Python_oldboy_自动化运维之路(三)
本节内容
- 列表,元组,字典
- 字符串操作
- copy的用法
- 文件操作
1.列表,元组,字典
【列表】
1.定义列表
names = ['Alex',"Tenglan",'Eric']
2.通过下标访问列表中的元素,下标从0开始计数
>>> names[0]
'Alex'
>>> names[2]
'Eric'
>>> names[-1]
'Eric'
>>> names[-2] #还可以倒着取
'Tenglan'
切片:取多个元素
>>> names = ["Alex","Tenglan","Eric","Rain","Tom","Amy"]
>>> names[1:4] #取下标1至下标4之间的数字,包括1,不包括4
['Tenglan', 'Eric', 'Rain']
>>> names[1:-1] #取下标1至-1的值,不包括-1
['Tenglan', 'Eric', 'Rain', 'Tom']
>>> names[0:3]
['Alex', 'Tenglan', 'Eric']
>>> names[:3] #如果是从头开始取,0可以忽略,跟上句效果一样
['Alex', 'Tenglan', 'Eric']
>>> names[3:] #如果想取最后一个,必须不能写-1,只能这么写
['Rain', 'Tom', 'Amy']
>>> names[3:-1] #这样-1就不会被包含了
['Rain', 'Tom']
>>> names[0::2] #后面的2是代表,每隔一个元素,就取一个
['Alex', 'Eric', 'Tom']
>>> names[::2] #和上句效果一样
['Alex', 'Eric', 'Tom']
追加
>>> names
['Alex', 'Tenglan', 'Eric', 'Rain', 'Tom', 'Amy']
>>> names.append("我是新来的")
>>> names
['Alex', 'Tenglan', 'Eric', 'Rain', 'Tom', 'Amy', '我是新来的']
插入
>>> names
['Alex', 'Tenglan', 'Eric', 'Rain', 'Tom', 'Amy', '我是新来的']
>>> names.insert(2,"强行从Eric前面插入")
>>> names
['Alex', 'Tenglan', '强行从Eric前面插入', 'Eric', 'Rain', 'Tom', 'Amy', '我是新来的'] >>> names.insert(5,"从eric后面插入试试新姿势")
>>> names
['Alex', 'Tenglan', '强行从Eric前面插入', 'Eric', 'Rain', '从eric后面插入试试新姿势', 'Tom', 'Amy', '我是新来的']
修改
>>> names
['Alex', 'Tenglan', '强行从Eric前面插入', 'Eric', 'Rain', '从eric后面插入试试新姿势', 'Tom', 'Amy', '我是新来的']
>>> names[2] = "该换人了"
>>> names
['Alex', 'Tenglan', '该换人了', 'Eric', 'Rain', '从eric后面插入试试新姿势', 'Tom', 'Amy', '我是新来的']
删除
>>> del names[2]
>>> names
['Alex', 'Tenglan', 'Eric', 'Rain', '从eric后面插入试试新姿势', 'Tom', 'Amy', '我是新来的']
>>> del names[4]
>>> names
['Alex', 'Tenglan', 'Eric', 'Rain', 'Tom', 'Amy', '我是新来的']
>>>
>>> names.remove("Eric") #删除指定元素
>>> names
['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy', '我是新来的']
>>> names.pop() #删除列表最后一个值
'我是新来的'
>>> names
['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy']
扩展
>>> names
['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy']
>>> b = [1,2,3]
>>> names.extend(b)
>>> names
['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy', 1, 2, 3]
拷贝
>>> names
['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy', 1, 2, 3] >>> name_copy = names.copy()
>>> name_copy
['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy', 1, 2, 3]
统计
>>> names
['Alex', 'Tenglan', 'Amy', 'Tom', 'Amy', 1, 2, 3]
>>> names.count("Amy")
2
排序&翻转
>>> names
['Alex', 'Tenglan', 'Amy', 'Tom', 'Amy', 1, 2, 3]
>>> names.sort() #排序
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unorderable types: int() < str() #3.0里不同数据类型不能放在一起排序了,擦
>>> names[-3] = ''
>>> names[-2] = ''
>>> names[-1] = ''
>>> names
['Alex', 'Amy', 'Amy', 'Tenglan', 'Tom', '', '', '']
>>> names.sort()
>>> names
['', '', '', 'Alex', 'Amy', 'Amy', 'Tenglan', 'Tom'] >>> names.reverse() #反转
>>> names
['Tom', 'Tenglan', 'Amy', 'Amy', 'Alex', '', '', '']
获取下标
>>> names
['Tom', 'Tenglan', 'Amy', 'Amy', 'Alex', '', '', '']
>>> names.index("Amy")
2 #只返回找到的第一个下标
案例1:如何删除列表重复的第二个值,默认只会删除第一个。
#删除重复第二个b
names=["a","b","c","d","b"]
print(names) first=names.index("b")
print(first) print(names[first:])
print(names[first+1:]) second=names[first+1:].index("b")
print(second) del names[first+second+1]
print(names)
【元组】
元组其实跟列表差不多,也是存一组数,只不是它一旦创建,便不能再修改,所以又叫只读列表
names = ("alex","jack","eric")
它只有2个方法,一个是count,一个是index,完毕。
案例1:如何在列表中添加索引。
for i,v in enumerate(range(3,10)):
print(i,v)
0 3
1 4
2 5
3 6
4 7
5 8
6 9 Process finished with exit code 0
案例2:
#-----------readme------------
#打印省,市,县三级菜单
#按b可以返回上一级
#按quit退出
# -*- coding: UTF-8 -*-
#blog:http://www.cnblogs.com/linux-chenyang/ location = {
"北京":{
"海淀":{
"西二旗":"新浪",
"中关村":"爱奇艺"
},
"昌平":{
"回龙观":"煎饼果子",
"沙河":"老男孩"
}
},
"内蒙":{
"呼和浩特":{
"火车站":"伊利",
"汽车站":"蒙牛"
},
"巴彦淖尔":{
"渡口":"苏木井",
"协成":"大棚"
}
}
}
flag = True while flag:
for i in location:
print(i)
choice = input(">>:").strip()
if choice in location:
location_1 = location[choice]
# print(location_1)
while flag:
for k in location_1:
print(k)
choice2 = input("继续选择>>:")
if choice2 in location_1:
location_2 = location[choice][choice2]
for z in location_2:
print(z) elif choice2 == "b":
break
elif choice2 == "quit":
flag = False
break
elif choice == "quit":
flag = False
else:
print("输入错误,请重新输入.....
案例3:程序:购物车程序
需求:
- 启动程序后,让用户输入工资,然后打印商品列表
- 允许用户根据商品编号购买商品
- 用户选择商品后,检测余额是否够,够就直接扣款,不够就提醒
- 可随时退出,退出时,打印已购买商品和余额
#!/usr/bin/python
# -*- coding: UTF-8 -*-
#blog:http://www.cnblogs.com/linux-chenyang/
#
#----------------readme-------------------------
#1.启动程序后输入你的工资,然后打印商品列表。
#2.如果选择的是列表内的商品,则进行下一步,否则提示没有这个商品。
#3.如果选择的商品小于工资,则显示余额,大于工资则显示还差多少钱。
#4.选择exit退出并且显示消费的钱和余额。 product_list = [
["Iphone7",6500],
["MackBook",12000],
["Python book",60],
["Bike",300],
["coffee",30],
]
shoppint_cart = [] salary = int(input("Please youer salary:"))
while True:
for index,i in enumerate(product_list):
print("%s.\t%s\t%s" %(index,i[0],i[1])) #\t表示空格。
choice = input(">>:").strip() #strip()表示去除空格。
if choice.isdigit(): #isdigit()检测字符串是否只由数字组成。
choice = int(choice)
if choice < len(product_list) and choice >=0:
product_item = product_list[choice] #选择的商品
if salary >= product_item[1]:
salary -= product_item[1] #剩余的钱
shoppint_cart.append(product_item) #添加至购物车 print("%s已经加入到你的购物车,余额还剩%s" %(product_item[0],salary))
else:
print("对不起你的余额不足,还差",product_item[1]-salary) #商品价格减去剩余的钱就少还差多少钱
else:
print("没有这个商品!") elif choice == "exit":
total_cost = 0
print("你已经添加到购物车的东西是:")
for i in shoppint_cart:
print(i)
total_cost += i[1] #循环加购物车里的钱
print("您总共消费为",total_cost )
print("您的余额是", salary)
break else:
print("非法的输入,请选择商品序号或者退出exit")
Please youer salary:5000
0. Iphone7 6500
1. MackBook 12000
2. Python book 60
3. Bike 300
4. coffee 30
>>:2
Python book已经加入到你的购物车,余额还剩4940
0. Iphone7 6500
1. MackBook 12000
2. Python book 60
3. Bike 300
4. coffee 30
>>:3
Bike已经加入到你的购物车,余额还剩4640
0. Iphone7 6500
1. MackBook 12000
2. Python book 60
3. Bike 300
4. coffee 30
>>:4
coffee已经加入到你的购物车,余额还剩4610
0. Iphone7 6500
1. MackBook 12000
2. Python book 60
3. Bike 300
4. coffee 30
>>:3
Bike已经加入到你的购物车,余额还剩4310
0. Iphone7 6500
1. MackBook 12000
2. Python book 60
3. Bike 300
4. coffee 30
>>:exit
你已经添加到购物车的东西是:
['Python book', 60]
['Bike', 300]
['coffee', 30]
['Bike', 300]
您总共消费为 690
您的余额是 4310 Process finished with exit code 0
【字典】
字典一种key - value 的数据类型,使用就像我们上学用的字典,通过笔划、字母来查对应页的详细内容。
- dict是无序的
- key必须是唯一的,so 天生去重
- 字典的查询速度比列表快(原因:使用了hash算法,中文叫撒列,比如字典name:lijun,通过name如何快速的找到lijun,其实是先将name利用hash转换成数值,然后在利用二分查找,先排序,取一半判断是大于这个数值还是小于这个数值,小于在左边,大于在右边,然后在取半)
循环dict
#方法1
for key in info:
print(key,info[key]) #方法2
for k,v in info.items(): #会先把dict转成list,数据里大时莫用
print(k,v)
names = {
"":{"name":"chenlijun","age":22,"hobbie":"girl",},
"":"lijun",
"":"xiaoyu",
}
#search
print(names)
print(names[""])
print(names[""]["hobbie"])
print(names.get("",""))
#add
names[""] = ["zhouxingchi","","DBA"]
print(names)
#update
names[""][0] = "xingye"
print(names)
#del
print(names.pop(""))
print(names)
print(names.pop("","没有这个号码"))
del names[""]
print(names)
{'': {'age': 22, 'hobbie': 'girl', 'name': 'chenlijun'}, '': 'xiaoyu', '': 'lijun'}
{'age': 22, 'hobbie': 'girl', 'name': 'chenlijun'}
girl
87654321
{'': {'age': 22, 'hobbie': 'girl', 'name': 'chenlijun'}, '': 'xiaoyu', '': 'lijun', '': ['zhouxingchi', '', 'DBA']}
{'': {'age': 22, 'hobbie': 'girl', 'name': 'chenlijun'}, '': 'xiaoyu', '': 'lijun', '': ['xingye', '', 'DBA']}
['xingye', '', 'DBA']
{'': {'age': 22, 'hobbie': 'girl', 'name': 'chenlijun'}, '': 'xiaoyu', '': 'lijun'}
没有这个号码
{'': {'age': 22, 'hobbie': 'girl', 'name': 'chenlijun'}, '': 'xiaoyu'}
Process finished with exit code 0
案例1:高富帅版本
#-----------readme------------
#打印省,市,县三级菜单
#按b可以返回上一级
#按quit退出
# -*- coding: UTF-8 -*-
#blog:http://www.cnblogs.com/linux-chenyang/ menu = {
'北京':{
'海淀':{
'西二旗':["新浪","网易","百度"],
'上地':["爱奇艺","优酷","土豆"]
},
'昌平':{
'沙河':["老男孩","沙县小吃"],
'回龙观':["龙锦苑","兰州拉面"]
}
},
'内蒙古':{
'呼和浩特':{
'企业':["蒙牛","伊利"],
'车站':["火车站","汽车站"]
},
'巴彦淖尔':{
'地理':["草原","沙漠"],
'特色':["华莱士","番茄"]
} }
} layer = menu
p_layer = [] while True:
for k in layer:
print(k)
choice = input(">:").strip()
if len(choice) == 0:continue if choice in layer:
p_layer.append(layer)
layer = layer[choice] elif choice == "b":
if len(p_layer) > 0:
layer = p_layer.pop()
elif choice == "q":
exit()
2.字符串操作
特性:不可修改
name.capitalize() 首字母大写
name.casefold() 大写全部变小写
name.center(50,"-") 输出 '---------------------Alex Li----------------------'
name.count('lex') 统计 lex出现次数
name.encode() 将字符串编码成bytes格式
name.endswith("Li") 判断字符串是否以 Li结尾
"Alex\tLi".expandtabs(10) 输出'Alex Li', 将\t转换成多长的空格
name.find('A') 查找A,找到返回其索引, 找不到返回-1 format :
>>> msg = "my name is {}, and age is {}"
>>> msg.format("alex",22)
'my name is alex, and age is 22'
>>> msg = "my name is {1}, and age is {0}"
>>> msg.format("alex",22)
'my name is 22, and age is alex'
>>> msg = "my name is {name}, and age is {age}"
>>> msg.format(age=22,name="ale")
'my name is ale, and age is 22'
format_map
>>> msg.format_map({'name':'alex','age':22})
'my name is alex, and age is 22' msg.index('a') 返回a所在字符串的索引
'9aA'.isalnum() True ''.isdigit() 是否整数
name.isnumeric
name.isprintable
name.isspace
name.istitle
name.isupper
"|".join(['alex','jack','rain'])
'alex|jack|rain' maketrans
>>> intab = "aeiou" #This is the string having actual characters.
>>> outtab = "" #This is the string having corresponding mapping character
>>> trantab = str.maketrans(intab, outtab)
>>>
>>> str = "this is string example....wow!!!"
>>> str.translate(trantab)
'th3s 3s str3ng 2x1mpl2....w4w!!!' msg.partition('is') 输出 ('my name ', 'is', ' {name}, and age is {age}') >>> "alex li, chinese name is lijie".replace("li","LI",1)
'alex LI, chinese name is lijie' msg.swapcase 大小写互换 >>> msg.zfill(40)
'00000my name is {name}, and age is {age}' >>> n4.ljust(40,"-")
'Hello 2orld-----------------------------'
>>> n4.rjust(40,"-")
'-----------------------------Hello 2orld' >>> b="ddefdsdff_哈哈"
>>> b.isidentifier() #检测一段字符串可否被当作标志符,即是否符合变量命名规则
True
3.copy的用法
第一层的数据不会跟着变,第二层后的数据会跟着变。
names = {
"":{"name":"chenlijun","age":22},
"":"lijun",
"":"xiaoyu",
}
n2 = names.copy()
print(names)
print(n2)
names[""] = "LIJUN"
print(names)
print(n2)
names[""]["age"] = 24
print(names)
print(n2)
{'': 'xiaoyu', '': {'name': 'chenlijun', 'age': 22}, '': 'lijun'}
{'': 'xiaoyu', '': {'name': 'chenlijun', 'age': 22}, '': 'lijun'}
{'': 'xiaoyu', '': {'name': 'chenlijun', 'age': 22}, '': 'LIJUN'}
{'': 'xiaoyu', '': {'name': 'chenlijun', 'age': 22}, '': 'lijun'}
{'': 'xiaoyu', '': {'name': 'chenlijun', 'age': 24}, '': 'LIJUN'}
{'': 'xiaoyu', '': {'name': 'chenlijun', 'age': 24}, '': 'lijun'}
案例1:银行的共享账户。
credit_card = {"name":"至尊宝","acc":{"id":6210222,"balance":900}}
credit_card2 = credit_card.copy()
credit_card2["name"] = "紫霞仙子"
print(credit_card)
print(credit_card2)
credit_card["acc"]["balance"] -= 300
print(credit_card)
print(credit_card2)
credit_card2["acc"]["balance"] -= 500
print(credit_card)
print(credit_card2)
{'name': '至尊宝', 'acc': {'balance': 900, 'id': 6210222}}
{'name': '紫霞仙子', 'acc': {'balance': 900, 'id': 6210222}}
{'name': '至尊宝', 'acc': {'balance': 600, 'id': 6210222}}
{'name': '紫霞仙子', 'acc': {'balance': 600, 'id': 6210222}}
{'name': '至尊宝', 'acc': {'balance': 100, 'id': 6210222}}
{'name': '紫霞仙子', 'acc': {'balance': 100, 'id': 6210222}}
4.文件操作
对文件操作流程
- 打开文件,得到文件句柄并赋值给一个变量
- 通过句柄对文件进行操作
- 关闭文件
打开文件的模式有:
- r,只读模式(默认)。
- w,只写模式。【不可读;不存在则创建;存在则删除内容;】
- a,追加模式。【可读; 不存在则创建;存在则只追加内容;】
"+" 表示可以同时读写某个文件
- r+,可读写文件。【可读;可写;可追加】
- w+,写读
- a+,同a
"U"表示在读取时,可以将 \r \n \r\n自动转换成 \n (与 r 或 r+ 模式同使用)
- rU
- r+U
"b"表示处理二进制文件(如:FTP发送上传ISO镜像文件,linux可忽略,windows处理二进制文件时需标注)
- rb
- wb
- ab
【r,w,a的用法】
案例1:创建一个文件,并且写入内容,会在同一个目录里创建一个lyrie文件。
f = open("lyrie",mode="a",encoding="utf-8")
f.write("\nPlease input send str...")
f.write("\nPlease input send str...")
f.write("\nPlease input send str...")
f.close()

案例2:替换文件里的内容(这种方法b弊端:太吃服务器的内存)
f = open("lyrie",mode="r",encoding="utf-8")
date = f.read()
date = date.replace("input","hahahhha")
f.close()
f = open("lyrie",mode="w",encoding="utf-8")
f.write(date)
f.close()
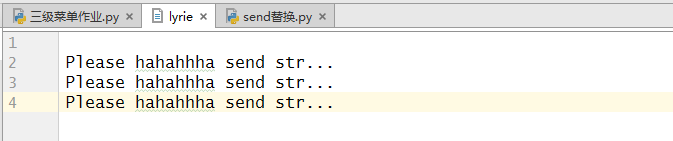
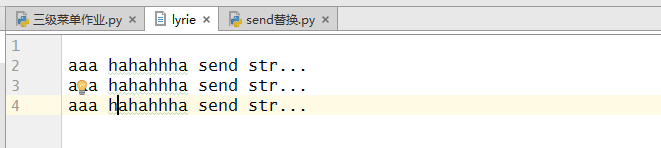
案例3:如果只修改一个字符串,可以循环一行行读,然后写到新的文件里,将原文件删除,新文件改成原文件的名字。(弊端:占用两倍硬盘空间)
import os #导入模块
f = open("lyrie",mode="r",encoding="utf-8")
f_new = open("lyrie_new",mode="w",encoding="utf-8")
for line in f:
print(line) #循环一行行读
if "Please" in line:
line = line.replace("Please","aaa")
f_new.write(line)
f.close()
f_new.close()
os.remove("lyrie")
os.rename("lyrie_new","lyrie")
【r+,w+,a+的用法】
1.r+在原因的文件追加,可读;a只能追加,可以定长修改,利用seek()的方法。
# -*- coding: UTF-8 -*-
#blog:http://www.cnblogs.com/linux-chenyang/ f = open("lyrie","r+",encoding="utf-8")
print(f.read())
f.write("--------test------")
f.close()


2.w+,清空原文件内容,在写入新的内容。
# -*- coding: UTF-8 -*-
#blog:http://www.cnblogs.com/linux-chenyang/ f = open("lyrie","w+",encoding="utf-8")
print(f.read())
f.write("--------test------")
f.close()

知识点:read()
a.读完后在读一次,发现在读不了了,说明read类似有个光标的功能,光标走到底在读就没有了。
# -*- coding: UTF-8 -*-
#blog:http://www.cnblogs.com/linux-chenyang/
f = open("lyrie","r",encoding="utf-8")
print(f.read())
print("--------------------------")
print(f.read())

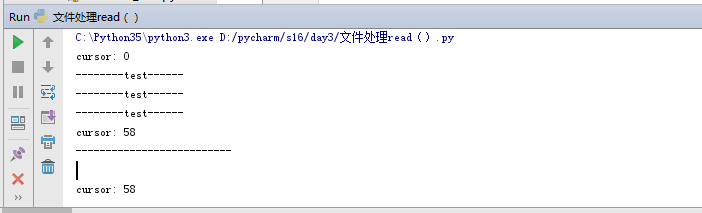
b.怎么看光标在那个位置。
# -*- coding: UTF-8 -*-
#blog:http://www.cnblogs.com/linux-chenyang/
f = open("lyrie","r",encoding="utf-8")
print('cursor:',f.tell())
print(f.read())
print('cursor:',f.tell())
print("--------------------------")
print(f.read())
print('cursor:',f.tell())
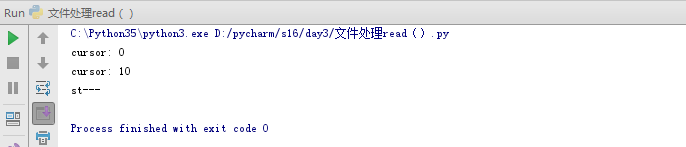
c.移动光标位置。
# -*- coding: UTF-8 -*-
#blog:http://www.cnblogs.com/linux-chenyang/
f = open("lyrie","r",encoding="utf-8")
print('cursor:',f.tell())
f.seek(10) #代表移动10个字节,不是10个字符。
print('cursor:',f.tell())
print(f.read(5)) #读的时候是字符,5个字符。
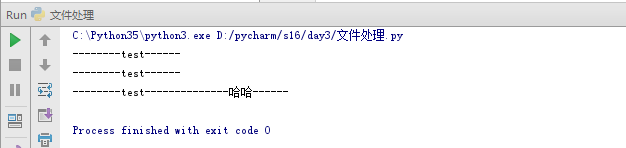
3.a+,可以追加,读。
# -*- coding: UTF-8 -*-
#blog:http://www.cnblogs.com/linux-chenyang/ f = open("lyrie","a+",encoding="utf-8")
f.write("--------哈哈------")
f.seek(0)
print(f.read())
f.close()
【rb的用法】
f = open("lyrie","rb")
print(f.read())
f.close()

知识点:import sys
# -*- coding: UTF-8 -*-
#blog:http://www.cnblogs.com/linux-chenyang/ import sys print(sys.argv) oldstr = sys.argv[1]
newstr = sys.argv[2] print(oldstr,newstr)

其他语法:
def close(self): # real signature unknown; restored from __doc__
"""
Close the file. A closed file cannot be used for further I/O operations. close() may be
called more than once without error.
"""
pass def fileno(self, *args, **kwargs): # real signature unknown
""" Return the underlying file descriptor (an integer). """
pass def isatty(self, *args, **kwargs): # real signature unknown
""" True if the file is connected to a TTY device. """
pass def read(self, size=-1): # known case of _io.FileIO.read
"""
注意,不一定能全读回来
Read at most size bytes, returned as bytes. Only makes one system call, so less data may be returned than requested.
In non-blocking mode, returns None if no data is available.
Return an empty bytes object at EOF.
"""
return "" def readable(self, *args, **kwargs): # real signature unknown
""" True if file was opened in a read mode. """
pass def readall(self, *args, **kwargs): # real signature unknown
"""
Read all data from the file, returned as bytes. In non-blocking mode, returns as much as is immediately available,
or None if no data is available. Return an empty bytes object at EOF.
"""
pass def readinto(self): # real signature unknown; restored from __doc__
""" Same as RawIOBase.readinto(). """
pass #不要用,没人知道它是干嘛用的 def seek(self, *args, **kwargs): # real signature unknown
"""
Move to new file position and return the file position. Argument offset is a byte count. Optional argument whence defaults to
SEEK_SET or 0 (offset from start of file, offset should be >= 0); other values
are SEEK_CUR or 1 (move relative to current position, positive or negative),
and SEEK_END or 2 (move relative to end of file, usually negative, although
many platforms allow seeking beyond the end of a file). Note that not all file objects are seekable.
"""
pass def seekable(self, *args, **kwargs): # real signature unknown
""" True if file supports random-access. """
pass def tell(self, *args, **kwargs): # real signature unknown
"""
Current file position. Can raise OSError for non seekable files.
"""
pass def truncate(self, *args, **kwargs): # real signature unknown
"""
Truncate the file to at most size bytes and return the truncated size. Size defaults to the current file position, as returned by tell().
The current file position is changed to the value of size.
"""
pass def writable(self, *args, **kwargs): # real signature unknown
""" True if file was opened in a write mode. """
pass def write(self, *args, **kwargs): # real signature unknown
"""
Write bytes b to file, return number written. Only makes one system call, so not all of the data may be written.
The number of bytes actually written is returned. In non-blocking mode,
returns None if the write would block.
"""
pass flush() 强制从内存中写入到硬盘,不用close,可以减少硬盘的读取操作。
Python_oldboy_自动化运维之路(三)的更多相关文章
- Python_oldboy_自动化运维之路_线程,进程,协程(十一)
本节内容: 线程 进程 协程 IO多路复用 自定义异步非阻塞的框架 线程和进程的介绍: 举个例子,拿甄嬛传举列线程和进程的关系: 总结:1.工作最小单元是线程,进程说白了就是提供资源的 2.一个应用程 ...
- Python_oldboy_自动化运维之路_socket编程(十)
链接:http://www.cnblogs.com/linhaifeng/articles/6129246.html 1.osi七层 引子: 须知一个完整的计算机系统是由硬件.操作系统.应用软件三者组 ...
- Python_oldboy_自动化运维之路_面向对象2(十)
本节内容: 面向对象程序设计的由来 什么是面向对象的程序设计及为什么要有它 类和对象 继承与派生 多的态与多态性 封装 静态方法和类方法 面向对象的软件开发 反射 类的特殊成员方法 异常处理 1.面向 ...
- Python_oldboy_自动化运维之路(八)
本节内容: 列表生成式,迭代器,生成器 Json & pickle 数据序列化 软件目录结构规范 作业:ATM项目开发 1.列表生成式,迭代器,生成器 1.列表生成式 #[列表生成] #1.列 ...
- Python_oldboy_自动化运维之路_函数,装饰器,模块,包(六)
本节内容 上节内容回顾(函数) 装饰器 模块 包 1.上节内容回顾(函数) 函数 1.为什么要用函数? 使用函数之模块化程序设计,定义一个函数就相当于定义了一个工具,需要用的话直接拿过来调用.不使用模 ...
- Python_oldboy_自动化运维之路_全栈考试(五)
1.执行 Python 脚本的两种方式 [root@localhost tmp]# cat a.py #!/usr/bin/python # -*- coding: UTF-8 -*- print & ...
- Python_oldboy_自动化运维之路(二)
本节内容: 1.pycharm工具的使用 2.进制运算 3.表达式if ...else语句 4.表达式for 循环 5.break and continue 6.表达式while 循环 1.pycha ...
- Python_oldboy_自动化运维之路(一)
python简介: Python 是一个高层次的结合了解释性.编译性.互动性和面向对象的脚本语言. Python 的设计具有很强的可读性,相比其他语言经常使用英文关键字,其他语言的一些标点符号,它具有 ...
- Python_oldboy_自动化运维之路_paramiko,mysql(十二)
本节内容: paramiko mysql 1.paramiko http://www.cnblogs.com/wupeiqi/articles/5095821.html paramiko是一个模块,s ...
随机推荐
- 基本数据结构 —— 堆以及堆排序(C++实现)
目录 什么是堆 堆的存储 堆的操作 结构体定义 判断是否为空 往堆中插入元素 从堆中删除元素 取出堆中最大的元素 堆排序 测试代码 例题 参考资料 什么是堆 堆(英语:heap)是计算机科学中一类特殊 ...
- 关于Powershell对抗安全软件(转)
Windows PowerShell的强大,并且内置,在渗透过程中,也让渗透变得更加有趣.而安全软件的对抗查杀也逐渐开始针对powershell的一切行为.在https://technet.micro ...
- 控制对象的创建方式(禁止创建栈对象or堆对象)和创建的数量
我们知道,C++将内存划分为三个逻辑区域:堆.栈和静态存储区.既然如此,我称位于它们之中的对象分别为堆对象,栈对象以及静态对象.通常情况下,对象创建在堆上还是在栈上,创建多少个,这都是没有限制的.但是 ...
- CJOJ 2482 【POI2000】促销活动(STL优先队列,大根堆,小根堆)
CJOJ 2482 [POI2000]促销活动(STL优先队列,大根堆,小根堆) Description 促销活动遵守以下规则: 一个消费者 -- 想参加促销活动的消费者,在账单下记下他自己所付的费用 ...
- Chapter 6(树)
1.树的储存方式 //****************双亲表示法************************ #define Max_TREE_SIZE 100 typedef int TElem ...
- 【Asp.net入门15】第一个Asp.net应用程序-输入验证
前言 所谓输入验证,顾名思义就是验证用户输入符不符合要求.前面我们已经完成了这个简单的应用程序,但还有一个问题需要解决:用户可以在Default.aspx窗体中 提交任何数据,甚至可以提交根本不包含任 ...
- 网络优化之net.ipv4.tcp_tw_recycle参数
不要在linux上启用net.ipv4.tcp_tw_recycle参数 2015/07/27 CFC4N 本文为翻译英文BLOG<Coping with the TCP TIME-WAIT ...
- Azure 上SQL Database(PaaS)Time Zone时区问题处理(进阶篇)
通常ISV在面对本地客户时对时间相关的处理,一般都时区信息都是不敏感的.但是现在云的世界里为了让大家把时间处理的方式统一起来,云上的服务都是以UTC时间为准的,现在如果作为一个ISV来说就算你面对的客 ...
- P2042 [NOI2005]维护数列 && Splay区间操作(四)
到这里 \(A\) 了这题, \(Splay\) 就能算入好门了吧. 今天是个特殊的日子, \(NOI\) 出成绩, 大佬 \(Cu\) 不敢相信这一切这么快, 一下子机房就只剩我和 \(zrs\) ...
- HDU 1525 类Bash博弈
给两数a,b,大的数b = b - a*k,a*k为不大于b的数,重复过程,直到一个数为0时,此时当前操作人胜. 可以发现如果每次b=b%a,那么GCD的步数决定了先手后手谁胜,而每次GCD的一步过程 ...