从 Hadoop 1.0 到 Hadoop 2.0 ,你需要了解这些
学习大数据,刚开始接触的是 Hadoop 1.0,然后过度到 Hadoop 2.0 ,这里为了书写方便,本文中 Hadoop 1.0 采用 HV1 的缩写方式,Hadoop 2.0 采用 HV2 的缩写方式。
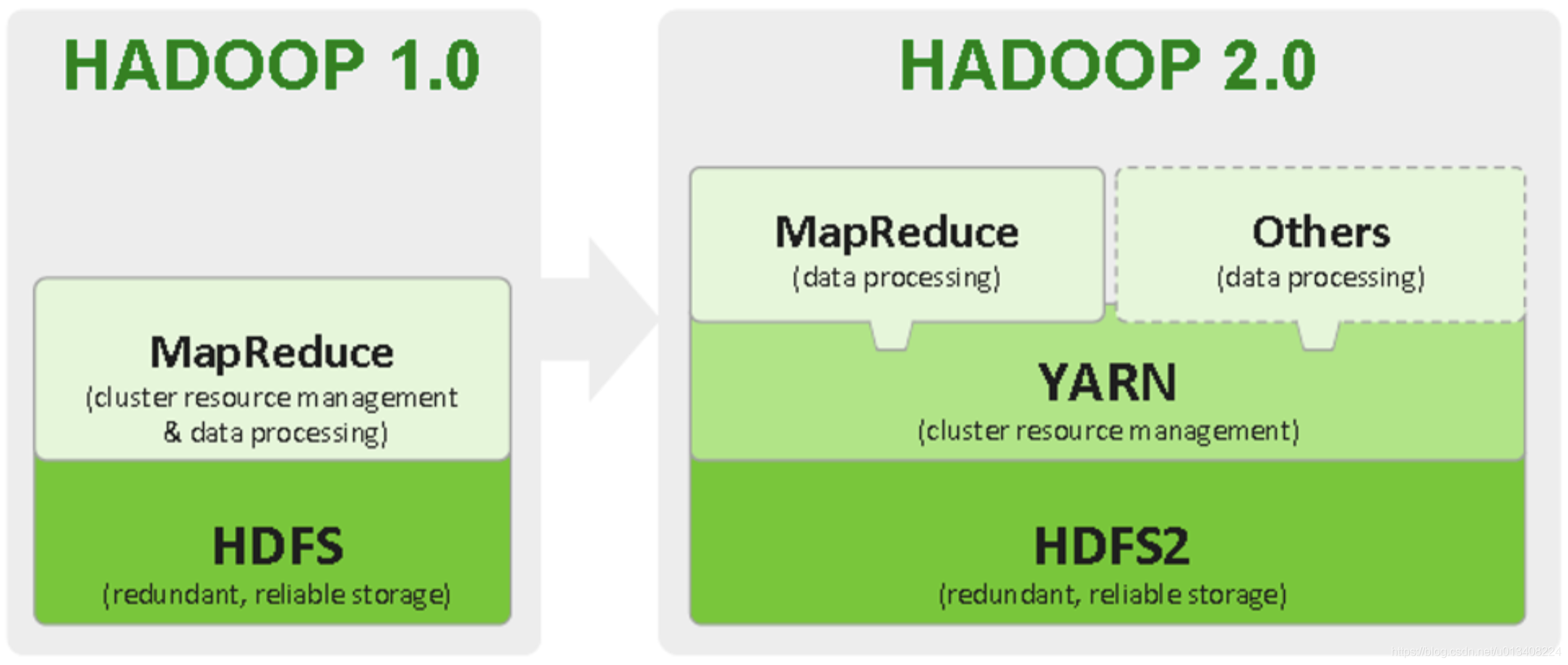
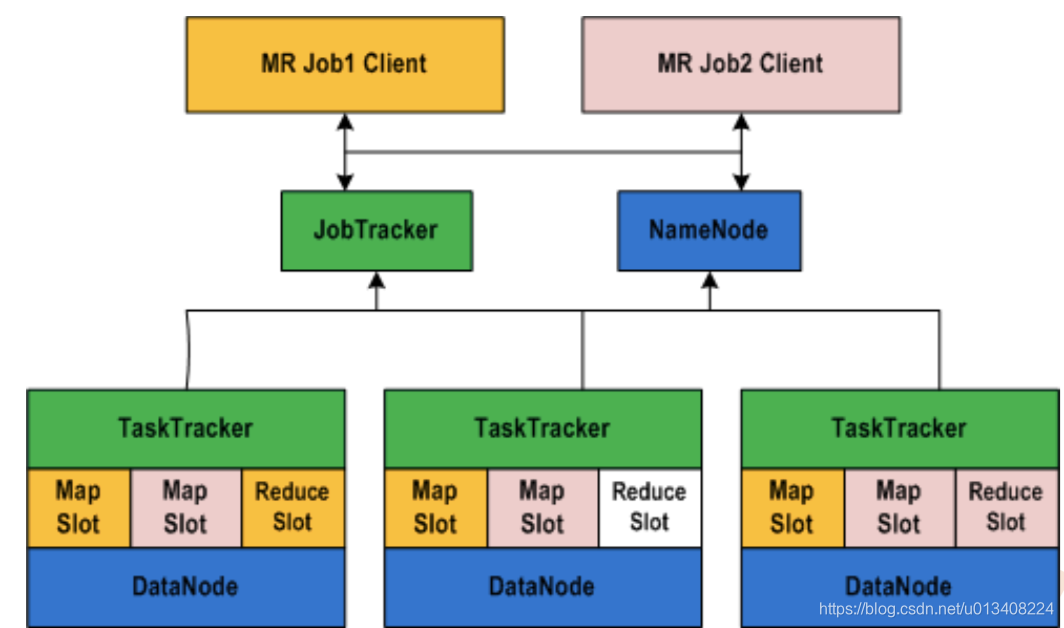
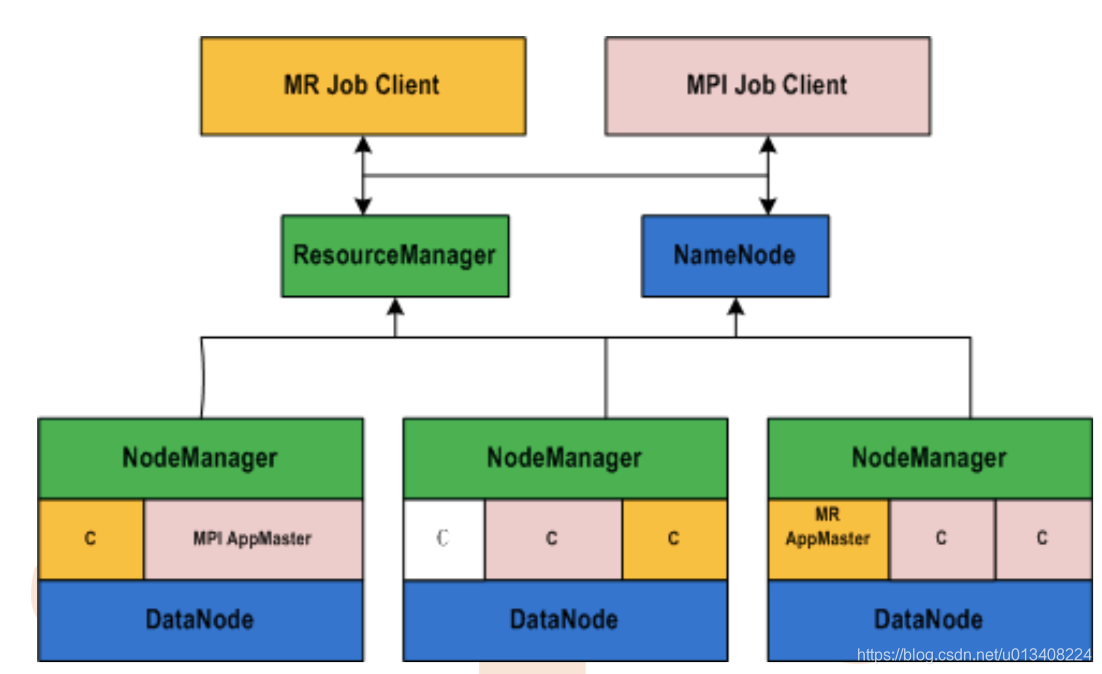
HV1 中不得不提的两个进程:JobTracker 和 TaskTracker。JobTracker 主要负责任务调度和集群资源管理,TaskTracker 主要负责任务执行。在 HV1 向 HV2 变迁后,引入了一个中间件Yarn,负责集群资源调度。可以简单地理解,Yarn 分离出了JobTracker 资源管理的权柄。
Yarn
Yarn 是一个分布式资源调度框架,其架构图如下所示:
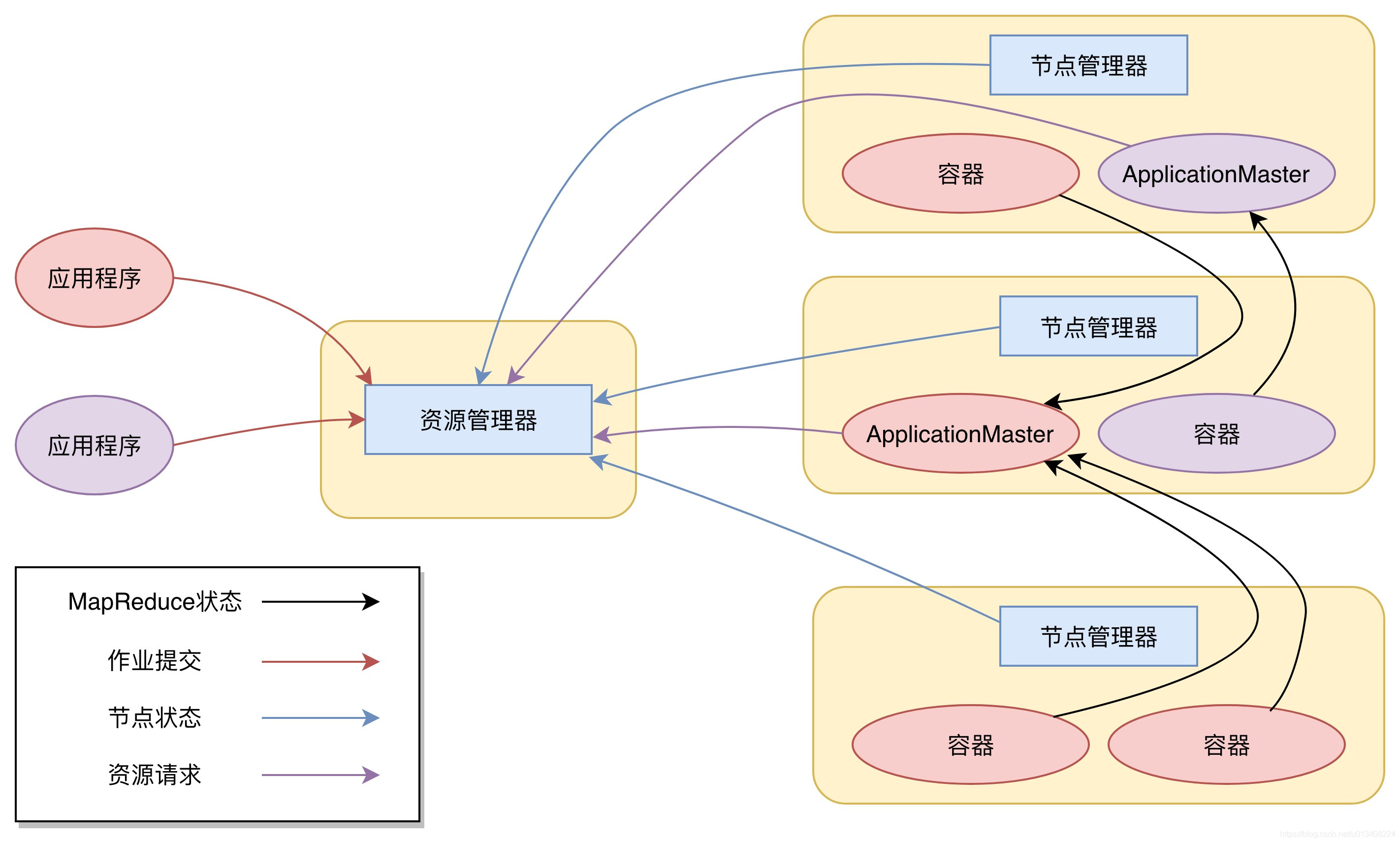
图中的三个重要进程:
- 资源管理器(ResourceManager,RM)
- 节点管理器(NodeManager,NM)
- ApplicationMaster(AM)
两个对比:
- Yarn 中容器(Container)可以对比 HV1 中 slot(槽) ,前者是逻辑层的概念,后者是物理层的概念。Container 是任务运行环境的抽象封装。
- HV1 中一个重要的概念 Job(作业),在 Yarn 中对应 Application(应用程序)。
HV1 和 HV2 对比示例图如下:
Yarn 的执行流程
Yarn 执行流程示意图如下所示:
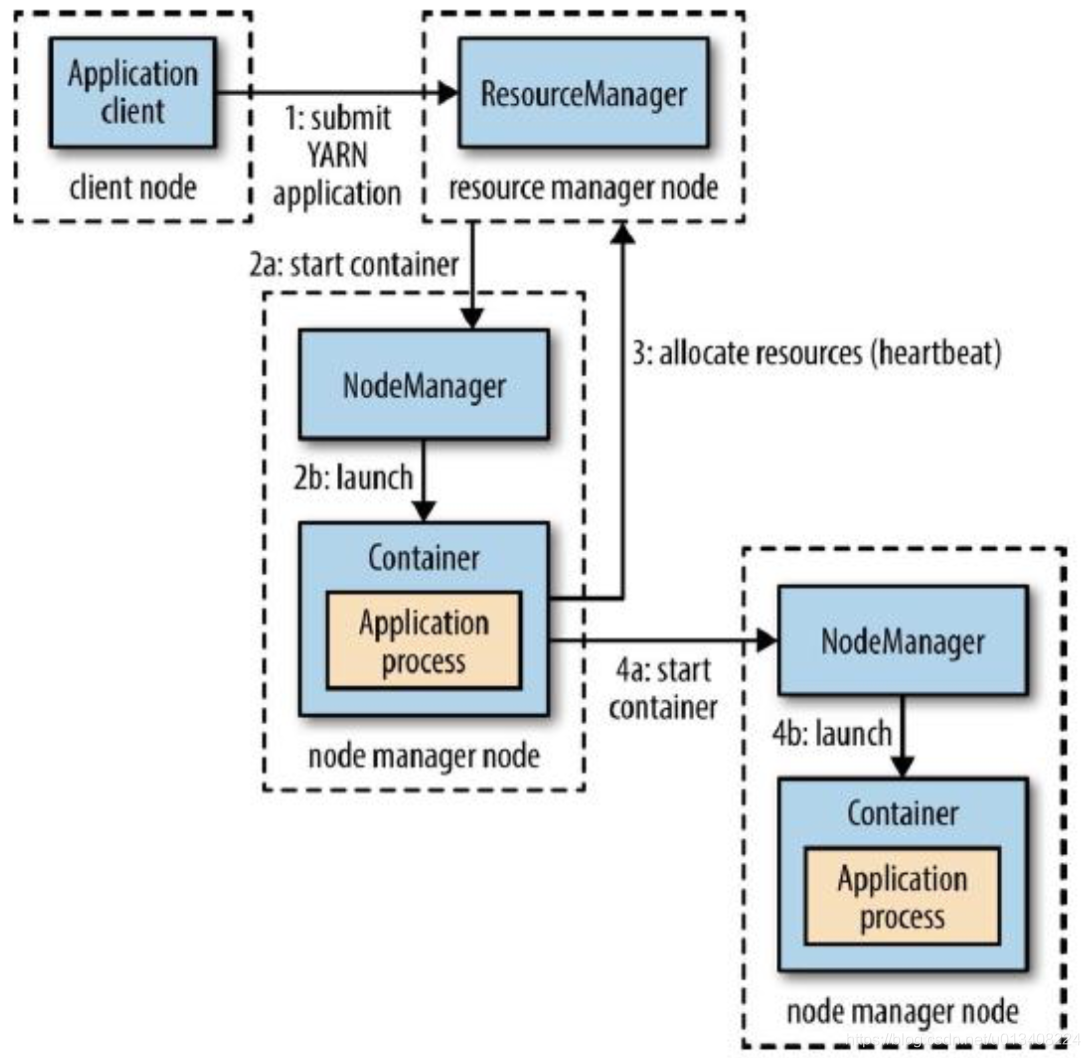
执行流程说明如下:
- Client 请求 ResourceManager 运行一个 ApplicationMaster 实例。
- ResourceManager 选择一个 NodeManager 启动一个 Container 运行 ApplicationMaster 实例。
- ApplicationMaster 根据实际需要向 ResourceManager 请求更多的 Container 资源,ApplicationMaster 通过获取到的 Container 资源执行分布式计算。
功能分析
通过执行流程,我们尝试去理解 Yarn 中三个重要进程(RM、NM、AM)对应的职责和功能。
RM 处理客户端请求,接收 JobSubmitter 提交的作业,按照作业的上下文(Context)信息,以及从 NM 收集来的状态信息,启动调度过程,分配一个 Container 作为 AM。RM 拥有系统中所有应用资源的决定权,是中心服务,调度、启动每一个作业所属的 Application,并监测 Application 的存在情况。
NM 处理来自 RM 的任务请求,接收并处理来自 AM 的 Container 启动、停止等请求。NM 负责启动应用程序的 Container ,监控它们的资源使用情况,并汇报给 RM。可以理解 NM 是在单节点上进行任务管理 和 资源管理。
AM 是应用程序的 Master,每一个 应用程序对应一个 AM,在用户提交一个应用程序时,一个 AM 的轻量型进程实例会启动,AM 协调应用程序内所有任务的执行。
HV2 新特性
HV2 的新特性包括:
- NameNode HA
- NameNode Federation
- HDFS 快照
- HDFS ACL
- 异构层级存储结构
本文只详述其中两点:NameNode HA 和NameNode Federation。NameNode HA优化的是单点故障问题,NameNode Federation优化的是集群的横向扩展问题。
NameNode HA
HV2 对 HV1 中存在的很多问题进行了优化。例如,HV1 中 NameNode 的单点故障问题,在 HV2 中可以通过一个集群中运行两个NameNode(active NameNode 和 standby NameNode)来解决。任何时间,只有一台机器处于 Active 状态,另一台机器处于standby 状态,其框架如下图所示:
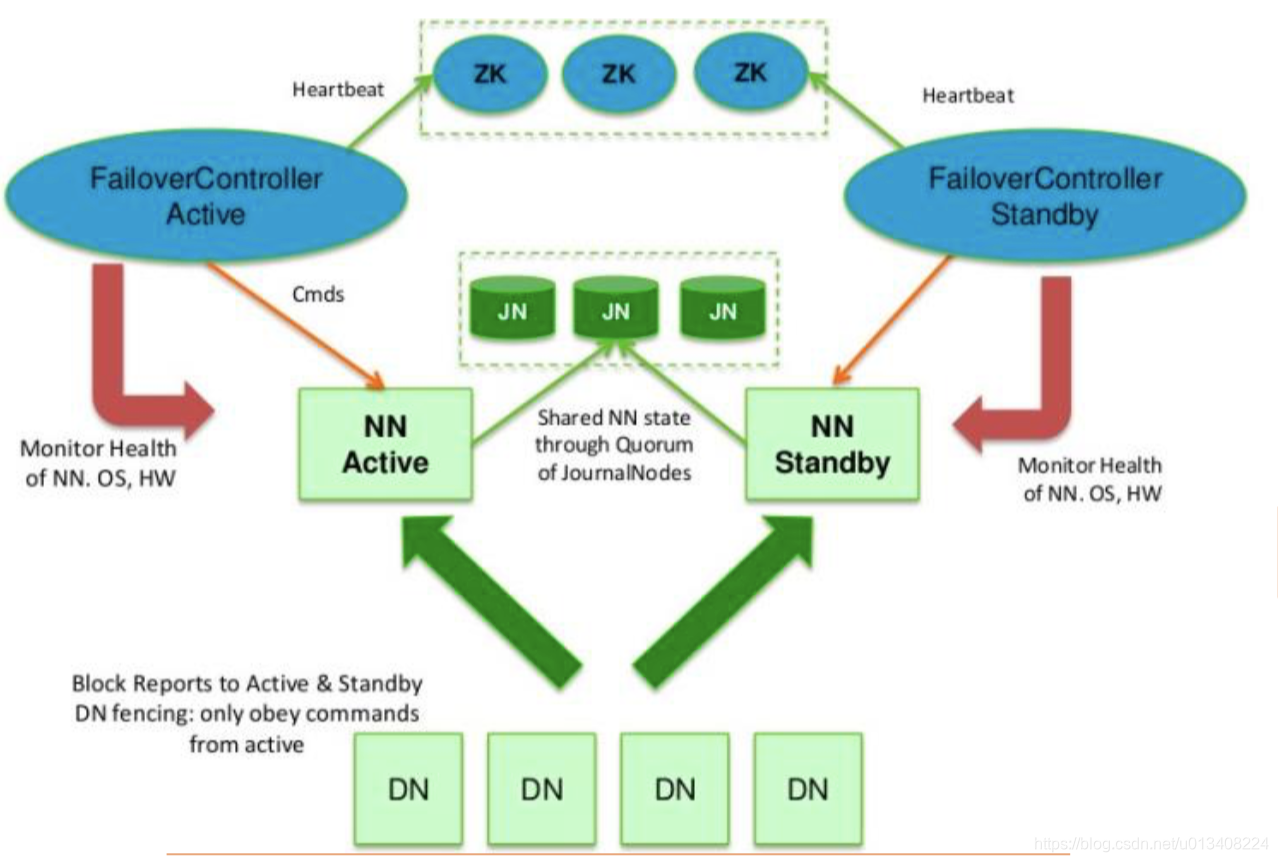
通过zookeeper(ZK)选举确定当前唯一active状态的NameNode,依赖 JournalNodes(JN)守护进程确保两个NameNode 数据同步。
NameNode Federation
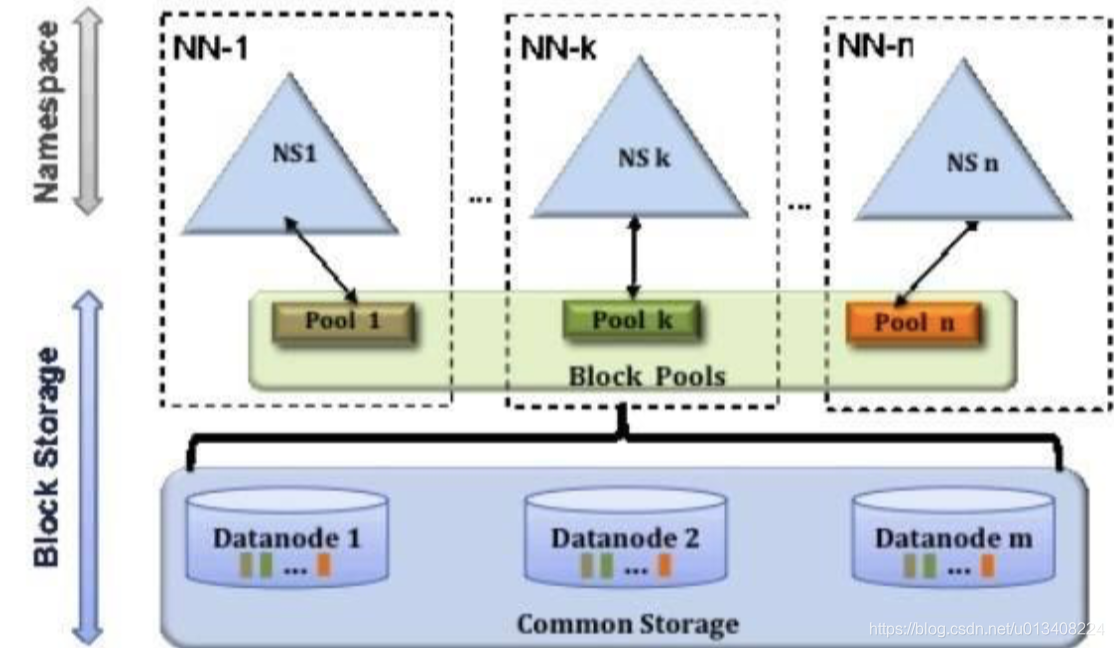
HV1 中 HDFS 只有一个NameSpace,元数据信息是存储在NameNode 上的,单一存储会使得 NameNode 的资源使用率达到上限,同时负载能力越来越高,影响 HDFS性能。HV2 中对NameNode 进行了一个横向扩展,引入了NameNode “城邦”特性。该特性允许在集群中提供多个 NameNode ,同时对外提供服务,每个 NameNode 管理一部分 DataNode。其框架如下图所示:
再谈
引入Yarn资源管理框架,将HV1中资源管理和任务调度的功能解耦,带来的好处如下:
- 减少了JobTracker(也就是现在的RM)的资源消耗,并且让监测每一个Job子任务(tasks)状态的程序分布式化了,更安全。
- AM是一个可变更的部分,用户可以对不同的编程模型编写自己的AM,让更多类型的编程模型能够跑在Hadoop集群中。
- 对于资源的表示以内存为单位,比以前以剩余slot数目更合理。
- 老的框架中,jobTracker一个很大的负担就是监控Job下的Task的运行情况,现在,这部分扔给ApplicationMaster做了。
- 资源表示成内存量,那就没有了之前的map slot/reduce slot分开造成集群资源闲置的尴尬情况。
好了,今天的博客就到这里了,期待你的指正。
从 Hadoop 1.0 到 Hadoop 2.0 ,你需要了解这些的更多相关文章
- 编译hadoop eclipse的插件(hadoop1.0)
原创文章,转载请注明: 转载自工学1号馆 欢迎关注我的个人博客:www.wuyudong.com, 更多云计算与大数据的精彩文章 在hadoop-1.0中,不像0.20.2版本,有现成的eclipse ...
- hadoop1.0 和 Hadoop 2.0 的区别
1.Hadoop概述 在Google三篇大数据论文发表之后,Cloudera公司在这几篇论文的基础上,开发出了现在的Hadoop.但Hadoop开发出来也并非一帆风顺的,Hadoop1.0版本有诸多局 ...
- Ambari2.7.3 和HDP3.1.0搭建Hadoop集群
一.环境及软件准备 1.集群规划 hdp01/10.1.1.11 hdp02/10.1.1.12 hdp03/10.1.1.13 hdp04/10.1.1.14 hdp05/10.1.1.15 a ...
- hadoop 遇到java.net.ConnectException: to 0.0.0.0:10020 failed on connection
hadoop 遇到java.net.ConnectException: to 0.0.0.0:10020 failed on connection 这个问题一般是在hadoop2.x版本里会出 ...
- failed to launch: nice -n 0 /home/hadoop/spark-2.3.3-bin-hadoop2.7/bin/spark-class org.apache.spark.deploy.worker.Worker --webui-port 8081 spark://namenode1:7077
spark2.3.3安装完成之后启动报错: [hadoop@namenode1 sbin]$ ./start-all.shstarting org.apache.spark.deploy.master ...
- Data - Hadoop单机配置 - 使用Hadoop2.8.0和Ubuntu16.04
系统版本 anliven@Ubuntu1604:~$ uname -a Linux Ubuntu1604 4.8.0-36-generic #36~16.04.1-Ubuntu SMP Sun Feb ...
- Linux上安装Hadoop集群(CentOS7+hadoop-2.8.0)
1下载hadoop 2安装3个虚拟机并实现ssh免密码登录 2.1安装3个机器 2.2检查机器名称 2.3修改/etc/hosts文件 2.4 给3个机器生成秘钥文件 2.5 在hserver1上创建 ...
- 通过tarball形式安装HBASE Cluster(CDH5.0.2)——重新编译CDH5.0.2 HADOOP点滴
本文参考博文Hadoop2.2.0遇到64位操作系统平台报错,重新编译Hadoop 由于我采用的tarball方式安装hadoop,其lib/native下根本没有内容,启动hdfs时报这个经典的na ...
- [转]hadoop运行mapreduce作业无法连接0.0.0.0/0.0.0.0:10020
14/04/04 17:15:12 INFO mapreduce.Job: map 0% reduce 0% 14/04/04 17:19:42 INFO mapreduce.Job: map 4 ...
- Hadoop集群搭建-Hadoop2.8.0安装(三)
一.准备安装介质 a).hadoop-2.8.0.tar b).jdk-7u71-linux-x64.tar 二.节点部署图 三.安装步骤 环境介绍: 主服务器ip:192.168.80.128(ma ...
随机推荐
- Android与js交互
本文转载自:http://blog.csdn.net/it1039871366/article/details/46372207 一文. Android 中可以通过webview来实现和js的交互,在 ...
- python 模块导入全局变量
在哪种情况下需要从模块导入全局变量 项目里多个脚本均更改「某一个全局变量」时 全量变量需要实现可配置时 从模块导入全局变量的方法 from test_prokject import global_va ...
- hdoj1575 Tr A(矩阵快速幂)
简单的矩阵快速幂.最后求矩阵的秩. #include<iostream> #include<cstring> using namespace std; ; int n,k; s ...
- Retrofit源码解析(上)
简介Retrofit是Square公司开发的一款针对Android网络请求的框架,官网地址http://square.github.io/retrofit/ ,在官网上有这样的一句话介绍retrofi ...
- [JavaScript] css将footer置于页面最底部
<!-- 父层 --> <div id="wapper"> <!-- 主要内容 --> <div id="main-conten ...
- [Swift实际操作]七、常见概念-(5)使用NSString对字符串进行各种操作
本文将为你演示字符串NSString的使用,NS是Cocoa类对象类型的前缀,来源于乔布斯建立的另一家公司--NeXT NSString的使用方法,和Swift语言中的String有很多相似之处.首先 ...
- SSH免密码远程登录Linux
1. 有A,B两台机(Linux/unix), 要想从A用ssh远程登录到B上(假设各自的IP,A:192.168.100:B:192.168.1.104). 2. 在A机上,用“ssh-keygen ...
- Nginx+Tomcat搭建负载均衡
一. 工具 nginx-1.8.0 apache-tomcat-6.0.33 二. 目标 实现高性能负载均衡的Tomcat集群: 三. 步骤 1.首先下载Nginx,要下载稳定 ...
- POJ 1046
#include<iostream> using namespace std; #define MAXN 16 #define inf 100000000 struct node { in ...
- node开发环境配置
node开发环境配置 用处 NodeJS——后台 JavaScript-前台 后台其他语言 1.PHP 2.Java 3.Pythonnode优势 1.性能高 nodejs php 86 1s 1分半 ...