 就是为了解决在 Kubernetes 集群部署并维护 Spark 应用而开发的,Spark Operator 是经典的 CRD + Controller,即 Kubernetes Operator 的实现。 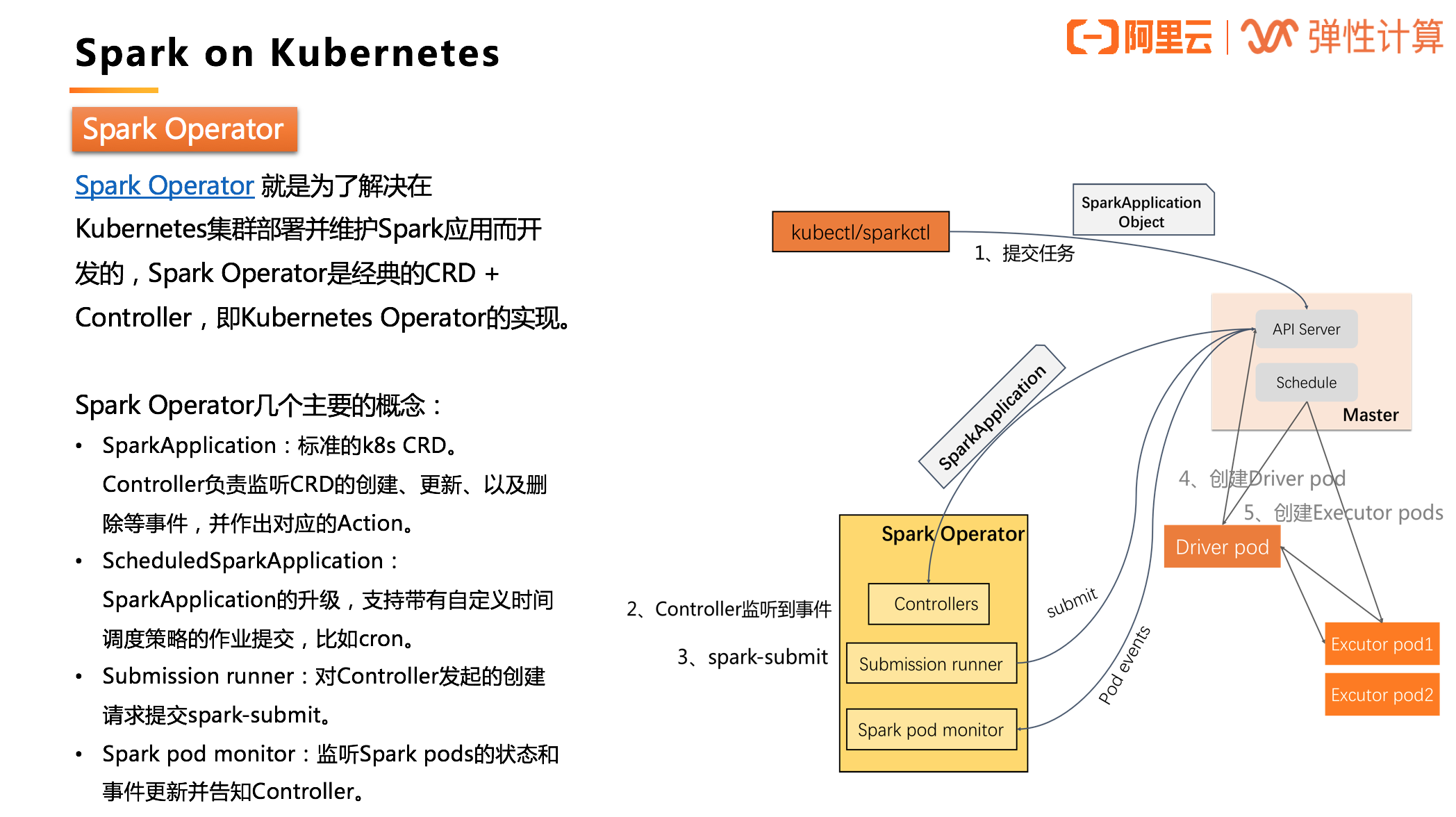
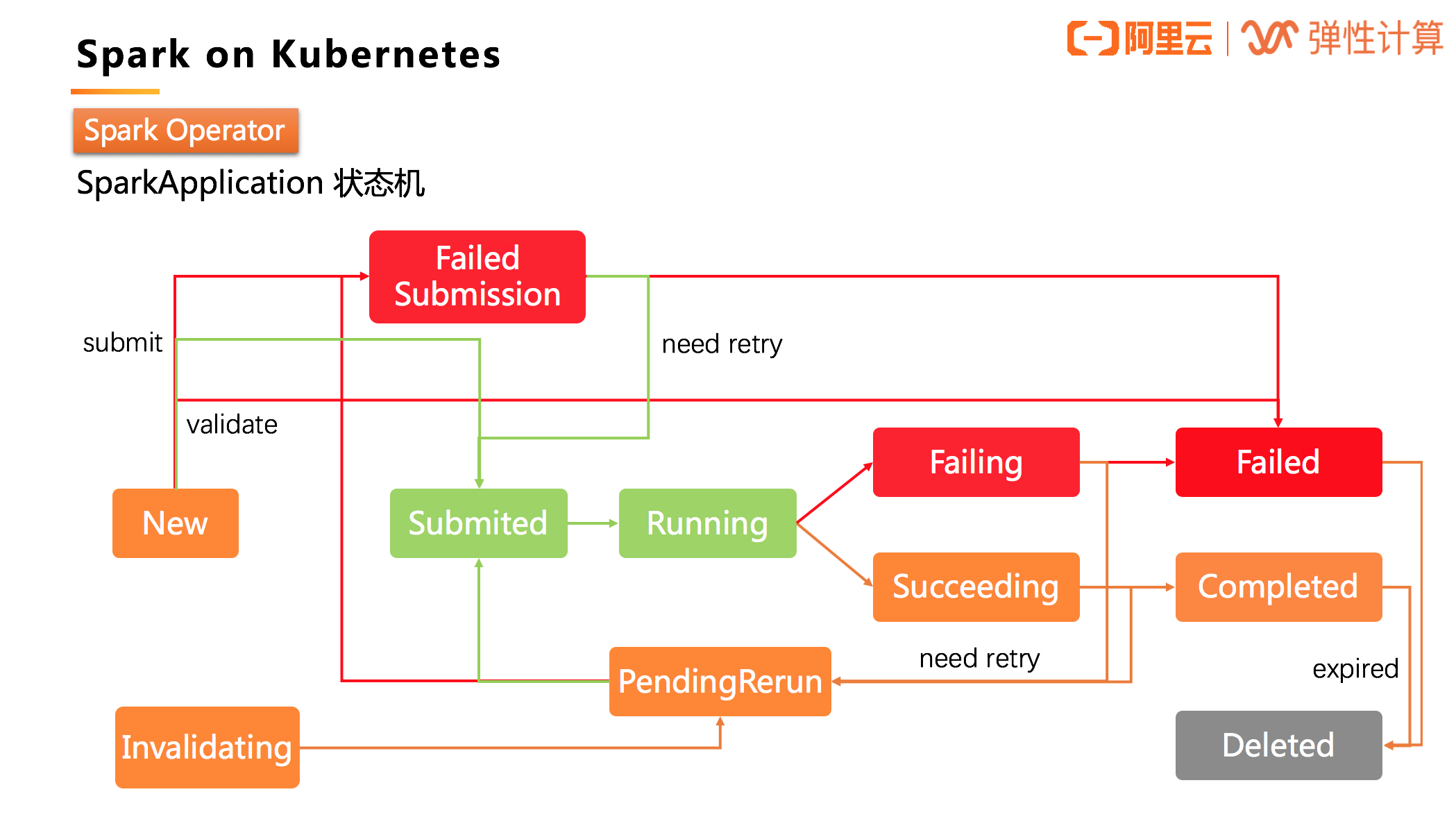
下图为 SparkApplication 状态机:
Serverless Kubernetes + ECI
那么,如果在 Serverless Kubernetes 集群中运行 Spark,其实际上是对原生 Spark 的进一步精简。 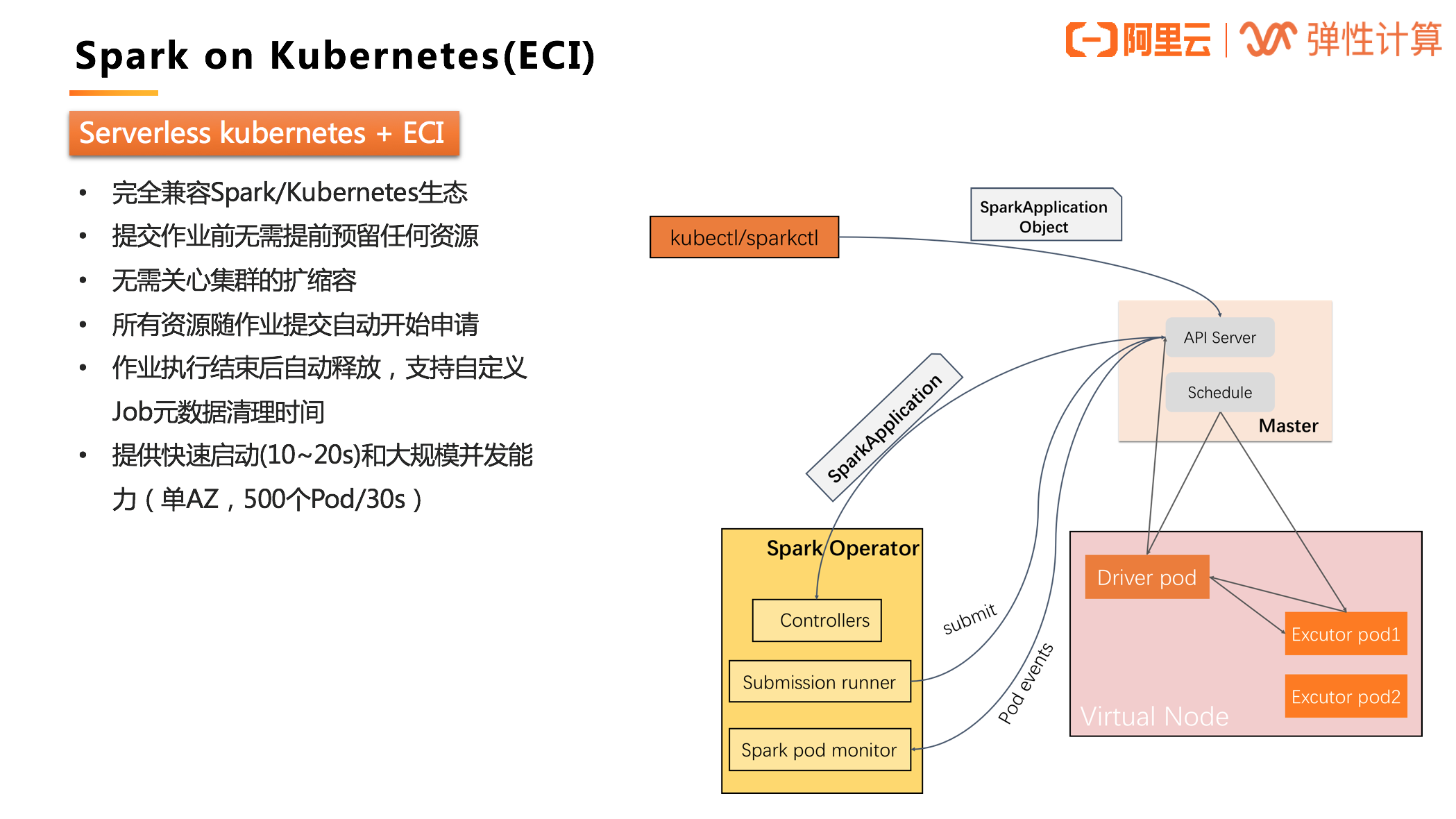
存储选择
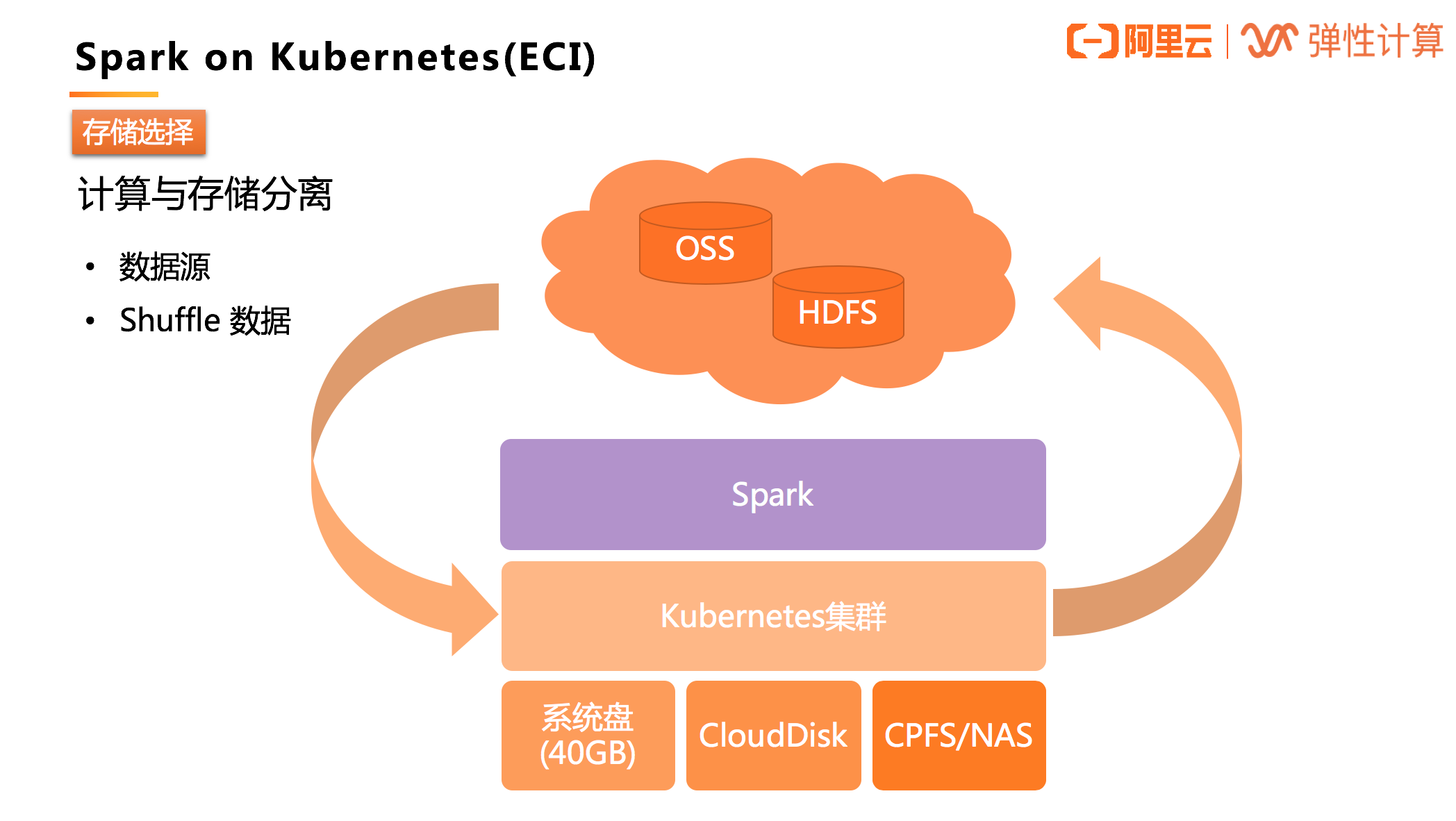 对于批量处理的数据源,由于集群不是基于 HDFS 的,所以数据源会有不同,需要计算与存储分离,Kubernetes 集群只负责提供计算资源。
对于批量处理的数据源,由于集群不是基于 HDFS 的,所以数据源会有不同,需要计算与存储分离,Kubernetes 集群只负责提供计算资源。
数据源的存储可以采用阿里云对象存储 OSS、阿里云分布式存储 HDFS 等。
计算的临时数据、Shuffle 数据可以采用 ECI 提供的免费的 40GB 的系统盘存储空间,还可以自定义挂载阿里云数据盘、以及 CPFS/NAS 文件系统等,都拥有非常不错的性能。
实操演示
本次实操分别展示 TPC-DS 和 WordCount 两个应用,点击即可观看具体操作演示过程 **
如何在 Serverless K8s 集群中低成本运行 Spark 数据计算?的更多相关文章
- rancher导入k8s集群后添加监控无数据
1.日志报错 rancher导入k8s集群后添加监控无数据,rancher日志报错: k8s.io/kube-state-metrics/pkg/collectors/builder.go:: Fai ...
- K8S集群入门:运行一个应用程序究竟需要多少集群?
如果你使用Kubernetes作为应用程序的操作平台,那么你应该会遇到一些有关使用集群的方式的基本问题: 你应该有多少集群? 它们应该多大? 它们应该包含什么? 本文将深入讨论这些问题,并分析你所拥有 ...
- 如何在k8s集群里快速运行一个镜像?
在docker里,快速run一个镜像,很简单的. k8s的世界,与之类似. 但要注意一下,如果镜像本身没有提供command命令,这个容器由于前台输出完成,很快就退出了. 所以,遇到这种镜像,就最好自 ...
- K8S集群组件
master节点主要由apiserver.controller-manager和scheduler三个组件,以及一个用于集群状态存储的etcd存储服务组成,而每个node节点则主要包含kubelet. ...
- 备战双 11!蚂蚁金服万级规模 K8s 集群管理系统如何设计?
作者 | 蚂蚁金服技术专家 沧漠 关注『阿里巴巴云原生』公众号,回复关键词"1024",可获取本文 PPT. 前言 Kubernetes 以其超前的设计理念和优秀的技术架构,在容器 ...
- 大规模 K8s 集群管理经验分享 · 上篇
11 月 23 日,Erda 与 OSCHINA 社区联手发起了[高手问答第 271 期 -- 聊聊大规模 K8s 集群管理],目前问答活动已持续一周,由 Erda SRE 团队负责人骆冰利为大家解答 ...
- 使用kubectl管理k8s集群(二十九)
前言 在搭建k8s集群之前,我们需要先了解下kubectl的使用,以便在集群部署出现问题时进行检查和处理.命令和语法记不住没有关系,但是请记住主要的语法和命令以及帮助命令的使用. 在下一篇,我们将讲述 ...
- 使用Kubeadm创建k8s集群之部署规划(三十)
前言 上一篇我们讲述了使用Kubectl管理k8s集群,那么接下来,我们将使用kubeadm来启动k8s集群. 部署k8s集群存在一定的挑战,尤其是部署高可用的k8s集群更是颇为复杂(后续会讲).因此 ...
- 使用Kubeadm创建k8s集群之节点部署(三十一)
前言 本篇部署教程将讲述k8s集群的节点(master和工作节点)部署,请先按照上一篇教程完成节点的准备.本篇教程中的操作全部使用脚本完成,并且对于某些情况(比如镜像拉取问题)还提供了多种解决方案.不 ...
随机推荐
- 模拟文件上传(二):使用apache fileupload组件进行文件上传
其中涉及到的jar包: jsp显示层: <%@ page language="java" import="java.util.*" pageEncodin ...
- 跨域@RequestBody@RequestParam 和JSON.stringify
- Django的基本运用(垃圾分类)
title: 利用Django实现一个能与用户交互的初级框架 author: Sun-Wind date: September 1, 2021 Django实现基本的框架 此框架的功能是搭建服务器,使 ...
- 基于SigalR实现的奥运会实时金牌榜
系统架构 三端 winform 后台数据管理 + Asp.Net Mvc 前台数据展示 + Xamarin.Forms 移动端跨平台APP 因为本人的代码水平一般,期间遇到了一些问题,如signalR ...
- MySQL之连接查询和子查询
多表连接的基本语法 多表连接,就是将几张表拼接为一张表,然后进行查询 select 字段1, 字段2, ... from 表1 {inner|lift|right} join 表2 on 连接条件; ...
- java agent简介
java agent简介 主要就是两种,一种的方法是premain,一种是agentmain.这两种的区别是: premain是在jvm启动的时候类加载到虚拟机之前执行的 agentmain是可以在j ...
- python类、继承
Python 是一种面向对象的编程语言.Python 中的几乎所有东西都是对象,拥有属性和方法.类(Class)类似对象构造函数,或者是用于创建对象的"蓝图". 一.python ...
- Spring Boot入门系列(二十六)超级简单!Spring Data JPA 的使用!
之前介绍了Mybatis数据库ORM框架,也介绍了使用Spring Boot 的jdbcTemplate 操作数据库.其实Spring Boot 还有一个非常实用的数据操作框架:Spring Data ...
- Identity角色管理二(显示角色)
需要将目前所有角色名显示出来,方法同用户管理 一.创建Index acction public async Task<ActionResult> Index() { var roles = ...
- 三剑客之awk 逐行读取
目录: 一.awk工作原理 二.按行输出文本 三.按字段输出文本 四.通过管道,双引号调用shall命令 五.CPU使用率 六.使用awk 统计 httpd 访问日志中每个客户端IP的出现次数 一.a ...