MySQL实战45讲(16--20)-笔记
笔记做的不好,因为还是又不少地方没有能够理解。见谅,后面理解了在更新…………
16 | “order by”是怎么工作的?
场景:
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`city` int(11) NOT NULL,
`name` varchar(16) NOT NULL,
`age` int(11) NOT NULL,
`addr` varchar(128) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `city` (`city`)
) ENGINE=InnoDB;
select city,name,age from t where city='杭州' order by name limit 1000 ;
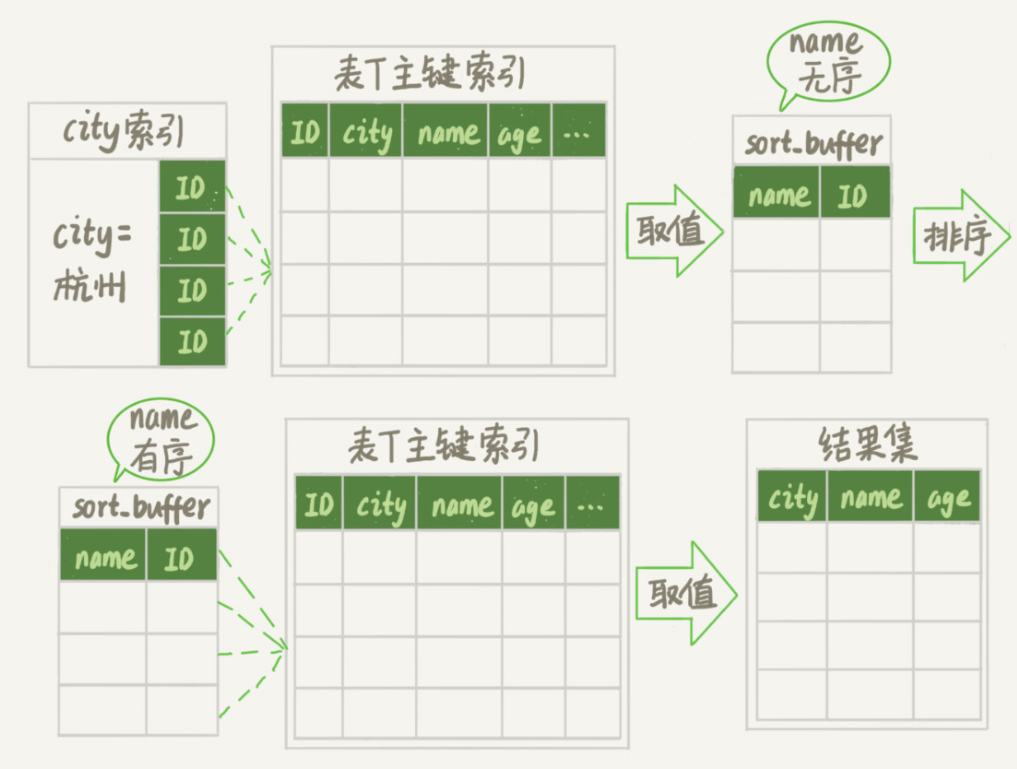
全字段排序
Extra 这个字段中的“Using filesort”表示的就是需要排序,MySQL 会给每个线程分配一块内存用于排序,称为 sort_buffer。

图中“按 name 排序”这个动作,可能在内存中完成,也可能需要使用外部排序,这取决于排序所需的内存和参数 sort_buffer_size。
可以用这个语句来确定一个排序语句是否使用了临时文件:
/* 打开 optimizer_trace,只对本线程有效 */
SET optimizer_trace='enabled=on';
/* @a 保存 Innodb_rows_read 的初始值 */
select VARIABLE_VALUE into @a from performance_schema.session_status where variable_name = 'Inndb'
/* 执行语句 */
select city, name,age from t where city='杭州' order by name limit 1000;
/* 查看 OPTIMIZER_TRACE 输出 */
SELECT * FROM `information_schema`.`OPTIMIZER_TRACE`\G
/* @b 保存 Innodb_rows_read 的当前值 */
select VARIABLE_VALUE into @b from performance_schema.session_status where variable_name = 'Innodb'
/* 计算 Innodb_rows_read 差值 */
select @b-@a
number_of_tmp_files 表示的是,排序过程中使用的临时文件数。
MySQL会将需要排序的文件分割成多份,小份单独排序后合一。(sort_buffer_size 越小,需要分成的份数越多,
number_of_tmp_files 的值就越大。)
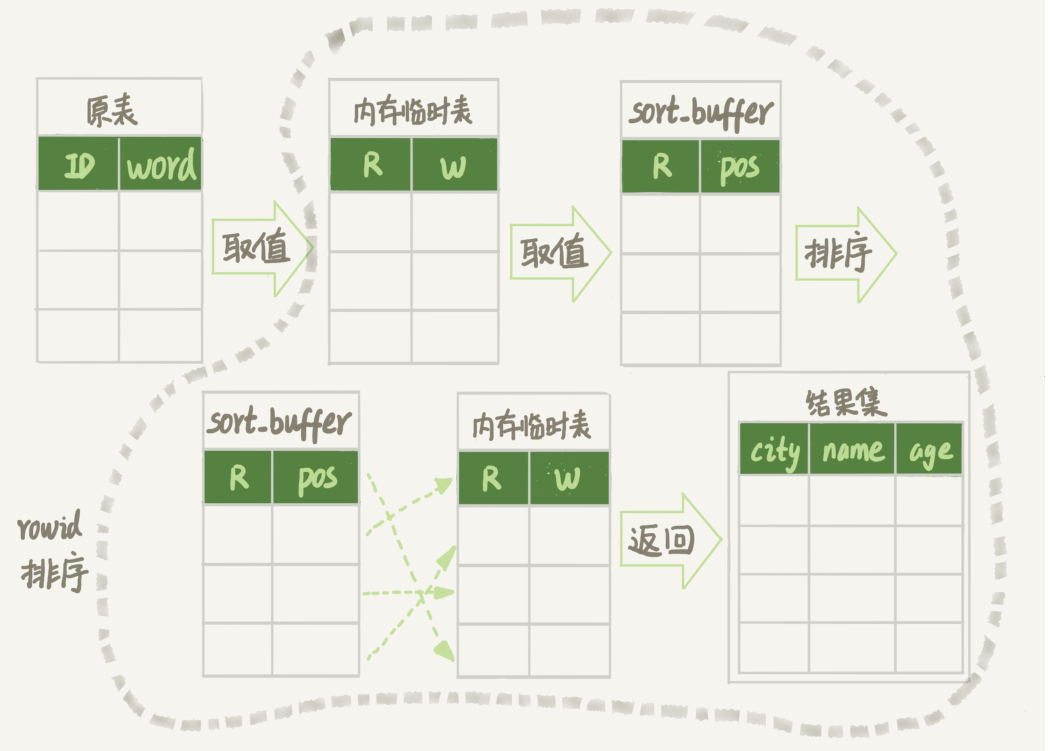
rowid 排序
MySQL 认为排序的单行长度太大 会使用 这个参数 max_length_for_sort_data 来提示MySQL要换一个算法。
过程:因为多了一次索引,排序使用的字段少了,所以数据量就下来了,相应的所需要的临时文件也变少了。
17 | 如何正确地显示随机消息?
场景:
英语学习App 每天 根据用户的级别推荐 随机的单词
随着单词表的变大,这个操作越来越慢
mysql> CREATE TABLE `words` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`word` varchar(64) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
内存临时表
order by rand() 来实现这个逻辑。
mysql> select word from words order by rand() limit 3;
一个结论:对于 InnoDB 表来说,执行全字段排序会减少磁盘访问,因此会被优先选择。
如果你创建的表没有主键,或者把一个表的主键删掉了,那么 InnoDB 会自己生成一个长度为 6 字节的 rowid 来作为主键。
这也就是排序模式里面,rowid 名字的来历。
实际上它表示的是:每个引擎用来唯一标识数据行的信息。
- 对于有主键的 InnoDB 表来说,这个 rowid 就是主键 ID;
- 对于没有主键的 InnoDB 表来说,这个 rowid 就是由系统生成的;
- MEMORY 引擎不是索引组织表。
在这个例子里面,你可以认为它就是一个数组。因此,这个 rowid 其实就是数组的下标。
order by rand() 使用了内存临时表,内存临时表排序的时候使用了 rowid 排序方法。
磁盘临时表
不是所有的临时表都是内存表。
tmp_table_size 这个配置限制了内存临时表的大小,默认值是 16M。如果临时表大小超过了 tmp_table_size,那么内存临时表就会转成磁盘临时表。
磁盘临时表使用的引擎默认是 InnoDB,是由参数 internal_tmp_disk_storage_engine 控制的。
当使用磁盘临时表的时候,对应的就是一个没有显式索引的 InnoDB 表的排序过程。
MySQL 5.6 版本引入的一个新的排序算法,即:优先队列排序算法
但是如果超过了我设置的 sort_buffer_size 大小,所以只能使用归并排序算法,因为要维护的堆太大了。
随机排序方法
mysql> select count(*) into @C from t;
set @Y1 = floor(@C * rand());
set @Y2 = floor(@C * rand());
set @Y3 = floor(@C * rand());
select * from t limit @Y1,1; // 在应用代码里面取 Y1、Y2、Y3 值,拼出 SQL 后执行
select * from t limit @Y2,1;
select * from t limit @Y3,1;
18 | 为什么这些SQL语句逻辑相同,性能却差异巨大?
在 MySQL 中,有很多看上去逻辑相同,但性能却差异巨大的 SQL 语句。对这些语句使用不当的话,就会不经意间导致整个数据库的压力变大。
案例一:条件字段函数操作
更新中…………
小结
对索引字段做函数操作,可能会破坏索引值的有序性,因此优化器就决定放弃走树搜索功能。
MySQL 的优化器确实有“偷懒”的嫌疑,即使简单地把 where id+1=1000 改写成 whereid=1000-1 就能够用上索引快速查找,也不会主动做这个语句重写。
因此,每次你的业务代码升级时,把可能出现的、新的 SQL 语句 explain 一下,是一个很好的习惯。
19 | 为什么我只查一行的语句,也执行这么慢?
场景:
mysql> CREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
在里面插入了 10 万行记录
第一类:查询长时间不返回
mysql> select * from t where id=1;
一般碰到这种情况的话,大概率是表 t 被锁住了。
接下来分析原因的时候,一般都是首先执行一下 show processlist 命令,看看当前语句处于什么状态。
然后我们再针对每种状态,去分析它们产生的原因、如何复现,以及如何处理。
等 MDL 锁
等 flush
等行锁
第二类:查询慢
20 | 幻读是什么,幻读有什么问题?
https://www.cnblogs.com/zwtblog/p/15134977.html
https://www.cnblogs.com/zwtblog/p/15132201.html#基本语法
幻读
在同一个事务内,读取到了别人插入的数据,导致前后读出来结果不一致
如何解决幻读?
现在你知道了,产生幻读的原因是,行锁只能锁住行,
但是新插入记录这个动作,要更新的是记录之间的“间隙”。因此,为了解决幻读问题,InnoDB 只好引入新的锁,也就是间隙锁 (GapLock)。
顾名思义,间隙锁,锁的就是两个值之间的空隙。
间隙锁的引入,可能会导致同样的语句锁住更大的范围,这其实是影响了并发度的。
MySQL实战45讲(16--20)-笔记的更多相关文章
- 《MySQL实战45讲》(1-7)笔记
<MySQL实战45讲>笔记 目录 <MySQL实战45讲>笔记 第一节: 基础架构:一条SQL查询语句是如何执行的? 连接器 查询缓存 分析器 优化器 执行器 第二节:日志系 ...
- 《MySQL实战45讲》(8-15)笔记
MySQL实战45讲 目录 MySQL实战45讲 第八节: 事务到底是隔离的还是不隔离的? 在MySQL里,有两个"视图"的概念: "快照"在MVCC里是怎么工 ...
- 《MySQL实战45讲》学习笔记1——MySQL的基础架构
在<极客时间>订阅了<MySQL实战45讲>专栏,总觉得看完和没看一样
- 《MySQL实战45讲》个人笔记-基础篇
拜读了林晓斌大佬的<MySQL实战45讲>,特意做个知识点总结,以便后期回忆. 01.基础架构:一条SQL查询语句是如何执行的? Server 层包括连接器.查询缓存.分析器.优化器.执行 ...
- 《MySQL实战45讲》学习笔记4——MySQL中InnoDB的索引
索引是在存储引擎层实现的,且在 MySQL 不同存储引擎中的实现也不同,本篇文章介绍的是 MySQL 的 InnoDB 的索引. 下文将以这张表为例开展. # 创建一个主键为 id 的表,表中有字段 ...
- 《MySQL实战45讲》学习笔记2——MySQL的日志系统
一.日志类型 逻辑日志:存储了逻辑SQL修改语句 物理日志:存储了数据被修改的值 二.binlog 1.定义 binlog 是 MySQL 的逻辑日志,也叫二进制日志.归档日志,由 MySQL Ser ...
- 《MySQL实战45讲》学习笔记3——InnoDB为什么采用B+树结构实现索引
索引的作用是提高查询效率,其实现方式有很多种,常见的索引模型有哈希表.有序列表.搜索树等. 哈希表 一种以key-value键值对的方式存储数据的结构,通过指定的key可以找到对应的value. 哈希 ...
- 深挖计算机基础:MySQL实战45讲学习笔记
参考极客时间专栏<MySQL实战45讲>学习笔记 一.基础篇(8讲) MySQL实战45讲学习笔记:第一讲 MySQL实战45讲学习笔记:第二讲 MySQL实战45讲学习笔记:第三讲 My ...
- Mysql实战45讲 04讲深入浅出索引(上)读书笔记 极客时间
极客时间 Mysql实战45讲 04讲深入浅出索引 极客时间(上)读书笔记 笔记体悟 1.索引的作用:提高数据查询效率2.常见索引模型:哈希表.有序数组.搜索树3.哈希表:键 - 值(key - v ...
- 极客时间 Mysql实战45讲 07讲行锁功过:怎么减少行锁对性能的影响笔记 极客时间
极客时间 Mysql实战45讲 07讲行锁功过:怎么减少行锁对性能的影响笔记 极客时间极客时间 Mysql实战45讲 07讲行锁功过:怎么减少行锁对性能的影响笔记 极客时间 笔记体会: 方案一,事务相 ...
随机推荐
- Mybatis学习笔记-缓存
简介 什么是缓存 **将一次查询的结果暂存至内存,后续查询只需查询缓存** 为什么使用缓存 **减少与数据库的交互次数,减少系统开销,提高系统效率** 什么样的数据能使用缓存 **经常查询且不常修改的 ...
- 小白学vue第四天,从入门到放弃(vue指令的使用加高阶函数)
v-on修饰符的使用 .stop 阻止事件冒泡 调用 stopPropagation() .prevent 阻止默认事件 调用 event.preventDefault() .keyCode 键盘事 ...
- 2020互联网寒冬之下,作为一个Android老码农,是如何进入腾讯的?
由于众所周知的原因,原生Android开发如今已经日渐凋敝,作为一个Android程序员,不仅要会Java,Kotlin,JavaScript,Css,Html,还要会Flutter,C++,FFmp ...
- Typora加七牛云实现实时图片自动上传
Typora加七牛云实现实时图片自动上传 前言: Typora是一款轻便简洁的Markdown编辑器,支持即时渲染技术,这也是与其他Markdown编辑器最显著的区别.重点是免费! 其风格简约 ...
- mybatis源码核心代码
/** * mybatis源码测试类 * @param args * @throws IOException * @see org.apache.ibatis.session.Configuratio ...
- 阿里云云服务器 ECS和云数据库 PolarDB的简单使用
阿里云云服务器 ECS和云数据库 PolarDB的简单使用 仅作为记录自己的操作使用,主要是怕自己太久不用都忘了 登录阿里云以后点击控制台 然后找到云服务器ECS,点击进入 在左侧找到实例,点击进入 ...
- docker容器dockerfile详解
docker公司在容器技术发展中提出了镜像分层的理念,可以说也是这个革命性的理念让原本只不过是整合linux内核特性的容器,开始野蛮生长. docker通过UnionFS联合文件系统将镜像的分层实现合 ...
- NOIP 模拟 $34\; \rm Equation$
题解 \(by\;zj\varphi\) 发现每个点的权值都可以表示成 \(\rm k\pm x\). 那么对于新增的方程,\(\rm x_u+x_v=k\pm x/0\) 且 \(\rm x_u+x ...
- NOIP 模拟 $29\; \rm 最近公共祖先$
题解 \(by\;zj\varphi\) 首先考虑,如果将一个点修改成了黑点,那么它能够造成多少贡献. 它先会对自己的子树中的答案造成 \(w_x\) 的贡献. 考虑祖先时,它会对不包括自己的子树造成 ...
- Python实现发送邮件(实现单发/群发邮件验证码)
Python smtplib 教程展示了如何使用 smtplib 模块在 Python 中发送电子邮件. 要发送电子邮件,我们使用 Python 开发服务器,Mailtrap 在线服务和共享的网络托管 ...