python抓取今日头条
# 直接上代码,抓取关键词搜索结果的json数据
# coding:utf-8
import requests
import json url = 'http://www.toutiao.com/search_content/?offset=0&format=json&keyword=%E5%B0%8F%E5%BA%B7%E7%A4%BE%E4%BC%9A&autoload=true&count=20&cur_tab=1'
wbdata = requests.get(url).text data = json.loads(wbdata)
news = data['data'] for n in news:
if 'title' in n:
title = n['title']
source = n['source']
url = n['article_url']
keyword = n['keywords']
print(title,url,keyword,source)
github: https://github.com/haibincoder/ToutiaoCrawler
1.浏览器中找到内容的接口,Network --> XHR是动态加载的,如果没有内容的话刷新当前页面,我们这里可以看到data节点下面有需要的数据。
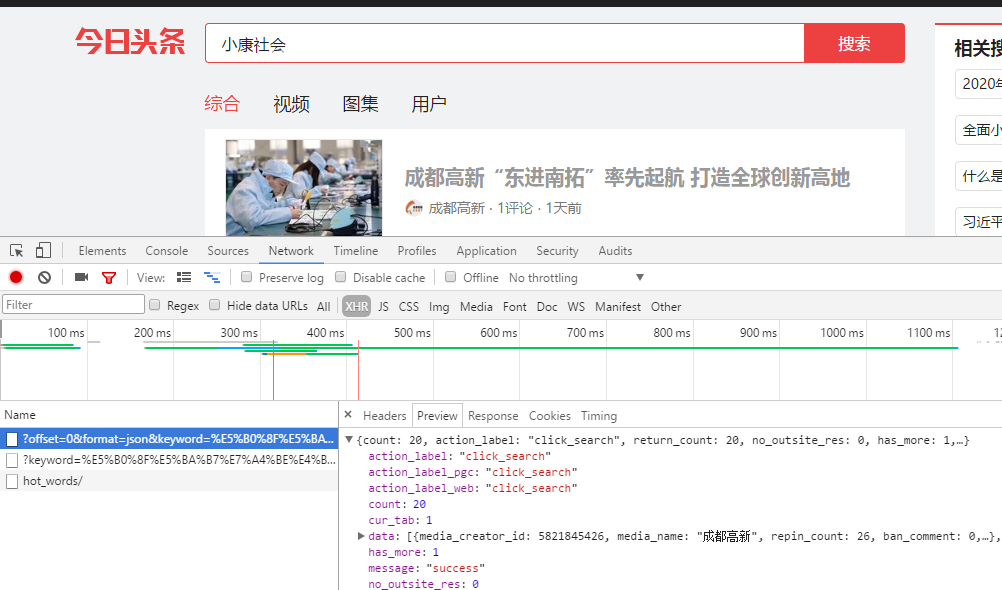
2.找到需要的内容和url

3.返回结果

另外可以爬取关键词搜索结果,keyword就是一个数组,可以自己定义。
def keyword_search(keyword):
url = 'http://www.toutiao.com/search_content/?offset=0&format=json&keyword= ' + keyword + '&autoload=true&count=200&cur_tab=1' toutiao_data = requests.get(url).text data = json.loads(toutiao_data)
items = data['data'] news_list = []
link_head = 'http://toutiao.com' for n in items:
if 'title' in n:
news = News()
news.title = n['title']
news.tag = n['tag']
news.source = n['source']
news.source_url = link_head + n['source_url']
# 两会关键词
news.keyword = keyword
# 今日头条自带关键词
news.keywords = n['keywords'] news_list.append(news)
#print(news.title, news.source_url, news.source, news.keyword, news.keywords) return news_list
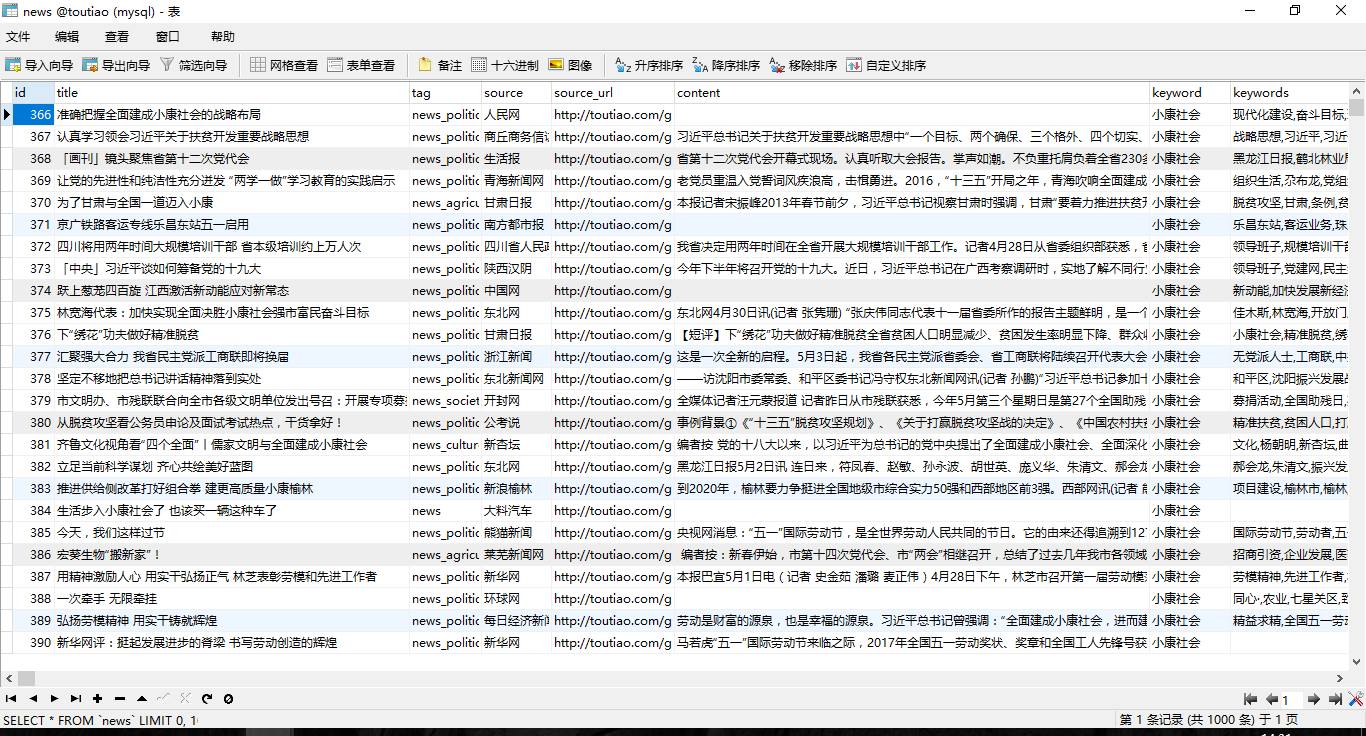
爬取结果,其中Content另外写了一个爬虫,第二个爬虫就是读取source_url,然后抓取正文
python抓取今日头条的更多相关文章
- python爬虫之分析Ajax请求抓取抓取今日头条街拍美图(七)
python爬虫之分析Ajax请求抓取抓取今日头条街拍美图 一.分析网站 1.进入浏览器,搜索今日头条,在搜索栏搜索街拍,然后选择图集这一栏. 2.按F12打开开发者工具,刷新网页,这时网页回弹到综合 ...
- Python Spider 抓取今日头条街拍美图
""" 抓取今日头条街拍美图 """ import os import time import requests from hashlib ...
- 分析ajax请求抓取今日头条关键字美图
# 目标:抓取今日头条关键字美图 # 思路: # 一.分析目标站点 # 二.构造ajax请求,用requests请求到索引页的内容,正则+BeautifulSoup得到索引url # 三.对索引url ...
- 15-分析Ajax请求并抓取今日头条街拍美图
流程框架: 抓取索引页内容:利用requests请求目标站点,得到索引网页HTML代码,返回结果. 抓取详情页内容:解析返回结果,得到详情页的链接,并进一步抓取详情页的信息. 下载图片与保存数据库:将 ...
- [Python爬虫] 之二十五:Selenium +phantomjs 利用 pyquery抓取今日头条网数据
一.介绍 本例子用Selenium +phantomjs爬取今日头条(http://www.toutiao.com/search/?keyword=电视)的资讯信息,输入给定关键字抓取资讯信息. 给定 ...
- Python爬取今日头条段子
刚入门Python爬虫,试了下爬取今日头条官网中的段子,网址为https://www.toutiao.com/ch/essay_joke/源码比较简陋,如下: import requests impo ...
- Python爬虫学习==>第十一章:分析Ajax请求-抓取今日头条信息
学习目的: 解决AJAX请求的爬虫,网页解析库的学习,MongoDB的简单应用 正式步骤 Step1:流程分析 抓取单页内容:利用requests请求目标站点,得到单个页面的html代码,返回结果: ...
- python学习(26)分析ajax请求抓取今日头条cosplay小姐姐图片
分析ajax请求格式,模拟发送http请求,从而获取网页代码,进而分析取出需要的数据和图片.这里分析ajax请求,获取cosplay美女图片. 登陆今日头条,点击搜索,输入cosplay 下面查看浏览 ...
- [Python爬虫] 之二十七:Selenium +phantomjs 利用 pyquery抓取今日头条视频
一.介绍 本例子用Selenium +phantomjs爬取今天头条视频(http://www.tvhome.com/news/)的信息,输入给定关键字抓取图片信息. 给定关键字:视频:融合:电视 二 ...
随机推荐
- Eclipse插件的安装与配置
1.下载插件时注意要和Eclipse版本兼容. 2.安装Eclipse插件时注意是否要安装其他的插件,这一点很容易被忽视. 3.有时启动Eclipse未加载插件,解决方法很多,总结一下: a ...
- Oracle 12C -- Plug in a Non-CDB as a PDB
1.备份non-CDB数据库2.关闭non-CDB数据库 SQL> shutdown immediate; 3.将non-CDB至于只读状态 SQL> startup open read ...
- C#winform实现跑马灯
using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; usin ...
- excel中对数据进行分类求和
我们在用excel处理数据时,常常需要按不同的类别分别汇总数据.例如下图中需要求出每个业务员的总销售金额等. 通常情况下我们的数据量很大,而且需要较快的统计出来结果,所以我们要用一定的技巧才能计算出来 ...
- 转 HystrixDashboard服务监控、Turbine聚合监控
SpringCloud系列七:Hystrix 熔断机制(Hystrix基本配置.服务降级.HystrixDashboard服务监控.Turbine聚合监控) 1.概念:Hystrix 熔断机制 2.具 ...
- Java:多线程,CountDownLatch同步器
1. 背景 CountDownLatch类,在完成一组正在其他线程中执行的操作之前,它允许一个或多个线程一直等待. 用给定的计数 初始化 CountDownLatch.由于调用了 countDown( ...
- Android 源码解析:单例模式-通过容器实现单例模式-懒加载方式
本文分析了 Android 系统服务通过容器实现单例,确保系统服务的全局唯一. 开发过 Android 的用户肯定都用过这句代码,主要作用是把布局文件 XML 加载到系统中,转换为 Android 的 ...
- Android Gradle 引入 aar 方式
方式 1 File -> New -> New Module -> Import .JAR/.AAR Package Choose File Finish 在 build.gradl ...
- java https 请求
http://li3huo.com/index.php/2009/09/https-certificates-are-ignoring-the-right-java-http-client/
- spring cloud 项目相关集成简介
Spring Cloud Config 配置管理工具包,让你可以把配置放到远程服务器,集中化管理集群配置,目前支持本地存储.Git以及Subversion. Spring Cloud Bus 事件.消 ...