03_Flume多节点Failover实践
1、实践场景
模拟上游Flume Agent在发送event时的故障切换 (failover)
1)初始:上游Agent向active的下游节点Collector1传递event
2)Collector1故障: kill该进程的方式来模拟, event此时发送给Collector2,完成故障切换
3)Collector1恢复:重新运行该进程,经过最大惩罚时间后,event将恢复发送给Collector1
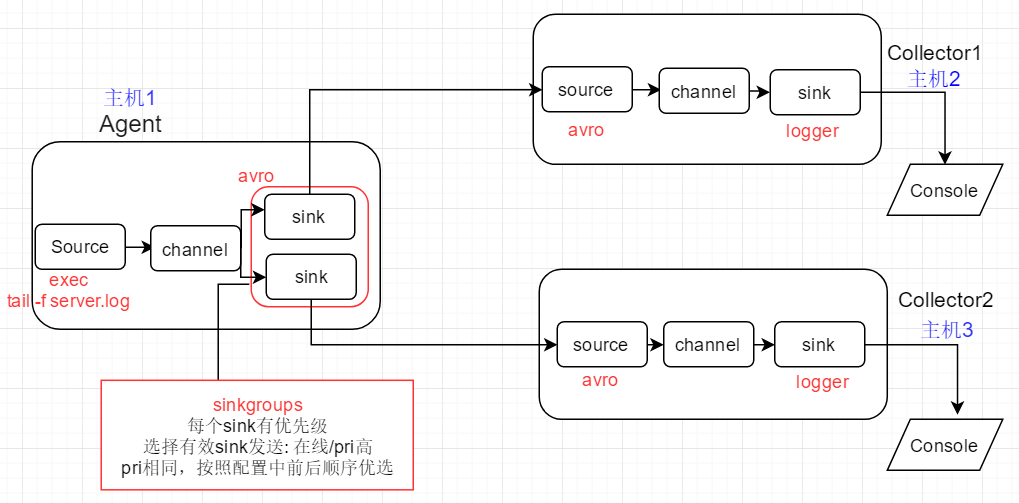
2、配置文件
Agent配置文件
# flume-failover-client
# agent name: a1
# source: exec with given command, monitor output of the command, each line will be generated as an event
# channel: memory
# sink: k1 k2, each set to avro type to link to next-level collector # define source,channel,sink name
a1.sources = r1
a1.channels = c1
a1.sinks = k1 k2 # define source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -f /root/flume_test/server.log # 03 define sink,each connect to next-level collector via hostname and port
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = slave1 # sink bind to remote host, RPC(上游Agent avro sink绑定到下游主机)
a1.sinks.k1.port = 4444 a1.sinks.k2.type = avro
a1.sinks.k2.hostname = slave2 # sink band to remote host, PRC(上游Agent avro sink绑定到下游主机)
a1.sinks.k2.port = 4444 # 04 define sinkgroups,only 1 sink will be selected as active based on priority and online status
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinkgroups.g1.processor.type = failover # k1 will be selected as active to send event if k1 is online, otherwise k2 is selected
a1.sinkgroups.g1.processor.priority.k1 = 10 # 基于优先级进行选择,优先级高的被选中active; 优先级相同则根据k1,k2出现的先后顺序进行选择
a1.sinkgroups.g1.processor.priority.k2 = # failover time,milliseconds
# if k1 is down and up again, k1 will be selected as active after seconds
a1.sinkgroups.g1.processor.priority.maxpenality = 1000 # 回切时间 # define channel
a1.channels.c1.type = memory
# number of events in memory queue
a1.channels.c1.capacity =
# number of events for commit(commit events to memory queue)
a1.channels.c1.transactioncapacity = # bind source,sink to channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c1
Collector1配置文件
# specify agent,source,sink,channel
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # 02 avro source,connect to local port 4444
a1.sources.r1.type = avro # 下游avro source绑定到本机,端口号要和上游Agent指定值保持一致
a1.sources.r1.bind = slave1
a1.sources.r1.port = 4444 # logger sink
a1.sinks.k1.type = logger # channel,memory
a1.channels.c1.type = memory
a1.channels.c1.capacity =
a1.channels.c1.transactionCapacity = # bind source,sink to channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
Collector2配置文件
# specify agent,source,sink,channel
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # 02 avro source,connect to local port 4444
a1.sources.r1.type = avro # 下游avro source绑定到本机,端口号要和上游Agent指定值保持一致
a1.sources.r1.bind = slave2
a1.sources.r1.port = 4444 # logger sink
a1.sinks.k1.type = logger # channel,memory
a1.channels.c1.type = memory
a1.channels.c1.capacity =
a1.channels.c1.transactionCapacity = # bind source,sink to channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
3、启动Collector1,2 以及Agent
启动Collector1
# ./bin/flume-ng agent --conf conf --conf-file ./conf/flume-failover-server.properties --name a1 -Dflume.root.logger=INFO,console
解读:根据当前目录下的conf目录中的flume-failvoer-server.properties配置文件启动flume agent; agent名称为a1;
flume向终端打印INFO级别及以上的日志信息
启动Collector2
# ./bin/flume-ng agent --conf conf --conf-file ./conf/flume-failover-server.properties --name a1 -Dflume.root.logger=INFO,console
启动Agent
# ./bin/flume-ng agent --conf conf --conf-file ./conf/flume-failover-client.properties --name a1 -Dflume.root.logger=INFO,console
注意:
1)要先启动下游Collector,再去启动Agent; 否则Agent启动后就会进行下游有效站点的选择,此时Collector如果还没有启动,则会出现报错

2)3个Agent正常启动后, Agent会建立和所有下游站点的连接: 经历 open -> bound -> connected 三个阶段


4、故障模拟及恢复
1) 故障发生前: 首先向log文件,管道方式添加数据,查看event是否在Collector1的终端被打印
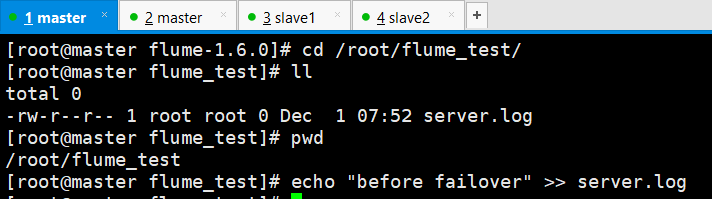
Collector1所在的Slave1节点收到并向终端打印event

2) 故障模拟: kill collector1进程
3)再次尝试发送数据

Collector2所在的Slave2节点收到并向终端打印event

与此同时,Agent将一直尝试重新建立和Collector1的连接

4)重新启动Collector1进程,模拟故障恢复
# ./bin/flume-ng agent --conf conf --conf-file ./conf/flume-failover-server.properties --name a1 -Dflume.root.logger=INFO,console
5)向log中再次追加数据,查看event是否重新被发送给collector1, 并被打印到终端

此时Collecot1收到并打印事件 (回切时间在Agent的配置中设置为1秒)

6) 考虑所有下游节点全部down掉,之后下游节点恢复的情况,数据最终给谁?
由于Flume有基于event的事务机制,当下游节点全部down掉时,Flume会将event保留在channel中
当下游节点重新恢复,Agent会再次进行active节点选择,然后将evnet再次发送
当下游节点收到event后,Agent才将event从channel中移除
如果是Collecotr2先恢复, 则event会发送给Collector2; 并且Collecot1之后并不会收到发给Collector2的数据,因此event此时已经从Agent的channel中被移除
03_Flume多节点Failover实践的更多相关文章
- 02_Flume1.6.0安装及单节点Agent实践
Flume1.6.0的安装1.上传Flume-1.6.0-tar.gz到待部署的所有机器 以我的为例: /usr/local/src/ 2.解压得到flume文件夹 # tar -x ...
- 04_Flume多节点load_balance实践
1.负载均衡场景 1)初始:上游Agent通过round_robin selector, 将event轮流发送给下游Collecotor1, Collector2 2)故障: 关闭Collector1 ...
- DG_Oracle DataGuard Primary/Standby物理主备节点安装实践(案例)
2014-09-09 Created By BaoXinjian
- 02_Kafka单节点实践
1.实践场景 开始前的准备条件: 1) 确认各个节点的jdk版本,将jdk升级到和kafka配套的版本(解压既完成安装,修改/etc/profile下的JAVA_HOME,source /etc/pr ...
- redis 学习笔记(2)
redis-cluster 简介 redis-cluster是一个分布式.容错的redis实现,redis-cluster通过将各个单独的redis实例通过特定的协议连接到一起实现了分布式.集群化的目 ...
- Centos6 安装 Redis
先确认gcc和tcl已经安装 sudo yum install gcc-c++ sudo yum install tcl 解压, 编译和安装 .tar.gz /usr/src/ cd /usr/src ...
- vagrant系列教程(四):vagrant搭建redis与redis的监控程序redis-stat(转)
上一篇php7环境的搭建 真是火爆,仅仅两天时间,就破了我之前swagger系列的一片文章,看来,大家对搭建环境真是情有独钟. 为了访问量,我今天再来一篇Redis的搭建.当然不能仅仅是redis的搭 ...
- memcached-session-manager的一些理解
1.节点分配 粘性规划: Tomcat-1(t1)将session优先备份在运行在令一台机器上的memcached-2(m2)上面,仅当m2失效的时候,t1才会将sessin存储在m1上面(m1是t1 ...
- 各种ESB产品比较(转)
介绍了主流商业和开源ESB的发展趋势.可借鉴的地方和其缺点: 主要介绍: Oracle Service Bus WebSphere Message Broker ...
随机推荐
- 007-spring cloud gateway-GatewayAutoConfiguration核心配置-RouteDefinition初始化加载
一.RouteDefinitionLocator 在Spring-Cloud-Gateway的GatewayAutoConfiguration初始化加载中会加载RouteDefinitionLocat ...
- [py]flask从0到1-模板/增删改查
flask知识点 1.后端渲染html到前端 render_template 2.后端获取前端数据 request.args.get 3.前端获取后端数据 模板 4.警示消息 flash {{ get ...
- [py]py2自带Queue模块实现了3类队列
py2自带Queue实现了3类队列 先搞清楚几个单词 Queue模块实现了三类队列: FIFO(First In First Out,先进先出,默认为该队列), 我们平时泛指的队列, LIFO(Las ...
- u-boot SPL的理解
uboot分为uboot-spl和uboot两个组成部分.SPL是Secondary Program Loader的简称,第二阶段程序加载器,这里所谓的第二阶段是相对于SOC中的BROM来说的,之前的 ...
- Hat's Fibonacci
http://acm.hdu.edu.cn/showproblem.php?pid=1250 大数斐波那契 %08d是什么东西,为什么我用flag交不上,唉,不刷大数了,没劲.暑假再讲. 就是交不上 ...
- 机器学习理论基础学习18---高斯过程回归(GPR)
一.高斯(分布)过程(随机过程)是什么? 一维高斯分布 多维高斯分布 无限维高斯分布 高斯网络 高斯过程 简单的说,就是一系列关于连续域(时间或空间)的随机变量的联合,而且针对每一个时间或是空间点 ...
- react native android 编译
修改 Maven 仓库地址 React Native 在初始化时会从 jcenter.binary.com 这个地方下载一些东西,网上搜索了一下,好像是在下载 Maven 相关的依赖. 针对全局进行修 ...
- 集合框架—常见的Set集合
list ArrayList 动态数组结构存储,遍历速度快,索引随机访问快,允许多空值 LinkedList 底层数据结构是链表,插入和删除速度快. Vector 数组结构存储,线程安全的,查找速度快 ...
- CFA
拜耳色彩滤波阵列(Bayer Color Filter Array, CFA)是非常有名的彩色图片的数字采集格式.由1/2的G,1/4得R,1/4的B组成. 当Image Sensor向外逐行输出数据 ...
- centos6更改密码
创建新用户 创建一个用户名为:zhangbiao [root@localhost ~]# adduser zhangbiao 为这个用户初始化密码,linux会判断密码复杂度,不过可以强行忽略: [r ...