Kafka副本同步机制
Kafka副本
Kafka中主题的每个Partition有一个预写式日志文件,每个Partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到Partition中,Partition中的每个消息都有一个连续的序列号叫做offset,确定它在分区日志中唯一的位置

Kafka的每个topic的partition有N个副本,其中N是topic的复制因子。Kafka通过多副本机制实现故障自动转移,当Kafka集群中一个Broker实现情况下仍然保证服务可用。在Kafka中发生复制时确保partition的预写式日志有序地写到其他节点上。N个replicas中,其中一个replica为leader,其他都为follower,leader处理partition的所有读写请求,与此同时,follower会被动定期地去复制leader上的数据。

Kafka必须提供数据复制算法,保证如果leader发生故障或挂掉,一个新leader被选举并接收客户端的消息成功写入。Kafka确保从同步副本列表中选举一个副本为leader,或者换句话说,follower追赶leader数据。leader负责维护和跟踪同步副本列表中所有follower滞后状态。当生产者发送一条消息到Broker,leader写入消息并复制到所有follower。消息提交之后才被成功复制到所有的同步副本。消息复制延迟受最慢的follower限制,重要的是快速检测慢副本,如果follower”落后”太多或者失效,leader将会把它从replicas从同步副本列表移除。
partition的follower追上leader含义
Kafka中每个partition的follower没有“赶上”leader的日志可能会从同步副本列表中移除。下面用一个例子解释一下“追赶”到底是什么意思。请看一个例子:主题名称为foo 1 partition 3 replicas。假如partition的replication分布在Brokers 1、2和3上,并且Broker 3消息已经成功提交。同步副本列表中1为leader、2和3为follower。假设replica.lag.max.messages设置为4,表明只要follower落后leader不超过3,就不会从同步副本列表中移除。replica.lag.time.max设置为500 ms,表明只要follower向leader发送请求时间间隔不超过500 ms,就不会被标记为死亡,也不会从同步副本列中移除。

下面看看,生产者发送下一条消息写入leader,与此同时follower Broker 3 GC暂停,如下图所示:
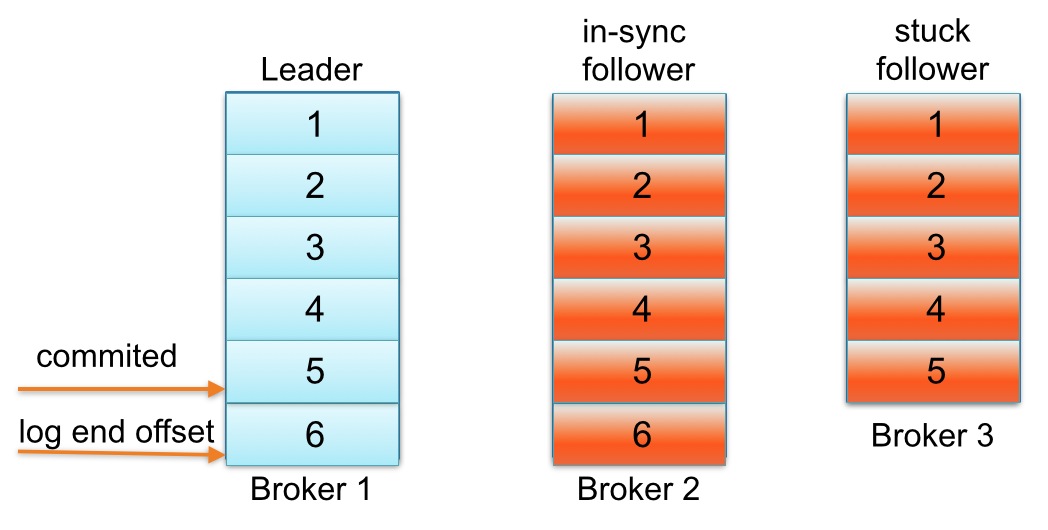
直到follower Broker 3从同步副本列表中移除或追赶上leader log end offset,最新的消息才会认为提交。注意,因为follower Broker 3小于replica.lag.max.messages= 4落后于leader Broker 1,Kafka不会从同步副本列表中移除。在这种情况下,这意味着follower Broker 3需要迎头追赶上知道offset = 6,如果是,那么它完全“赶上” leader Broker 1 log end offset。让我们假设代理3出来的GC暂停在100 ms和追赶上领袖的日志结束偏移量。在这种状态下,下面partition日志会看起来像这样

一个副本可以不同步Leader有如下几个原因
- 慢副本:在一定周期时间内follower不能追赶上leader。最常见的原因之一是I / O瓶颈导致follower追加复制消息速度慢于从leader拉取速度
- 卡住副本:在一定周期时间内follower停止从leader拉取请求。follower replica卡住了是由于GC暂停或follower失效或死亡。
- 新启动副本:当用户给主题增加副本因子时,新的follower不在同步副本列表中,直到他们完全赶上了leader日志。
一个partition的follower落后于leader足够多时,被认为不在同步副本列表或处于滞后状态。在Kafka-0.8.2.x中,副本滞后判断依据是副本落后于leader最大消息数量(replica.lag.max.messages)或replicas响应partition leader的最长等待时间(replica.lag.time.max.ms)。前者是用来检测缓慢的副本,而后者是用来检测失效或死亡的副本
如何确定副本是滞后的?
这个模型检测不同步卡住副本列表工作下所有情况都适用。它追踪follower replica时间内没有向leader发送拉取请求,表明它已经死了。另一方面,如果均匀流量模式情况下,为一个主题或多个主题设置这些参数检测模型不同步慢副本列表消息的数量会工作很好,但我们发现生产环境中它不扩展到所有主题各种工作负载。
接着上面的例子,如果主题foo获取数据速率2 msg/sec,leader单次批量接收一般不会超过3条消息,然后你知道主题参数replica.lag.max.messages设置为4。为什么?因为follower replica从leader复制消息前,已经有大批量消息写leader,follower replica落后于leader不超过3条消息 。另一方面,如果主题foo的follower replica初始落后于leader持续超过3消息,leader会从同步副本列表中移除慢副本,避免消息写延迟增加。
这本质上是replica.lag.max.messages的目标。能够检测follower与leader不一致且从同步副本列表移除。然而,主题在流量高峰期发送了一批消息(4条消息),等于replica.lag.max.messages = 4配置值。在那一瞬间,2个follower replica将被认为是”out-of-sync”并且leader会从同步副本列表中移除。

2个follower replica都是活着,下次拉取请求他们会赶上leader log end offset并重新加入同步副本列表。重复相同的过程,如果生产者继续发送相对一批较大消息到leader。这种情况演示了当follower replica频繁在从同步副本列表移除和重新加入同步副本列表之间来回切换时,不必要触发虚假警报。
副本配置规则
我们认为真正重要的事情是检测卡或慢副本,这段时间follower replica是“out-of-sync”落后于leader。在服务端现在只有一个参数需要配置replica.lag.time.max.ms。这个参数解释replicas响应partition leader的最长等待时间。检测卡住或失败副本的探测——如果一个replica失败导致发送拉取请求时间间隔超过replica.lag.time.max.ms。Kafka会认为此replica已经死亡会从同步副本列表从移除。检测慢副本机制发生了变化——如果一个replica开始落后leader超过replica.lag.time.max.ms。Kafka会认为太缓慢并且会从同步副本列表中移除。除非replica请求leader时间间隔大于replica.lag.time.max.ms,因此即使leader使流量激增和大批量写消息。Kafka也不会从同步副本列表从移除该副本。
Kafka副本同步机制的更多相关文章
- Kafka 0.8 副本同步机制理解
Kafka的普及在很大程度上归功于它的设计和操作简单,如何自动调优Kafka副本的工作,挑战之一:如何避免follower进入和退出同步副本列表(即ISR).如果某些topic的部分partition ...
- kafka 副本同步细节
图片来源:咕泡学院
- 图文了解 Kafka 的副本复制机制
让分布式系统的操作变得简单,在某种程度上是一种艺术,通常这种实现都是从大量的实践中总结得到的.Apache Kafka 的受欢迎程度在很大程度上归功于其设计和操作简单性.随着社区添加更多功能,开发者们 ...
- 深入理解 Kafka 副本机制
一.Kafka集群 二.副本机制 2.1 分区和副本 2.2 ISR机制 2.3 不完全的首领选举 2.4 最少同步副本 ...
- Kafka 学习之路(五)—— 深入理解Kafka副本机制
一.Kafka集群 Kafka使用Zookeeper来维护集群成员(brokers)的信息.每个broker都有一个唯一标识broker.id,用于标识自己在集群中的身份,可以在配置文件server. ...
- Kafka 系列(五)—— 深入理解 Kafka 副本机制
一.Kafka集群 Kafka 使用 Zookeeper 来维护集群成员 (brokers) 的信息.每个 broker 都有一个唯一标识 broker.id,用于标识自己在集群中的身份,可以在配置文 ...
- Kafka——副本(Replica)机制
副本定义 Kafka 是有主题概念的,而每个主题又进一步划分成若干个分区.副本的概念实际上是在分区层级下定义的,每个分区配置有若干个副本. 所谓副本(Replica),本质就是一个只能追加写消息的提交 ...
- Kafka副本管理—— 为何去掉replica.lag.max.messages参数
今天查看Kafka 0.10.0的官方文档,发现了这样一句话:Configuration parameter replica.lag.max.messages was removed. Partiti ...
- Kafka— —副本(均衡负载)
创建一个副本数为3的topic Now create a new topic with a replication factor of three: > bin/kafka-topics.sh ...
随机推荐
- 创建WRAPPER时, SQL20076N 未对指定的操作启用数据库的实例。
您可以通过运行DB2 UPDATE DBM CFG USING FEDERATED YES来设置这个参数.修改这个参数后,必须重新启动实例才会生效(DB2STOP/DB2START).所以你会出现你的 ...
- python函数、装饰器、迭代器、生成器
目录: 函数补充进阶 函数对象 函数的嵌套 名称空间与作用域 闭包函数 函数之装饰器 函数之迭代器 函数之生成器 内置函数 一.函数补充进阶 1.函数对象: 函数是第一类对象,即函数可以当作数据传递 ...
- 44 The shopping psychology 购物心理
The shopping psychology 购物心理 ①People can be addicted to different things ---e. g.,alcohol, drugs, ce ...
- python私有公有属性
python中,类内方法外的变量叫属性,类内方法内的变量叫字段.他们的私有公有访问方法类似. class C: __name="私有属性" def func(self): prin ...
- IntelliJ IDEA 2017版 导入项目项目名称为红色
1.导入的项目全部是红色的,原因是版本控制问题,所以修改如下:(File--->settings) 2.找到如图位置的字样,选中当前项目,选择铅笔位置 选择铅笔 弹出对话框(默认选择的是proj ...
- MySQL】存储过程、游标、循环简单实例
create procedure my_procedure() -- 创建存储过程 begin -- 开始存储过程 declare my_id varchar(32); -- 自定义变量1 decla ...
- 玩转git分支
搞个代码的管理工具,居然不弄上分支啥的东西.这简直太low了.尤其是在使用了传说中得很牛X的Git的时候,尤其显得low.拿着青龙偃月刀当烧火棍子使,关公知道了还不重反人间教育你!? 远程分支 要说分 ...
- 计算服务器的pv量算法
如何计算服务器能够承受多大的pv? 你想建设一个能承受500万PV/每天的网站吗? 500万PV是什么概念?服务器每秒要处理多少个请求才能应对?如果计算呢? PV是什么: PV是page view ...
- PAT甲 1012. The Best Rank (25) 2016-09-09 23:09 28人阅读 评论(0) 收藏
1012. The Best Rank (25) 时间限制 400 ms 内存限制 65536 kB 代码长度限制 16000 B 判题程序 Standard 作者 CHEN, Yue To eval ...
- AOT和JIT以及混合编译的区别、优劣
AOT,JIT是什么? JIT,即Just-in-time,动态(即时)编译,边运行边编译: AOT,Ahead Of Time,指运行前编译,是两种程序的编译方式 区别 这两种编译方式的主要区别在于 ...