opencv——PCA(主要成分分析)数学原理推导
引言:
最近一直在学习主成分分析(PCA),所以想把最近学的一点知识整理一下,如果有不对的还请大家帮忙指正,共同学习。
首先我们知道当数据维度太大时,我们通常需要进行降维处理,降维处理的方式有很多种,PCA主成分分析法是一种常用的一种降维手段,它主要是基于方差来提取最有价值的信息,虽然降维之后我们并不知道每一维度的数据代表什么意义,但是它将主要的信息成分保留了下来,那么PCA是如何实现的呢?
本文详细推导了PCA的数学原理,最后以实例进行演算。
PCA的数学原理
(一)降维问题
大家都知道,PCA主要是用来将高维数据降为低维数据,并保留主要成分的。但是降维的现实意义是什么呢?如何保留主要成分呢?
一般情况下,在数据挖掘和机器学习中,数据被表示为向量。例如某个淘宝店2020年全年的流量及交易情况可以看成一组记录的集合,其中每一天的数据是一条记录,格式如下:
( 浏览量, 访客数, 下单数, 成交数, 成交金额)T=(500,240,25,13,2312.15)T
我们对这组5维向量进行降维分析:
从经验我们可以知道,“浏览量”和“访客数”往往具有较强的相关关系,而“下单数”和“成交数”也具有较强的相关关系。这里我们非正式的使用“相关关系”这个词,可以直观理解为“当某一天这个店铺的浏览量较高(或较低)时,我们应该很大程度上认为这天的访客数也较高(或较低)”。这种情况表明,如果我们删除浏览量或访客数其中一个指标,我们应该期待并不会丢失太多信息。因此我们可以删除一个,以降低机器学习算法的复杂度。
这就是降维的朴素思想描述,可以有助于直观理解降维的动机和可行性,但并不具有操作指导意义。
那么我们到底删除哪一列损失的信息才最小?亦或根本不是单纯删除几列,而是通过某些变换将原始数据变为更少的列但又使得丢失的信息最小?到底如何度量丢失信息的多少?如何根据原始数据决定具体的降维操作步骤?
要想回答这些问题,就要一步一步分析,推导PCA背后的数学原理。
(二)向量的表示及基变换
既然我们面对的数据被抽象为一组向量,那么下面有必要研究一些向量的数学性质。而这些数学性质将成为后续导出PCA的理论基础。
1️⃣内积与投影
两个维数相同的向量的内积被定义为(高中知识):
(a1,a2,⋯,an)T⋅(b1,b2,⋯,bn)T=a1b1+a2b2+⋯+anbn
内积运算将两个向量映射为一个实数。其计算方式非常容易理解,但是其意义并不明显。下面我们分析内积的几何意义。
假设A和B是两个2维向量(为了简单起见),A=(x1,y1),B=(x2,y2)。则在二维平面上A和B可以用两条发自原点的有向线段表示,见下图:
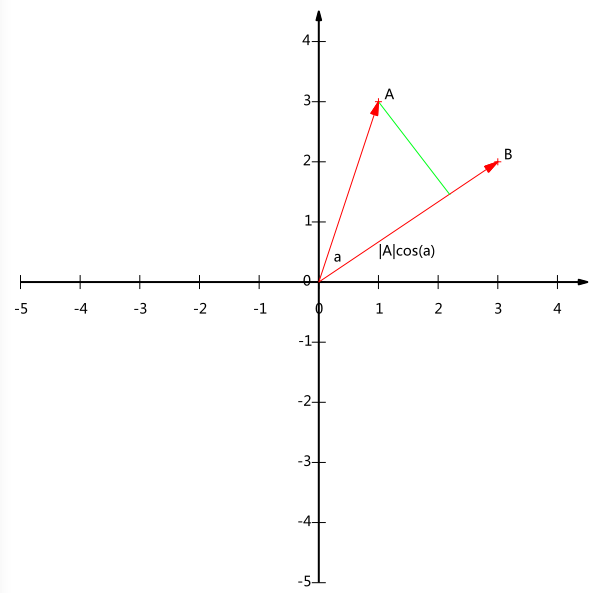
设A与B的夹角是a,则A在B上的投影为|A|cos(a)
我们将内积表示为另一种我们熟悉的形式:
A⋅B=|A||B|cos(a)
2️⃣基的定义
我们都知道一个二维向量可以对应二维笛卡尔直角坐标系中从原点出发的一个有向线段。例如下面这个向量:
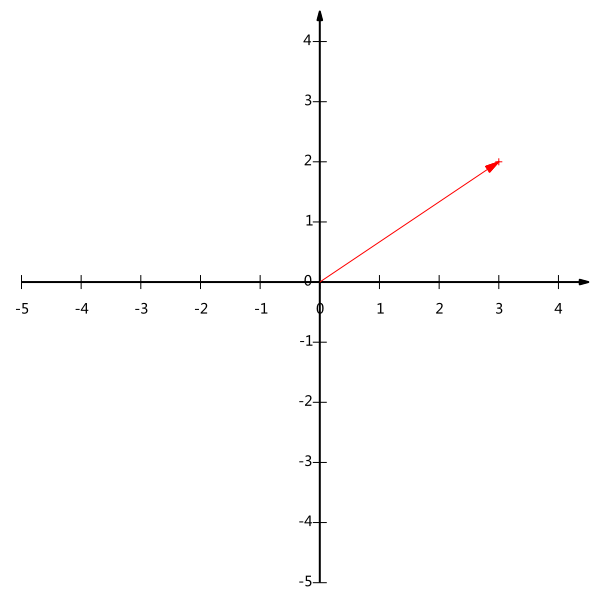
很容易就能看得出来,这个向量表示为(3,2)。不过我们常常忽略,只有一个(3,2)本身是不能够精确表示一个向量的。我们仔细看一下,这里的3实际表示的是向量在x轴上的投影值是3,在y轴上的投影值是2。也就是说我们其实隐式引入了一个定义:以x轴和y轴上正方向长度为1的向量为标准。那么一个向量(3,2)实际是说在x轴投影为3而y轴的投影为2。注意投影是一个矢量,所以可以为负。
更正式的说,向量(x,y)实际上表示线性组合:
x(1,0)T+y(0,1)T
不难证明所有二维向量都可以表示为这样的线性组合。此处(1,0)和(0,1)叫做二维空间中的一组基。所以,要准确描述向量,首先要确定一组基,然后给出在基所在的各个直线上的投影值,就可以了。
我们之所以默认选择(1,0)和(0,1)为基,当然是比较方便,例如,(1,1)和(-1,1)也可以成为一组基。一般来说,我们希望基的模是1,因为从内积的意义可以看到,如果基的模是1,那么就可以方便的用向量点乘基而直接获得其在新基上的坐标了!实际上,对应任何一个向量我们总可以找到其同方向上模为1的向量,只要让两个分量分别除以模就好了(单位化)。例如,上面的基可以变为 。那么(3,2)在新基的坐标就是
。那么(3,2)在新基的坐标就是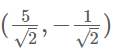 。下图给出了新的基以及(3,2)在新基上坐标值的示意图:
。下图给出了新的基以及(3,2)在新基上坐标值的示意图:
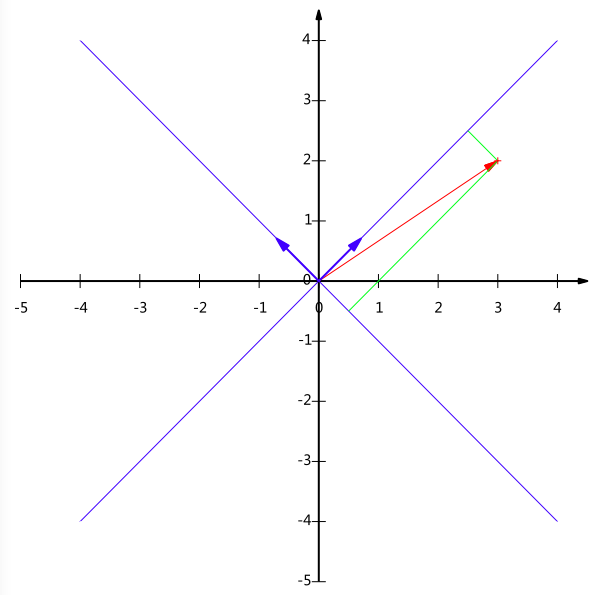
另外这里要注意的是,我们列举的例子中基是正交的(即内积为0,或直观说相互垂直),但可以成为一组基的唯一要求就是线性无关,非正交的基也是可以的。不过因为正交基有较好的性质,所以一般使用的基都是正交的。
3️⃣基变换(降维变换)
下面我们找一种简便的方式来表示基变换。我们可以用矩阵相乘的形式简洁的表示这个变换:
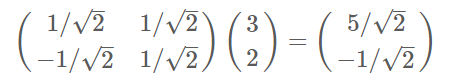
稍微推广一下,如果我们有m个二维向量,只要将二维向量按列排成一个两行m列矩阵,然后用“基矩阵”乘以这个矩阵,就得到了所有这些向量在新基下的值。例如(1,1),(2,2),(3,3),想变换到刚才那组基上,则可以这样表示:
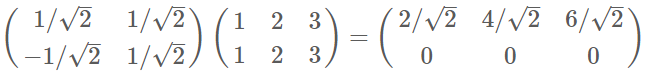
于是一组向量的基变换被干净的表示为矩阵的相乘。
一般的,如果我们有M个N维向量,想将其变换为由R个N维向量表示的新空间中,那么首先将R个基按行组成矩阵A,然后将向量按列组成矩阵B,那么两矩阵的乘积AB就是变换结果,其中AB的第m列为A中第m列变换后的结果。
其数学表达式为:
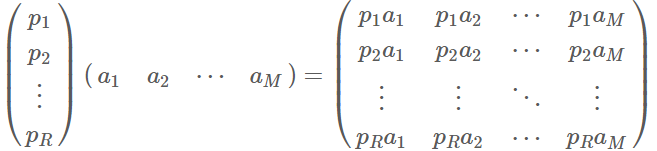
其中,pi表示为R个N维行向量。aj表示M个N维列向量。(基按行排列,向量按列排列,R决定了变换后数据的维数。)
因此我们可以发现,当R小于N时,N维数据变换到更低维度的空间中去,变换后的维度取决于基的数量。因此这种矩阵相乘的表示也可以表示降维变换。
最后,上述分析同时给矩阵相乘找到了一种物理解释:两个矩阵相乘的意义是将右边矩阵中的每一列列向量变换到左边矩阵中每一行行向量为基所表示的空间中去。更抽象的说,一个矩阵可以表示一种线性变换。
4️⃣协方差矩阵(优化目标)
我们已经知道了如果基的数量少于向量本身的维数,则可以达到降维的效果。但是我们还没有回答一个最最关键的问题:如何选择基才是最优的。或者说,如果我们有一组N维向量,现在要将其降到K维(K小于N),那么我们应该如何选择K个基才能最大程度保留原有的信息?
为了避免过于抽象的讨论,我们仍以一个具体的例子展开。假设我们的数据由五条记录组成,将它们表示成矩阵形式:

其中每一列为一条数据记录,而一行为一个字段。为了后续处理方便,我们首先将每个字段内所有值都减去字段均值(一行取均值),其结果是将每个字段都变为均值为0。

我们可以看下五条数据在平面直角坐标系内的样子:
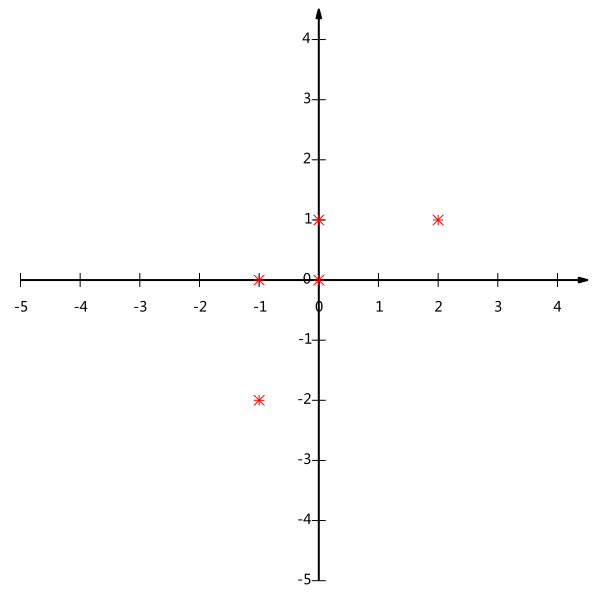
如果我们必须使用一维来表示这些数据(降维),又希望尽量保留原始的信息,该如何选择?
这个问题实际上是要在二维平面中选择一个方向,将所有数据都投影到这个方向所在直线上,用投影值表示原始记录。这是一个实际的二维降到一维的问题。
那么如何选择这个方向(或者说基)才能尽量保留最多的原始信息呢?一种直观的看法是:希望投影后的投影值尽可能分散。
以上图为例,可以看出如果向x轴投影(做垂线),那么最左边的两个点会重叠在一起,中间的两个点也会重叠在一起,于是本身四个各不相同的二维点投影后只剩下两个不同的值了,这是一种严重的信息丢失,同理,如果向y轴投影也会重叠。所以看来x和y轴都不是最好的投影选择。我们直观目测,如果向通过第一象限和第三象限的斜线投影,则五个点在投影后还是可以区分的。
下面,我们用数学方法表述这个问题。
5️⃣方差(表示分散程度)
我们希望投影后投影值尽可能分散,而这种分散程度,可以用数学上的方差来表述。因此,一个字段的方差可以看做是每个元素与字段均值的差的平方和的均值,即:
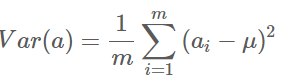
由于上面我们已经将每个字段的均值都化为0了,因此方差可以直接用每个元素的平方和除以元素个数表示:

于是上面的问题被形式化表述为:寻找一个一维基,使得所有数据变换为这个基上的坐标表示后,方差值最大。
6️⃣协方差(表示相关性)
对于上面二维降成一维的问题来说,找到那个使得方差最大的方向就可以了。不过对于更高维,我们还需要寻找其他的投影方向。比如三维降到二维问题。与之前相同,首先我们希望找到一个方向使得投影后方差最大,这样就完成了第一个方向的选择,继而我们选择第二个投影方向。
要让两个字段尽可能表示更多的原始信息,我们还是不希望它们之间存在(线性)相关性的,因为相关性意味着两个字段不是完全独立,必然存在重复表示的信息。
数学上可以用两个字段的协方差表示其相关性,由于已经让每个字段均值为0,则:
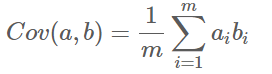
可以看到,在字段均值为0的情况下,两个字段的协方差简洁的表示为其内积除以元素数m。
当协方差为0时,表示两个字段完全独立。为了让协方差为0,我们选择第二个基时只能在与第一个基正交的方向上选择。因此最终选择的两个方向一定是正交的。
至此,我们得到了降维问题的优化目标:将一组N维向量降为K维(K大于0,小于N),其目标是选择K个单位(模为1)正交基,使得原始数据变换到这组基上后,各字段两两间协方差为0,而字段的方差则尽可能大(在正交的约束下,取最大的K个方差)。
7️⃣协方差矩阵(将方差和协方差统一表示)
上面虽然我们确定了优化目标,但是很难直接去实现它。因为它只说要什么,但根本没有说怎么做。所以我们要继续在数学上研究计算方案。
我们看到,最终要达到的目的与字段内方差及字段间协方差有密切关系。因此我们希望能将两者统一表示,仔细观察发现,两者均可以表示为内积的形式,而内积又与矩阵相乘密切相关。
假设我们只有a和b两个字段,那么我们将它们按行组成矩阵X:
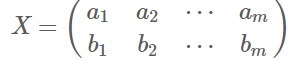
然后我们用X乘以X的转置,并乘上系数1/m:
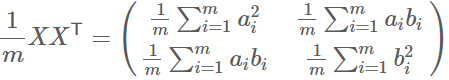
我们可以发现对角线上的两个元素分别是两个字段的方差,而其它元素是a和b的协方差。两者被统一到了一个矩阵的。
根据矩阵相乘的运算法则,这个结论很容易被推广到一般情况:
设我们有m个n维数据记录,将其按列排成n乘m的矩阵X,设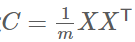 则C是一个对称矩阵,其对角线分别个各个字段的方差,而第i行j列和j行i列元素相同,表示i和j两个字段的协方差。
则C是一个对称矩阵,其对角线分别个各个字段的方差,而第i行j列和j行i列元素相同,表示i和j两个字段的协方差。
8️⃣协方差矩阵对角化
根据上述推导,我们发现要达到优化目标(方差最大,协方差为0),等价于将协方差矩阵对角化:即除对角线外的其它元素化为0,并且在对角线上将元素按大小从上到下排列,这样我们就达到了优化目的。
我们进一步看下原矩阵的协方差矩阵与基变换后矩阵的协方差矩阵的关系:
设原始数据矩阵X对应的协方差矩阵为C,而P是一组基按行组成的矩阵,设Y=PX,则Y为X对P做基变换后的数据。设Y的协方差矩阵为D,我们推导一下D与C的关系:
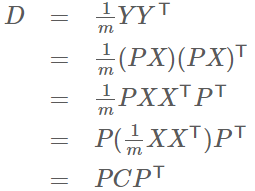
到此优化目标变成了寻找一个矩阵P,满足PCPT是一个对角矩阵,并且对角元素按从大到小依次排列,那么P的前K行就是要寻找的基,用P的前K行组成的矩阵乘以X就使得X从N维降到了K维并满足上述优化条件。
最后一步!!
由上文知道,协方差矩阵C是一个是对称矩阵,在线性代数上,实对称矩阵有一系列非常好的性质:
1)实对称矩阵不同特征值对应的特征向量必然正交。
2)设特征向量λλ重数为r,则必然存在r个线性无关的特征向量对应于λ,因此可以将这r个特征向量单位正交化。
由上面两条可知,一个n行n列的实对称矩阵一定可以找到n个单位正交特征向量,设这n个特征向量为e1,e2,⋯,en,我们将其按列组成矩阵:
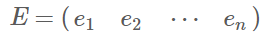
则对协方差矩阵C有如下结论:
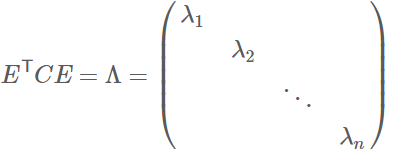
其中Λ为对角矩阵,其对角元素为各特征向量对应的特征值(可能有重复)。
至此我们完成了整个PCA的数学原理讨论!!
PCA实例
为了巩固上面的理论,我们在这一节给出一个具体的PCA实例。
PCA算法
总结一下PCA的算法步骤:
设有m条n维数据。
1)将原始数据按列组成n行m列矩阵X
2)将X的每一行(代表一个属性字段)进行零均值化,即减去这一行的均值
3)求出协方差矩阵
4)求出协方差矩阵的特征值及对应的特征向量
5)将特征向量按对应特征值大小从上到下按行排列成矩阵,取前k行组成矩阵P
6)Y=PX即为降维到k维后的数据
实例:
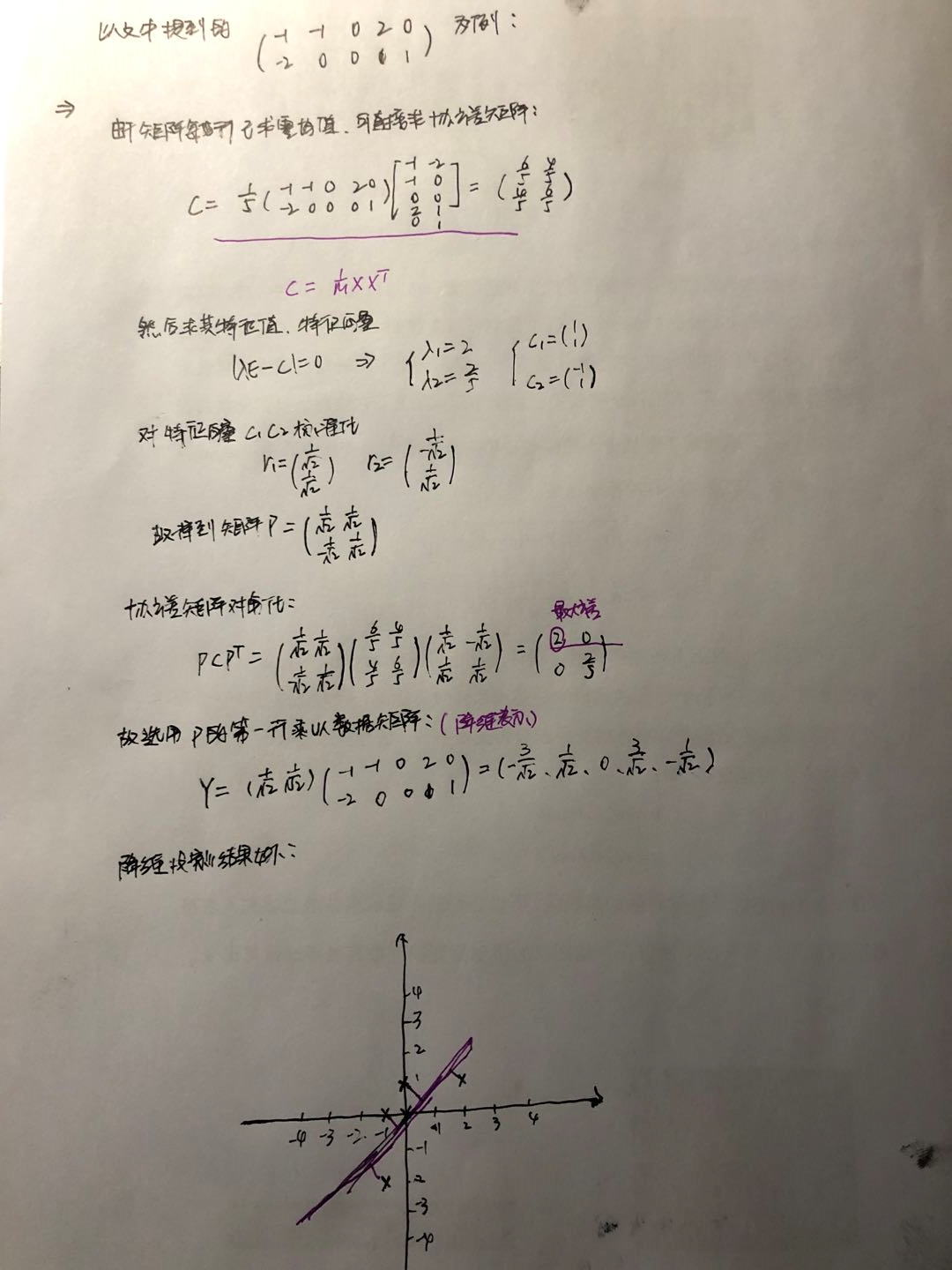
总结:
根据上面对PCA的数学原理的解释,对PCA的理解有一个更深入的认知。PCA本质上是将方差最大的方向作为主要特征,并且在各个正交方向上将数据“离相关”,也就是让它们在不同正交方向上没有相关性。
因此,PCA也存在一些限制,例如它可以很好的解除线性相关,但是对于高阶相关性就没有办法了,对于存在高阶相关性的数据,可以考虑Kernel PCA,通过Kernel函数将非线性相关转为线性相关,另外,PCA假设数据各主特征是分布在正交方向上,如果在非正交方向上存在几个方差较大的方向,PCA的效果就大打折扣了。
最后需要说明的是,PCA是一种无参数技术,也就是说面对同样的数据,如果不考虑清洗,谁来做结果都一样,没有主观参数的介入,所以PCA便于通用实现,但是本身无法个性化的优化。
参考博文:(9条消息) PCA(主成分分析)-------原理,推导,步骤、实例、代码_xxty1122的博客-CSDN博客_pca主成分分析
Object Orientation, Principal Component Analysis & OpenCV | Robospace (wordpress.com)
opencv学习之路(39)、PCA - 进击的小猴子 - 博客园 (cnblogs.com)
opencv——PCA(主要成分分析)数学原理推导的更多相关文章
- PCA主成分分析算法的数学原理推导
PCA(Principal Component Analysis)主成分分析法的数学原理推导1.主成分分析法PCA的特点与作用如下:(1)是一种非监督学习的机器学习算法(2)主要用于数据的降维(3)通 ...
- SVM数学原理推导&鸢尾花实例
//看了多少遍SVM的数学原理讲解,就是不懂,对偶形式推导也是不懂,看来我真的是不太适合学数学啊,这是面试前最后一次认真的看,并且使用了sklearn包中的SVM来进行实现了一个鸢尾花分类的实例,进行 ...
- SVM数学原理推导
//2019.08.17 #支撑向量机SVM(Support Vector Machine)1.支撑向量机SVM是一种非常重要和广泛的机器学习算法,它的算法出发点是尽可能找到最优的决策边界,使得模型的 ...
- 机器学习 - 算法 - Xgboost 数学原理推导
工作原理 基于集成算法的多个树累加, 可以理解为是弱分类器的提升模型 公式表达 基本公式 目标函数 目标函数这里加入了损失函数计算 这里的公式是用的均方误差方式来计算 最优函数解 要对所有的样本的损失 ...
- PCA的数学原理
PCA(Principal Component Analysis)是一种常用的数据分析方法.PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维 数据的 ...
- PCA数学原理
PCA(Principal Component Analysis)是一种常用的数据分析方法.PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维数据的降 ...
- PCA的数学原理(转)
PCA(Principal Component Analysis)是一种常用的数据分析方法.PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维数据的降 ...
- pca数学原理(转)
PCA的数学原理 前言 数据的向量表示及降维问题 向量的表示及基变换 内积与投影 基 基变换的矩阵表示 协方差矩阵及优化目标 方差 协方差 协方差矩阵 协方差矩阵对角化 算法及实例 PCA算法 实例 ...
- 图像处理中的数学原理具体解释21——PCA实例与图像编码
欢迎关注我的博客专栏"图像处理中的数学原理具体解释" 全文文件夹请见 图像处理中的数学原理具体解释(总纲) http://blog.csdn.net/baimafujinji/ar ...
随机推荐
- malloc函数详解 glibc2.27
malloc 函数分析(glibc.2.27) 本人菜一只,如果分析的有错误,请大佬指正. __libc_malloc函数分析 void * __libc_malloc (size_t bytes) ...
- inline®ister
inline关键字: 内联只是一个请求,不代表编译器会响应:同时某些编译器会将一些函数优化成为内联函数. C++在类内定义的函数默认是内联函数,具体是否真变成内联函数还需看编译器本身. registe ...
- JVM小册(1)------jstat和Parallel GC日志
JVM小册(1)------jstat和Parallel GC日志 一. 背景 在生产环境中,有时候会遇到OOM的情况,抛开Arthas 等比较成熟的工具以外,我们可以使用java 提供的jatat和 ...
- Weekly Contest 184
1408. String Matching in an Array Given an array of string words. Return all strings in words which ...
- 【秒懂音视频开发】21_显示BMP图片
文本的主要内容是:使用SDL显示一张BMP图片,算是为后面的<播放YUV>做准备. 为什么是显示BMP图片?而不是显示JPG或PNG图片? 因为SDL内置了加载BMP的API,使用起来会更 ...
- DVWA之File Inclusion(文件包含)
目录 LOW: Medium: High Impossible LOW: 源代码: <?php // The page we wish to display $file = $_GET[ 'pa ...
- UVA10943简单递推
题意: 给你两个数字n,k,意思是用k个不大于n的数字组合(相加和)为n一共有多少种方法? 思路: 比较简单的递推题目,d[i][j]表示用了i个数字的和为j一共有多少种情况,则 ...
- Windows核心编程 第27章 硬件输入模型和局部输入状态
第27章 硬件输入模型和局部输入状态 这章说的是按键和鼠标事件是如何进入系统并发送给适当的窗口过程的.微软设计输入模型的一个主要目标就是为了保证一个线程的动作不要对其他线程的动作产生不好的影响. 27 ...
- postgresql高级应用之合并单元格
postgresql高级应用之合并单元格 转载请注明出处https://www.cnblogs.com/funnyzpc/p/14732172.html 1.写在前面✍ 继上一篇postgresql高 ...
- 【Git】3. Git重要特性-分支操作,合并冲突详解
一.分支介绍 在版本控制过程当中,有时候需要同时推进多个任务,这样的话,就可以给每个任务创建单独的分支. 有了分支之后,对应的开发人员就可以把自己的工作从主线上分离出来,在做自己分支开发的时候,不会影 ...