Kubernetes client-go Indexer / ThreadSafeStore 源码分析
Contents
概述
源码版本信息
- Project: kubernetes
- Branch: master
- Last commit id: d25d741c
- Date: 2021-09-26
Indexer 主要依赖于 ThreadSafeStore 实现,是 client-go 提供的一种缓存机制,通过检索本地缓存可以有效降低 apiserver 的压力,我们在自定义控制器里调用一个 List() 方法带一个 ListOption 本质就是加上条件检索了 Indexer,掌握 Indexer 的实现可以在 Operator 编码时更加心里有底。
Indexer 接口
Indexer 接口主要是在 Store 接口的基础上拓展了对象的检索功能
- client-go/tools/cache/index.go:35
|
|
Indexer 的默认实现是 cache
|
|
cache 对应两个方法体实现完全一样的 New 函数:
|
|
这里涉及到两个类型:
- KeyFunc
- ThreadSafeStore
我们先看一下 Indexer 的 Add()、Update() 等方法是怎么实现的:
|
|
可以看到这里的逻辑就是调用 keyFunc() 方法获取 key,然后调用 cacheStorage.Xxx() 方法完成对应增删改查过程。KeyFunc 类型时这样定义的:
|
|
也就是给一个对象,返回一个字符串类型的 key。KeyFunc 的一个默认实现如下:
|
|
可以看到一般情况下返回值是 <namespace><name> ,如果 namespace 为空则直接返回 name。类似的还有一个叫做 IndexFunc 的类型,定义如下:
|
|
这是给一个对象生成 Index 用的,一个通用实现如下,直接返回对象的 namespace 字段作为 Index
|
|
下面我们直接来看 cacheStorage 是如果实现增删改查的。
ThreadSafeStore
ThreadSafeStore 是 Indexer 的核心逻辑所在,Indexer 的多数方法是直接调用内部 cacheStorage 属性的方法实现的,同样先看接口定义:
- client-go/tools/cache/thread_safe_store.go:41
|
|
对应实现:
|
|
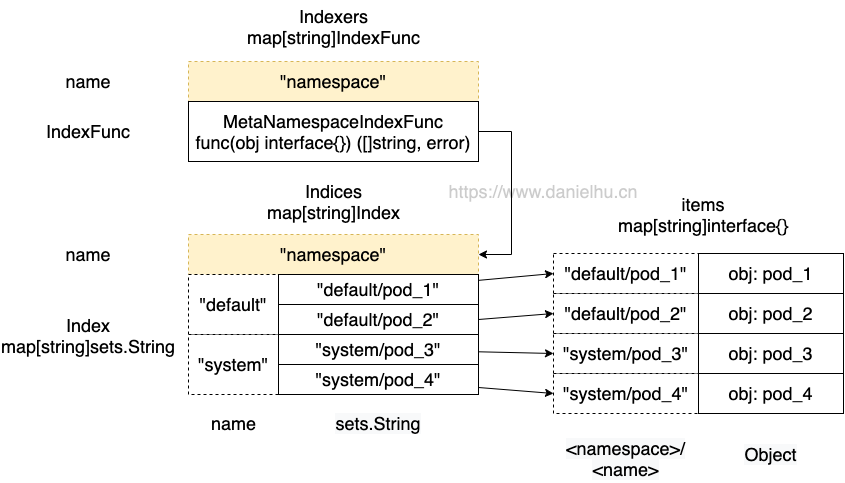
这里的 Indexers 和 Indices 是:
|
|
对照图片理解一下这几个字段的关系:Indexers 里存的是 Index 函数 map,一个典型的实现是字符串 namespace 作为 key,IndexFunc 类型的实现 MetaNamespaceIndexFunc 函数作为 value,也就是我们希望通过 namespace 来检索时,通过 Indexers 可以拿到对应的计算 Index 的函数,接着拿着这个函数,把对象穿进去,就可以计算出这个对象对应的 key,在这里也就是具体的 namespace 值,比如 default、kube-system 这种。然后在 Indices 里存的也是一个 map,key 是上面计算出来的 default 这种 namespace 值,value 是一个 set,而 set 表示的是这个 default namespace 下的一些具体 pod 的 <namespace>/<name> 这类字符串。最后拿着这种 key,就可以在 items 里检索到对应的对象了。
threadSafeMap.Xxx()
比如 Add() 方法代码如下:
|
|
可以看到更复杂的逻辑在 updateIndices 方法里,我们继续来看:
- client-go/tools/cache/thread_safe_store.go:256
|
|
上面还提到了一个 deleteFromIndices 方法,前半段和上面逻辑上类似的,最后拿到 set 后不同于上面的 Insert 过程,这里调用了一个 Delete。
|
|
Index() 等实现
最后看几个具体方法等实现
Index() 方法
来看一下 Index() 方法的实现,Index() 方法的作用是给定一个 obj 和 indexName,比如 pod1和 “namespace”,然后返回 pod1 所在 namespace 下的所有 pod。
- client-go/tools/cache/thread_safe_store.go:141
|
|
ByIndex() 方法
相比 Index(),这个函数要简单的多,直接传递 indexedValue,也就不需要通过 obj 去计算 key 了,例如 indexName == namespace & indexValue == default 就是直接检索 default 下的资源对象。
|
|
IndexKeys() 方法
和上面返回 obj 列表不同,这里只返回 key 列表,就是 []string{“default/pod_1”} 这种数据
|
|
Replace() 方法
Replace() 的实现简单粗暴,给一个新 items map,直接替换到 threadSafeMap.items 中,然后重建索引。
|
|
(转载请保留本文原始链接)
https://www.danielhu.cn/post/k8s/client-go-indexer/
Kubernetes client-go Indexer / ThreadSafeStore 源码分析的更多相关文章
- kubernetes垃圾回收器GarbageCollector Controller源码分析(二)
kubernetes版本:1.13.2 接上一节:kubernetes垃圾回收器GarbageCollector Controller源码分析(一) 主要步骤 GarbageCollector Con ...
- eureka client服务续约源码分析
必备知识: 1.定时任务 ScheduledExecutorService public class demo { public static void main(String[] args){ Sc ...
- Kubernetes client-go DeltaFIFO 源码分析
概述Queue 接口DeltaFIFO元素增删改 - queueActionLocked()Pop()Replace() 概述 源码版本信息 Project: kubernetes Branch: m ...
- Kubernetes client-go Informer 源码分析
概述ControllerController 的初始化Controller 的启动processLoopHandleDeltas()SharedIndexInformersharedIndexerIn ...
- Kubernetes Deployment 源码分析(二)
概述startDeploymentController 入口逻辑DeploymentController 对象DeploymentController 类型定义DeploymentController ...
- client-go客户端自定义开发Kubernetes及源码分析
介绍 client-go 是一种能够与 Kubernetes 集群通信的客户端,通过它可以对 Kubernetes 集群中各资源类型进行 CRUD 操作,它有三大 client 类,分别为:Clien ...
- k8s client-go源码分析 informer源码分析(6)-Indexer源码分析
client-go之Indexer源码分析 1.Indexer概述 Indexer中有informer维护的指定资源对象的相对于etcd数据的一份本地内存缓存,可通过该缓存获取资源对象,以减少对api ...
- 【原】Spark中Client源码分析(二)
继续前一篇的内容.前一篇内容为: Spark中Client源码分析(一)http://www.cnblogs.com/yourarebest/p/5313006.html DriverClient中的 ...
- Docker源码分析(二):Docker Client创建与命令执行
1. 前言 如今,Docker作为业界领先的轻量级虚拟化容器管理引擎,给全球开发者提供了一种新颖.便捷的软件集成测试与部署之道.在团队开发软件时,Docker可以提供可复用的运行环境.灵活的资源配置. ...
随机推荐
- 【转】SpringCloud学习
Spring Cloud Alibaba与Spring Boot.Spring Cloud之间不得不说的版本关系 这篇博文是临时增加出来的内容,主要是由于最近连载<Spring Cloud ...
- vue组件里不用的css还在搜索过滤来删除?试一下vue-clearcss吧!
这篇文章其实是推广介绍我个人的npm工具库,但你不会后悔点进来的(应该吧...)vue-clearcss 为什么要用它? 一个vue文件在长期迭代中css会越来越冗余,它不像html和js那么好删除, ...
- Golang gomail 发送邮件 --初使用
gomail是一个第三方库,可以发送邮件 安装:go get -u github.com/go-gomail/gomail 使用示例: m := gomail.NewMessage() m.SetHe ...
- Linux Ubuntu SVN图形界面 安装使用
安装 sudo apt-get install rapidsvn 使用 rapidsvn
- Dapper同时操作任意多张表的实现
1:Dapper的查询帮助类,部分代码,其它新增更新删除可以自行扩展 using Microsoft.Extensions.Configuration; using System; using Sys ...
- 一个double free相关问题的澄清
引言 前一阵定位 Oracle 的 OCI 接口相关的一个内存释放问题,在网上看到了链接如下的这篇文章: 一个C++bug引入的许多知识 看到后面说 vector 里的两个单元里的内部成员指针地址是一 ...
- 5M1E,软件质量管理最佳解决方案
- 如何做好一个产品? - 用户.需求.文化.价值.设计.流程,这些因素缺一不可.- 那么,如何做好产品的质量管理?- 人.机器.物料.方法.环境.测量,这些因素同样缺一不可.能够影响产品质量波动的因 ...
- LVS实现(VS/DR)负载均衡和Keepalived高可用
LVS是Linux Virtual Server的简写即Linux虚拟服务器,是一个虚拟的服务器集群系统一组服务器通过高速的局域网或者地理分布的广域网相互连接,在它们的前端有一个负载调度器(Load ...
- Tricks
由于本人着实有些菜,因此在此积累一些巧妙的 \(Tricks\) ,以备不时之需... 与其说是 \(Tricks\) 不如说是学习笔记?? 数学 组合数 常见的数列 斐波那契数列 图论 树论 \(P ...
- TreeListLookUpEdit控件使用
绑定数据 treeListLookUpEdit1.Properties.DataSource=list;增加列treeListLookUpEdit1.Properties.TreeList.Colum ...