深度学习——手动实现残差网络ResNet 辛普森一家人物识别
深度学习——手动实现残差网络 辛普森一家人物识别
目标
通过深度学习,训练模型识别辛普森一家人动画中的14个角色
最终实现92%-94%的识别准确率。
数据
ResNet介绍
论文地址 https://arxiv.org/pdf/1512.03385.pdf
残差网络(ResNet)是微软亚洲研究院的何恺明、孙剑等人2015年提出的,它解决了深层网络训练困难的问题。利用这样的结构我们很容易训练出上百层甚至上千层的网络。
残差网络的提出,有效地缓解了深度学习两个大问题
梯度消失:当使用深层的网络时(例如> 100)反向传播时会产生梯度消。由于参数初始化一般更靠近0,这样在训练的过程中更新浅层网络的参数时,很容易随着网络的深入而导致梯度消失,浅层的参数无法更新。
退化问题:层数越多,训练错误率与测试错误率反而升高。举个例子,假设已经有了一个最优化的网络结构,是18层。当我们设计网络结构的时候,我们并不知道具体多少层次的网络时最优化的网络结构,假设设计了34层网络结构。那么多出来的16层其实是冗余的,我们希望训练网络的过程中,模型能够自己训练这16层为恒等映射,也就是经过这层时的输入与输出完全一样,这样子最终的结果和18层是一致的最优的。但是往往模型很难将这16层恒等映射的参数学习正确,那么就一定会不比最优化的18层网络结构性能好,所以随着网络深度增加,模型会产生退化现象。它不是由过拟合产生的,而是由冗余的网络层学习了不是恒等映射的参数造成的。
ResNet使用了一个新的思想,ResNet的思想是假设我们的网络,存在最优化的网络层次,那么往往我们设计的深层次网络是有很多网络层为冗余层的。那么我们希望这些冗余层能够完成恒等映射,保证经过该恒等层的输入和输出完全相同。
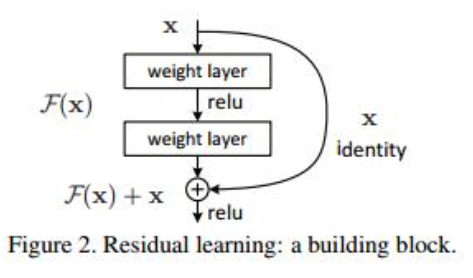
这是残差网络的基本单元,和普通的网络结构多了一个直接到达输出前的连线(shortcut)。开始输入的X是这个残差块的输入,F(X)是经过第一层线性变化并激活后的输出。在第二层输出值激活前加入X,这条路径称作shortcut连接,然后再进行激活后输出。
这个残差怎么理解呢?大家可以这样理解在线性拟合中的残差说的是数据点距离拟合直线的函数值的差,那么这里我们可以类比,这里的X就是我们的拟合的函数,而H(x)的就是具体的数据点,那么我通过训练使的拟合的值加上F(x)的就得到具体数据点的值,因此这 F(x)的就是残差了,还是画个图吧,如下图:
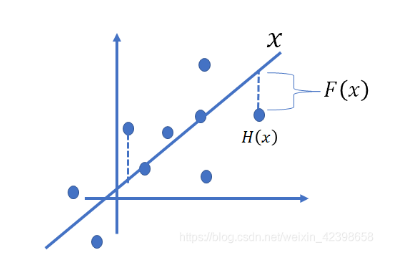
引用:https://blog.csdn.net/weixin_42398658/article/details/84627628
ResNet就是在网络中添加shortcut,来构成一个个的残差块,从而解决梯度爆炸和网络退化。
ResNet18网络结构
这是一个ResNet18的网络结构,在我的实现中,我根据这个结构搭建网络,并根据自己的实际情况进行调整。
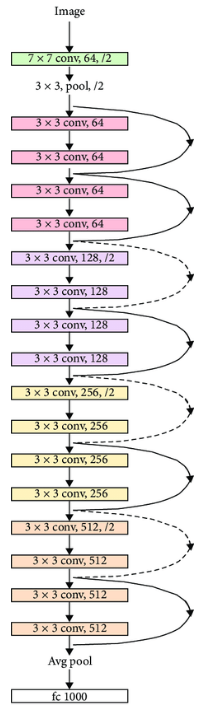
引用:https://www.researchgate.net/figure/ResNet-18-model-architecture-10_fig2_342828449
项目思路
首先,ResNets利用恒等映射帮助解决渐变消失的问题。我开始尝试使用简单的MLP模型,例如一个输入层、一个输出层和三个卷积层。但是它的训练表现很差,只有45%的准确率。所以我需要更多的神经网络层,但是如果太多的神经网络层会导致梯度消失的问题。最后我想到了ResNet。
其次,网络深度决定了savedModel.pth(训练好的模型)的文件大小,该数据集总共有15,000张图像和14个类别,并不是很多。所以我选择了ResNet18,因为我们的数据集不是特别大。
而且不需要更深层次的网络模型。
ResNet18是一个卷积神经网络。它的架构有18层。它在图像分类中是非常有用和有效的。首先是一个卷积层,内核大小为3x3,步幅为1。
在标准的ResNet18模型中,这一层使用7*7的内核大小和步幅2。我在这里做了一些改变。
根据实际情况,因为原始模型中输入的文件大小是224224,而我们的图像大小是6464,7*7的内核大小对于这个任务来说太大了。在本作业中,标准ResNet18模型的精度为大约89%,而我修改的模型的准确率大约为94%。
输入层之后是由剩余块组成的四个中间层。ResNet的残余块是由两个33卷积层,包括一个shortcut,使用11卷积层直接添加的输入前一层到另一层的输出。最后,average pooling应用于的输出,将最终的残块和接收到的特征图赋给全连通层。
此外,模型中的卷积结果采用ReLu激活函数和归一化处理。
Data Transform:
为了减少过拟合,我使用图像变换进行数据增强。并对输入图像进行归一化处理。这样可以保证所有图像的分布是相似的,即在训练过程中更容易收敛,训练速度更快,效果更好。
我还尝试将图像的大小调整为224224,并在输入层使用77的卷积核,但我发现图像放大得太多,导致特征模糊,模型性能变差。
归一化:我使用下面的脚本来计算所有数据的均值和标准差。
data = torchvision.datasets.ImageFolder(root=student.dataset,
transform=student.transform('train'))
trainloader = torch.utils.data.DataLoader(data,
batch_size=1, shuffle=True)
mean = torch.zeros(3)
std = torch.zeros(3)
for batch in trainloader:
images, labels = batch
for d in range(3):
mean[d] += images[:, d, :, :].mean()
std[d] += images[:, d, :, :].std()
mean.div_(len(data))
std.div_(len(data))
print(list(mean.numpy()), list(std.numpy()))
超参数及其他设定
Epochs, batch_size, learning rate:
epochs = 120, 如果太小,收敛可能不会结束。
batch_size = 256, 如果batch_size太小,可能会导致收敛速度过慢或损失不会减少
lr = 0.001,当学习率设置过大时,梯度可能会围绕最小值振荡,甚至无法收敛
Loss function:
torch.nn.CrossEntropyLoss() 是很适合图像作业的
Aptimiser:
我尝试过SGD, RMSprop, Adadelta等,但Adam是最适合我的。
Dropout and weight_decay: not use them
当我试图设置它们来减少过拟合问题时,效果并不好。这种设置使loss无法减少或精度降低。
代码
图像增强代码
def transform(mode):
"""
Called when loading the data. Visit this URL for more information:
https://pytorch.org/vision/stable/transforms.html
You may specify different transforms for training and testing
"""
if mode == 'train':
return transforms.Compose([
# transforms.Grayscale(num_output_channels=1),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.42988312, 0.42988312, 0.42988312],
[0.17416202, 0.17416202, 0.17416202])
])
elif mode == 'test':
return transforms.Compose([
# transforms.Grayscale(num_output_channels=1),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.42988312, 0.42988312, 0.42988312],
[0.17416202, 0.17416202, 0.17416202])
])
ResNet18手工搭建
class Network(nn.Module):
def __init__(self, num_classes=14):
super().__init__()
self.inchannel = 64
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU()
# nn.MaxPool2d(3, 1, 1)
)
self.layer1 = self.make_layer(ResBlock, 64, 2, stride=1)
self.layer2 = self.make_layer(ResBlock, 128, 2, stride=2)
self.layer3 = self.make_layer(ResBlock, 256, 2, stride=2)
self.layer4 = self.make_layer(ResBlock, 512, 2, stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512, num_classes)
def make_layer(self, block, channels, num_blocks, stride):
layers = []
for i in range(num_blocks):
if i == 0:
layers.append(block(self.inchannel, channels, stride))
else:
layers.append(block(channels, channels, 1))
self.inchannel = channels
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv1(x)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.avgpool(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out
class ResBlock(nn.Module):
def __init__(self, inchannel, outchannel, stride=1):
super(ResBlock, self).__init__()
# two 3*3 kenerl size conv layers
self.left = nn.Sequential(
nn.Conv2d(inchannel, outchannel, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(outchannel),
nn.ReLU(inplace=True),
nn.Conv2d(outchannel, outchannel, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(outchannel)
)
self.shortcut = nn.Sequential()
if stride != 1 or inchannel != outchannel:
# shortcut,1*1 kenerl size
# shortcut,这里为了跟2个卷积层的结果结构一致,要做处理
self.shortcut = nn.Sequential(
nn.Conv2d(inchannel, outchannel, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(outchannel)
)
def forward(self, x):
out = self.left(x)
# 将2个卷积层的输出跟处理过的x相加,实现ResNet的基本结构
out = out + self.shortcut(x)
out = F.relu(out)
return out
参考
论文:
https://arxiv.org/pdf/1512.03385.pdf
参考博客:
https://www.cnblogs.com/gczr/p/10127723.html
https://blog.csdn.net/weixin_42398658/article/details/84627628
深度学习——手动实现残差网络ResNet 辛普森一家人物识别的更多相关文章
- 深度残差网络——ResNet学习笔记
深度残差网络—ResNet总结 写于:2019.03.15—大连理工大学 论文名称:Deep Residual Learning for Image Recognition 作者:微软亚洲研究院的何凯 ...
- 深度残差网络(ResNet)
引言 对于传统的深度学习网络应用来说,网络越深,所能学到的东西越多.当然收敛速度也就越慢,训练时间越长,然而深度到了一定程度之后就会发现越往深学习率越低的情况,甚至在一些场景下,网络层数越深反而降低了 ...
- 从头学pytorch(二十):残差网络resnet
残差网络ResNet resnet是何凯明大神在2015年提出的.并且获得了当年的ImageNet比赛的冠军. 残差网络具有里程碑的意义,为以后的网络设计提出了一个新的思路. googlenet的思路 ...
- (转)零基础入门深度学习(6) - 长短时记忆网络(LSTM)
无论即将到来的是大数据时代还是人工智能时代,亦或是传统行业使用人工智能在云上处理大数据的时代,作为一个有理想有追求的程序员,不懂深度学习(Deep Learning)这个超热的技术,会不会感觉马上就o ...
- 使用dlib中的深度残差网络(ResNet)实现实时人脸识别
opencv中提供的基于haar特征级联进行人脸检测的方法效果非常不好,本文使用dlib中提供的人脸检测方法(使用HOG特征或卷积神经网方法),并使用提供的深度残差网络(ResNet)实现实时人脸识别 ...
- 残差网络resnet学习
Deep Residual Learning for Image Recognition 微软亚洲研究院的何凯明等人 论文地址 https://arxiv.org/pdf/1512.03385v1.p ...
- CNN卷积神经网络_深度残差网络 ResNet——解决神经网络过深反而引起误差增加的根本问题,Highway NetWork 则允许保留一定比例的原始输入 x。(这种思想在inception模型也有,例如卷积是concat并行,而不是串行)这样前面一层的信息,有一定比例可以不经过矩阵乘法和非线性变换,直接传输到下一层,仿佛一条信息高速公路,因此得名Highway Network
from:https://blog.csdn.net/diamonjoy_zone/article/details/70904212 环境:Win8.1 TensorFlow1.0.1 软件:Anac ...
- 残差网络ResNet笔记
发现博客园也可以支持Markdown,就把我之前写的博客搬过来了- 欢迎转载,请注明出处:http://www.cnblogs.com/alanma/p/6877166.html 下面是正文: Dee ...
- 残差网络resnet理解与pytorch代码实现
写在前面 深度残差网络(Deep residual network, ResNet)自提出起,一次次刷新CNN模型在ImageNet中的成绩,解决了CNN模型难训练的问题.何凯明大神的工作令人佩服 ...
随机推荐
- roslaunch 启动时修改参数
启动命令: roslaunch beginner_tutorials turtlemimic.launch arg1:=3.0 查询命令: rosparam get /param1 可以看到param ...
- ecshop文件架构
/*ECShop 2.5.1 的结构图及各文件相应功能介绍ECShop2.5.1_Beta upload 的目录┣ activity.php 活动列表┣ affiche.php 广告处理文件┣ aff ...
- iptables开启后造成本地套接字阻塞的问题
前段时间,我使用iptables实现了针对IP地址与MAC地址的白名单功能,即将INPUT链的默认规则设为DROP: iptables -P INPUT DROP 这样就能拒绝一切外来报文.随后只需要 ...
- eBPF 安全项目 Tracee 初探
1. Tracee 介绍 1.1 Tracee 介绍 Tracee 是一个用 于 Linux 的运行时安全和取证工具.它使用 Linux eBPF 技术在运行时跟踪系统和应用程序,并分析收集的事件以检 ...
- C#提取程序的图标
需要添加对System.Management.dll的引用 ,并且不要忘记导入下面的名称空间. using System.Management; 将ListView和 ImageList控件从可视 ...
- 珠峰2016,第9期 vue.js 笔记部份
在珠峰参加培训好年了,笔记原是记在本子上,现在也经不需要看了,搬家不想带上书和本了,所以把笔记整理下,存在博客中,也顺便复习一下 安装vue.js 因为方便打包和环境依赖,所以建意npm init ...
- Docker系列(19)- 数据卷之Dockerfile
初识Dockerfile Dockerfile就是用来构建docker镜像的构建文件!命令脚本! 通过这个脚本生成镜像,镜像是一层一层的,脚本与一个个的命令,每个命令都是一层! # 创建一个docke ...
- MySql分区、分表和分库
MySql分区.分表和分库 数据库的数据量达到一定程度之后,为避免带来系统性能上的瓶颈.需要进行数据的处理,采用的手段是分区.分片.分库.分表. 一些问题的解释: 1.为什么要分表和分区? 日常开发中 ...
- 取得get参数 从url
1. getUrlParam.js define(function() { // url参数 var data, index; (function init() { data = []; index ...
- iPhone发布内测程序的方法
iPhone是封闭系统,不像android手机可以自行安装apk,所以iPhone手机发布内测程序相对来说复杂一些. 越狱安装 如果测试用户的机器已经越狱,那就简单了,直接打包成ipa,用户直接通过9 ...