再谈MySql索引
一、索引简介
MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度。
索引分单列索引(主键索引、唯一索引、普通索引)和组合索引。单列索引,即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引。组合索引,即一个索引包含多个列。
创建索引时,你需要确保该索引是应用在 SQL 查询语句的条件(一般作为 WHERE 子句的条件)。
实际上,索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录。
上面都在说使用索引的好处,但过多的使用索引将会造成滥用。因此索引也会有它的缺点:虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。
建立索引会占用磁盘空间的索引文件。
1、什么是索引?为什么要建立索引?
索引用于快速找出在某个列中有一特定值的行,不使用索引,MySQL必须从第一条记录开始读完整个表,直到找出相关的行,表越大,查询数据所花费的时间就越多,如果表中查询的列有一个索引,MySQL能够快速到达一个位置去搜索数据文件,而不必查看所有数据,那么将会节省很大一部分时间。
例如:有一张person表,其中有2W条记录,记录着2W个人的信息。有一个Phone的字段记录每个人的电话号码,现在想要查询出电话号码为xxxx的人的信息。
如果没有索引,那么将从表中第一条记录一条条往下遍历,直到找到该条信息为止。
如果有了索引,那么会将该Phone字段,通过一定的方法进行存储,好让查询该字段上的信息时,能够快速找到对应的数据,而不必在遍历2W条数据了。
2、Mysql索引主要有两种结构:B+Tree索引和Hash索引
Hash索引
MySQL中,只有Memory(Memory表只存在内存中,断电会消失,适用于临时表)存储引擎显示支持Hash索引,是Memory表的默认索引类型,尽管Memory表也可以使用B+Tree索引。hsah索引把数据的索引以hash形式组织起来,因此当查找某一条记录的时候,速度非常快。当时因为是hash结构,每个键只对应一个值,而且是散列的方式分布。所以他并不支持范围查找和排序等功能。
Hash索引有以下一些限制:
(1)由于索引仅包含hash code和记录指针,所以,MySQL不能通过使用索引避免读取记录。但是访问内存中的记录是非常迅速的,不会对性造成太大的影响。
(2)不能使用hash索引排序。
(3)Hash索引不支持键的部分匹配,因为是通过整个索引值来计算hash值的。
(4)Hash索引只支持等值比较,例如使用=,IN( )和<=>。对于WHERE price>100并不能加速查询。
B+树索引
B+tree是mysql使用最频繁的一个索引数据结构,是Inodb和Myisam存储引擎模式的索引类型。相对Hash索引,B+树在查找单条记录的速度比不上Hash索引,但是因为更适合排序等操作,所以他更受用户的欢迎。毕竟不可能只对数据库进行单条记录的操作。
带顺序访问指针的B+Tree
B+Tree所有索引数据都在叶子结点上,并且增加了顺序访问指针,每个叶子节点都有指向相邻叶子节点的指针。
这样做是为了提高区间查询效率,例如查询key为从18到49的所有数据记录,当找到18后,只需顺着节点和指针顺序遍历就可以一次性访问到所有数据节点,极大提到了区间查询效率。
大大减少磁盘I/O读取
数据库系统的设计者巧妙利用了磁盘预读原理,将一个节点的大小设为等于一个页,这样每个节点只需要一次I/O就可以完全载入。
为了达到这个目的,在实际实现B- Tree还需要使用如下技巧:
每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个node只需一次I/O。
B-Tree中一次检索最多需要h-1次I/O(根节点常驻内存),渐进复杂度为O(h)=O(logdN)。一般实际应用中,出度d是非常大的数字,通常超过100,因此h非常小(通常不超过3)。而红黑树这种结构,h明显要深的多。由于逻辑上很近的节点(父子)物理上可能很远,无法利用局部性,所以红黑树的I/O渐进复杂度也为O(h),效率明显比B-Tree差很多。
我们平常所说的索引,如果没有特别指明,一般都是指B树结构组织的索引(B+Tree索引)。索引如图所示
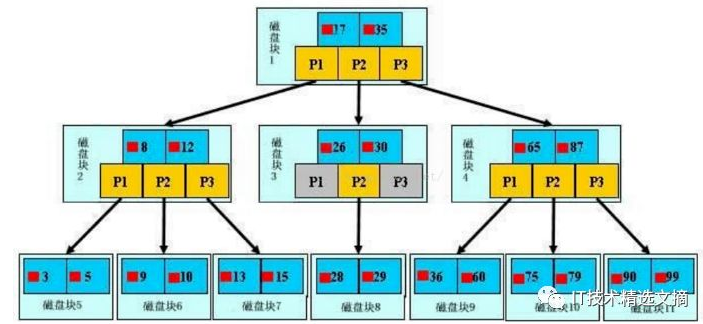
最外层浅蓝色磁盘块1里有数据17、35(深蓝色)和指针P1、P2、P3(黄色)。P1指针表示小于17的磁盘块,P2是在17-35之间,P3指向大于35的磁盘块。真实数据存在于子叶节点也就是最底下的一层3、5、9、10、13......非叶子节点不存储真实的数据,只存储指引搜索方向的数据项,如17、35。
查找过程:例如搜索28数据项,首先加载磁盘块1到内存中,发生一次I/O,用二分查找确定在P2指针。接着发现28在26和30之间,通过P2指针的地址加载磁盘块3到内存,发生第二次I/O。用同样的方式找到磁盘块8,发生第三次I/O。
真实的情况是,上面3层的B+Tree可以表示上百万的数据,上百万的数据只发生了三次I/O而不是上百万次I/O,时间提升是巨大的。
Mysql常见索引有:主键索引、唯一索引、普通索引、全文索引、组合索引
PRIMARY KEY(主键索引) ALTER TABLE `table_name` ADD PRIMARY KEY ( `col` )
UNIQUE(唯一索引) ALTER TABLE `table_name` ADD UNIQUE (`col`)
INDEX(普通索引) ALTER TABLE `table_name` ADD INDEX index_name (`col`)
FULLTEXT(全文索引) ALTER TABLE `table_name` ADD FULLTEXT ( `col` )
组合索引 ALTER TABLE `table_name` ADD INDEX index_name (`col1`, `col2`, `col3` )
Mysql各种索引区别:
普通索引:最基本的索引,没有任何限制
唯一索引:与"普通索引"类似,不同的就是:索引列的值必须唯一,但允许有空值。
主键索引:它 是一种特殊的唯一索引,不允许有空值。
全文索引:仅可用于 MyISAM 表,针对较大的数据,生成全文索引很耗时好空间。
组合索引:为了更多的提高mysql效率可建立组合索引,遵循”最左前缀“原则。创建复合索引时应该将最常用(频率)作限制条件的列放在最左边,依次递减。
组合索引最左字段用in是可以用到索引的,最好explain一下select。
1、普通索引
创建索引
这是最基本的索引,它没有任何限制。它有以下几种创建方式:
CREATE INDEX indexName ON mytable(username(length));
如果是CHAR,VARCHAR类型,length可以小于字段实际长度;如果是BLOB和TEXT类型,必须指定 length。
修改表结构(添加索引)
ALTER table tableName ADD INDEX indexName(columnName)
创建表的时候直接指定
CREATE TABLE mytable( ID INT NOT NULL, username ) NOT NULL, INDEX [indexName] (username(length)) );
删除索引的语法
DROP INDEX [indexName] ON mytable;
2、唯一索引
它与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值(可以重复)。如果是组合索引,则列值的组合必须唯一。它有以下几种创建方式:
创建索引
CREATE UNIQUE INDEX indexName ON mytable(username(length))
修改表结构
ALTER table mytable ADD UNIQUE [indexName] (username(length))
创建表的时候直接指定
CREATE TABLE mytable( ID INT NOT NULL, username ) NOT NULL, UNIQUE [indexName] (username(length)) );
3、主键索引
它是一种特殊的唯一索引,不允许有空值。一般是在建表的时候同时创建主键索引:
) NOT NULL, PRIMARY KEY(ID) );
当然也可以用 ALTER 命令。记住:一个表只能有一个主键。
4、组合索引
为了形象地对比单列索引和组合索引,为表添加多个字段:
CREATE TABLE mytable( ID INT NOT NULL, username ) NOT NULL, city ) NOT NULL, age INT NOT NULL );
为了进一步榨取MySQL的效率,就要考虑建立组合索引。就是将 name, city, age建到一个索引里:
),city,age);
建表时,usernname长度为 16,这里用 10。这是因为一般情况下名字的长度不会超过10,这样会加速索引查询速度,还会减少索引文件的大小,提高INSERT的更新速度。
如果分别在 usernname,city,age上建立单列索引,让该表有3个单列索引,查询时和上述的组合索引效率也会大不一样,远远低于我们的组合索引。虽然此时有了三个索引,但MySQL只能用到其中的那个它认为似乎是最有效率的单列索引。
MySQL组合索引“最左前缀”的结果。简单的理解就是只从最左面的开始组合。并不是只要包含这三列的查询都会用到该组合索引,下面的几个SQL就会用到这个组合索引:
SELECT * FROM mytable WHREE username="admin" AND city="郑州" SELECT * FROM mytable WHREE username="admin"
而下面几个则不会用到:
AND city="郑州" SELECT * FROM mytable WHREE city="郑州"
解释最左前缀
组合索引就是遵从了最左前缀,利用索引中最左边的列集来匹配行,这样的列集称为最左前缀,不明白没关系,举几个例子就明白了,例如,这里由id、name和age3个字段构成的索引,索引行中就按id/name/age的顺序存放,索引可以索引下面字段组合(id,name,age)、(id,name)或者(id)。如果要查询的字段不构成索引最左面的前缀,那么就不会是用索引,比如,age或者(name,age)组合就不会使用索引查询。
5、使用ALTER 命令添加和删除索引
有四种方式来添加数据表的索引:
- ALTER TABLE tbl_name ADD PRIMARY KEY (column_list): 该语句添加一个主键,这意味着索引值必须是唯一的,且不能为NULL。
- ALTER TABLE tbl_name ADD UNIQUE index_name (column_list): 这条语句创建索引的值必须是唯一的(除了NULL外,NULL可能会出现多次)。
- ALTER TABLE tbl_name ADD INDEX index_name (column_list): 添加普通索引,索引值可出现多次。
- ALTER TABLE tbl_name ADD FULLTEXT index_name (column_list):该语句指定了索引为 FULLTEXT ,用于全文索引。
以下实例为在表中添加索引。
mysql> ALTER TABLE testalter_tbl ADD INDEX (c);
你还可以在 ALTER 命令中使用 DROP 子句来删除索引。尝试以下实例删除索引:
mysql> ALTER TABLE testalter_tbl DROP INDEX c;
使用 ALTER 命令添加和删除主键
主键只能作用于一个列上,添加主键索引时,你需要确保该主键默认不为空(NOT NULL)。实例如下:
mysql> ALTER TABLE testalter_tbl MODIFY i INT NOT NULL; mysql> ALTER TABLE testalter_tbl ADD PRIMARY KEY (i);
你也可以使用 ALTER 命令删除主键:
mysql> ALTER TABLE testalter_tbl DROP PRIMARY KEY;
删除主键时只需指定PRIMARY KEY,但在删除索引时,你必须知道索引名。
6、建立与使用索引的时机
到这里我们已经学会了建立索引,那么我们需要在什么情况下建立索引呢?一般来说,在WHERE和JOIN中出现的列需要建立索引,但也不完全如此,因为MySQL只对<,<=,=,>,>=,BETWEEN,IN,以及某些时候的LIKE才会使用索引。例如:
AND m.city='郑州'
此时就需要对city和age建立索引,由于mytable表的userame也出现在了JOIN子句中,也有对它建立索引的必要。
刚才提到只有某些时候的LIKE才需建立索引。因为在以通配符%和_开头作查询时,MySQL不会使用索引。例如下句会使用索引:
SELECT * FROM mytable WHERE username like'admin%'
而下句就不会使用:
SELECT * FROM mytable WHEREt Name like'%admin'
因此,在使用LIKE时应注意以上的区别。

7、显示索引信息
你可以使用 SHOW INDEX 命令来列出表中的相关的索引信息。可以通过添加 \G 来格式化输出信息。
尝试以下实例:
mysql> SHOW INDEX FROM table_name; \G ........
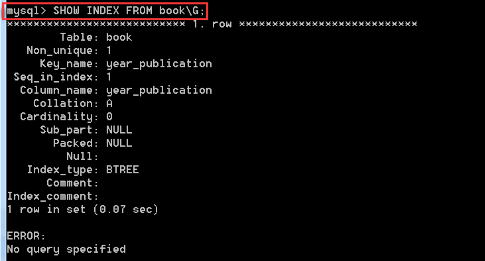
挑重点讲,我们需要了解的就5个,用红颜色标记了的,如果想深入了解,可以去查查该方面的资料,我个人觉得,这些等以后实际工作中遇到了在做详细的了解把。
Table:创建索引的表
Non_unique:表示索引非唯一,1代表 非唯一索引, 0代表 唯一索引,意思就是该索引是不是唯一索引
Key_name:索引名称
Seq_in_index 表示该字段在索引中的位置,单列索引的话该值为1,组合索引为每个字段在索引定义中的顺序(这个只需要知道单列索引该值就为1,组合索引为别的)
Column_name:表示定义索引的列字段
Sub_part:表示索引的长度
Null:表示该字段是否能为空值
Index_type:表示索引类型
二、索引优化
1、导致SQL执行慢的原因:
1.硬件问题。如网络速度慢,内存不足,I/O吞吐量小,磁盘空间满了等。
2.没有索引或者索引失效。(一般在互联网公司,DBA会在半夜把表锁了,重新建立一遍索引,因为当你删除某个数据的时候,索引的树结构就不完整了。所以互联网公司的数据做的是假删除.一是为了做数据分析,二是为了不破坏索引 )
3.数据过多(分库分表)
4.服务器调优及各个参数设置(调整my.cnf)
2、分析原因时,一定要找切入点:
1.先观察,开启慢查询日志,设置相应的阈值(比如超过3秒就是慢SQL),在生产环境跑上个一天过后,看看哪些SQL比较慢。
2.Explain和慢SQL分析。比如SQL语句写的烂,索引没有或失效,关联查询太多(有时候是设计缺陷或者不得以的需求)等等。
3.Show Profile是比Explain更近一步的执行细节,可以查询到执行每一个SQL都干了什么事,这些事分别花了多少秒。
4.找DBA或者运维对MySQL进行服务器的参数调优。
3、选择索引的数据类型
MySQL支持很多数据类型,选择合适的数据类型存储数据对性能有很大的影响。通常来说,可以遵循以下一些指导原则:
(1)越小的数据类型通常更好:越小的数据类型通常在磁盘、内存和CPU缓存中都需要更少的空间,处理起来更快。
(2)简单的数据类型更好:整型数据比起字符,处理开销更小,因为字符串的比较更复杂。在MySQL中,应该用内置的日期和时间数据类型,而不是用字符串来存储时间;以及用整型数据类型存储IP地址。
(3)尽量避免NULL:应该指定列为NOT NULL,除非你想存储NULL。在MySQL中,含有空值的列很难进行查询优化,因为它们使得索引、索引的统计信息以及比较运算更加复杂。你应该用0、一个特殊的值或者一个空串代替空值。
选择标识符
选择合适的标识符是非常重要的。选择时不仅应该考虑存储类型,而且应该考虑MySQL是怎样进行运算和比较的。一旦选定数据类型,应该保证所有相关的表都使用相同的数据类型。
(1) 整型:通常是作为标识符的最好选择,因为可以更快的处理,而且可以设置为AUTO_INCREMENT。
(2) 字符串:尽量避免使用字符串作为标识符,它们消耗更好的空间,处理起来也较慢。而且,通常来说,字符串都是随机的,所以它们在索引中的位置也是随机的,这会导致页面分裂、随机访问磁盘,聚簇索引分裂(对于使用聚簇索引的存储引擎)。
4、Explain分析
先来插入测试需要的数据:
) ) ) DEFAULT NULL, PRIMARY KEY (`id`), KEY `name_index` (`name`) )ENGINE ););););););););););) ) ) ) DEFAULT NULL, PRIMARY KEY (`id`), KEY `user_product_detail_index` (`user_id`, `product_name`, `productor`) )ENGINE , , , , , , , , , 'p8', 'TE');
初体验,执行Explain的效果:

索引使用情况在possible_keys、key和key_len三列,接下来我们先从左到右依次讲解。
1.id
--id相同,执行顺序由上而下explain select u.*,o.* from user_info u,order_info o where u.id=o.user_id;

--id不同,值越大越先被执行explain select * from user_info where id=(select user_id from order_info where product_name ='p8');

2.select_type
可以看id的执行实例,总共有以下几种类型:
SIMPLE: 表示此查询不包含 UNION 查询或子查询
PRIMARY: 表示此查询是最外层的查询
SUBQUERY: 子查询中的第一个 SELECT
UNION: 表示此查询是 UNION 的第二或随后的查询
DEPENDENT UNION: UNION 中的第二个或后面的查询语句, 取决于外面的查询
UNION RESULT, UNION 的结果
DEPENDENT SUBQUERY: 子查询中的第一个 SELECT, 取决于外面的查询. 即子查询依赖于外层查询的结果.
DERIVED:衍生,表示导出表的SELECT(FROM子句的子查询)
3.table
table表示查询涉及的表或衍生的表:

id为1的<derived2>的表示id为2的u和o表衍生出来的。
4.type
type 字段比较重要,它提供了判断查询是否高效的重要依据依据。 通过 type 字段,我们判断此次查询是 全表扫描 还是 索引扫描等。

type 常用的取值有:
system: 表中只有一条数据, 这个类型是特殊的 const 类型。
const: 针对主键或唯一索引的等值查询扫描,最多只返回一行数据。 const 查询速度非常快, 因为它仅仅读取一次即可。例如下面的这个查询,它使用了主键索引,因此 type 就是 const 类型的:explain select * from user_info where id = 2;
eq_ref: 此类型通常出现在多表的 join 查询,表示对于前表的每一个结果,都只能匹配到后表的一行结果。并且查询的比较操作通常是 =,查询效率较高。例如:explain select * from user_info, order_info where user_info.id = order_info.user_id;
ref: 此类型通常出现在多表的 join 查询,针对于非唯一或非主键索引,或者是使用了 最左前缀 规则索引的查询。例如下面这个例子中, 就使用到了 ref 类型的查询:explain select * from user_info, order_info where user_info.id = order_info.user_id AND order_info.user_id = 5
range: 表示使用索引范围查询,通过索引字段范围获取表中部分数据记录。这个类型通常出现在 =, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, IN() 操作中。例如下面的例子就是一个范围查询:explain select * from user_info where id between 2 and 8;
index: 表示全索引扫描(full index scan),和 ALL 类型类似,只不过 ALL 类型是全表扫描,而 index 类型则仅仅扫描所有的索引, 而不扫描数据。index 类型通常出现在:所要查询的数据直接在索引树中就可以获取到, 而不需要扫描数据。当是这种情况时,Extra 字段 会显示 Using index。
ALL: 表示全表扫描,这个类型的查询是性能最差的查询之一。通常来说, 我们的查询不应该出现 ALL 类型的查询,因为这样的查询在数据量大的情况下,对数据库的性能是巨大的灾难。 如一个查询是 ALL 类型查询, 那么一般来说可以对相应的字段添加索引来避免。
通常来说, 不同的 type 类型的性能关系如下:
ALL < index < range ~ index_merge < ref < eq_ref < const < system
ALL 类型因为是全表扫描, 因此在相同的查询条件下,它是速度最慢的。而 index 类型的查询虽然不是全表扫描,但是它扫描了所有的索引,因此比 ALL 类型的稍快.后面的几种类型都是利用了索引来查询数据,因此可以过滤部分或大部分数据,因此查询效率就比较高了。
5.possible_keys
它表示 mysql 在查询时,可能使用到的索引。 注意,即使有些索引在 possible_keys 中出现,但是并不表示此索引会真正地被 mysql 使用到。 mysql 在查询时具体使用了哪些索引,由 key 字段决定。
6.key
此字段是 mysql 在当前查询时所真正使用到的索引。比如请客吃饭,possible_keys是应到多少人,key是实到多少人。
当我们没有建立索引时:
explain select o.* from order_info o where o.product_name= 'p1' and o.productor='whh';create index idx_name_productor on order_info(productor);drop index idx_name_productor on order_info;

建立复合索引后再查询:

7.key_len
表示查询优化器使用了索引的字节数,这个字段可以评估组合索引是否完全被使用。
8.ref
这个表示显示索引的哪一列被使用了,如果可能的话,是一个常量。前文的type属性里也有ref,注意区别。

9.rows
rows 也是一个重要的字段,mysql 查询优化器根据统计信息,估算 sql 要查找到结果集需要扫描读取的数据行数,这个值非常直观的显示 sql 效率好坏, 原则上 rows 越少越好。可以对比key中的例子,一个没建立索引钱,rows是9,建立索引后,rows是4。
10.extra

explain 中的很多额外的信息会在 extra 字段显示, 常见的有以下几种内容:
using filesort :表示 mysql 需额外的排序操作,不能通过索引顺序达到排序效果。一般有 using filesort都建议优化去掉,因为这样的查询 cpu 资源消耗大。
using index:覆盖索引扫描,表示查询在索引树中就可查找所需数据,不用扫描表数据文件,往往说明性能不错。
using temporary:查询有使用临时表, 一般出现于排序, 分组和多表 join 的情况, 查询效率不高,建议优化。
using where :表名使用了where过滤。
三、高性能的索引策略
1、聚簇索引(Clustered Indexes)
聚簇索引保证关键字的值相近的元组存储的物理位置也相同(所以字符串类型不宜建立聚簇索引,特别是随机字符串,会使得系统进行大量的移动操作),且一个表只能有一个聚簇索引。因为由存储引擎实现索引,所以,并不是所有的引擎都支持聚簇索引。目前,只有solidDB和InnoDB支持。
聚簇索引的结构大致如下:
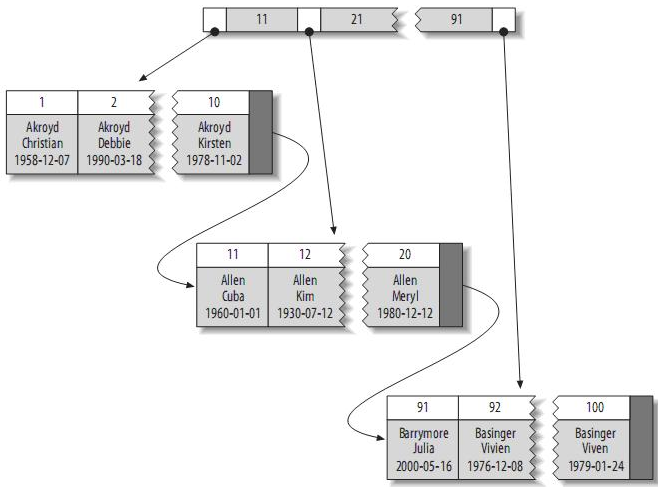
注:叶子页面包含完整的元组,而内节点页面仅包含索引的列(索引的列为整型)。一些DBMS允许用户指定聚簇索引,但是MySQL的存储引擎到目前为止都不支持。InnoDB对主键建立聚簇索引。如果你不指定主键,InnoDB会用一个具有唯一且非空值的索引来代替。如果不存在这样的索引,InnoDB会定义一个隐藏的主键,然后对其建立聚簇索引。一般来说,DBMS都会以聚簇索引的形式来存储实际的数据,它是其它二级索引的基础。
2、InnoDB和MyISAM的数据布局的比较
为了更加理解聚簇索引和非聚簇索引,或者primary索引和second索引(MyISAM不支持聚簇索引),来比较一下InnoDB和MyISAM的数据布局,对于如下表:
CREATE TABLE layout_test ( col1 int NOT NULL, col2 int NOT NULL, PRIMARY KEY(col1), KEY(col2) );
假设主键的值位于1---10,000之间,且按随机顺序插入,然后用OPTIMIZE TABLE进行优化。col2随机赋予1---100之间的值,所以会存在许多重复的值。
(1) MyISAM的数据布局
其布局十分简单,MyISAM按照插入的顺序在磁盘上存储数据,如下:
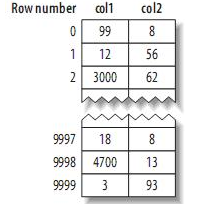
注:左边为行号(row number),从0开始。因为元组的大小固定,所以MyISAM可以很容易的从表的开始位置找到某一字节的位置。
据些建立的primary key的索引结构大致如下:
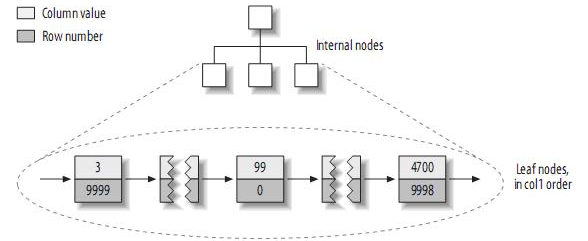
注:MyISAM不支持聚簇索引,索引中每一个叶子节点仅仅包含行号(row number),且叶子节点按照col1的顺序存储。
来看看col2的索引结构:
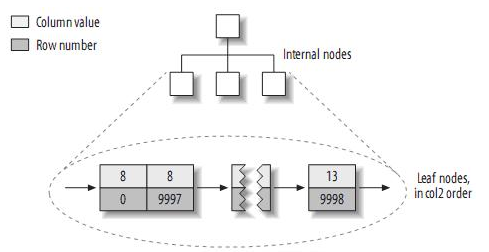
实际上,在MyISAM中,primary key和其它索引没有什么区别。Primary key仅仅只是一个叫做PRIMARY的唯一,非空的索引而已。
(2) InnoDB的数据布局
InnoDB按聚簇索引的形式存储数据,所以它的数据布局有着很大的不同。它存储表的结构大致如下:
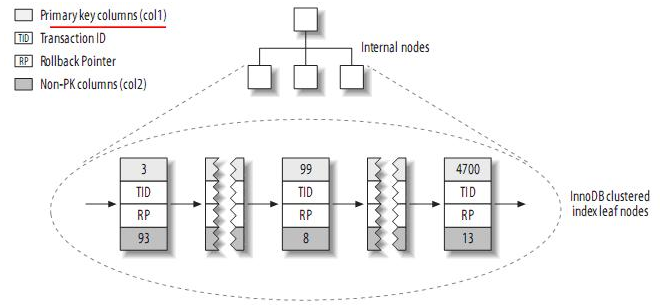
注:聚簇索引中的每个叶子节点包含primary key的值,事务ID和回滚指针(rollback pointer)——用于事务和MVCC,和余下的列(如col2)。
相对于MyISAM,二级索引与聚簇索引有很大的不同。InnoDB的二级索引的叶子包含primary key的值,而不是行指针(row pointers),这减小了移动数据或者数据页面分裂时维护二级索引的开销,因为InnoDB不需要更新索引的行指针。
按primary key的顺序插入行(InnoDB)
如果你用InnoDB,而且不需要特殊的聚簇索引,一个好的做法就是使用代理主键(surrogate key)——独立于你的应用中的数据。最简单的做法就是使用一个AUTO_INCREMENT的列,这会保证记录按照顺序插入,而且能提高使用primary key进行连接的查询的性能。应该尽量避免随机的聚簇主键,例如,字符串主键就是一个不好的选择,它使得插入操作变得随机。
3、覆盖索引(Covering Indexes)
如果索引包含满足查询的所有数据,就称为覆盖索引。覆盖索引是一种非常强大的工具,能大大提高查询性能。只需要读取索引而不用读取数据有以下一些优点:
(1)索引项通常比记录要小,所以MySQL访问更少的数据;
(2)索引都按值的大小顺序存储,相对于随机访问记录,需要更少的I/O;
(3)大多数据引擎能更好的缓存索引。比如MyISAM只缓存索引。
(4)覆盖索引对于InnoDB表尤其有用,因为InnoDB使用聚集索引组织数据,如果二级索引中包含查询所需的数据,就不再需要在聚集索引中查找了。
覆盖索引不能是任何索引,只有B-TREE索引存储相应的值。而且不同的存储引擎实现覆盖索引的方式都不同,并不是所有存储引擎都支持覆盖索引(Memory和Falcon就不支持)。
对于索引覆盖查询(index-covered query),使用EXPLAIN时,可以在Extra一列中看到“Using index”。例如,在sakila的inventory表中,有一个组合索引(store_id,film_id),对于只需要访问这两列的查询,MySQL就可以使用索引,如下:
mysql> EXPLAIN SELECT store_id, film_id FROM sakila.inventory\G
. row ***************************
id:
select_type: SIMPLE
table: inventory
type: index
possible_keys: NULL
key: idx_store_id_film_id
key_len:
ref: NULL
rows:
Extra: Using index
row in set (0.17 sec)
在大多数引擎中,只有当查询语句所访问的列是索引的一部分时,索引才会覆盖。但是,InnoDB不限于此,InnoDB的二级索引在叶子节点中存储了primary key的值。因此,sakila.actor表使用InnoDB,而且对于是last_name上有索引,所以,索引能覆盖那些访问actor_id的查询,如:
mysql> EXPLAIN SELECT actor_id, last_name
-> FROM sakila.actor WHERE last_name = 'HOPPER'\G
. row ***************************
id:
select_type: SIMPLE
table: actor
type: ref
possible_keys: idx_actor_last_name
key: idx_actor_last_name
key_len:
ref: const
rows:
Extra: Using where; Using index
4、利用索引进行排序
MySQL中,有两种方式生成有序结果集:一是使用filesort,二是按索引顺序扫描。利用索引进行排序操作是非常快的,而且可以利用同一索引同时进行查找和排序操作。当索引的顺序与ORDER BY中的列顺序相同且所有的列是同一方向(全部升序或者全部降序)时,可以使用索引来排序。如果查询是连接多个表,仅当ORDER BY中的所有列都是第一个表的列时才会使用索引。其它情况都会使用filesort。
四、索引的缺点
上面都在说使用索引的好处,但过多的使用索引将会造成滥用。因此索引也会有它的缺点:
1.虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。
2.建立索引会占用磁盘空间的索引文件。一般情况这个问题不太严重,但如果你在一个大表上创建了多种组合索引,索引文件的会膨胀很快。
索引只是提高效率的一个因素,如果你的MySQL有大数据量的表,就需要花时间研究建立最优秀的索引,或优化查询语句。
五、使用索引的注意事项
使用索引时,有以下一些技巧和注意事项:
1.索引不会包含有NULL值的列
只要列中包含有NULL值都将不会被包含在索引中,复合索引中只要有一列含有NULL值,那么这一列对于此复合索引就是无效的。所以我们在数据库设计时不要让字段的默认值为NULL。
2.使用短索引
对串列进行索引,如果可能应该指定一个前缀长度。例如,如果有一个CHAR(255)的列,如果在前10个或20个字符内,多数值是惟一的,那么就不要对整个列进行索引。短索引不仅可以提高查询速度而且可以节省磁盘空间和I/O操作。
3.索引列排序
MySQL查询只使用一个索引,因此如果where子句中已经使用了索引的话,那么order by中的列是不会使用索引的。因此数据库默认排序可以符合要求的情况下不要使用排序操作;尽量不要包含多个列的排序,如果需要最好给这些列创建复合索引。
4.like语句操作
一般情况下不鼓励使用like操作,如果非使用不可,如何使用也是一个问题。like “%aaa%” 不会使用索引而like “aaa%”可以使用索引。
5.不要在列上进行运算
;
将在每个行上进行运算,这将导致索引失效而进行全表扫描,因此我们可以改成:
';
6.不使用NOT IN和<>操作。
参考文章:
https://www.cnblogs.com/wasayezi/p/7412153.html
https://www.cnblogs.com/shijianchuzhenzhi/p/6383117.html
https://blog.csdn.net/GV7lZB0y87u7C/article/details/79969293
https://www.cnblogs.com/doudouxiaoye/p/5831449.html
再谈MySql索引的更多相关文章
- 再谈mysql锁机制及原理—锁的诠释
加锁是实现数据库并发控制的一个非常重要的技术.当事务在对某个数据对象进行操作前,先向系统发出请求,对其加锁.加锁后事务就对该数据对象有了一定的控制,在该事务释放锁之前,其他的事务不能对此数据对象进行更 ...
- 浅谈MySQL索引背后的数据结构及算法
摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BT ...
- 浅谈MySQL索引背后的数据结构及算法(转载)
转自:http://blogread.cn/it/article/4088?f=wb1 摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储 ...
- 浅谈MySQL索引背后的数据结构及算法【转】
摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BT ...
- 浅谈Mysql索引
文章原创于公众号:程序猿周先森.本平台不定时更新,喜欢我的文章,欢迎关注我的微信公众号. 我们都知道,数据库索引可以帮助我们更加快速的找出符合的数据,但是如果不使用索引,Mysql则会从第一条开始查询 ...
- InnoDB还是MyISAM 再谈MySQL存储引擎的选择
两种类型最主要的差别就是Innodb 支持事务处理与外键和行级锁.而MyISAM不支持.所以MyISAM往往就容易被人认为只适合在小项目中使用. 我作为使用MySQL的用户角度出发,Innodb和My ...
- 谈Mysql索引
myisam和innodb的索引有什么区别? 两个索引都是B+树索引,但是myisam的表存储和索引存储是分开的,索引存储中存放的是表的地址.而innodb表存储本身就是一个B+树,它是用主键来做B+ ...
- 再谈PG索引-存储架构
1.索引的基本架构 PG的索引是B+树,B+树是为磁盘或其他直接存取辅助设备而设计的一种平衡查找树,在B+树中,所有记录节点都是按键值的大小顺序存放在同一层的叶节点中,各叶节点指针进行连接: meta ...
- 再谈 Mysql解决中文乱码
一是要把数据库服务器的字符集设置为 utf8. 数据库的字符集会跟服务器的字符集一起变化, 也会变成 utf8: 在/etc/my.cnf中, 的 [mysqld]中, 设置 character-se ...
随机推荐
- ORM框架学习之EF
首先推荐一篇很好的EF文章翻译,可以系统的学习一遍. <Entity Framework 6 Recipes>中文翻译系列 EF使用体会 优点: 可以省去Ado.net复杂的管道连接代码. ...
- Java中的Union Types和Intersection Types
前言 Union Type和Intersection Type都是将多个类型结合起来的一个等价的"类型",它们并非是实际存在的类型. Union Type Union type(联 ...
- WebGL实现sprite精灵效果的GUI控件
threejs已经有了sprite插件,这就方便了three的用户,直接可以使用threejs的sprite插件来制作GUI模型.sprite插件是阿里的lasoy老师改造过的,这个很厉害,要学习一哈 ...
- halcon算子之tuple_gen_const,用于生成特定长度的元组并且初始化其元素
原文地址:http://blog.sina.com.cn/s/blog_d38f8be50102wczk.html 函数原型: tuple_gen_const(: : Length, Const : ...
- shell中与运算 cut切分行 if while综合在一起的一个例子
前言: 公司要统计 treasury库hive表磁盘空间,写了个脚本,如下: 查询hive仓库表占用hdfs文件大小: hadoop fs -du -h /user/hive/warehouse/t ...
- Spring中的数据库事物管理
Spring中的数据库事物管理 只要给方法加一个@Transactional注解就可以了 例如:
- MD5加密简单使用
MD5加密简单使用规则 先写一个加密的工具类吧! public class MD5Util { public static String encoderPassword(String s) throw ...
- CHAPTER 40 Science in Our Digital Age 第40章 我们数字时代的科学
CHAPTER 40 Science in Our Digital Age 第40章 我们数字时代的科学 The next time you switch on your computer, you ...
- Spring入门学习笔记(1)
目录 Spring好处 依赖注入 面向面编程(AOP) Spring Framework Core Container Web Miscellaneous 编写第一个程序 IoC容器 Spring B ...
- 一种利用ADO连接池操作MySQL的解决方案(VC++)
VC++连接MySQL数据库 常用的方式有三种:ADO.mysql++,mysql API ; 本文只讲述ADO的连接方式. 为什么要使用连接池? 对于简单的数据库应用,完全可以先创建一个常连接(此连 ...