Hadoop:开发机运行spark程序,抛出异常:ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
问题:
windows开发机运行spark程序,抛出异常:ERROR Shell: Failed to locate the winutils binary in the hadoop binary path,但是可以正常执行,并不影响结果。
// :: WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
// :: ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:)
at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:)
at org.apache.hadoop.util.Shell.<clinit>(Shell.java:)
at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:)
at org.apache.hadoop.security.Groups.parseStaticMapping(Groups.java:)
at org.apache.hadoop.security.Groups.<init>(Groups.java:)
at org.apache.hadoop.security.Groups.<init>(Groups.java:)
at org.apache.hadoop.security.Groups.getUserToGroupsMappingService(Groups.java:)
at org.apache.hadoop.security.UserGroupInformation.initialize(UserGroupInformation.java:)
at org.apache.hadoop.security.UserGroupInformation.ensureInitialized(UserGroupInformation.java:)
at org.apache.hadoop.security.UserGroupInformation.loginUserFromSubject(UserGroupInformation.java:)
at org.apache.hadoop.security.UserGroupInformation.getLoginUser(UserGroupInformation.java:)
at org.apache.hadoop.security.UserGroupInformation.getCurrentUser(UserGroupInformation.java:)
at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$.apply(Utils.scala:)
at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$.apply(Utils.scala:)
at scala.Option.getOrElse(Option.scala:)
at org.apache.spark.util.Utils$.getCurrentUserName(Utils.scala:)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:)
at org.apache.spark.api.java.JavaSparkContext.<init>(JavaSparkContext.scala:)
at com.lm.sparkLearning.utils.SparkUtils.getJavaSparkContext(SparkUtils.java:)
at com.lm.sparkLearning.rdd.RddLearning.main(RddLearning.java:)
// :: WARN RddLearning: singleOperateRdd mapRdd->[, , , ]
// :: WARN RddLearning: singleOperateRdd flatMapRdd->[, , , , , , , ]
// :: WARN RddLearning: singleOperateRdd filterRdd->[, ]
// :: WARN RddLearning: singleOperateRdd distinctRdd->[, , ]
// :: WARN RddLearning: singleOperateRdd sampleRdd->[, ]
// :: WARN RddLearning: the program end
这里所执行的程序是:
package com.lm.sparkLearning.rdd; import java.util.Arrays;
import java.util.Iterator;
import java.util.List; import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.VoidFunction;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory; import com.lm.sparkLearning.utils.SparkUtils; public class RddLearning {
private static Logger logger = LoggerFactory.getLogger(RddLearning.class); public static void main(String[] args) { JavaSparkContext jsc = SparkUtils.getJavaSparkContext("RDDLearning", "local[2]", "WARN"); SparkUtils.createRddExternal(jsc, "D:/README.txt");
singleOperateRdd(jsc); jsc.stop(); logger.warn("the program end");
} public static void singleOperateRdd(JavaSparkContext jsc) {
List<Integer> nums = Arrays.asList(new Integer[] { 1, 2, 3, 3 });
JavaRDD<Integer> numsRdd = SparkUtils.createRddCollect(jsc, nums); // map
JavaRDD<Integer> mapRdd = numsRdd.map(new Function<Integer, Integer>() {
private static final long serialVersionUID = 1L; @Override
public Integer call(Integer v1) throws Exception {
return (v1 + 1);
}
}); logger.warn("singleOperateRdd mapRdd->" + mapRdd.collect().toString()); JavaRDD<Integer> flatMapRdd = numsRdd.flatMap(new FlatMapFunction<Integer, Integer>() {
private static final long serialVersionUID = 1L; @Override
public Iterable<Integer> call(Integer t) throws Exception {
return Arrays.asList(new Integer[] { 2, 3 });
}
}); logger.warn("singleOperateRdd flatMapRdd->" + flatMapRdd.collect().toString()); JavaRDD<Integer> filterRdd = numsRdd.filter(new Function<Integer, Boolean>() {
private static final long serialVersionUID = 1L; @Override
public Boolean call(Integer v1) throws Exception {
return v1 > 2;
}
}); logger.warn("singleOperateRdd filterRdd->" + filterRdd.collect().toString()); JavaRDD<Integer> distinctRdd = numsRdd.distinct(); logger.warn("singleOperateRdd distinctRdd->" + distinctRdd.collect().toString()); JavaRDD<Integer> sampleRdd = numsRdd.sample(false, 0.5); logger.warn("singleOperateRdd sampleRdd->" + sampleRdd.collect().toString());
}
}
解决方案:
1.下载winutils的windows版本
GitHub上,有人提供了winutils的windows的版本,项目地址是:https://github.com/srccodes/hadoop-common-2.2.0-bin,直接下载此项目的zip包,下载后是文件名是hadoop-common-2.2.0-bin-master.zip,随便解压到一个目录。
2.配置环境变量
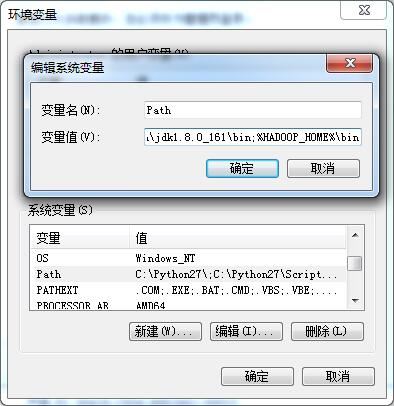
增加用户变量HADOOP_HOME,值是下载的zip包解压的目录,然后在系统变量path里增加$HADOOP_HOME\bin 即可。
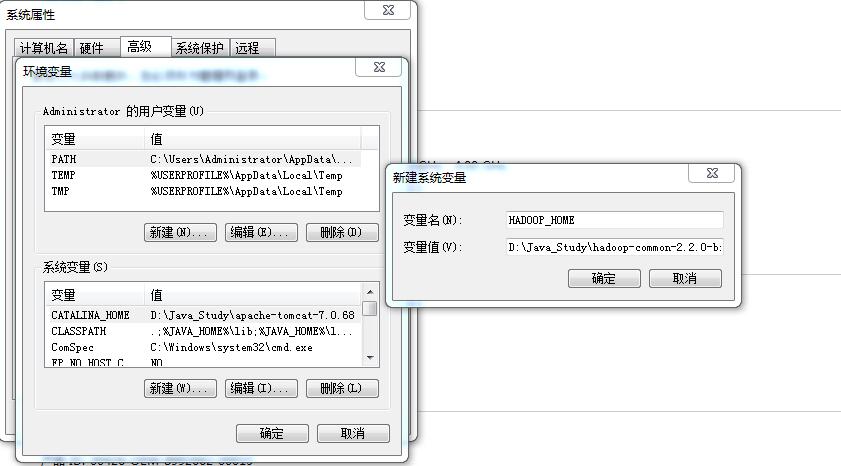
添加“%HADOOP%\bin”到path
再次运行程序,正常执行。
Hadoop:开发机运行spark程序,抛出异常:ERROR Shell: Failed to locate the winutils binary in the hadoop binary path的更多相关文章
- ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
文章发自:http://www.cnblogs.com/hark0623/p/4170172.html 转发请注明 14/12/17 19:18:53 ERROR Shell: Failed to ...
- Spark- ERROR Shell: Failed to locate the winutils binary in the hadoop binary path java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
运行 mport org.apache.log4j.{Level, Logger} import org.apache.spark.rdd.RDD import org.apache.spark.{S ...
- Windows本地运行调试Spark或Hadoop程序失败:ERROR util.Shell: Failed to locate the winutils binary in the hadoop binary path
报错内容 ERROR util.Shell: Failed to locate the winutils binary in the hadoop binary path java.io.IOExce ...
- idea 提示:ERROR util.Shell: Failed to locate the winutils binary in the hadoop binary path java.io.IOException解决方法
Windows系统中的IDEA链接Linux里面的Hadoop的api时出现的问题 提示:ERROR util.Shell: Failed to locate the winutils binary ...
- windows本地调试安装hadoop(idea) : ERROR util.Shell: Failed to locate the winutils binary in the hadoop binary path
1,本地安装hadoop https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/ 下载hadoop对应版本 (我本意是想下载hadoop ...
- ERROR [org.apache.hadoop.util.Shell] - Failed to locate the winutils binary in the hadoop binary path
错误日志如下: -- ::, DEBUG [org.apache.hadoop.metrics2.lib.MutableMetricsFactory] - field org.apache.hadoo ...
- WIN7下运行hadoop程序报:Failed to locate the winutils binary in the hadoop binary path
之前在mac上调试hadoop程序(mac之前配置过hadoop环境)一直都是正常的.因为工作需要,需要在windows上先调试该程序,然后再转到linux下.程序运行的过程中,报Failed to ...
- Windows7系统运行hadoop报Failed to locate the winutils binary in the hadoop binary path错误
程序运行的过程中,报Failed to locate the winutils binary in the hadoop binary path Java.io.IOException: Could ...
- Spark报错:Failed to locate the winutils binary in the hadoop binary path
之前在mac上调试hadoop程序(mac之前配置过hadoop环境)一直都是正常的.因为工作需要,需要在windows上先调试该程序,然后再转到linux下.程序运行的过程中,报 Failed to ...
随机推荐
- 使用 IntraWeb (3) - 页面切换
新建 StandAlone Application 工程后, 再通过 File > New > Other.. > IntraWeb > New Form 添加两个窗体. 然后 ...
- [多问几个为什么]为什么匿名内部类中引用的局部变量和参数需要final而成员字段不用?(转)
昨天有一个比较爱思考的同事和我提起一个问题:为什么匿名内部类使用的局部变量和参数需要final修饰,而外部类的成员变量则不用?对这个问题我一直作为默认的语法了,木有仔细想过为什么(在分析完后有点印象在 ...
- E3-1260L (8M Cache, 2.40 GHz) E3-1265L v2 (8M Cache, 2.50 GHz)
http://ark.intel.com/compare/52275,65728 Product Name Intel® Xeon® Processor E3-1260L (8M Ca ...
- mysql 阿里内核人员
丁奇 http://dinglin.javaeye.com/ 鸣嵩 @曹伟-鸣嵩 (新浪微博) 彭立勋 http://www.penglixun.com/ 皓庭 http://wqtn22.iteye ...
- [转]LRU缓存实现(Java)
LRU Cache的LinkedHashMap实现 LRU Cache的链表+HashMap实现 LinkedHashMap的FIFO实现 调用示例 LRU是Least Recently Used 的 ...
- Cocos2d-x3.1TestCpp之NewRenderTest Demo分析
1.代码构成 VisibleRect.h VisibleRect.cpp AppDelegate.h AppDelegate.cpp HelloWorldScene.h HelloWorldScene ...
- delphi GetKeyState
GetKeyState(VK_CAPITAL) & 0x0001 0x8000 是键有否按下0x0001 是键的翻转状态 var bF1Down: Boolean;begin bF1Down ...
- 【推荐】腾讯android镜像(做Android开发的得好好利用下这个网站,国内的大公司还是可以滴……)
原文地址:http://android-mirror.bugly.qq.com:8080/include/usage.html ☀ Windows I. Open Android SDK Manage ...
- 【ELK】【ElasticSearch】3.es入门基本操作
docker安装elasticSearch步骤 ================================================================== 本篇参考: htt ...
- C++点和箭头操作符用
http://www.cnblogs.com/ManMonth/archive/2013/09/05/3302873.html C++点和箭头操作符用法区别 变量是对象的时候用“.”访问 变量是对象指 ...