如何使用正则做文本数据的清洗(附免费AI视频福利)
手工打造文本数据清洗工具
作者 白宁超
2019年4月30日09:43:59
前言:数据清理指删除、更正错误、不完整、格式有误或多余的数据。数据清理不仅仅更正错误,同样加强来自各个单独信息系统不同数据间的一致性。本章首先介绍了新闻语料的基本情况及语料构建的相关原则;然后,回顾对比递归遍历与生成器遍历,打造一款高效的文件读取工具;最后,结合正则数据清洗方法完成新闻语料的批量处理。(本文原创,转载标明出处。限时福利:《福利:33套AI技术视频免费领取》)
1 新闻语料的准备
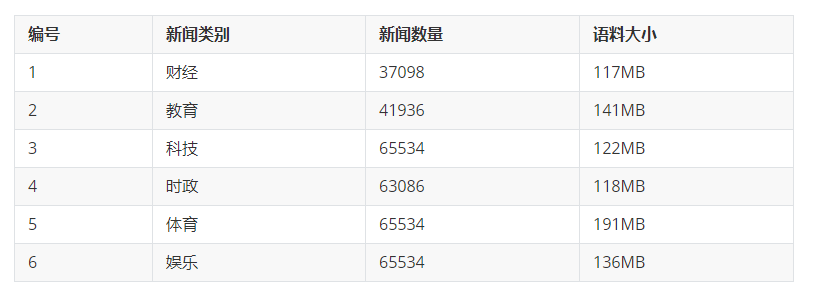
语料可以理解为语言材料,包括口语材料和书面材料。语料的定义较为广泛,其来源可能是教材、报纸、综合刊物、新闻材料、图书等,语料所涉及的学科门类也较为复杂。 本章所介绍的新闻语料,狭义上来讲,就是为实验或工程应用所准备的相对规范的数据集。其目的是通过有监督学习方法,训练算法模型以达到工程应用。本书新闻语料来源于复旦大学新闻语料摘选,原始语料达到近千万条,为了更加适应教学,作者选择平衡语料30余万条,具体语料信息如下:
为什么我们不是自己构建语料,而采用开源数据集?前面我们介绍的数据采集和爬虫技术,可以完成对某特定领域数据的爬取和整理。然后结合第四章数据预处理技术,最终整理成相对规范的文本信息,理论上讲完全是可行的。但是,实际情况而言,语料库构建需要遵循以下几个原则:
- 代表性:在应用领域中,不是根据量而划分是否是语料库,而是在一定的抽样框架范围内采集而来的,并且在特定的抽样框架内做到代表性和普遍性。
- 结构性:有目的的收集语料的集合,必须以电子形式存在,计算机可读的语料集合结构性体现在语料库中语料记录的代码,元数据项、数据类型、数据宽度、取值范围、完整性约束。
- 平衡性:主要体现在平缓因子:学科、年代、文体、地域、登载语料的媒体、使用者的年龄、性别、文化背景、阅历、预料用途(私信/广告等),根据实际情况选择其中一个或者几个重要的指标作为平衡因子,最常见的平衡因子有学科、年代、文体、地域等。
- 规模性:大规模的语料对语言研究特别是对自然语言研究处理很有用的,但是随着语料库的增大,垃圾语料越来越多,语料达到一定规模以后,语料库功能不能随之增长,语料库规模应根据实际情况而定。
- 元数据:元数据对于研究语料库有着重要的意义,我们可以通过元数据了解语料的时间、地域、作者、文本信息等;还可以构建不同的子语料库;除此外,还可以对不同的子语料对比;另外还可以记录语料知识版权、加工信息、管理信息等。
2 高效读取文件
2.1 递归遍历读取新闻
递归在计算机科学中是指一种通过重复将问题分解为同类的子问题而解决问题的方法。递归式方法可以被用于解决很多的计算机科学问题,因此它是计算机科学中十分重要的一个概念。绝大多数编程语言支持函数的自调用,在这些语言中函数可以通过调用自身来进行递归。计算理论可以证明递归的作用可以完全取代循环,因此有很多在函数编程语言中用递归来取代循环的例子。计算机科学家尼克劳斯·维尔特如此描述递归:递归的强大之处在于它允许用户用有限的语句描述无限的对象。因此,在计算机科学中,递归可以被用来描述无限步的运算,尽管描述运算的程序是有限的。
事实上,递归算法核心思想就是分而治之。在一些适用情形下可以让人惊讶不已,但也不是任何场合都能发挥的作用的,诸如遍历读取大量文件的时候。往往科学的实验揭露事实的真相,我们开启这样一个实验即递归算法遍历读取CSCMNews文件夹下的30余万新闻语料,每读取5000条信息再屏幕上打印一条读取完成的信息。代码实现如下:
# 遍历CSCMNews目录文件
def TraversalDir(rootDir):
# 返回指定目录包含的文件或文件夹的名字的列表
for i,lists in enumerate(os.listdir(rootDir)):
# 待处理文件夹名字集合
path = os.path.join(rootDir, lists)
# 核心算法,对文件具体操作
if os.path.isfile(path):
if i%5000 == 0:
print('{t} *** {i} \t docs has been read'.format(i=i, t=time.strftime('%Y-%m-%d %H:%M:%S',time.localtime())))
# 递归遍历文件目录
if os.path.isdir(path):
TraversalDir(path)
我们运行main主函数:
if __name__ == '__main__':
t1=time.time()
# 根目录文件路径
rootDir = r"../Corpus/CSCMNews"
TraversalDir(rootDir)
t2=time.time()
print('totally cost %.2f' % (t2-t1)+' s')
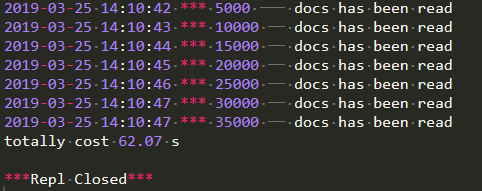
经过实验证明,完成约30万新闻文本读取花费65.28秒(这里还没有对文件执行任何操作),随着语料数量增加,执行速度也将会越来越慢。递归遍历读取新闻语料结果如图所示:
2.2 高效遍历读取新闻
前面介绍的yield生成器大大提升了执行效率,对于读取文件操作,我们只需要构建一个类文件就可以,其中loadFiles类负责加载目录文件,而loadFolders类负责加载文件夹下的子文件,实现如下:
# 加载目录文件
class loadFiles(object):
def __init__(self, par_path):
self.par_path = par_path
def __iter__(self):
folders = loadFolders(self.par_path)
# level directory
for folder in folders:
catg = folder.split(os.sep)[-1]
#secondary directory
for file in os.listdir(folder):
yield catg, file
# 加载目录下的子文件
class loadFolders(object): # 迭代器
def __init__(self, par_path):
self.par_path = par_path
def __iter__(self):
for file in os.listdir(self.par_path):
file_abspath = os.path.join(self.par_path, file)
# if file is a folder
if os.path.isdir(file_abspath):
yield file_abspath
上述代码最大的变化就是return关键字改为yield,如此便成了生成器函数了,我们通过yield生成器函数遍历30余万新闻文件,每完成5000个文件读取变打印一条信息,调用main函数如下:
if __name__=='__main__':
start = time.time()
filepath = os.path.abspath(r'../Corpus/CSCMNews')
files = loadFiles(filepath)
for i, msg in enumerate(files):
if i%5000 == 0:
print('{t} *** {i} \t docs has been Read'.format(i=i,t=time.strftime('%Y-%m-%d %H:%M:%S',time.localtime())))
end = time.time()
print('total spent times:%.2f' % (end-start)+ ' s')
执行以上函数,运行结果如下图所示:
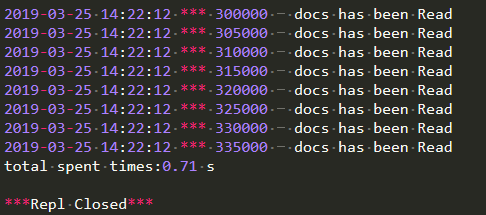
递归遍历读取30万新闻数据耗时65.28秒,而yield生成器仅仅耗时0.71秒。前者是后者的87倍多,随着对文件操作和数据量的增加,这种区别可以达到指数级。本节封装的yield生成器类文件,读者可以保留下来,复用到其他文件操作之中。
3 正则表达式提取文本信息
正则表达式(代码中常简写regex、regexp或RE),是计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换那些匹配某个模式的文本。许多程序设计语言都支持利用正则表达式进行字符串操作。正则表达式是一种用来匹配字符串的强有力的武器。它的设计思想是用一种描述性的语言来给字符串定义一个规则,凡是符合规则的字符串,我们就认为它“匹配”了,否则,该字符串就是不合法的。regular.py包含以下正则案例实现。

- 提取0结束的字符串
line = 'this is a dome about this scrapy2.0'
regex_str='^t.*0$'
match_obj = re.match(regex_str,line)
if match_obj:
print(match_obj.group(1))
- 提取指定字符t与t之间的子串
line = 'this is a dome about this scrapy2.0'
regex_str=".*?(t.*?t).*" # 提取tt之间的子串
match_obj = re.match(regex_str,line)
if match_obj:
print(match_obj.group(0))
- 提取课程前面内容
line = '这是Scrapy学习课程,这次课程很好'
regex_str=".*?([\u4E00-\u9FA5]+课程)"
match_obj = re.match(regex_str,line)
if match_obj:
print(match_obj.group(0))
- 提取日期内容
line = 'xxx出生于1989年'
regex_str=".*?(\d+)年"
match_obj = re.match(regex_str,line)
if match_obj:
print(match_obj.group(0))
- 提取不同格式的出生日期
line = '张三出生于1990年10月1日'
line = '李四出生于1990-10-1'
line = '王五出生于1990-10-01'
line = '孙六出生于1990/10/1'
line = '张七出生于1990-10'
regex_str='.*出生于(\d{4}[年/-]\d{1,2}([月/-]\d{1,2}|[月/-]$|$))'
match_obj = re.match(regex_str,line)
if match_obj:
print(match_obj.group(1))
4 正则清洗文本数据
正则处理文本数据,可以剔除脏数据和指定条件的数据筛选。我们这些选用体育新闻中的一篇文本信息,读取文本信息如下:
# 读取文本信息
def readFile(path):
str_doc = ""
with open(path,'r',encoding='utf-8') as f:
str_doc = f.read()
return str_doc
# 1 读取文本
path= r'../Corpus/CSCMNews/体育/0.txt'
str_doc = readFile(path)
print(str_doc
原始新闻文本节选如下:
马晓旭意外受伤让国奥警惕 无奈大雨格外青睐殷家军 记者傅亚雨沈阳报道 来到沈阳,国奥队依然没有摆脱雨水的困扰。7月31日下午6点,国奥队的日常训练再度受到大雨的干扰,无奈之下队员们只慢跑了25分钟就草草收场。 31日上午10点,国奥队在奥体中心外场训练的时候,天就是阴沉沉的,气象预报显示当天下午沈阳就有大雨,但幸好队伍上午的训练并没有受到任何干扰。 下午6点,当球队抵达训练场时,大雨已经下了几个小时,而且丝毫没有停下来的意思。抱着试一试的态度,球队开始了当天下午的例行训练,25分钟过去了,天气没有任何转好的迹象,为了保护球员们,国奥队决定中止当天的训练,全队立即返回酒店。
我们假设需要清除文本中的特殊符号、标点、英文、数字等,仅仅只保留汉字信息,甚至于去除换行符,还有多个空格转变成一个空格。当然,以上这几点也是数据清洗中常见的情况,其代码实现如下:
def textParse(str_doc):
# 正则过滤掉特殊符号、标点、英文、数字等。
r1 = '[a-zA-Z0-9’!"#$%&\'()*+,-./::;;|<=>?@,—。?★、…【】《》?“”‘’![\\]^_`{|}~]+'
# 去除换行符
str_doc=re.sub(r1, ' ', str_doc)
# 多个空格成1个
str_doc=re.sub(r2, ' ', str_doc)
return str_doc
# 正则清洗字符串
word_list=textParse(str_doc)
print(word_list)
执行上述代码,文本信息清洗后结果如下:

以上实验,只是简单的使用正则方法处理文本信息,具体正则使用情况视情形而定。有时候我们面对的不一定是纯文本信息,也有可能是网页数据,或者是微博数据。我们如何去清洗这些半结构化数据呢?
5 正则HTML网页数据
设想我们现在有这样一个需求,任务是做信息抽取,然后构建足球球员技能数据库。你首先想到的是一些足球网站,然后编写爬虫代码去爬取足球相关的新闻,并对这些网页信息本地化存储如下图所示:
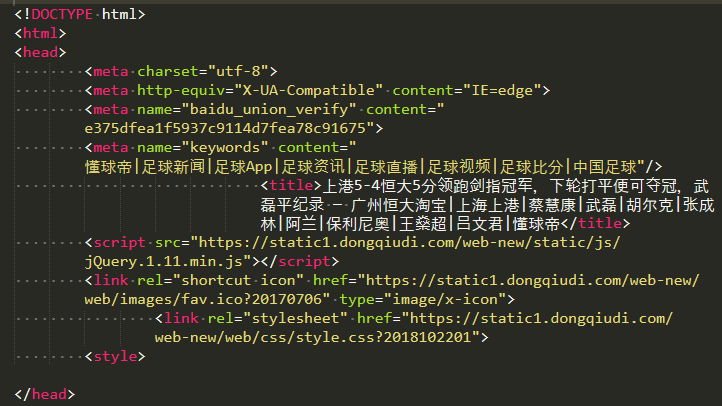
乍一看非常头疼,我们如何抽取文本信息?一篇篇手工处理显然不现实,采用上面正则方法会出现各种形式干扰数据。这里,我们介绍一种网页数据通用的正则处理方法。实现代码如下:
# 清洗HTML标签文本
# @param htmlstr HTML字符串.
def filter_tags(htmlstr):
# 过滤DOCTYPE
htmlstr = ' '.join(htmlstr.split()) # 去掉多余的空格
re_doctype = re.compile(r'<!DOCTYPE .*?> ', re.S)
s = re_doctype.sub('',htmlstr)
# 过滤CDATA
re_cdata = re.compile('//<!CDATA\[[ >]∗ //\] > ', re.I)
s = re_cdata.sub('', s)
# Script
re_script = re.compile('<\s*script[^>]*>[^<]*<\s*/\s*script\s*>', re.I)
s = re_script.sub('', s) # 去掉SCRIPT
# style
re_style = re.compile('<\s*style[^>]*>[^<]*<\s*/\s*style\s*>', re.I)
s = re_style.sub('', s) # 去掉style
# 处理换行
re_br = re.compile('<br\s*?/?>')
s = re_br.sub('', s) # 将br转换为换行
# HTML标签
re_h = re.compile('</?\w+[^>]*>')
s = re_h.sub('', s) # 去掉HTML 标签
# HTML注释
re_comment = re.compile('<!--[^>]*-->')
s = re_comment.sub('', s)
# 多余的空行
blank_line = re.compile('\n+')
s = blank_line.sub('', s)
# 剔除超链接
http_link = re.compile(r'(http://.+.html)')
s = http_link.sub('', s)
return s
# 正则处理html网页数据
s=filter_tags(str_doc)
print(s)
执行上述代码,得到以下结果:

6 实战案例:批量新闻文本数据清洗
我们详细的介绍了迭代遍历与yield生成器遍历的两个小实验,通过实验对比,高效文件读取方式效果显著。上节我们只是读取文件名,那么对文件内容如何修改?这是本节侧重的知识点。其中loadFolders方法保持不变,主要对loadFiles方法进行修改。实现批量新闻文本数据清洗。
class loadFiles(object):
def __init__(self, par_path):
self.par_path = par_path
def __iter__(self):
folders = loadFolders(self.par_path)
for folder in folders: # level directory
catg = folder.split(os.sep)[-1]
for file in os.listdir(folder): # secondary directory
file_path = os.path.join(folder, file)
if os.path.isfile(file_path):
this_file = open(file_path, 'rb') #rb读取方式更快
content = this_file.read().decode('utf8')
yield catg, content
this_file.close()
在统计学中,抽样是一种推论统计方法,它是指从目标总体中抽取一部分个体作为样本,通过观察样本的某一或某些属性,依据所获得的数据对总体的数量特征得出具有一定可靠性的估计判断,从而达到对总体的认识。抽样方法诸多,常见的包括以下几个方法:
- 简单随机抽样,也叫纯随机抽样。从总体N个单位中随机地抽取n个单位作为样本,使得每一个容量为样本都有相同的概率被抽中。特点是:每个样本单位被抽中的概率相等,样本的每个单位完全独立,彼此间无一定的关联性和排斥性。简单随机抽样是其它各种抽样形式的基础。通常只是在总体单位之间差异程度较小和数目较少时,才采用这种方法。
- 系统抽样,也称等距抽样。将总体中的所有单位按一定顺序排列,在规定的范围内随机地抽取一个单位作为初始单位,然后按事先规定好的规则确定其他样本单位。先从数字1到k之间随机抽取一个数字r作为初始单位,以后依次取r+k、r+2k……等单位。这种方法操作简便,可提高估计的精度。
- 分层抽样,将抽样单位按某种特征或某种规则划分为不同的层,然后从不同的层中独立、随机地抽取样本。从而保证样本的结构与总体的结构比较相近,从而提高估计的精度。
- 整群抽样,将总体中若干个单位合并为组,抽样时直接抽取群,然后对中选群中的所有单位全部实施调查。抽样时只需群的抽样框,可简化工作量,缺点是估计的精度较差。
接下来,我们实现新闻文本的抽样读取,我们假设抽样率为5即每隔5条信息处理一篇文章,然后每处理5000篇文章在屏幕打印一条信息,其执行代码如下:
if __name__=='__main__':
start = time.time()
filepath = os.path.abspath(r'../Corpus/CSCMNews')
files = loadFiles(filepath)
n = 5 # n 表示抽样率
for i, msg in enumerate(files):
if i % n == 0:
if int(i/n) % 1000 == 0:
print('{t} *** {i} \t docs has been dealed'.format(i=i, t=time.strftime('%Y-%m-%d %H:%M:%S',time.localtime())))
end = time.time()
print('total spent times:%.2f' % (end-start)+ ' s')
我们使用简单抽样的方法,信息处理结果如下图所示,总耗时为1120.44秒。
我们最终目的是通过批量操作去清洗文本信息,到目前为止,我们只是实现了文件的遍历和文本提取。并且我们知道如何使用简单抽样,距离最终目的只是一步之遥。这里我们还有提前前文正则处理文本的textParse方法,本节直接导入即可,接下来,我们就是提取文章类别、文章内容、正则清洗。其实现代码如下
if __name__=='__main__':
start = time.time()
filepath = os.path.abspath(r'../Corpus/CSCMNews')
files = loadFiles(filepath)
n = 5 # n 表示抽样率, n抽1
for i, msg in enumerate(files):
if i % n == 0:
catg = msg[0] # 文章类别
content = msg[1] # 文章内容
content = textParse(content) # 正则清洗
if int(i/n) % 1000 == 0:
print('{t} *** {i} \t docs has been dealed'
.format(i=i, t=time.strftime('%Y-%m-%d %H:%M:%S',time.localtime())),'\n',catg,':\t',content[:20])
end = time.time()
print('total spent times:%.2f' % (end-start)+ ' s')
运行main函数实现最终结果:
>> 限时福利:《福利:33套AI技术视频免费领取》
如何使用正则做文本数据的清洗(附免费AI视频福利)的更多相关文章
- 采用Json字符串,往服务器回传大量富文本数据时,需要注意的地方,最近开发时遇到的问题。
json字符串中存在常规的用户输入的字符串,和很多的富文本样式标签(用户不能直接看到,点击富文本编辑器中的html源码按钮能看到),例如下面的: <p><strong>富文本& ...
- 如何使用 scikit-learn 为机器学习准备文本数据
欢迎大家前往云+社区,获取更多腾讯海量技术实践干货哦~ 文本数据需要特殊处理,然后才能开始将其用于预测建模. 我们需要解析文本,以删除被称为标记化的单词.然后,这些词还需要被编码为整型或浮点型,以用作 ...
- Python文本数据互相转换(pandas and win32com)
(工作之后,就让自己的身心都去休息吧) 今天介绍一下文本数据的提取和转换,这里主要实例的转换为excel文件(.xlsx)转换world文件(.doc/docx),同时需要使用win32api,同py ...
- NLP相关问题中文本数据特征表达初探
1. NLP问题简介 0x1:NLP问题都包括哪些内涵 人们对真实世界的感知被成为感知世界,而人们用语言表达出自己的感知视为文本数据.那么反过来,NLP,或者更精确地表达为文本挖掘,则是从文本数据出发 ...
- 机器学习入门-文本数据-构造词频词袋模型 1.re.sub(进行字符串的替换) 2.nltk.corpus.stopwords.words(获得停用词表) 3.nltk.WordPunctTokenizer(对字符串进行分词操作) 4.np.vectorize(对函数进行向量化) 5. CountVectorizer(构建词频的词袋模型)
函数说明: 1. re.sub(r'[^a-zA-Z0-9\s]', repl='', sting=string) 用于进行字符串的替换,这里我们用来去除标点符号 参数说明:r'[^a-zA-Z0- ...
- 亿级别G级别文本数据去重
亿级别G级别文本数据去重 文件总行数 字节数 去重后行数 [root@d mongoexport]# wc -l superpub-ask-question.csv126530681 superpub ...
- 视频网站数据MapReduce清洗及Hive数据分析
一.需求描述 利用MapReduce清洗视频网站的原数据,用Hive统计出各种TopN常规指标: 视频观看数 Top10 视频类别热度 Top10 视频观看数 Top20 所属类别包含这 Top20 ...
- 浏览器在一次 HTTP 请求中,需要传输一个 4097 字节的文本数据给服务端,可以采用那些方式?
浏览器在一次 HTTP 请求中,需要传输一个 4097 字节的文本数据给服务端,可以采用那些方式? 存入 IndexdDB 写入 COOKIE 放在 URL 参数 写入 Session 使用 POST ...
- scikit-learning教程(三)使用文本数据
使用文本数据 本指南的目标是探讨scikit-learn 一个实际任务中的一些主要工具:分析二十个不同主题的文本文档(新闻组帖子)集合. 在本节中,我们将看到如何: 加载文件内容和类别 提取适用于机器 ...
随机推荐
- [IDE]快捷键整理
VS Resharper eclipse 备注 运行 Ctrl+F5 - Ctrl+F11 调试 F5 - F11 逐语句执行 F11 - F5 IE.FF: F11 逐过程执行 F10 ...
- 福州大学oj 1752 A^B mod C ===>数论的基本功。位运用。五星*****
Problem 1752 A^B mod C Accept: 579 Submit: 2598Time Limit: 1000 mSec Memory Limit : 32768 KB P ...
- hdu Square DFS
Square Time Limit: 10000/5000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Sub ...
- CodeForces765A
A. Neverending competitions time limit per test:2 seconds memory limit per test:512 megabytes input: ...
- 浅谈脚本化css(三)之方块运动函数
我们可以写一个让小方块运动的函数: div#demo { width: 100px; ; position: absolute; ; ; } var div = document.getElement ...
- Git学习 之 安装
1.官网下载 https://git-scm.com/downloads 2.修改安装目标路径,其他默认安装 3.通过系统管理员身份打开cmd,输入git 检查是否安装成功
- iis配置asp.net常见问题解决方案
很多朋友在用IIS6架网站的时候遇到不少问题,而这些问题有些在过去的IIS5里面就遇到过,有些是新出来的,俺忙活了一下午,做 了很多次试验,结合以前的排错经验,做出了这个总结,希望能给大家帮上忙:) ...
- 模拟时钟(AnalogClock)
模拟时钟(AnalogClock) 显示一个带时钟和分针的表面 会随着时间的推移变化 常用属性: android:dial 可以为表面提供一个自定义的图片 下面我们直接看代码: 1.Activity ...
- 一起来学习android自定义控件—边缘凹凸的View
1前言 最近做项目的时候遇到一个卡劵的效果,由于自己觉得用图片来做的话可以会出现适配效果不好,再加上自己自定义view方面的知识比较薄弱,所以想试试用自定义View来实现.但是由于自己知识点薄弱,一开 ...
- 润乾报表在proxool应用下的数据源配置
大多数应用会使用proxool数据连接池,proxool.xml的配置文件如下: <?xml version="1.0″ encoding="UTF-8″?> & ...