大数据学习(25)—— 用IDEA搭建Spark开发环境
IDEA是一个优秀的Java IDE工具,它同样支持其他语言。Spark是用Scala语言编写的,用Scala开发Spark是最舒畅的。当然,Spark也提供Java和Python的API。
Java是一门热度很高的开发语言,也是一个高龄语言。Java本身很牛逼,但它最牛逼的地方是——成就了JVM。
基于JVM的语言非常多,常用的除了Java还有Scala、Groovy、Kotlin、Clojure。能编译成字节码的语言,都能在JVM上运行。
Scala
Scala 是一门多范式(multi-paradigm)的编程语言,设计初衷是要集成面向对象编程和函数式编程的各种特性。
Scala 运行在 Java 虚拟机上,并兼容现有的 Java 程序。
Scala 源代码被编译成 Java 字节码,所以它可以运行于 JVM 之上,并可以调用现有的 Java 类库。
与JAVA的区别
我们学习的是大数据,重点不在于Scala用的有多么溜,够用就行。作为一个从Java上手的码农,我感觉Java是一个古板先生,语言和语法都规规矩矩,显得有点儿臃肿。Scala像一个翩翩少年,没那么多束缚,语法天马行空,用行话说就是“有很甜的语法糖”,一个API可以做很多事。用惯了Scala的数据集操作,简直就不想再用Java的那一套,什么都要自己写,太麻烦了。当然,想招聘一个精通Scala的人,这个难度比招一个精通Java的人要大得多,毕竟用的人少。
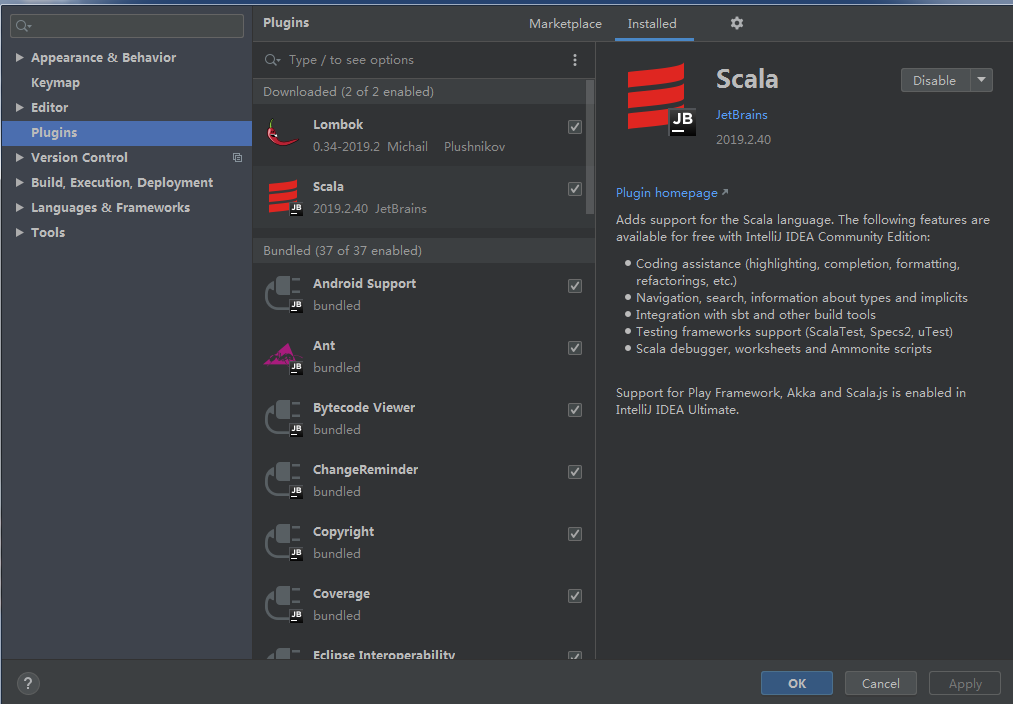
IDEA安装Scala插件
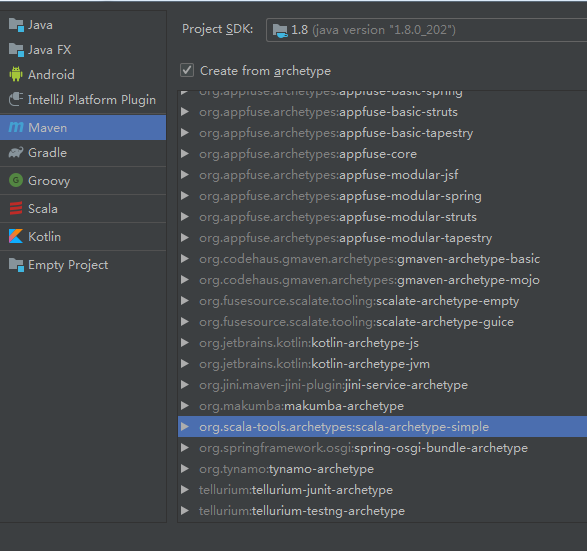
创建Scala Maven项目
建好项目把App、AppTest、MySpec三个类删掉。修改pom文件里scala的版本号。
<properties>
<scala.version>2.12.0</scala.version>
</properties>
引入spark-core依赖。
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.1.2</version>
</dependency>
编写Scala代码
环境配好之后,可以写代码了。创建一个Scala的Object,它可以运行main方法。
package com.xy
import org.apache.spark.{SparkConf, SparkContext}
object Test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Test").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("ERROR")
val rdd = sc.parallelize(Array(1,2,3,2,1,4,5,2))
val kv = rdd.map(x=>(x,1)).reduceByKey(_+_)
kv.foreach(println)
}
}
从(1,2,3,2,1,4,5,2)这个数据集里计算每个数字出现的次数,运行结果如下。
(4,1)
(1,2)
(3,1)
(5,1)
(2,3) Process finished with exit code 0
大数据学习(25)—— 用IDEA搭建Spark开发环境的更多相关文章
- PyCharm搭建Spark开发环境 + 第一个pyspark程序
一, PyCharm搭建Spark开发环境 Windows7, Java 1.8.0_74, Scala 2.12.6, Spark 2.2.1, Hadoop 2.7.6 通常情况下,Spark开发 ...
- Intellij IDEA使用Maven搭建spark开发环境(scala)
如何一步一步地在Intellij IDEA使用Maven搭建spark开发环境,并基于scala编写简单的spark中wordcount实例. 1.准备工作 首先需要在你电脑上安装jdk和scala以 ...
- 大数据学习系列之八----- Hadoop、Spark、HBase、Hive搭建环境遇到的错误以及解决方法
前言 在搭建大数据Hadoop相关的环境时候,遇到很多了很多错误.我是个喜欢做笔记的人,这些错误基本都记载,并且将解决办法也写上了.因此写成博客,希望能够帮助那些搭建大数据环境的人解决问题. 说明: ...
- Intellij Idea搭建Spark开发环境
在Spark高速入门指南 – Spark安装与基础使用中介绍了Spark的安装与配置.在那里还介绍了使用spark-submit提交应用.只是不能使用vim来开发Spark应用.放着IDE的方便不用. ...
- 大数据学习系列之Hadoop、Spark学习线路(想入门大数据的童鞋,强烈推荐!)
申明:本文出自:http://www.cnblogs.com/zlslch/p/5448857.html(该博客干货较多) 1 Java基础: 视频方面: 推荐<毕向东JAVA ...
- 大数据学习——HADOOP集群搭建
4.1 HADOOP集群搭建 4.1.1集群简介 HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起 HDFS集群: 负责海量数据的存储,集群中的角色主 ...
- 大数据学习——hadoop集群搭建2.X
1.准备Linux环境 1.0先将虚拟机的网络模式选为NAT 1.1修改主机名 vi /etc/sysconfig/network NETWORKING=yes HOSTNAME=itcast ### ...
- 大数据学习之scala-环境搭建
scala 下载网站 https://www.scala-lang.org/download/ 安装scala要先安装java,并且配置java环境,官网也有说明 不过国内的网站下载不下来可以访问: ...
- 大数据学习——Storm集群搭建
安装storm之前要安装zookeeper 一.安装storm步骤 1.下载安装包 2.解压安装包 .tar.gz storm 3.修改配置文件 mv /root/apps/storm/conf/st ...
随机推荐
- Linux常见信号介绍
1.信号 首先信号我们要和信号量区分开来,虽然两者都是操作系统进程通信的方式.可以简单的理解,信号是用来通知进程发生了什么需要做什么,信号量一般是用作进程同步(pv操作) 2.常见信号量 (以下数字标 ...
- ClickHouse学习系列之七【系统命令介绍】
背景 前面介绍了ClickHouse相关的系列文章,该系列文章包括了安装.权限管理.副本分片.配置说明等.这次介绍一些ClickHouse相关的系统命令,如重载配置文件.关闭服务和进程.停止和启动后 ...
- 附加数据库出现 无法打开物理文件 操作系统错误 5:拒绝访问 SQL
刚刚从公司的电脑上考到自己刚刚装好系统的笔记本上面,出现了问题: 无法打开物理文件 操作系统错误 5:拒绝访问 . 网上找了下解决方法: 找到需要导入的 mdf和ldf 修改它的权限为完全控制,不 ...
- sys用户权限不足,本地登录失败 |ORA-01031 insufficient privileges|
机器总喜欢挑放假的时候出问题,"双节"(中秋.国庆)快到了,对于搞系统运维的工程师来说其实并不轻松,于是今天赶紧装起一台数据库备用服务器以备半夜"机"叫. 安装 ...
- 并发王者课-铂金9:互通有无-Exchanger如何完成线程间的数据交换
欢迎来到<并发王者课>,本文是该系列文章中的第22篇,铂金中的第9篇. 在前面的文章中,我们已经介绍了ReentrantLock,CountDownLatch,CyclicBarrier, ...
- “限时分享“ 本地80个小游戏 HTML+CSS+JS源码分享
里面有80款小游戏源码,支持内置导航,可以拿来练手或者消磨时间,具体功能以及游戏请看下图 维京战争小游戏源码 链接:https://pan.baidu.com/s/ ...
- .NET Core授权失败如何自定义响应信息?
前言 在.NET 5之前,当授权失败即403时无法很友好的自定义错误信息,以致于比如利用Vue获取到的是空响应,不能很好的处理实际业务,同时涉及到权限粒度控制到控制器.Action,也不能很好的获取对 ...
- 暑假自学java第四天
今天学习了类 1,声明并实例化 :类名 对象名 = new 类名([参数1 ,参数2,....]):例:Car bus =new car (); 2,调用类的方法 :对象名.方法名(参 ...
- php 扩展 rabbitmq popt
首先是rabbitmq-c-master.tar.gz包, 可以访问https://github.com/alanxz/rabbitmq-c去下载最新的 wget https://github.com ...
- XCTF logmein
一.查壳 发现是64位的Linux文件(ELF可以看出是linux的文件) 二.拖入ida64,静态分析 注意这里两个坑: 1.strcpy是复制字符串的意思,前面定义的v8数组只有8个,但是后面的字 ...