系统设计实践(03)- Instagram社交服务
前言
系统设计实践篇的文章将会根据《系统设计面试的万金油》为前置模板,讲解数十个常见系统的设计思路。
前置阅读:
设计目标
让我们设计一个像Instagram这样的照片分享的社交网站,用户可以上传照片分享给其他用户。
一. 什么是Instagram?
Instagram是一种社交网络服务,用户可以上传和分享自己的照片、视频给其他用户。Instagram用户可以选择公开或私下分享信息。公开共享的内容都可以被任何其他用户看到,而私有共享的内容只能被指定的一组人访问。Instagram还允许用户通过Facebook、Twitter、Flickr和Tumblr等其他社交网络平台进行分享。
在此,我们计划设计一个更简单的Instagram,用户可以分享照片,也可以关注其他用户。每个用户的动态消息将包含该用户关注的所有人的照片动态。
二. 系统的需求与目标
在设计Instagram时,我们将重点关注以下需求
功能性需求
- 用户可以上传下载查看照片
- 用户可以根据视频或者照片标题搜索
- 用户之间可以互相关注
- 该系统应该能够生成并显示用户关注的所有人的热门照片组成的“新闻动态(News Feed)”。
非功能性需求
- 我们的服务需要高可用性。
- 对于好友动态的生成,系统可接受的延迟是200ms。
- 一致性可能会受到影响(出于可用性的考虑),如果用户一段时间没有看到照片,应该没问题
- 系统应高度可靠;任何上传的照片或视频都不能丢失。
不用考虑
给照片添加标签,在标签上搜索照片,在照片上评论,给照片用户加标签,跟踪谁,等等
三. 系统分析
该系统将具有大量的读操作,因此我们将重点构建一个能够快速检索照片的系统。
- 实际上,用户可以上传任意多的照片。在设计该系统时,有效的存储管理应该是一个关键因素。
- 在查看照片时,预计延迟较低。
- 数据应该是100%可靠的。如果用户上传了一张照片,系统将保证它永远不会丢失。
四. 容量估计与约束
- 假设我们有5亿用户,每天有100万活跃用户
- 每天200万张新照片,每秒23张。
- 平均照片文件大小=> 200KB
- 一天照片需要的存储量
2M * 200KB => 400 GB
- 十年需要的存储空间
400GB * 365(day a year) * 10 (years) ~= 1425TB
五. 高级设计
在高级设计中,我们需要支持两种方案,一种是上传图片,另一种是查看和搜索图片。
我们需要对象存储服务器来存储照片,还需要一些数据库服务器来存储关于照片的元数据信息。
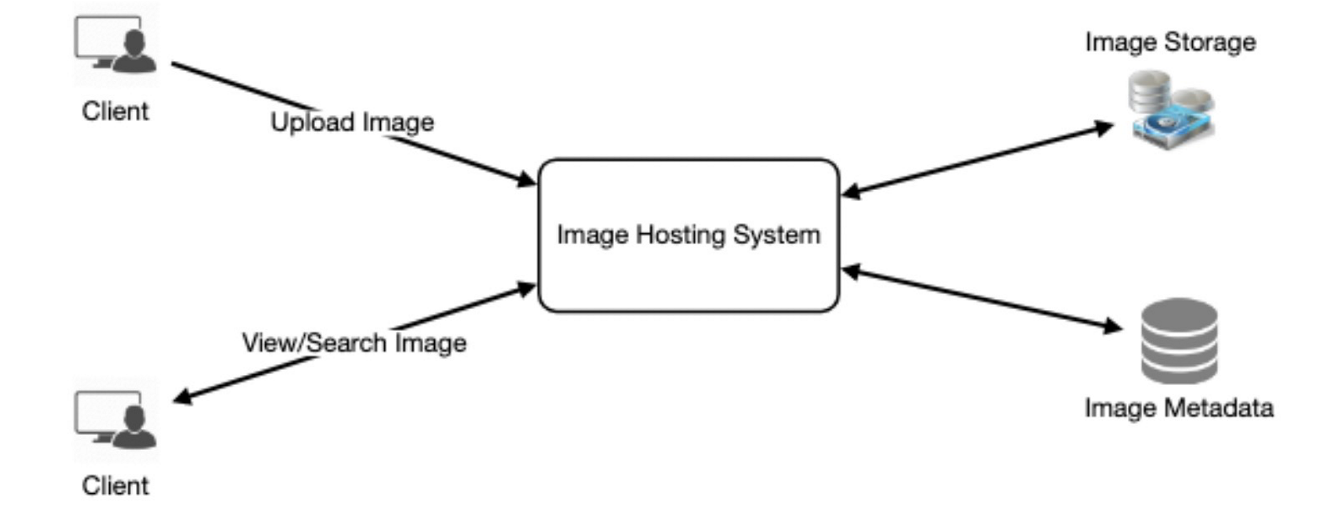
六. 数据库设计
早期阶段定义DB模型将有助于理解不同组件之间的数据流,并在之后进行数据分区
我们需要存储用户、用户上传的照片以及用户关注的人的数据。照片表将存储一张照片相关的所有数据,我们需要在(PhotoID, CreationDate)上有一个索引,因为我们需要获取最近的照片。
| Photo | User | UserFollow |
|---|---|---|
| [PK] Photo ID: int | [PK] UserID: int | [PK] UserID1: int |
| UserID: int | Name: varchar(20) | [PK] UserID2: int |
| PhotoPath: varchar(256) | Email: varchar(20) | |
| PhotoLatitude: int | DateOfBirth: datetime | |
| PhotoLongitude: int | CreationDate: datetime | |
| UserLatitude: int | LastLoginDate: datetime | |
| UserLongitude: int | ||
| CreationDate: datetime |
存储上述表结构的一种简单方法是使用像MySQL这样的RDBMS,因为我们有连表查询的场景。但是关系数据库也存在其他挑战。关于细节请参阅SQL vs NoSQL。
我们可以将照片存储在像HDFS或S3这样的分布式文件存储中,将上述表结构存储在分布式键值存储中,以享受NoSQL提供的好处。所有与照片相关的元数据都可以进入一个表,其中的键是PhotoID,值是一个包含PhotoLocation、UserLocation、CreationTimestamp等的对象。
我们需要存储用户和照片之间的关系,知道谁拥有哪张照片。我们还需要存储用户关注的人的列表。对于这两个表,我们可以使用像Cassandra这样的宽列数据存储。对于UserPhoto表,键是UserID,值是用户拥有的PhotoID列表,存储在不同的列中。对于UserFollow表,我们将有一个类似的方案。
一般来说,Cassandra或键值存储总是维护一定数量的副本,以提供可靠性。此外,在这样的数据存储中,删除操作不会立即生效,数据在从系统中永久删除之前会保留几天(以支持反删除)。
七. 数据估算
让我们估算一下每个表中会有多少数据,以及10年里我们总共需要多少存储空间。
用户表
假设每个int和dateTime都是四个字节,那么用户表中的每一行都是 68 个字节
UserID (4 bytes) + Name (20 bytes) + Email (32 bytes) + DateOfBirth (4 bytes) + CreationDate (4 bytes) + LastLogin (4 bytes) = 68 bytes
如果我们有5亿用户,我们将需要32GB的总存储空间。
500 million * 68 ~= 32GB
照片表
Photo表中的每一行都是284字节
PhotoID (4 bytes) + UserID (4 bytes) + PhotoPath (256 bytes) + PhotoLatitude (4 bytes) + PhotLongitude(4 bytes) + UserLatitude (4 bytes) + UserLongitude (4 bytes) + CreationDate (4 bytes) = 284 bytes
如果每天有2M的新照片上传,我们一天需要0.5GB的存储空间
2M * 284 bytes ~= 0.5GB per day
未来10年,我们需要1.88TB的存储空间。
用户关注表
UserFollow表中的每一行都由8个字节组成。如果我们有5亿用户,平均每个用户关注500个用户。我们需要1.82TB的存储空间来存储UserFollow表。
500 million users * 500 followers * 8 bytes ~= 1.82TB
所有表10年所需的总空间为3.7TB
32GB + 1.88TB + 1.82TB ~= 3.7TB
八. 组件设计
照片上传(写操作)可能会很慢,因为它们必须进入磁盘,而读取将会更快,特别是当它们是从缓存读取来提供服务时。
用户上传操作有可以消耗所有可用的连接,因为上传是一个缓慢的过程。 这意味着如果系统忙于处理所有写入请求,则无法提供读取服务。 在设计我们的系统之前,我们应该记住 Web 服务器有一个连接限制。 如果我们假设一个 Web 服务器同时最多可以有 500 个连接,那么它的并发上传或读取不能超过 500。 为了解决这个瓶颈,我们可以将读取和写入拆分为单独的服务。 我们将用于读取的服务器和用于写入的服务器进行分离,以确保上传不会影响到读取。
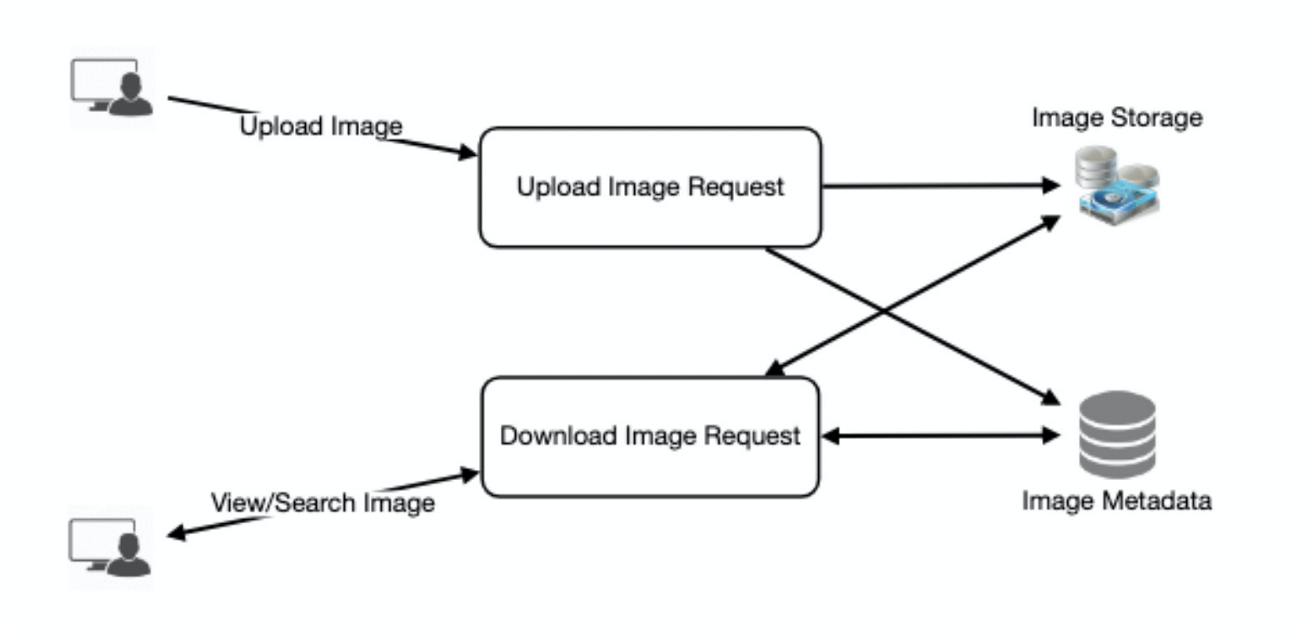
九. 可靠性与冗余性
我们需要保证用户上传的图片不会丢失,并且可查看。因此,我们将为每个文件存储多个副本,这样,如果一个存储服务器挂掉,我们可以从另一个存储服务器上的副本检索照片。
同样的原则也适用于系统的其他组件。如果我们希望系统具有高可用性,我们需要在系统中运行多个服务副本,这样,如果一些服务宕机,系统仍然可用并在运行。冗余消除了系统中的单点故障。
如果在任何时刻只需要一个服务实例运行,我们可以运行不服务任何流量的服务的冗余辅助副本,但当主服务器出现问题时,它可以在故障转移后接管控制权。
在系统中创建冗余可以消除单点故障,并在主节点出现问题时提供备份或备用功能。例如,如果同一服务的两个实例运行在生产环境中,其中一个实例发生故障或降级,则系统可以故障转移到正常的副本。故障转移可以自动发生,也可以人工干预。
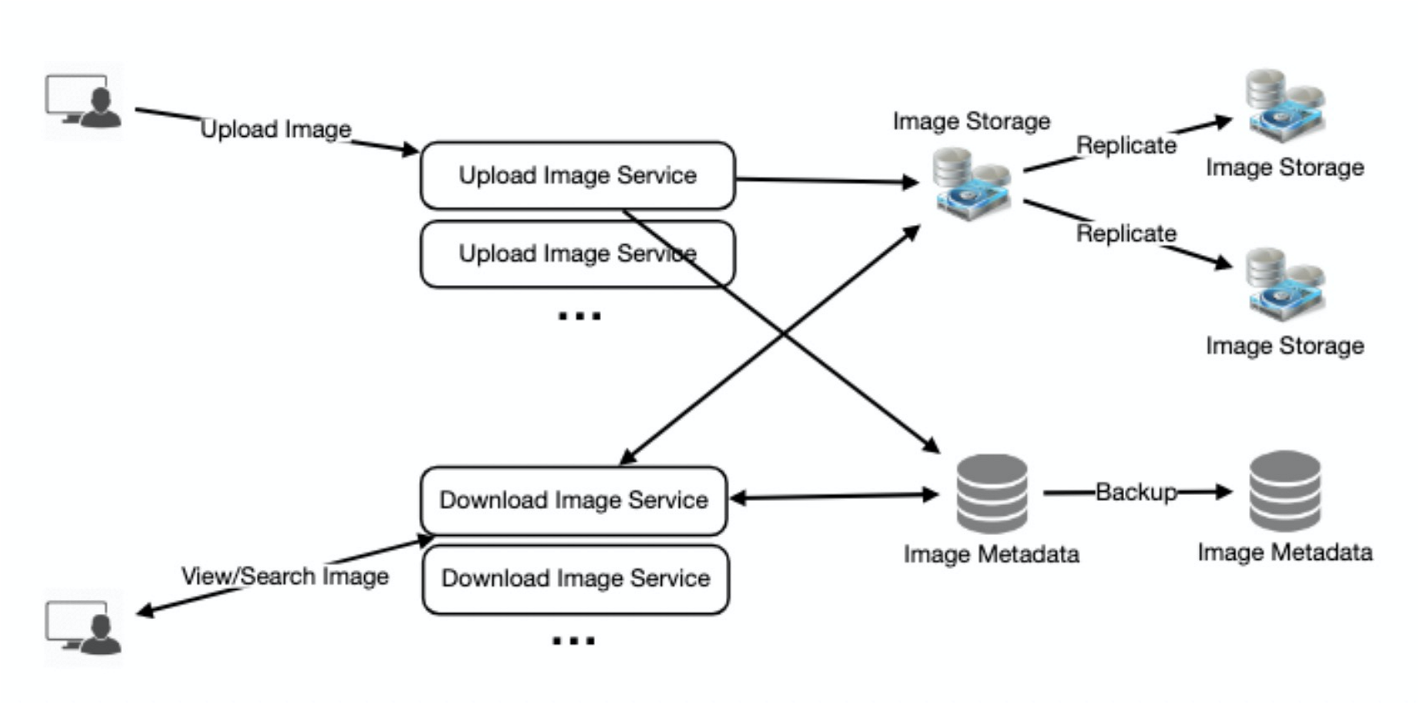
十. 数据分片
让我们讨论元数据分片的不同方案。
方案一. 基于UserID分片
假设我们基于UserID进行分片,这样我们就可以将一个用户的所有照片保存在同一个分片上。如果一个DB Shard是1TB,那么我们需要4个shard来存储3.7TB的数据。让我们假设为了更好的性能和可伸缩性,我们保留10个分片
因此,我们将根据UserID % 10找到分片数,然后将数据存储在那里。为了在我们的系统中唯一地识别任何照片,我们可以在每个PhotoID后面添加分片号。
如何生成PhotoID? 每个DB分片都可以有自己的PhotoID自动递增序列,因为我们将用每个PhotoID添加ShardID,它将使它在整个系统中独一无二。
这个分区方案有什么问题
- 我们将如何处理热门用户? 一些人关注这些热门用户,很多人看到他们上传的任何照片。
- 有些用户会比其他人拥有更多的照片,从而造成存储的不均匀分布。
- 如果我们不能将一个用户的所有图片存储在一个分片上,该怎么办? 如果我们将一个用户的照片分发到多个分片上会导致更高的延迟
- 将一个用户的所有照片存储在一个分片上可能会导致一些问题,比如如果分片宕机,所有用户的数据都不可用,或者如果分片负载高,延迟会更高,等等。
方案二. 基于PhotoID分片
如果我们能先生成唯一的PhotoID,然后通过PhotoID % 10找到一个分片号,那么上述问题就解决了。在这种情况下,我们不需要在ShardID后面加上PhotoID,因为PhotoID本身在整个系统中是唯一的。
我们怎样才能生成PhotoIds?
在这里,我们不能在每个Shard中使用自动递增序列来定义PhotoID,因为我们需要知道PhotoID才能找到存储它的Shard。一种解决方案是我们专门使用一个单独的数据库实例来生成自动递增的 ID(参考美团Leaf实现)。 如果我们的 PhotoID 可以容纳 64 位,我们可以定义一个只包含 64 位 ID 字段的表。 所以每当我们想在我们的系统中添加一张照片时,我们可以在这个表中插入一个新行,并将该 ID 作为我们新照片的 PhotoID。
生成DB的密钥不是单点故障吗?
是的。解决方法是定义两个这样的数据库,一个生成偶数id,另一个生成奇数id。对于MySQL,下面的脚本可以定义这样的序列。
KeyGeneratingServer1:
auto-increment-increment = 2
auto-increment-offset = 1
KeyGeneratingServer2:
auto-increment-increment = 2
auto-increment-offset = 2
我们可以在这两个数据库前面放置一个负载均衡器,以便在它们之间进行轮询并处理。这两个服务器可能不同步,其中一个生成的密钥比另一个多,但这不会在我们的系统中造成任何问题。我们可以通过为Users、Photo-Comments或系统中存在的其他对象定义单独的ID表来扩展这种设计。
另外,我们可以实现一个密钥生成方案,类似于我们在设计一个URL短链服务(如TinyURL)中讨论过的方案KGS。
如何规划我们系统的未来发展?
我们可以有大量的逻辑分区来适应未来的数据增长,这样以来,多个逻辑分区驻留在单个物理数据库服务器上。 由于每个数据库服务器上可以有多个数据库实例,我们可以为任何服务器上的每个逻辑分区拥有单独的数据库。 所以每当我们觉得某个特定的数据库服务器有很多数据时,我们可以将一些逻辑分区从它迁移到另一台服务器。 我们可以维护一个配置文件(或一个单独的数据库),将我们的逻辑分区映射到数据库服务器; 这将使我们能够轻松地移动分区。 每当我们想要移动一个分区时,我们只需要更新配置文件来更改。
十一. 好友动态生成
要为给定用户创建好友动态(类似于朋友圈),我们需要获取该用户关注的人的最新、最受欢迎的照片。
为简单起见,假设我们需要为用户的朋友圈获取前 100 张照片。 我们的应用服务器将首先获取用户关注的人列表,然后从每个用户获取最新 100 张照片的元数据信息。 在最后一步,服务器将所有这些照片提交给我们的排名算法,该算法将确定前 100 张照片(基于时间维度、相似度等)并将它们返回给用户。 这种方法的问题是延迟很高,因为我们必须查询多个表并对结果执行排序/合并/排名。 为了提高效率,我们可以预先生成好友动态数据并将其存储在单独的表中。
预生成好友动态: 我们可以使用专门服务器,不断生成用户好友动态数据并将它们存储在UserNewsFeed表中。因此,当任何用户需要查看他的好友动态照片时,我们只需查询这个表并将结果返回给用户。
每当服务器需要生成用户的NewsFeed时,它们将首先查询UserNewsFeed表,以查找最后一次为该用户生成好友动态的时间。然后,新的好友动态数据将从那时起生成(按照上面提到的步骤)。
向用户发送动态消息内容有哪些不同的方法?
- 拉模式: 客户可以定期或在需要的时候手动从服务器拉出好友动态内容。这种方法可能存在的问题是:
- 直到客户端发出拉取请求时,新数据可能不会显示给用户;
- 如果没有新数据,大多数情况下拉取请求会导致空响应
- 推模式 : 服务器可以在新数据可用时将其推送给用户。为了有效地管理这一点,用户必须在服务器上维护一个Long Poll请求以接收更新。这种方法可能存在的一个问题是,一个关注了很多人的用户,或者一个拥有数百万粉丝的名人用户;在这种情况下,服务器必须非常频繁地推送更新。
- 混合模式 : 我们可以采用混合方法。 我们可以将所有拥有大量关注的用户转移到基于拉取的模型,并且只将数据推送给那些拥有数百(或数千)关注的用户。 另一种方法可能是服务器以不超过一定频率向所有用户推送更新,让有大量关注/更新的用户定期拉取数据.
十二. 使用分片数据创建好友动态
为任何给定用户创建好友动态最重要的要求之一就是从该用户关注的所有人那里获取最新的照片。为此,我们需要一种机制来对照片在创建时进行排序。为了有效地做到这一点,我们可以将照片创建时间作为PhotoID的一部分。因为我们在PhotoID上有一个主索引,所以很快就能找到最新的PhotoID。
我们可以使用时间来记录。假设PhotoID有两部分,第一部分将表示epoch时间,而第二部分将是一个自动递增的序列。因此,要创建一个新的PhotoID时,我们可以取当前的epoch time,并从生成密钥的DB中添加一个自动递增的ID。我们可以从这个PhotoID (PhotoID % 10)中计算出分片数,并将照片存储在那里。
PhotoID的大小是多少? 假设我们的时间从今天开始,我们需要多少位来存储未来 50 年的秒数?
86400 sec/day * 365 (days a year) * 50 (years) => 1.6 billion seconds
我们需要31位来存储这个数字。平均而言,我们预计每秒会有23张新照片,我们可以分配9位来存储自动递增序列。所以每一秒我们都能存储(2^9 => 512)新照片。我们可以每秒重置自动递增序列。
十三. 缓存与负载均衡
我们的服务将需要一个大规模的照片传送系统来服务全球分布的用户。我们的服务应该使用大量地理分布的照片缓存服务器,并使用cdn(详细信息请参见缓存),将内容推向用户。
为元数据服务器引入一个缓存来缓存部分热点数据。我们可以使用Memcache来缓存数据,应用服务器在访问数据库之前可以快速检查缓存中是否有所需的行。对于我们的系统来说,最近最少使用(LRU)是一种合理的缓存回收策略。在这个策略下,我们首先丢弃最近查看次数最少的行。
如何构建更智能的缓存? 如果我们采用80-20法则,即每天20%的照片阅读量产生80%的流量,这些照片非常受欢迎,大多数人都会查看访问它们。这意味着我们可以尝试缓存每日照片和元数据读取量的20%。
系统设计实践(03)- Instagram社交服务的更多相关文章
- iOS开发——高级技术&社交服务
社交服务 Social 现 在很多应用都内置“社交分享”功能,可以将看到的新闻.博客.广告等内容分享到微博.微信.QQ.空间等,其实从iOS6.0开始苹果官方就内置了 Social.framework ...
- OpenStack实践系列⑨云硬盘服务Cinder
OpenStack实践系列⑨云硬盘服务Cinder八.cinder8.1存储的三大分类 块存储:硬盘,磁盘阵列DAS,SAN存储 文件存储:nfs,GluserFS,Ceph(PB级分布式文件系统), ...
- 【实战】Docker入门实践二:Docker服务基本操作 和 测试Hello World
操作环境 操作系统:CentOS7.2 内存:1GB CPU:2核 Docker服务常用命令 docker服务操作命令如下 service docker start #启动服务 service doc ...
- 使用Bootstrap 3开发响应式网站实践03,轮播下方的内容排版
通常把一些重要信息.需要重点标注的信息放在轮播的下方显示,这部分区域用到了大字体的标题.副标题以及段落文字等. <div class="row" id="bigCa ...
- 全链路实践Spring Cloud 微服务架构
Spring Cloud 微服务架构全链路实践Spring Cloud 微服务架构全链路实践 阅读目录: 网关请求流程 Eureka 服务治理 Config 配置中心 Hystrix 监控 服务调用链 ...
- 4、架构--NFS实践、搭建web服务、文件共享
笔记 1.晨考 1.数据备份的方式有哪些 全量和增量 2.数据备份的命令有哪些,都有哪些优点缺点 cp : 本地,全量复制 scp :远程,全量复制 rsync :远程,增量复制 3.rsync的参数 ...
- api-gateway实践(03)新服务网关 - 网关请求拦截检查
参考链接:http://www.cnblogs.com/jivi/archive/2013/03/10/2952829.html 一.为什么要拦截检查请求? 防止重放攻击.篡改重放,进行使用规格检查 ...
- 从实践出发:微服务布道师告诉你Spring Cloud与Spring Boot他如何选择
背景 随着公司业务量的飞速发展,平台面临的挑战已经远远大于业务,需求量不断增加,技术人员数量增加,面临的复杂度也大大增加.在这个背景下,平台的技术架构也完成了从传统的单体应用到微服务化的演进. 系统架 ...
- 从实践出发:微服务布道师告诉你Spring Cloud与Boot他如何选择
背景 随着公司业务量的飞速发展,平台面临的挑战已经远远大于业务,需求量不断增加,技术人员数量增加,面临的复杂度也大大增加.在这个背景下,平台的技术架构也完成了从传统的单体应用到微服务化的演进. 系统架 ...
随机推荐
- Mysql5.6.47开放远程访问(修改远程访问密码)
1.登录mysql mysql -u root -p 然后输入密码,登录进去mysql: 2.切换数据库 use mysql; 3.修改权限 GRANT ALL PRIVILEGES ON *.* T ...
- vs2019编写c++的静态链接库并自己使用
参考网址:https://blog.csdn.net/flame333/article/details/108346305 静态链接库1.新建一个静态库项目,其中有两个头文件,两个源文件 其中比较重要 ...
- uwp 之语音朗读
xml code --------------------------------- <Page x:Class="MyApp.MainPage" xmlns="h ...
- Spring第一课:核心API(三)
以上是Spring的核心部分,其中需要了解的是:BeanFactory.ApplicationContext[FileSystemXmlApplicationContext.ClassPathXmlA ...
- forEachRemaining
ArrayList<Integer> arrayList=new ArrayList<>(); for (int i = 0; i <10; i++) { arrayLi ...
- centos7 shell 计算器 bc 命令
2021-08-03 1. 安装 yum -y install bc 2. 简介 bc 命令是任意精度计算器语言,通常在 linux 下当计算器使用 类似基本的计算器, 使用这个计算器可以做基本的数学 ...
- group by分组查询
有如下数据: 一个简单的分组查询的案例 按照部门编号deptno分组,统计每个部门的平均工资. select deptno,avg(sal) avgs from emp group by deptno ...
- IO流学习笔记(一)之FileWriter与FileReader
IO流用来处理设备之间的数据传输 Java对数据的操作是通过流的方式 Java用于操作流的对象都在IO包中 流按照操作数据分为两种:字节流和字符流 流按流向分为:输入流和输出流 输入流和输出流是相对于 ...
- 云原生学习筑基 ~ 组网必备知识点 ~ DNS服务
@ 目录 一.为啥写这篇文章? 二.DNS的作用 三.域 四.DNS工作原理 五.搭建DNS服务器 5.1.Bind 5.2.系统环境准备 5.3.安装 5.4.查看bind的相关文件 5.5.查看b ...
- 性能测试工具JMeter 基础(二)—— 主界面介绍
主界面介绍 JMeter的主界面主要分为菜单导航栏.工具栏.计划树标签栏.内容栏 菜单导航栏:全部的功能的都包含在菜单栏中 工具栏:相当于菜单栏常用功能的快捷按钮 计划树标签栏:显示测试用例(计划)相 ...