Hadoop基础-HDFS分布式文件系统的存储
Hadoop基础-HDFS分布式文件系统的存储
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.HDFS数据块
1>.磁盘中的数据块
每个磁盘都有默认的数据块大小,这个磁盘进行数据读/写的最小单位,构建于单个磁盘之上的上文件系统通过磁盘来管理该文件中的块,该文件系统块的大小可以是磁盘块的整数倍。文件系统块一般为几千字节,而磁盘快一般为512字节。这个信息(文件系统块大小)对于需要读/写文件的文件系统用户来说是透明的。尽管如此,系统仍然提供了一些工具(如df和fsck)来维护系文件系统,由它们对文件系统中的块进行操作。对了,windows文件存放的基本单位是:簇(默认是4k。即4096字节)。
2>.HDFS的数据块
HDFS同样也有块(block)的概念,但是大得多,默认为128MB(既然我这里说默认,那自然是可以这个默认属性的哟!)。与单一磁盘上的文件系统相似,HDFS上的文件也被划分为块大小的多个分块(chunk),作为独立的存储单元。但与面向单一磁盘的文件系统不同的是,HDFS中小于一个块大小的文件不会占据整个块的空间(例如,当一个1MB的文件存储在一个128MB的块中时,文件只使用1MB的磁盘空间,而不是128MB)。
3>.为什么HDFS中块默认是128M
HDFS的块比磁盘的块大,其目的是为了最小化寻址开销。如果块足够大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间。因而,传输一个由多个块组成的大文件的时间取决于磁盘传输速率。
我们来做一个运算,如果寻址时间约为10ms,机械硬盘传输速率(磁盘速率)为100MB/s,为了使寻址时间仅占传输时间的1%,我们要将块大小设置约为100MB,Hadoop2.x的版本默认的块大小实际为128MB,初学者的小伙伴会很费解这个128是怎么来的,以及在Hadoop1.x的版本,默认大小为64MB。一开始我也很懵逼,但是根据这两个数字大家是否想到了二进制?在Java中一个int类型的它需要占用4个字节,每一个字节有8个比特位,而一个字节每个比特位代表的数据是不同的,一个字节从右往左大小依次是:“1,2,4,8,16,32,64,128,256,512,1024,.....”等等。考虑有些笔记本的硬盘传输速度在60MB/s~90MB/之间。Hadoop1.x那些大佬们就取一个好记的数组,也就是我们上面说的64MB/s;随着技术的提升,我们机械硬盘速率在100MB/s~190MB/s,Hadoop2.x那些大佬们就取一个好记的数组,也就是我们上面说的128MB/s;但是很多情况下HDFS安装时使用更大的块。以后随着新一代磁盘驱动器传输速率的提示,块的大小会被设置的更大。比如目前主流固态硬盘的速率在450/MB~550/MB之间,估计也没有哪家企业能把机械硬盘都干掉,而是采用固态硬盘来存取数据,随着技术的提升,将来硬盘速度上的提升也是一个必然趋势。我也大胆猜测,当机械硬盘的普遍的传输速度提升到300MB/s左右时,Hadoop官方的大佬们又会再一次修改目前的128MB大小,很有可能默认大小为256MB/s哟!
4>.对分布式文件系统(HDFS)中的块进行抽象的好处
第一个最明显的好处是,一个文件的大小可以大于网络中任意一个磁盘的容量。文件的所有块并不需要存储在同一个磁盘上,因此他们可以利用集群上的任意一个磁盘进行存储。事实上,尽管不常见,但对于整个HDFS集群而言,也可以仅存储一个文件,该文件的块沾满集群中所有的磁盘。
第二个好处是,使用抽象块而非整个文件作为存储单元,大大简化了存储子系统的设计。简化是所有系统的目标,但是这对于故障种类繁多的分布式系统来说尤为重要。将存储子系统的处理对象设置为块,可以简化存储管理(由于块的大小是固定的,因此计算单个磁盘能存储多少个块就相对容易)。同时也消除了对元数据的顾虑(块只是要存储的大块数据,而文件的元数据,如权限信息,并不需要与块一同存储,这样一来,其他系统就可以单独管理这个元数据)。
第三个好处是,块还非常社会用于数据备份进而提供数据容错能力和提高可用性。将每个块复制到少数几个物理上互相独立的服务器上(默认为3个),可以确保在块,磁盘或机器发生故障后数据不会丢失。如果发现一个块不可用,系统会自动从其他地方读取另一个复本,而这个过程对用户是透明的。一个因损坏机器故障而丢失的块可以从其他候选地点复制到另一台可以正常运行的机器上,以保证复本的数量回到正常水平,同样,有些应用程序可能选择为一些常用的文件块设置更高的复本数量进而分散集群的读取负载。
第四个好处是,与磁盘文件系统相似,HDFS中fsck指令可以显示块信息,例如,执行命令“hdfs fsck / -files -blocks”将会列出文件系统中各个文件由哪些块组成
二.Hadoop的文件存储方式
1>.上传文件到服务器
服务端上传文件:
[yinzhengjie@s101 ~]$ ll -h
total 382M
drwxrwxr-x. yinzhengjie yinzhengjie May : hadoop
drwxr-xr-x. yinzhengjie yinzhengjie .0K Aug hadoop-2.7.
-rw-rw-r--. yinzhengjie yinzhengjie 205M Aug hadoop-2.7..tar.gz
-rw-rw-r--. yinzhengjie yinzhengjie 177M May jdk-8u131-linux-x64.tar.gz
-rwxrwxr-x. yinzhengjie yinzhengjie May : xcall.sh
-rwxrwxr-x. yinzhengjie yinzhengjie May : xrsync.sh
[yinzhengjie@s101 ~]$
[yinzhengjie@s101 ~]$ hdfs dfs -put xcall.sh /
[yinzhengjie@s101 ~]$ hdfs dfs -put xcall.sh hadoop-2.7..tar.gz /
[yinzhengjie@s101 ~]$ hdfs dfs -ls /
Found items
-rw-r--r-- yinzhengjie supergroup -- : /hadoop-2.7..tar.gz
-rw-r--r-- yinzhengjie supergroup -- : /xcall.sh
[yinzhengjie@s101 ~]$
客户端查看HDFS上实际存储的文件:(从图形界面中可以体验出图形的上传过程)
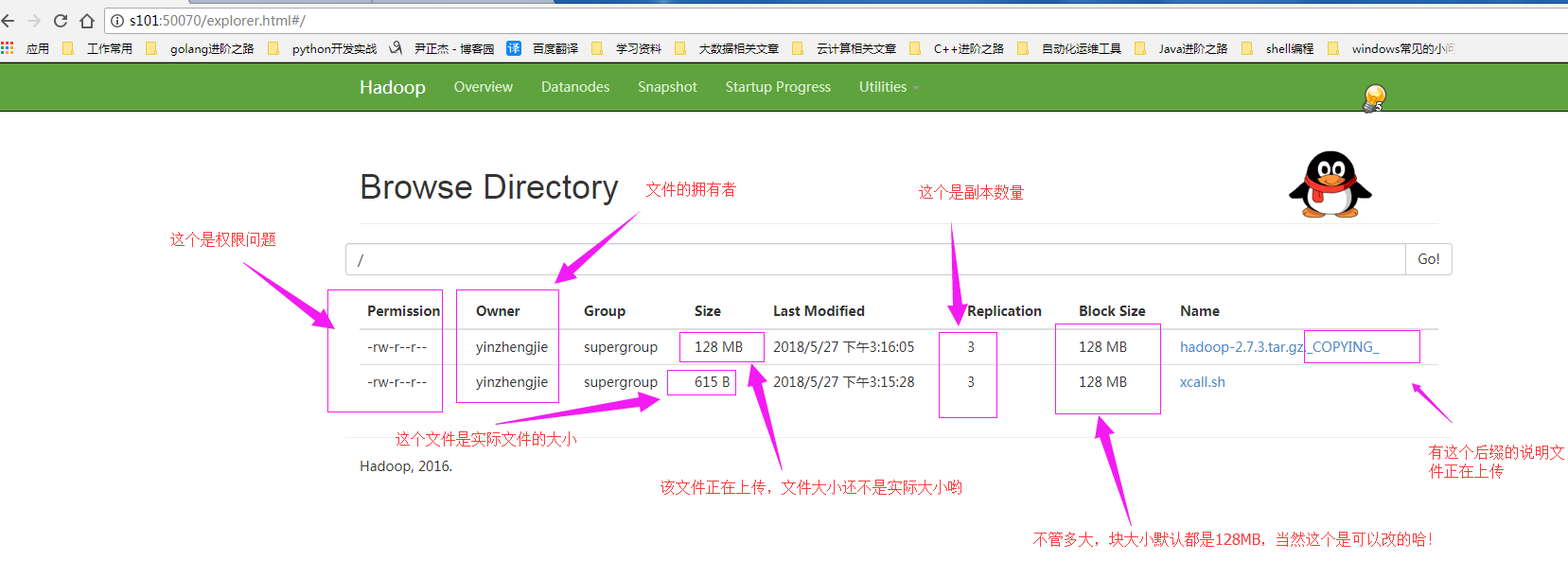
客户端查看上传成功的文件(这个时候我们可以看到上传完后的文件是没有“COPYING”后缀的文件啦!)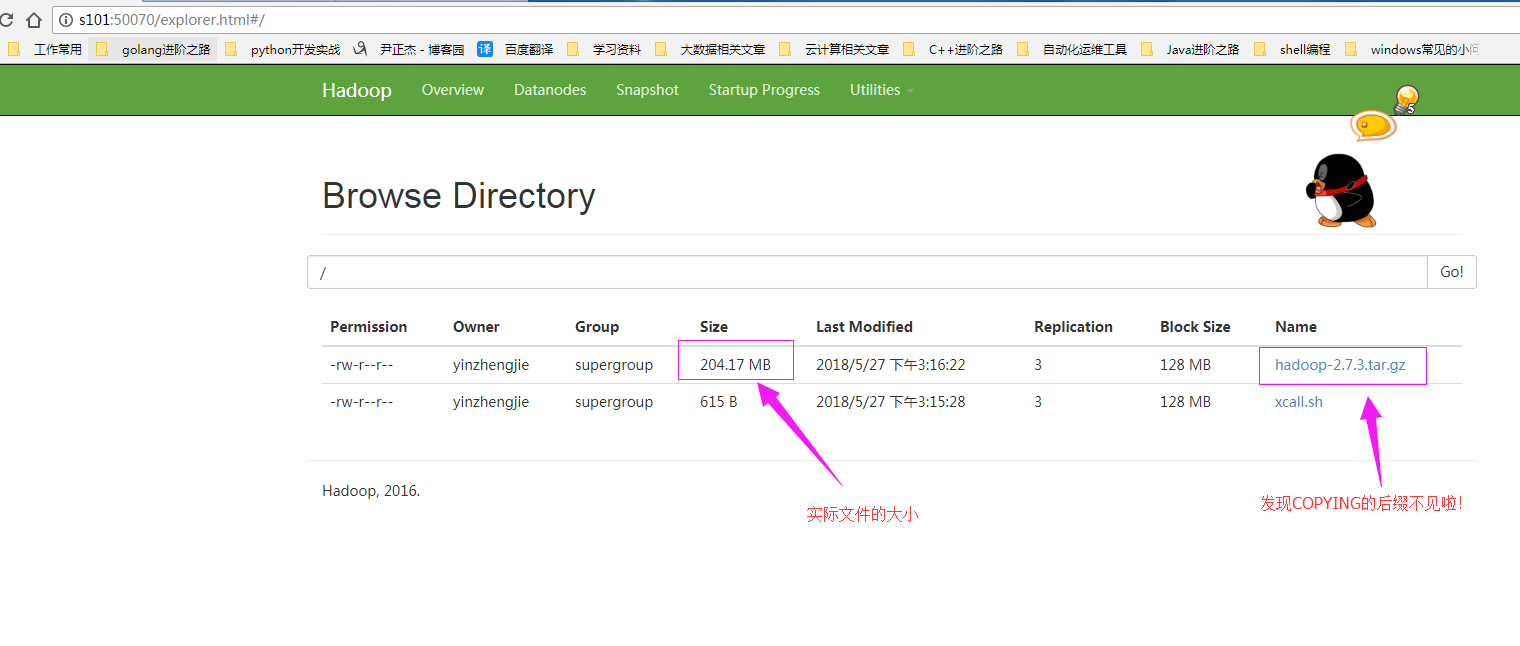
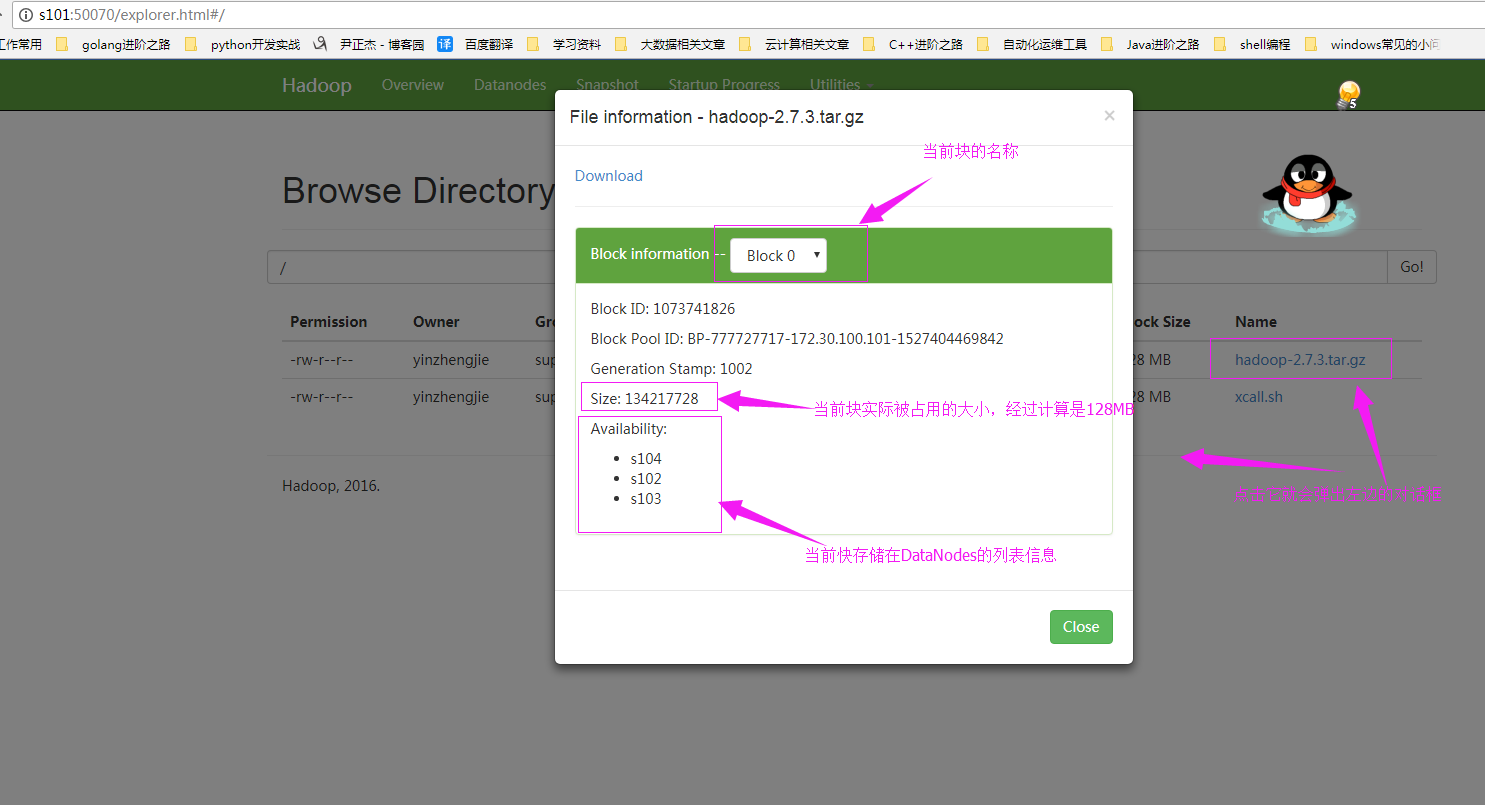
2>.查看存储的块信息
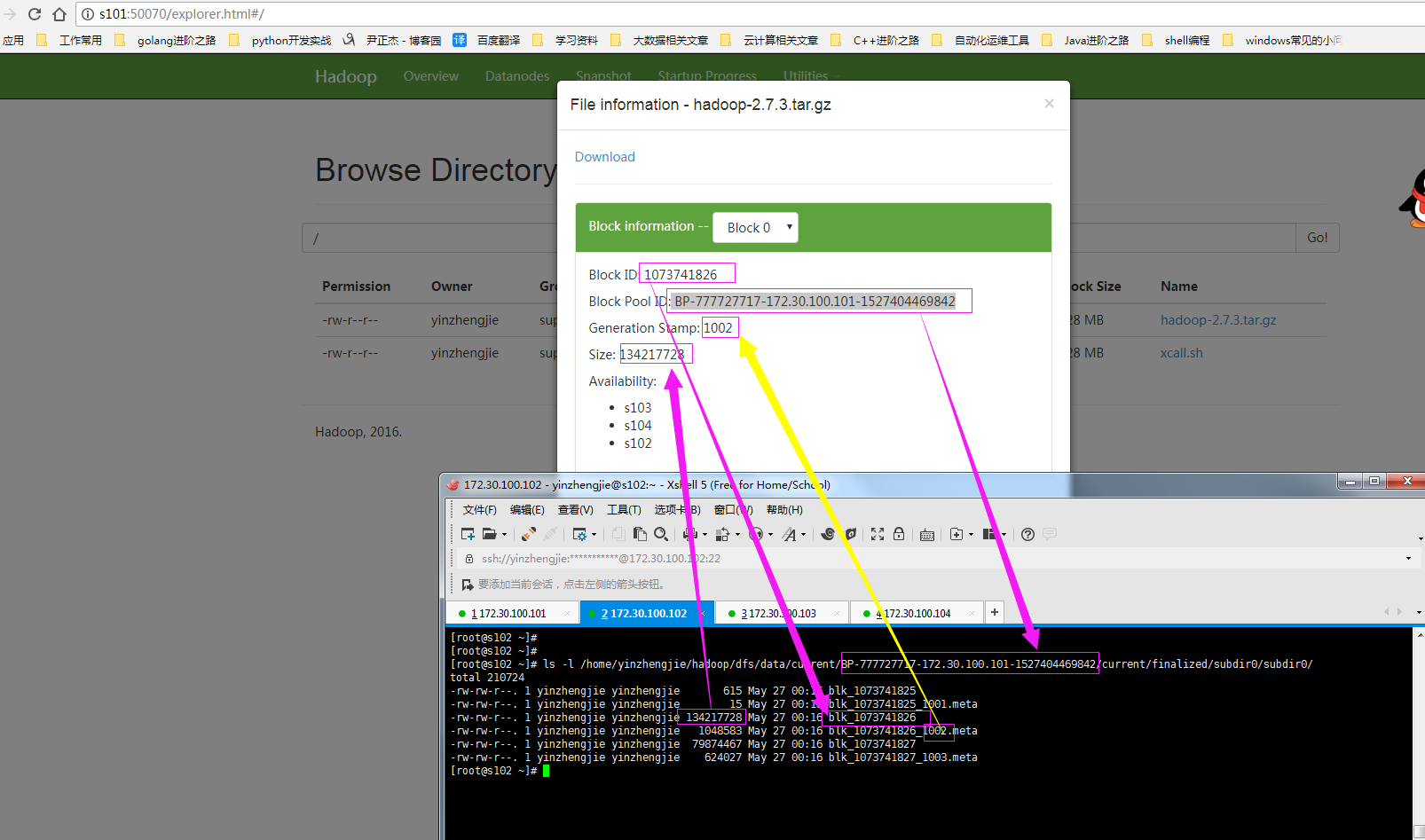
查看“hadoop-2.7.3.tar.gz”实际存储的块信息,下图为“Block 0”的信息
查看“hadoop-2.7.3.tar.gz”实际存储的块信息,下图为“Block 1”的信息
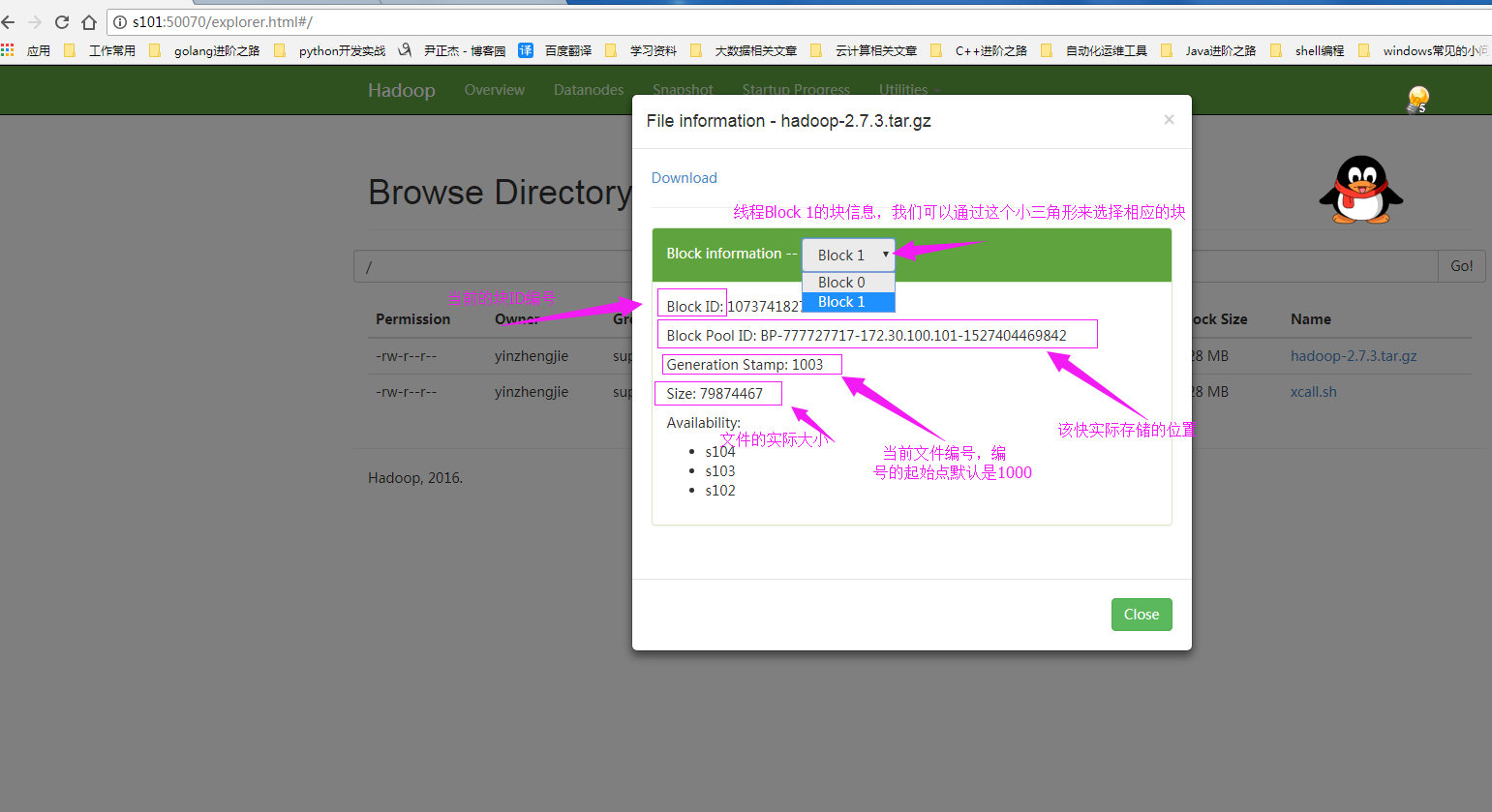
你可能好奇上面两幅图的数据在DataNode上是如何存储的,其实后台的数据存储是这样的:
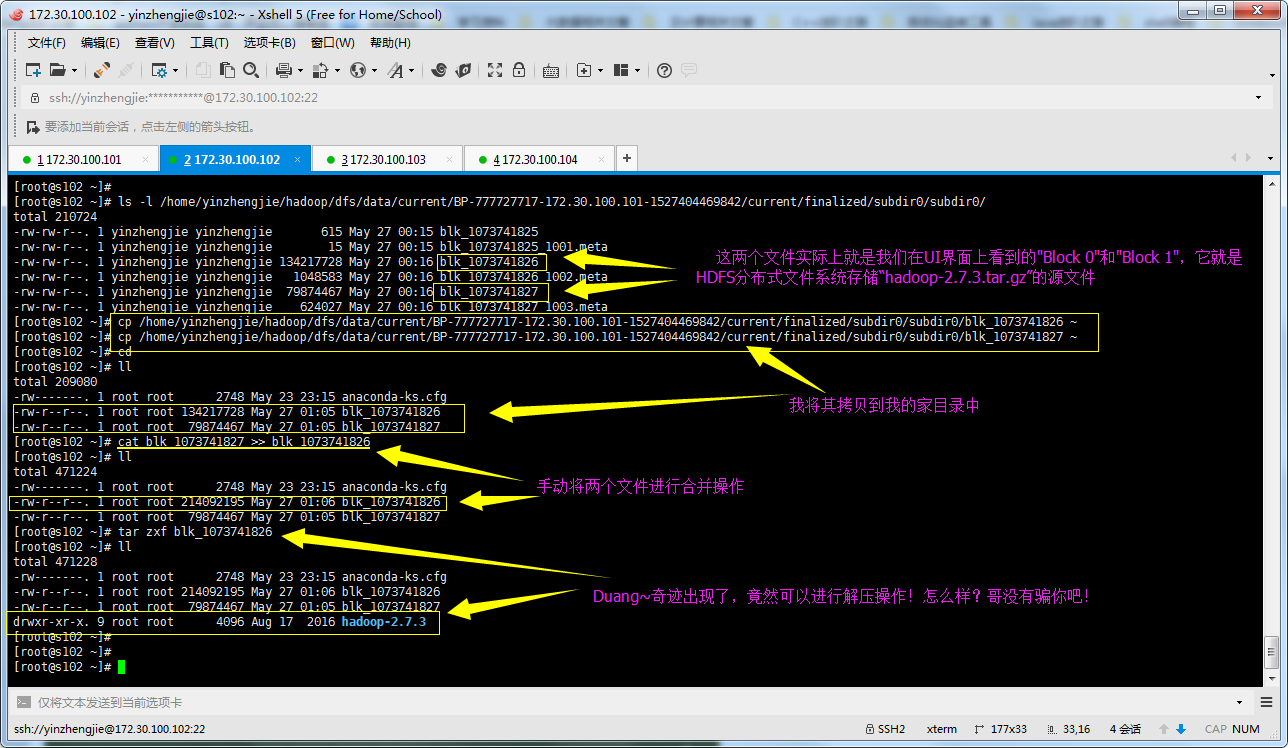
看到以上的内容你对我说的话是不是还是半信半疑,别着急的啊,看我的杀手锏,我们将HDFS存储的源文件拿出来,看是否能够正常解压操作,操作如下:
三.知识拔高
如果你是运维看到上面的两个知识点估计对你来说是小菜一碟,如果你是会Java编程的运维的话,那么上传和下载以及修改文件内容的方式都可以通过Hadoop提供的JAVA相关API实现正删改查,详情请参考:https://www.cnblogs.com/yinzhengjie/p/9093850.html。当然,用shell或是Python,C++等编程语言也可以实现增删改查,但是不建议你用他们,因为Hadoop就是用Java语言写的。用Java对Hadoop编程的话自然是再好不过啦!
当然不用Hadoop提供的API照样是可以取到HDFS文件系统的数据的哟,直接用Java自带的包就可以轻松实现,代码如下:(以下代码只是实现了读取功能)
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E8%BF%9B%E9%98%B6%E4%B9%8B%E8%B7%AF/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.day01; import org.apache.hadoop.fs.FsUrlStreamHandlerFactory;
import java.io.InputStream;
import java.net.URL;
import java.net.URLConnection; public class Demo { //通过URLStreamHandler 实例以标准输出方式显示Hadoop 文件系统的文件
static {
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
} public static void main(String[] args) throws Exception{
select();
} //读取htfs文件
private static void select() throws Exception {
//定义HDFS文件系统的文件路径
URL url = new URL("hdfs://s101:8020/xcall.sh");
//根据我们上面定义的url去连接这个地址,返回的是一个URLConnection对象。
URLConnection conn = url.openConnection();
//通过conn对象可以回去一个InputStream流对象
InputStream inputStream = conn.getInputStream();
//接下来就读取文件内容,由于我文件并不是很大,就将缓存大小设置为inputStream的长度(即inputStream.available())。
byte[] buf = new byte[inputStream.available()];
//将数据一次性读取出来,再次强调,如果你文件较大建议使用while循环的方式读取!
int read = inputStream.read(buf);
//释放资源
inputStream.close();
String res = new String(buf);
System.out.println(res);
}
} /*
以上代码执行结果如下:
#!/bin/bash
#@author :yinzhengjie
#blog:http://www.cnblogs.com/yinzhengjie
#EMAIL:y1053419035@qq.com #判断用户是否传参
if [ $# -lt 1 ];then
echo "请输入参数"
exit
fi #获取用户输入的命令
cmd=$@ for (( i=101;i<=104;i++ ))
do
#使终端变绿色
tput setaf 2
echo ============= s$i $cmd ============
#使终端变回原来的颜色,即白灰色
tput setaf 7
#远程执行命令
ssh s$i $cmd
#判断命令是否执行成功
if [ $? == 0 ];then
echo "命令执行成功"
fi
done */
Hadoop基础-HDFS分布式文件系统的存储的更多相关文章
- 【史上最全】Hadoop 核心 - HDFS 分布式文件系统详解(上万字建议收藏)
1. HDFS概述 Hadoop 分布式系统框架中,首要的基础功能就是文件系统,在 Hadoop 中使用 FileSystem 这个抽象类来表示我们的文件系统,这个抽象类下面有很多子实现类,究竟使用哪 ...
- 大数据基础总结---HDFS分布式文件系统
HDFS分布式文件系统 文件系统的基本概述 文件系统定义:文件系统是一种存储和组织计算机数据的方法,它使得对其访问和查找变得容易. 文件名:在文件系统中,文件名是用于定位存储位置. 元数据(Metad ...
- Hadoop基础-HDFS递归列出文件系统-FileStatus与listFiles两种方法
Hadoop基础-HDFS递归列出文件系统-FileStatus与listFiles两种方法 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. fs.listFiles方法,返回Loc ...
- 我理解中的Hadoop HDFS分布式文件系统
一,什么是分布式文件系统,分布式文件系统能干什么 在学习一个文件系统时,首先我先想到的是,学习它能为我们提供什么样的服务,它的价值在哪里,为什么要去学它.以这样的方式去理解它之后在日后的深入学习中才能 ...
- Hadoop HDFS分布式文件系统 常用命令汇总
引言:我们维护hadoop系统的时候,必不可少需要对HDFS分布式文件系统做操作,例如拷贝一个文件/目录,查看HDFS文件系统目录下的内容,删除HDFS文件系统中的内容(文件/目录),还有HDFS管理 ...
- Hadoop基础-Hdfs各个组件的运行原理介绍
Hadoop基础-Hdfs各个组件的运行原理介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.NameNode工作原理(默认端口号:50070) 1>.什么是NameN ...
- Hadoop基础-HDFS的读取与写入过程剖析
Hadoop基础-HDFS的读取与写入过程剖析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客会简要介绍hadoop的写入过程,并不会设计到源码,我会用图和文字来描述hdf ...
- Hadoop基础-HDFS的API实现增删改查
Hadoop基础-HDFS的API实现增删改查 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客开发IDE使用的是Idea,如果没有安装Idea软件的可以去下载安装,如何安装 ...
- 1、HDFS分布式文件系统
1.HDFS分布式文件系统 分布式存储 分布式计算 2.hadoop hadoop含有四个模块,分别是 common. hdfs和yarn. common 公共模块. HDFS hadoop dist ...
随机推荐
- 调研ANDRIOD平台的开发环境的发展演变
在同学的推荐下,我选用学习eclipse这个软件,参考了这个网址的教程开始了一步一步的搭建之路. http://jingyan.baidu.com/article/bea41d437a41b6b4c5 ...
- vmware_vcenter_api
VMware Vcenter_API 介绍 本文主要通过调用Vcenter_API,获取其中的数据中心,集群,主机,网络,存储,虚拟机信息. 开发语言 python 使用官方sdk pyvmomi 文 ...
- Pytorch相关内容
---恢复内容开始--- Pytorch中文官方文档:https://pytorch-cn.readthedocs.io/zh/latest/package_references/torch-nn P ...
- AWS上的实例无法ping通的解决方案
首先Ping只是向服务器发送ICMP的数据包,如果在服务器的防火墙没有允许ICMP协议的数据包的话,那么即使服务器正常运行,那也是ping不同的. 对于亚马逊云服务器,首先我们要确保实例绑定的安全组允 ...
- 蜗牛慢慢爬 LeetCode 6. ZigZag Conversion [Difficulty: Medium]
题目 The string "PAYPALISHIRING" is written in a zigzag pattern on a given number of rows li ...
- Mysql Group Replication 简介及单主模式组复制配置【转】
一 Mysql Group Replication简介 Mysql Group Replication(MGR)是一个全新的高可用和高扩张的MySQL集群服务. 高一致性,基于原生复制及p ...
- scrapy学习笔记(三):使用item与pipeline保存数据
scrapy下使用item才是正经方法.在item中定义需要保存的内容,然后在pipeline处理item,爬虫流程就成了这样: 抓取 --> 按item规则收集需要数据 -->使用pip ...
- apache +PHP多版本 切换的问题
在开发中切换php版本的时候出错 经过2小时的日子排查终于找到是因为切换版本后加载的php7ts.dll模块还是原来版本的,因此保pid file 错误 解决方法 PHPIniDir "H: ...
- SQLSERVER 的资源限制
https://docs.microsoft.com/en-us/sql/sql-server/maximum-capacity-specifications-for-sql-server?view= ...
- keydown和KeyPress事件有何不同
KEYPRESSWhen a windowed control receives a key-press message (WM_CHAR) from Windows, its message han ...