Day 19 re 模块 random模块,正则表达式
https://www.cnblogs.com/Eva-J/p/7228075.html#_label10


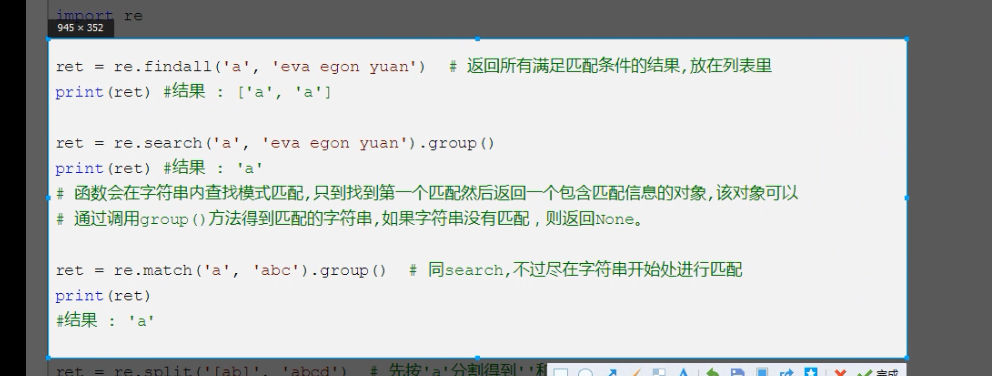
findall

search


match方法 和 search相比 match自带 ^
search match findall区别 :
findall 返回所有匹配项 ,放在列表中
search 需要通过group方法返回满足条件值 。 group分组
search方法 是自带“^” 分组问题


split方法
替换方法 sub
Compile

分组命名
模块名. 方法名()
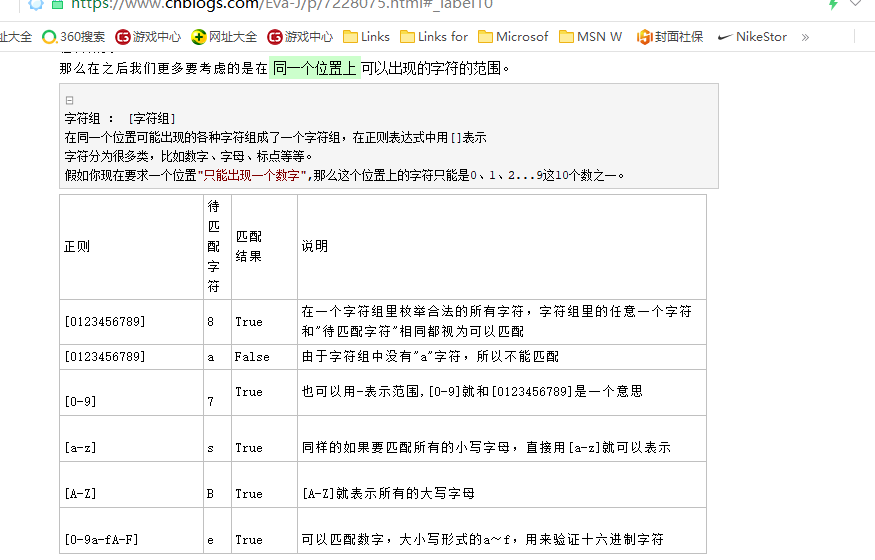
# re 模块的findall 方法
import re
ret =re.findall('\d','eva1 egon2 yuan3 dadf')
print(ret)
# 结果:['1', '2', '3'] 返回所有满足匹配条件的结果,放在列表中
import re
ret = re.findall('[a-z]\d','abd2dfasdfadfadl')
print(ret)
#输出结果为:['d2']
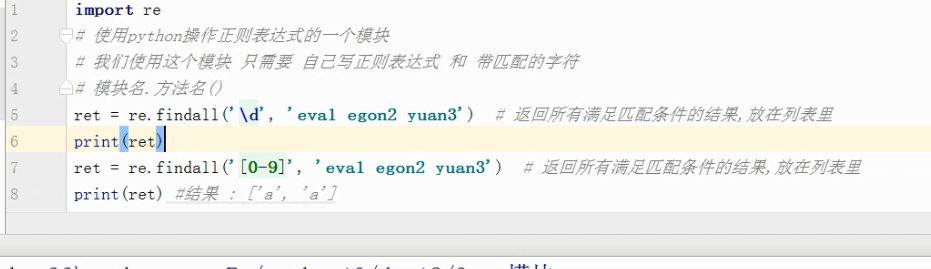
# research
import re
ret = re.search('a','ad ad3oookew a rew')
print(ret)
res =ret.group()
print(res)
# 结果 为a ,返回的事第一个满足条件的项。
# 使用group方法就可以获得到具体的值 #match
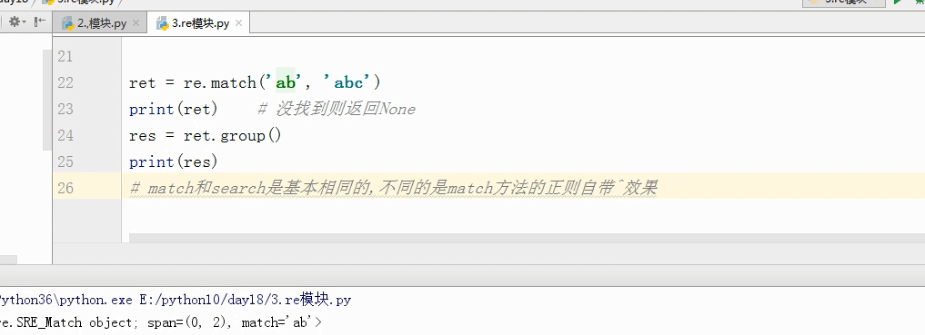
ret =re.match('ab','abcd')
print(ret) # 没找到则返回None
# 返回结果 :<_sre.SRE_Match object; span=(0, 2), match='ab'>
res =ret.group()
print(res)
# 返回结果 ab
# match和search是基本相同的,不同的是match方法的正则自带^效果
ret =re.search('^ab','abcd')
res=ret.group()
print(res)
# 输出结果为ab
findall方法
ret= re.findall('[a-z]\d','ab32300sfasd2dfladsf;')
print(ret)
输出结果 :['b3', 'd2']
分组()
ret= re.findall('[a-z](\d)','ab32300sfasd2dfladsf;')
print(ret)
输出结果:['3', '2']
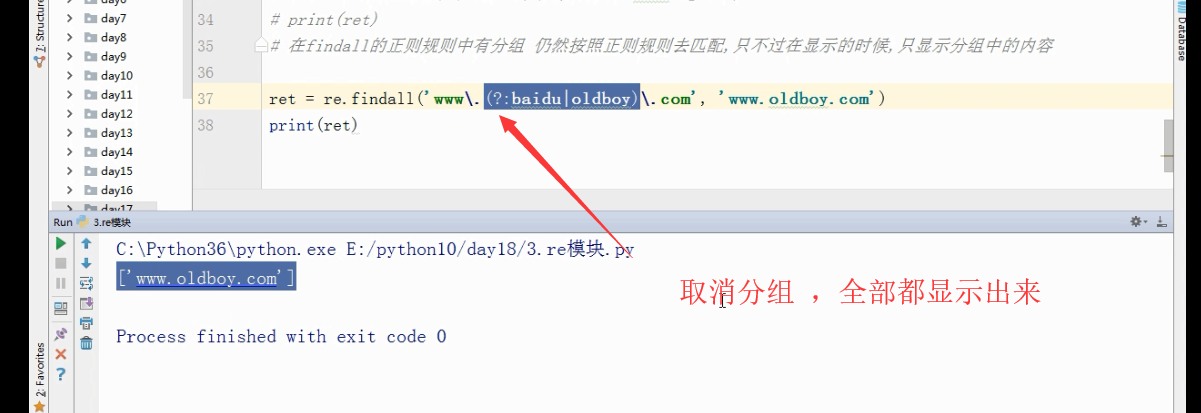
# 在findall的正则规则中有分组 仍然按照正则规则去匹配,只不过在显示的时候,只显示分组中的内容
ret = re.findall('www\.(?:baidu|oldboy)\.com', 'www.oldboy.com')
print(ret)
输出结果['www.oldboy.com']
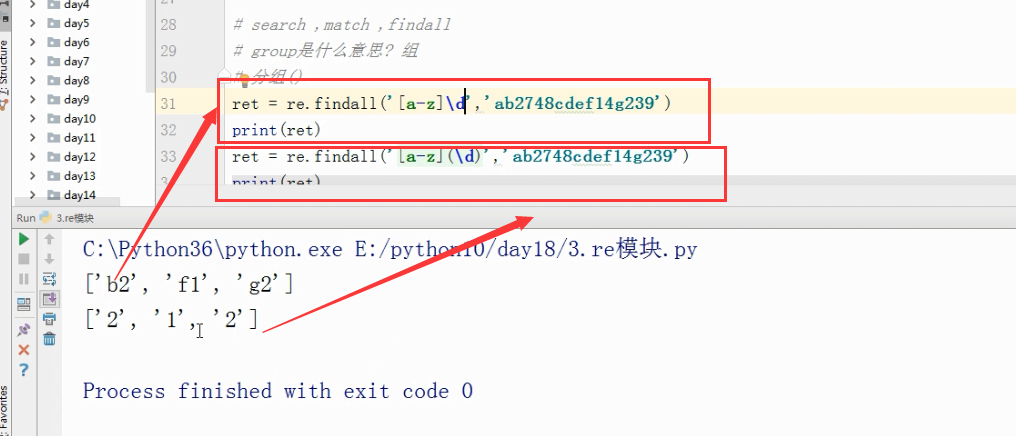
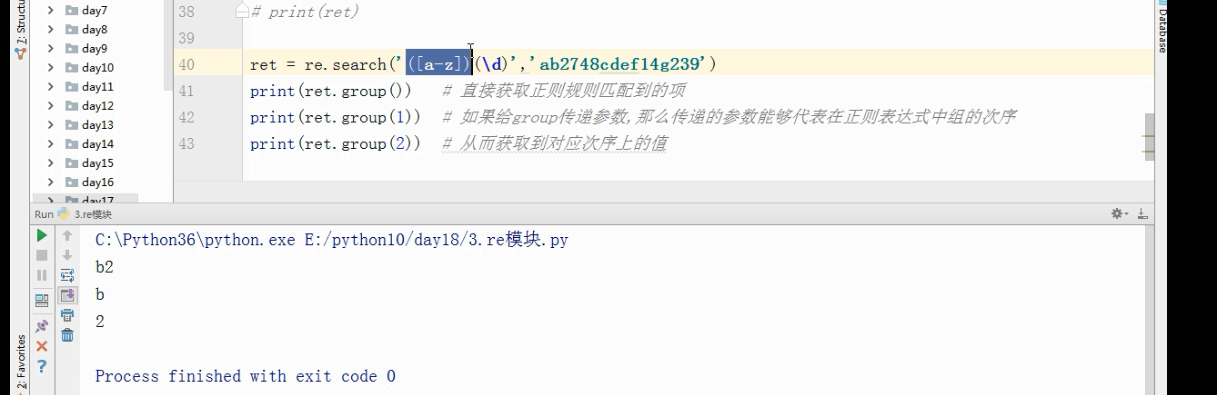
# ret = re.search('([a-z])(\d)','ab2748cdef14g239')
# print(ret.group()) # 直接获取正则规则匹配到的项
# print(ret.group(2)) # 如果给group传递参数,那么传递的参数能够代表在正则表达式中组的次序
# print(ret.group(1)) # 从而获取到对应次序上的值
ret =re.split('\d','a1b2c3d4sdf434')
print(ret)
结果 :['a', 'b', 'c', 'd', 'sdf', '', '', '']
# 先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割
split()
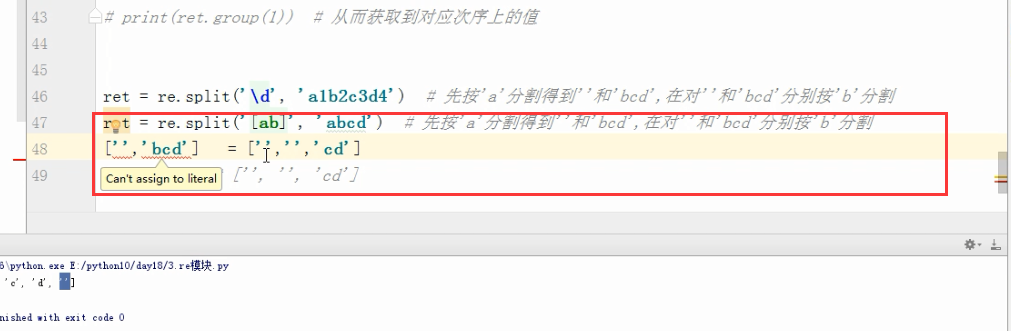
ret = re.split('[ab]','a* bcd')
print(ret)
# 先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割
# ['', '* ', 'cd']
Sub()
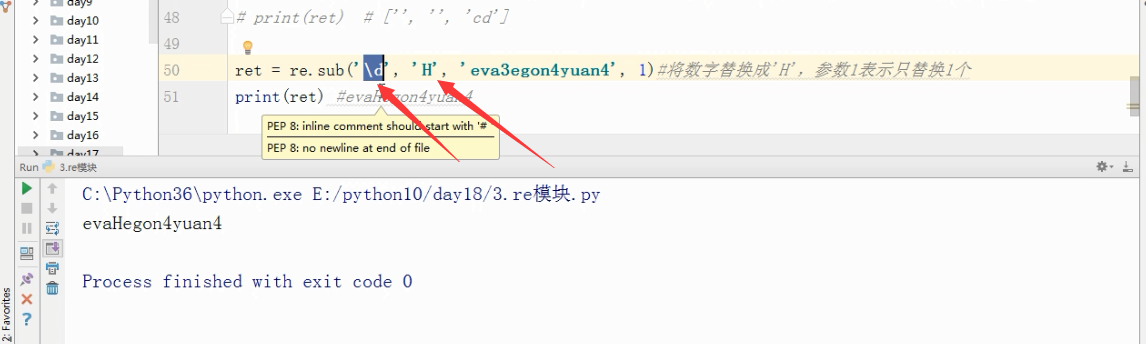
ret =re.sub('\d','H','eva3eon4yuan4',1)#将数字替换成'H',参数1表示只替换1个
print(ret)
输出结果为:evaHeon4yuan4
subn()
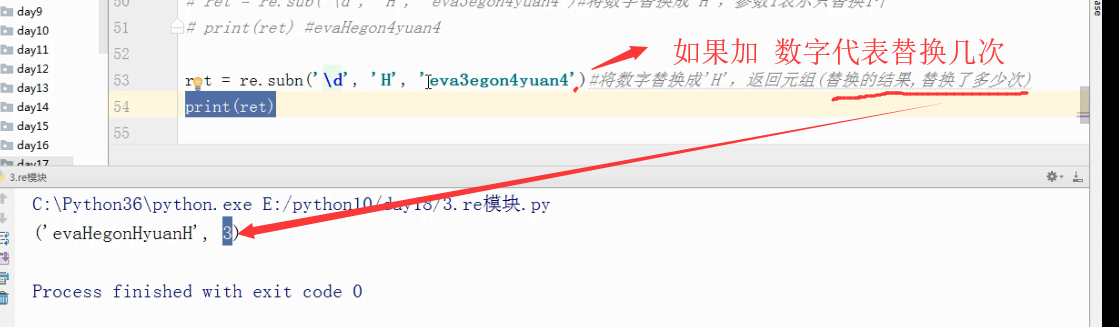
ret = re.subn('\d', 'H', 'eva3egon4yuan4')#将数字替换成'H',返回元组(替换的结果,替换了多少次)
print(ret)
输出结果:('evaHegonHyuanH', 3)
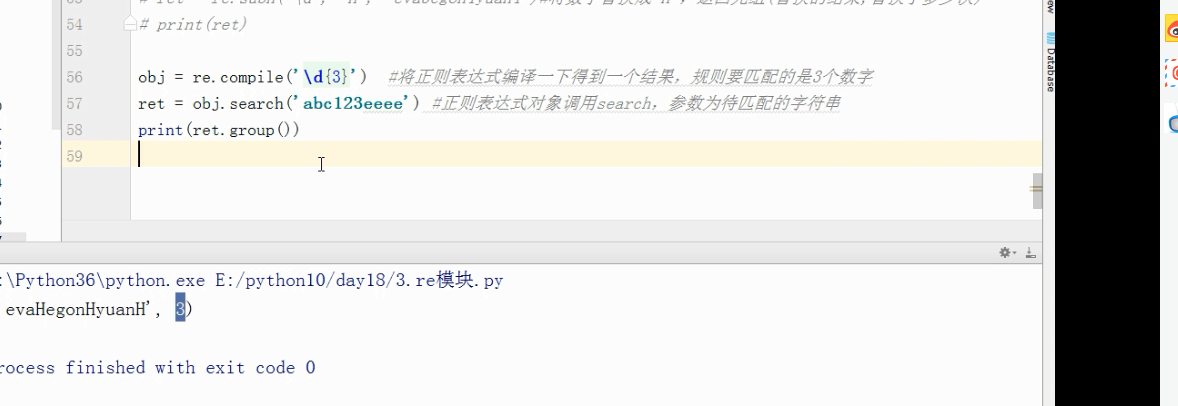
obj =re.compile('\d{3}')#将正则表达式编译一下得到一个结果,规则要匹配的是3个数字
ret=obj.search('abc123eee') #正则表达式对象调用search,参数为待匹配的字符串
print(ret.group())
ret =obj.search("asdfasdfapwe34243243")
print(ret.group())
输出结果 为 :
finderiter .
ret =re.finditer('\d','alfas33dofo2324') #finditer返回一个存放匹配结果的迭代器
print(ret)
# 返回结果<callable_iterator object at 0x01CFC4B0>
for i in ret:
print(i.group())
# 结果2
# 3
# 2
# 4
import re
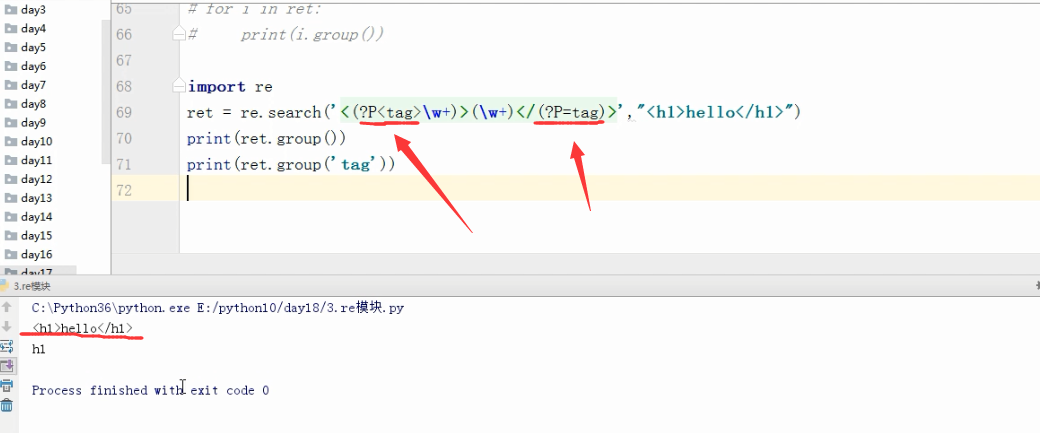
ret = re.search('<(?P<tag>\w+)>(\w+)</(?P=tag)>',"<h1>hello</h1>")
print(ret.group())
print(ret.group('tag'))
结果:
<h1>hello</h1>
h1
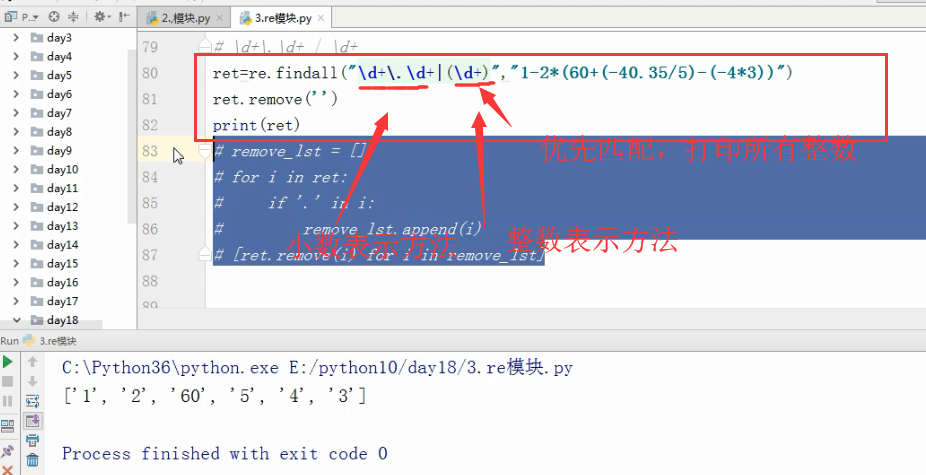
ret=re.findall("\d+","1-2*(60+(-40.35/5)-(-4*3))")
print(ret)
输出结果 ['1', '2', '60', '40', '35', '5', '4', '3'] 查询所有的数字 带小数点的有误.
# \d+\.\d+ | \d+ 小数的表示方法.
# ret=re.findall("\d+\.\d+|(\d+)","1-2*(60+(-40.35/5)-(-4*3))")
# ret.remove('')
# print(ret)
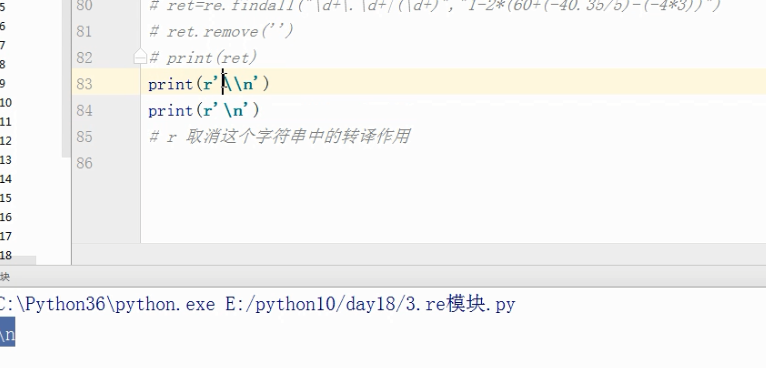
# print(r'\\n')
# print(r'\n')
# r 取消这个字符串中的转译作用
# 凡是出现\且没有特殊意义的时候都可以在字符串的前面加上r符号
# r'\\n' r'\n'
# r'\app\ntp'
输出结果:
['1', '2', '60', '5', '4', '3']
\\n
\n
import re
import json
from urllib.request import urlopen def getPage(url):
'''使用url访问对应的网页,将网页的源码返回'''
response = urlopen(url)
return response.read().decode('utf-8') def parsePage(s):
com = re.compile(
'<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\d+).*?<span class="title">(?P<title>.*?)</span>'
'.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>', re.S) ret = com.finditer(s)
for i in ret:
yield {
"id": i.group("id"),
"title": i.group("title"),
"rating_num": i.group("rating_num"),
"comment_num": i.group("comment_num"),
} def main(num):
url = 'https://movie.douban.com/top250?start=%s&filter=' % num
response_html = getPage(url)
ret = parsePage(response_html)
print(ret)
f = open("move_info7", "a", encoding="utf8")
for obj in ret:
print(obj)
data = str(obj)
f.write(data + "\n") count = 0
for i in range(10):
main(count) #
count += 25
import random
print (random.random()) #返回大于0 小于1 的随机小数
print(random.uniform(2,3)) #返回大于2,小于3的小数.
print(random.randint(10,20))# 返回大于10 小于20的随机整数 .
random.choice 后面加一个(列表等可迭代对象) ,然后取随机一个数或者字符串 ,列表等等.
# print(random.choice([1,'23',[4,5]]))
random.sample 后面加一个(列表等可迭代对象) 和然后n数字, 随机抽取n个字符做随机循环.
# print(random.sample([1,'23',[4,5]],))
random.shuffle 洗牌会用到. random.shuffle(item), item 为一个列表
print (random.shuffle([1,2,2,3,4,6,6,7,8])) #无返回值
# 随机
# 验证码
# 抽奖
import random
# print(random.choice([,'',[,]]))
# print(random.sample([,'',[,]],))# 内容为可迭代对象.
rand
# 排序
# item = [,,,,]
# random.shuffle(item)
# print(item) # 作业 :
# 用namedtuple描述扑克牌
# 用random模块完成生成随机验证码
# 4位随机数字 可以重复
# 6位验证码随机数字和字母 可以重复
# 计算器
# 正则表达式 从大算式中找到一个不再含有小括号的最小算式
# ret -/ -*/ + /*/* + * / -* -*
# 从没有括号的算式中找到乘除法 -/ -*/ + /*/* + * /
# 计算'2*5'的结果
Random
import random
print(random.choice([1,'23',[4,5]]))
print(random.sample([1,'23',[4,5]],2)) # 排序 10000
item = [1,3,5,7,9]
random.shuffle(item)
print(item) 输出结果 :
23
[[4, 5], 1]
[3, 7, 1, 9, 5]
1
[[4, 5], '23']
[5, 7, 3, 9, 1]
Day 19 re 模块 random模块,正则表达式的更多相关文章
- python常用模块——random模块
参考博客:http://www.360doc.com/content/14/0430/11/16044571_373443266.shtml 今天突然想起python该怎么生成随机数?查了一下,贴出实 ...
- Python进阶(十)----软件开发规范, time模块, datatime模块,random模块,collection模块(python额外数据类型)
Python进阶(十)----软件开发规范, time模块, datatime模块,random模块,collection模块(python额外数据类型) 一丶软件开发规范 六个目录: #### 对某 ...
- Python模块01/自定义模块/time模块/datetime模块/random模块
Python模块01/自定义模块/time模块/datetime模块/random模块 内容大纲 1.自定义模块 2.time模块 3.datetime模块 4.random模块 1.自定义模块 1. ...
- python-Day5-深入正则表达式--冒泡排序-时间复杂度 --常用模块学习:自定义模块--random模块:随机验证码--time & datetime模块
正则表达式 语法: mport re #导入模块名 p = re.compile("^[0-9]") #生成要匹配的正则对象 , ^代表从开头匹配,[0 ...
- re模块 ,random模块
# 在python中使用正则表达式 # 转义符 : 在正则中的转义符 \ 在python中的转义符# 正则表达式中的转义 :# '\(' 表示匹配小括号# [()+*?/$.] 在字符组中一些特殊的字 ...
- 转译符,re模块,random模块
一, 转译符 1.python 中的转译符 正则表达式中的内容在Python中就是字符串 ' \n ' : \ 转移符赋予了这个n一个特殊意义,表示一个换行符 ' \ \ n' : \ \ 表示取 ...
- 常用模块(collections模块,时间模块,random模块,os模块,sys模块,序列化模块,re模块,hashlib模块,configparser模块,logging模块)
认识模块 什么是模块? 常见的场景:一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀. 但其实import加载的模块分为四个通用类别: 1 使用python编写的 ...
- 4-24日 collections模块 random模块 time模块 sys模块 os模块
1, collections模块 在内置数据类型(dict.list.set.tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter.deque.defaultdi ...
- Python全栈之路----常用模块----random模块
程序中有很多地方需要用到随机字符,比如登陆网站的随机验证码,通过random模块可以很容易生成随机字符串. >>> import random >>> random ...
随机推荐
- 44-python-三维画图
https://www.cnblogs.com/xingshansi/p/6777945.html python绘制三维图 作者:桂. 时间:2017-04-27 23:24:55 链接:htt ...
- 配置Spring框架编写XML的提示
1. 步骤一:先复制, http://www.springframework.org/schema/beans/spring-beans.xsd 2. 步骤二:搜索XML Catalog,点击Add按 ...
- How to Install and Configure Bind 9 (DNS Server) on Ubuntu / Debian System
by Pradeep Kumar · Published November 19, 2017 · Updated November 19, 2017 DNS or Domain Name System ...
- java读取配置文件的方法
1. Preferences类 这个主要是设置个人喜好.它的数据一般存在系统目录或是用户目录.还可以操作注册表. 2. Properties类 保存键值对.可以指定路径. 3. commons con ...
- 2018.08.16 洛谷P1471 方差(线段树)
传送门 线段树基本操作. 把那个方差的式子拆开可以发现只用维护一个区间平方和和区间和就可以完成所有操作. 同样区间修改也可以简单的操作. 代码: #include<bits/stdc++.h&g ...
- 41 Pain and Pain Management 疼痛与疼痛管理
Pain and Pain Management 疼痛与疼痛管理 ①Years ago,doctors often said that pain was a normal part of life.I ...
- Django(3)
https://www.cnblogs.com/yuanchenqi/articles/7429279.html
- Mysql字符串字段判断是否包含某个字符串的3种方法[转载]
方法一: SELECT * FROM users WHERE emails like "%b@email.com%"; 方法二: 利用mysql字符串函数 find_in_set( ...
- Linux服务器部署系列之六—远程管理篇
做为网络管理员,我们不可能总是在机房操作服务器,对于windows服务器,我们可以通过远程终端或netmeeting进行操作.但是对于Linux服务器呢?我们也可以使用远程工具进行操作,常用的远程管理 ...
- chandy-lamport 分布式一致性快照 算法详细介绍
在一个分布式计算系统中,为了保证数据的一致性需要对数据进行一致性快照.Flink和spark在做流失计算的时候都借鉴了chandy-lamport算法的原理,这篇文章就是对chandy-lamport ...