第六篇:Eclipse上运行第一个Hadoop实例 - WordCount(单词统计程序)
需求
计算出文件中每个单词的频数。要求输出结果按照单词的字母顺序进行排序。每个单词和其频数占一行,单词和频数之间有间隔。
比如,输入两个文件,其一内容如下:
hello world
hello hadoop
hello mapreduce
另一内容如下:
bye world
bye hadoop
bye mapreduce
对应上面给出的输入样例,其输出样例为:
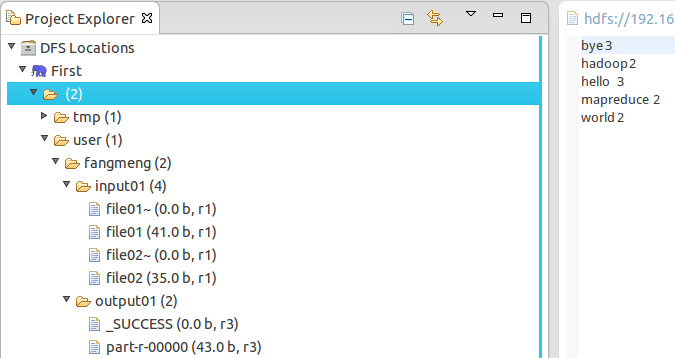
bye 3
hadoop 2
hello 3
mapreduce 2
world 2
方案制定
对该案例,可设计出如下的MapReduce方案:
1. Map阶段各节点完成由输入数据到单词切分再到单词搜集的工作
2. shuffle阶段完成相同单词的聚集再到分发到各个Reduce节点的工作 (shuffle阶段是MapReduce的默认过程)
3. Reduce阶段负责接收所有单词并计算各自频数
代码示例
/**
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/ package org.apache.hadoop.examples; import java.io.IOException;
import java.util.StringTokenizer; //导入各种Hadoop包
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser; // 主类
public class WordCount { // Mapper类
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{ // new一个值为1的整数对象
private final static IntWritable one = new IntWritable(1);
// new一个空的Text对象
private Text word = new Text(); // 实现map函数
public void map(Object key, Text value, Context context) throws IOException, InterruptedException { // 创建value的字符串迭代器
StringTokenizer itr = new StringTokenizer(value.toString()); // 对数据进行再次分割并输出map结果。初始格式为<字节偏移量,单词> 目标格式为<单词,频率>
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
} // Reducer类
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { // new一个值为空的整数对象
private IntWritable result = new IntWritable(); // 实现reduce函数
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0;
for (IntWritable val : values) {
sum += val.get();
} // 得到本次计算的单词的频数
result.set(sum); // 输出reduce结果
context.write(key, result);
}
} // 主函数
public static void main(String[] args) throws Exception { // 获取配置参数
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); // 检查命令语法
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
} // 定义作业对象
Job job = new Job(conf, "word count");
// 注册分布式类
job.setJarByClass(WordCount.class);
// 注册Mapper类
job.setMapperClass(TokenizerMapper.class);
// 注册合并类
job.setCombinerClass(IntSumReducer.class);
// 注册Reducer类
job.setReducerClass(IntSumReducer.class);
// 注册输出格式类
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 设置输入输出路径
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); // 运行程序
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
运行方法
1. 打开Eclipse并启动Hdfs(方法请参考前文)
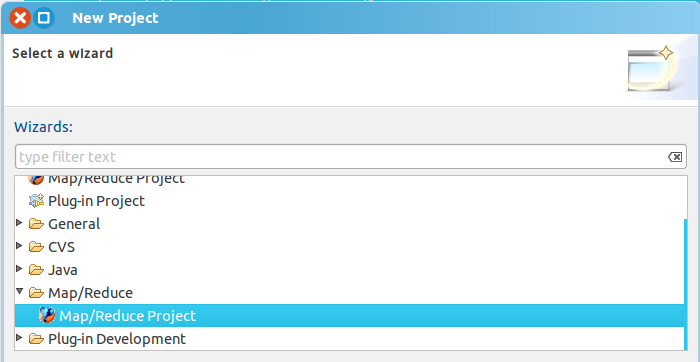
2. 新建一个MapReduce工程:”file" -> "new" -> "project",然后选择 "Map/Reduce Project"
3. 设置输入目录及文件
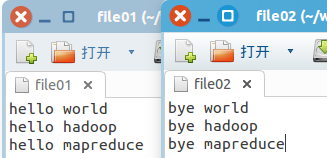
在项目工程包里面新建一个名为input的目录,里面存放需要处理的输入文件。这里选用2个文件名分别为file01和file02的文件进行测试。文件内容同需求示例。
4. 将输入文件传输入Hdfs
在终端输入以下命令即可将整个目录传输进Hdfs(input目录下的所有文件将会被送进Hdfs下名为input01的目录里),请根据MapReduce工程包实际路径对如下命令略作修改即可:
./bin/hadoop fs -put ../workspace/Hadoop_t1/input/ input01
5. 在工程包中新建一个WordCount类并将上面的源代码拷贝进去。
6. 调整项目运行参数:右键项目 -> “Run As" -> ”Run Configurations"
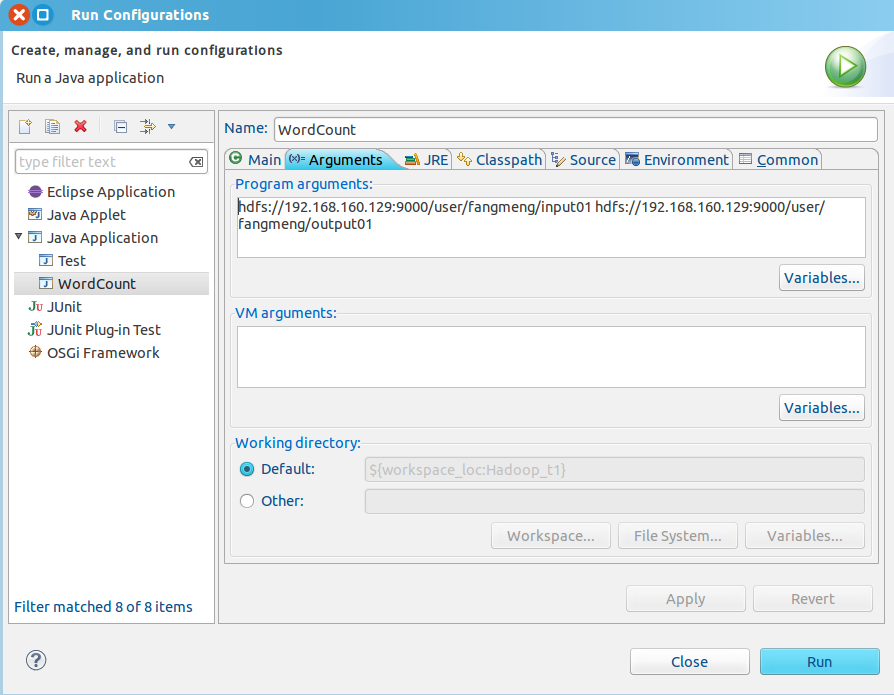
需要添加的就是"Program arguments"下的那些代码。它们其实是作为命令行参数传递进程序的,第一段是输入文件路径;第二段是输出文件路径。
路径的格式为 "[主机IP地址:hdfs端口] + [输入/输出目录在hdfs中的路径]"。
可以输入以下命令查看输入目录路径:
./bin/hadoop fs -ls

7. 点击"Run"运行程序。
8. 执行以下命令查看结果:
./bin/hadoop fs -cat output01/*

这些主机和Hdfs的文件传递,显示也可以使用Eclipse,更方便容易。在此就不提了。
小结
1. 多多熟练Hadoop平台下MapReduce项目基本创建流程。
2. WordCount是一个很经典的Hadoop示例,它虽然简单,但具有很大的代表性。
3. 从某个程度上来说也反映了其设计的初衷,对日志文件的分析。
第六篇:Eclipse上运行第一个Hadoop实例 - WordCount(单词统计程序)的更多相关文章
- Eclipse上运行第一个Hadoop实例 - WordCount(单词统计程序)
需求 计算出文件中每个单词的频数.要求输出结果按照单词的字母顺序进行排序.每个单词和其频数占一行,单词和频数之间有间隔. 比如,输入两个文件,其一内容如下: hello world hello had ...
- hadoop学习---运行第一个hadoop实例
hadoop环境搭建好后,运行第wordcount示例 1.首先启动hadoop:sbin/start-dfs.sh,sbin/start-yarn.sh(必须能够正常运行) 2.进入到hadoo ...
- 第二章 mac上运行第一个appium实例
一.打开appium客户端工具 1 检查环境是否正常运行: 点击左边第三个图标 这是测试你环境是否都配置成功了 2 执行的过程中,遇到Could not detect Mac OS ...
- 在Hadoop1.2.1上运行第一个Hadoop程序FileSystemCat
- 在Eclipse上运行Spark(Standalone,Yarn-Client)
欢迎转载,且请注明出处,在文章页面明显位置给出原文连接. 原文链接:http://www.cnblogs.com/zdfjf/p/5175566.html 我们知道有eclipse的Hadoop插件, ...
- 在Hadoop上运行基于RMM中文分词算法的MapReduce程序
原文:http://xiaoxia.org/2011/12/18/map-reduce-program-of-rmm-word-count-on-hadoop/ 在Hadoop上运行基于RMM中文分词 ...
- 运行第一个Hadoop程序,WordCount
系统: Ubuntu14.04 Hadoop版本: 2.7.2 参照http://www.cnblogs.com/taichu/p/5264185.html中的分享,来学习运行第一个hadoop程序. ...
- mac上eclipse上运行word count
1.打开eclipse之后,建立wordcount项目 package wordcount; import java.io.IOException; import java.util.StringTo ...
- Eclipse上运行Python,使用PyDev
转自:http://www.ibm.com/developerworks/cn/opensource/os-cn-ecl-pydev/index.html 级别: 初级 郑 伟芳 (zhengwf@c ...
随机推荐
- ErrorProvider控件使用
在Windows应用程序开发中,我们可以通过处理输入控件(如TextBox控件)的Validating事件,对用户的输入进行有效性验证,当用户输入不正确时,可以使用错误提示控件ErrorProvide ...
- matlab中常用的函数
find()函数: 功能:用于返回矩阵中想要的元素的索引值: 用法: index = find(X), 当X为一个矩阵时,返回的index是一个列向量,表示矩阵X中非零值的索引值,这个索引值吧,是按把 ...
- css 解决父div与子div不在同一容器的问题
<html> <head> </head> <body> <div style="margin:0 auto;width:600px;b ...
- MySQL存储引擎Innodb和MyISAM对比总结
Innodb引擎 InnoDB是一个事务型的存储引擎,设计目标是处理大数量数据时提供高性能的服务,它在运行时会在内存中建立缓冲池,用于缓冲数据和索引. Innodb引擎优点 1.支持事务处理.ACID ...
- 特殊权限set_uid /特殊权限set_gid/特殊权限stick_bit/软链接文件/硬连接文件
2.18 特殊权限set_uid 2.19 特殊权限set_gid 2.20 特殊权限stick_bit 2.21 软链接文件 2.22 硬连接文件 特殊权限set_uid(s权限用户user权限) ...
- HttpURLConnection和HttpClient的区别2(转)
1.HttpClient比HttpURLConnection功能更强大,但是做java建议用前者,安卓建议用后者 2.这两者都支持HTTPS,streaming 上传与下载,配置超时时间,IPv6, ...
- Link1123:转换到COFF期间失败:文件无效或损坏
当在编译VS项目时,出现如下错误: 这个错误,表明在连接阶段出错.COFF为Common Object File Format,通用对象文件格式,它的出现为混合语言编程带来方便 ...
- Mac OS终端中设置颜色高亮和自动补全
已测试通过,原文:http://blog.csdn.net/songjinshi/article/details/8945809 一.颜色高亮显示 针对terminal采用bash模式: 编辑 ~/. ...
- 移动端网页使用flexible.js加入百度联盟广告样式不一致问题解决
flexible.js是淘宝推出的一款移动端手机自适应的库,源码内容很简洁,当网页使用了该库之后,页面会在head中加入对应的页面响应式的meta标签. 当使用flexible.js的时候,引入百度联 ...
- win8.1的ie11无法打开127.0.0.1和本机IP访问
解决方法:把ie11安全选项里的启动保护模式对勾去掉!