哈夫曼编码(Huffman coding)的那些事,(编码技术介绍和程序实现)
前言
哈夫曼编码(Huffman coding)是一种可变长的前缀码。哈夫曼编码使用的算法是David A. Huffman还是在MIT的学生时提出的,并且在1952年发表了名为《A Method for the Construction of Minimum-Redundancy Codes》的文章。编码这种编码的过程叫做哈夫曼编码,它是一种普遍的熵编码技术,包括用于无损数据压缩领域。由于哈夫曼编码的运用广泛,本文将简要介绍:
哈夫曼编码的编码(不包含解码)原理
代码(java)实现过程
一、哈弗曼编码原理
哈夫曼编码使用一种特别的方法为信号源中的每个符号设定二进制码。出现频率更大的符号将获得更短的比特,出现频率更小的符号将被分配更长的比特,以此来提高数据压缩率,提高传输效率。具体编码步骤主要为,
1、统计:
在开始编码时,通常都需要对信号源,也就是本文的一段文字,进行处理,计算出每个符号出现的频率,得到信号源的基本情况。接下来就是对统计信息进行处理了
2、构造优先对列:
把得到的符号添加到优先队列中,此优先队列的进出逻辑是频率低的先出,因此在设计优先队列时需要如此设计,如果不熟悉优先队列,请阅读相关书籍,在此不做过多概述。得到包含所有字符的优先队列后,就是处理优先队列中的数据了。
3、构造哈夫曼树:
哈夫曼树是带权值得二叉树,我们使用的哈夫曼树的权值自然就是符号的频率了,我们构建哈夫曼树是自底向上的,先构建叶子节点,然后逐步向上,最终完成整颗树。先把队列中的一个符号出列,也就是最小频率的符号,,然后再出列一个符号。这两个符号将作为哈夫曼树的节点,而且这两个节点将作为新节点,也就是它们父节点,的左右孩子节点。新节点的频率,即权值,为孩子节点的和。把这个新节点添加到队列中(队列会重新根据权值排序)。重复上面的步骤,两个符号出列,构造新的父节点,入列……直到队列最后只剩下一个节点,这个节点也就是哈夫曼树的根节点了。
4、为哈弗曼树编码:
哈夫曼树的来自信号源的符号都是叶子节点,需要知道下。树的根节点分配比特0,左子树分配0,右字数分配1。然后就可以得到符号的码值了。
二、示例(转自这的)
假如我有A,B,C,D,E五个字符,出现的频率(即权值)分别为5,4,3,2,1,那么我们第一步先取两个最小权值作为左右子树构造一个新树,即取1,2构成新树,其结点为1+2=3,如图:
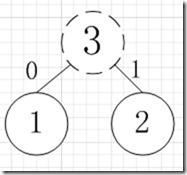
虚线为新生成的结点,第二步再把新生成的权值为3的结点放到剩下的集合中,所以集合变成{5,4,3,3},再根据第二步,取最小的两个权值构成新树,如图:
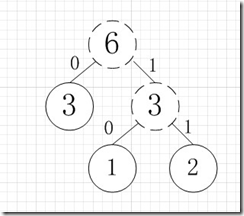
再依次建立哈夫曼树,如下图:
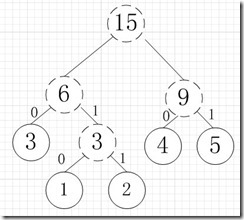
其中各个权值替换对应的字符即为下图:
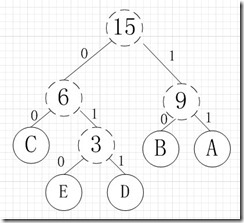
所以各字符对应的编码为:A->11,B->10,C->00,D->011,E->010
如下图也可以加深大家的理解(图片来自于wikipedia)

下面的这个图片是互动示例的截图,来自http://www.hightechdreams.com/weaver.php?topic=huffmancoding,输入符号就会动态展示出树的构建,有兴趣的朋友可以去看看

三、 代码实现
先是设计一个用于节点比较的接口
package com.huffman; //用来实现节点比较的接口
public interface Compare<T> {
//小于
boolean less(T t);
}
然后写一个哈夫曼树节点的类,主要是用于储存符号信息的,实现上面的接口,get、set方法已经省略了
package com.huffman;
public class Node implements Compare<Node>{
//节点的优先级
private int nice;
//字符出现的频率(次数)
private int count;
//文本中出现的字符串
private String str;
//左孩子
private Node leftNode;
//右孩子
private Node rightNode;
//对应的二进制编码
private String code;
public Node(){
}
public Node(int nice, String str, int count){
this.nice = nice;
this.str = str;
this.count = count;
}
//把节点(权值,频率)相加,返回新的节点
public Node add(Node node){
Node n = new Node();
n.nice = this.nice + node.nice;
n.count = this.count + node.count;
return n;
}
public boolean less(Node node) {
return this.nice < node.nice;
}
public String toString(){
return String.valueOf(this.nice);
}
设计一个优先队列
package com.huffman;
import java.util.List;
public class PriorityQueue<T extends Compare<T>> {
public List<T> list = null;
public PriorityQueue(List<T> list){
this.list = list;
}
public boolean empty(){
return list.size() == 0;
}
public int size(){
return list.size();
}
//移除指定索引的元素
public void remove(int number){
int index = list.indexOf(number);
if (-1 == index){
System.out.println("data do not exist!");
return;
}
list.remove(index);
//每次删除一个元素都需要重新构建队列
buildHeap();
}
//弹出队首元素,并把这个元素返回
public T pop(){
//由于优先队列的特殊性,第一个元素(索引为0)是不使用的
if (list.size() == 1){
return null;
}
T first = list.get(1);
list.remove(1);
buildHeap();
return first;
}
//加入一个元素到队列中
public void add(T object){
list.add(object);
buildHeap();
}
//维护最小堆
private List<T> minHeap(List<T> list, int position, int heapSize){
int left = 2 * position; //得到左孩子的位置
int right = left + 1; //得到右孩子的位置
int min = position; //min储存最小值的位置,暂时假定当前节点是最小节点
//寻找最小节点
if (left < heapSize && list.get(left).less(list.get(min))){
min = left;
}
if (right < heapSize && list.get(right).less(list.get(min))){
min = right;
}
if (min != position){
exchange(list, min, position); //交换当前节点与最小节点的位置
minHeap(list, min, heapSize); //重新维护最小堆
}
return list;
}
//交换元素位置
private List<T> exchange(List<T> list, int former, int latter){
T temp = list.get(former);
list.set(former, list.get(latter));
list.set(latter, temp);
return list;
}
//构建最小堆
public List<T> buildHeap(){
int i;
for (i = list.size() - 1; i > 0; i--){
minHeap(list, i, list.size());
}
return list;
}
}
最后是用一个类构建哈夫曼树
package com.huffman; import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map; public class Huffman {
//优先队列
private PriorityQueue<Node> priorQueue; //需要处理的文本
private String[] text; //文本处理后的统计信息
private Map<String, Integer> statistics; //huffman编码最终结果
private Map<String, String> result; public Huffman(String text) {
this.text = text.split("\\W+");
init();
} private void init() {
statistics = new HashMap<String, Integer>();
result = new HashMap<String, String>();
} //获取字符串统计信息,得到如"abc":3,"love":12等形式map
private void getStatistics() {
int count;
for (String c : text) {
if (statistics.containsKey(c)) {
count = statistics.get(c);
count++;
statistics.put(c, count);
} else {
statistics.put(c, 1);
}
}
} //构建huffman树
private void buildTree() {
List<Node> list = new ArrayList<Node>();
list.add(new Node(2222, "123", 2222)); //因为优先队列的特殊性,添加这个不使用的节点
//把字符串信息储存到节点中,并把节点添加到arrayList中
for (String key : statistics.keySet()) {
Node leaf = new Node(statistics.get(key), key, statistics.get(key));
list.add(leaf);
}
Node tree = null; //用于储存指向huffman树根节点的指针
priorQueue = new PriorityQueue<Node>(list); //以上面节点为元素,构建优先队列
priorQueue.buildHeap();
Node first = null;
Node second = null;
Node newNode = null;
do {
first = priorQueue.pop(); //取出队首的元素,作为左孩子节点
second = priorQueue.pop(); //取出队首的元素,作为右孩子节点
newNode = first.add(second); //构建父节点
priorQueue.add(newNode); //把父节点添加到队列中
newNode.setLeftNode(first);
newNode.setRightNode(second);
tree = newNode; //把tree指向新节点
} while (priorQueue.size() > 2); //由于队列中有一个元素是不使用的,所以队列只剩最后一个元素(实际就是队列只有2个元素)时就该退出循环了。
//最后剩下一个节点是根节点,把它取出来,并拼装树
Node root = priorQueue.pop();
root.setCode("0");
root.setLeftNode(tree.getLeftNode());
root.setRightNode(tree.getRightNode());
tree = null;
setCodeNum(root); //遍历树,为每个节点编码
System.out.println("----------------------------");
System.out.println(result);
} public void buildHuffman(){
getStatistics(); //收集统计信息
buildTree();
for (String c : statistics.keySet()) {
System.out.println(c + ":" + statistics.get(c));
}
} //编码
private void setCodeNum(Node tree){
if(null == tree){
return;
}
Node left = tree.getLeftNode();
Node right = tree.getRightNode();
if (left !=null){
left.setCode("0" + tree.getCode()); //左孩子的码为0
if (statistics.containsKey(left.getStr())){
//如果节点在统计表里,把它添加到result中
result.put(left.getStr(), left.getCode());
}
}
if (right != null){
right.setCode("1" + tree.getCode()); //右孩子的码为1
if (statistics.containsKey(right.getStr())){
//如果节点在统计表里,把它添加到result中 result.put(right.getStr(), right.getCode());
}
}
setCodeNum(left); //递归
setCodeNum(right); //递归 } }
注意:代码实现的提供主要是为了概要介绍哈夫曼编码的实现过程,部分代码逻辑并为深思,效率也略低,请大家只做参考,并多参考其他人的代码。
参考文章:
http://people.cs.pitt.edu/~kirk/cs1501/animations/Huffman.html
http://www.hightechdreams.com/weaver.php?topic=huffmancoding
延伸阅读:
http://www.hightechdreams.com/weaver.php?topic=huffmancoding
这个网站是由一群用它们的话说是为“对编程狂热或者有兴趣的人建立的”,提供了很多算法有关的互动的例子,以及一些小程序
http://www.siggraph.org/education/materials/HyperGraph/video/mpeg/mpegfaq/huffman_tutorial.html
这是一个建立哈夫曼树的简明教程
http://rosettacode.org/wiki/Huffman_codes
提供了多语言的哈夫曼树实现,包括c, c++, java, c#, python, lisp等。有兴趣的朋友可以参考下,看看国外的码农是怎么玩哈夫曼树的。
哈夫曼编码(Huffman coding)的那些事,(编码技术介绍和程序实现)的更多相关文章
- 哈夫曼(Huffman)树和哈夫曼编码
一.哈夫曼(Huffman)树和哈夫曼编码 1.哈夫曼树(Huffman)又称最优二叉树,是一类带权路径长度最短的树, 常用于信息检测. 定义: 结点间的路径长度:树中一个结点到另一个结点之间分支数目 ...
- 哈夫曼(huffman)树和哈夫曼编码
哈夫曼树 哈夫曼树也叫最优二叉树(哈夫曼树) 问题:什么是哈夫曼树? 例:将学生的百分制成绩转换为五分制成绩:≥90 分: A,80-89分: B,70-79分: C,60-69分: D,<60 ...
- Python---哈夫曼树---Huffman Tree
今天要讲的是天才哈夫曼的哈夫曼编码,这是树形数据结构的一个典型应用. !!!敲黑板!!!哈夫曼树的构建以及编码方式将是我们的学习重点. 老方式,代码+解释,手把手教你Python完成哈夫曼编码的全过程 ...
- 哈夫曼树Huffman
哈夫曼树处理这样的一种问题: 给出一棵n个叶子的k叉树,每个叶子有一个权值wi,要求最小化∑wi*di di表示,第i个叶子节点到根节点的距离.(一般是边数) 处理方法比较固定. 贪心的思路:我们让权 ...
- 哈夫曼(Huffman)树及其应用
Huffman树又称最优树,是一类带权路径长度最短的树,带权路径长度为从该节点到树根之间的路径长度与节点上权值的成积. 那么如何构建一个Huffman树呢?就需要Huffman算法 1.利用给定的n个 ...
- 霍夫曼编码(Huffman Coding)
霍夫曼编码(Huffman Coding)是一种编码方法,霍夫曼编码是可变字长编码(VLC)的一种. 霍夫曼编码使用变长编码表对源符号(如文件中的一个字母)进行编码,其中变长编码表是通过一种评估来源符 ...
- 哈夫曼编码的理解(Huffman Coding)
哈夫曼编码(Huffman Coding),又称霍夫曼编码,是一种编码方式,可变字长编码(VLC)的一种.Huffman于1952年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的平均长度最 ...
- 赫夫曼\哈夫曼\霍夫曼编码 (Huffman Tree)
哈夫曼树 给定n个权值作为n的叶子结点,构造一棵二叉树,若带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree).哈夫曼树是带权路径长度最短的树,权值较大的结点离 ...
- Huffuman Coding (哈夫曼编码)
哈夫曼编码(Huffman Coding),又称霍夫曼编码,是一种编码方式,哈夫曼编码是可变字长编码(VLC)的一种.Huffman于1952年提出一种编码方法,该方法完全依据字符出现概率来构造异字头 ...
随机推荐
- Android的基础知识点
一.Intent的2种启动方式 1.显示启动: setClass(“包名”,“启动的Activity.class”); XML文件中启动Activity 2.隐示启动: setAction(" ...
- 1.在html中引入js文件和Jquery框架
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Java 日期加减
import java.text.SimpleDateFormat;import java.util.Calendar;import java.util.Date; public class Test ...
- Swift 里字符串(三)small String
 small string, 只有两个 UInt64 的字,这里面存储了所有的信息. 内存布局如下:  第二个 UInt64 存储了标记位和长度信息,以及部分字符串的值 // Get an int ...
- iOS多线程---NSOperation介绍和使用
1. NSOperation实现多线程编程,需要和NSOperationQueue一起使用. (1)先将要执行的操作封装到NSOperation中 (2)将NSOperation对象添加到NSOpe ...
- Python小白学习之路(十六)—【内置函数一】
将68个内置函数按照其功能分为了10类,分别是: 数学运算(7个) abs() divmod() max() min() pow() round() sum() 类型转换(24个) bo ...
- WebDriverAPI(4)
单击某个元素 采用元素id.click()方法即可 双击某个元素id.doubleClick 操作单选下拉列表 测试网页HTML代码 <html> <body> <sel ...
- Mac 10.12连接iSCSI硬盘软件iSCSI Initiator X
Mac下的iSCSI协议苹果一直以来没有集成,而网络上流传的最好用支持iSCSI硬盘的软件是globalSAN,但是这个软件是收费的,当然有破解版,只不多不太好找,因为现在用iSCSI的用户已经很少了 ...
- (转)Python——functools
原文:https://www.cnblogs.com/Security-Darren/p/4168310.html#t7 http://www.wklken.me/posts/2013/08/18/p ...
- (转)http://blog.csdn.net/renfufei/article/details/38474435
原文:http://blog.csdn.net/renfufei/article/details/38474435