写给java程序员的c++与java实现的一些重要细微差别-附完整版pdf学习手册
0、其实常规的逻辑判断结构、工具类、文件读写、控制台读写这些的关系都不大,熟悉之后,这些都是灵活运用的问题。
学习c/c++需要预先知道的一个前提就是,虽然有ANSI C标准,但是每个c/c++编译器的实现在不少实用特性(除了标准库外)上存在着很大的差异,所以最好的方法是先针对某种实现(可参考标准)去,而不是针对ANSI C或者C99或者C11标准去学。比如,vc对c99的标准支持就比较奇葩。比如说,在vc++中,内置的布尔类型或者别名就包括BOOL、bool、_Bool,如下所示:
BOOL boptVal = FALSE;
bool cppbool;
_Bool cBool;
这三都是合法的,而在标准的c99中,只定义了_Bool。
VC++的C++可参见https://msdn.microsoft.com/zh-cn/library/ty9hx077(v=vs.100).aspx
VC++的C可参考https://msdn.microsoft.com/zh-cn/library/fw5abdx6(v=vs.110).aspx
VC++的主要类库可参考https://msdn.microsoft.com/zh-cn/library/52cs05fz(v=vs.100).aspx,其中大部分在https://msdn.microsoft.com/zh-cn/library/59ey50w6(v=vs.100).aspx
VC++ 2010不支持C99下面的几个特性:
- 支持不定长的数组
- 变量声明不必放在语句块的开头
- 除了已有的 __line__、__file__ 以外,增加了 __func__ 得到当前的函数名。
- 不支持_Bool类型。不过在vc++中,从vc++ 5.0开始,内置支持bool类型,占用1个字节,_Bool通过typedef定义的,而不是定义在stdbool.h头文件中。
1、在java中,不支持无符号型基本数据,也就是都是有符号的。如果要得到无符号的值,需要使用更大范围的值做位与,比如byte a = (byte) 234; int i = a; i = a&0xff; 来得到。
在c++中,默认有没有符号跟c++编译器实现有关,不同的编译器可能有不同的行为,同时标准因为制定的时候,目标C就是短小精悍,因此仅仅规定了最小值,而不是明确值,导致不同平台可以自己决定如何实现。如下所示:
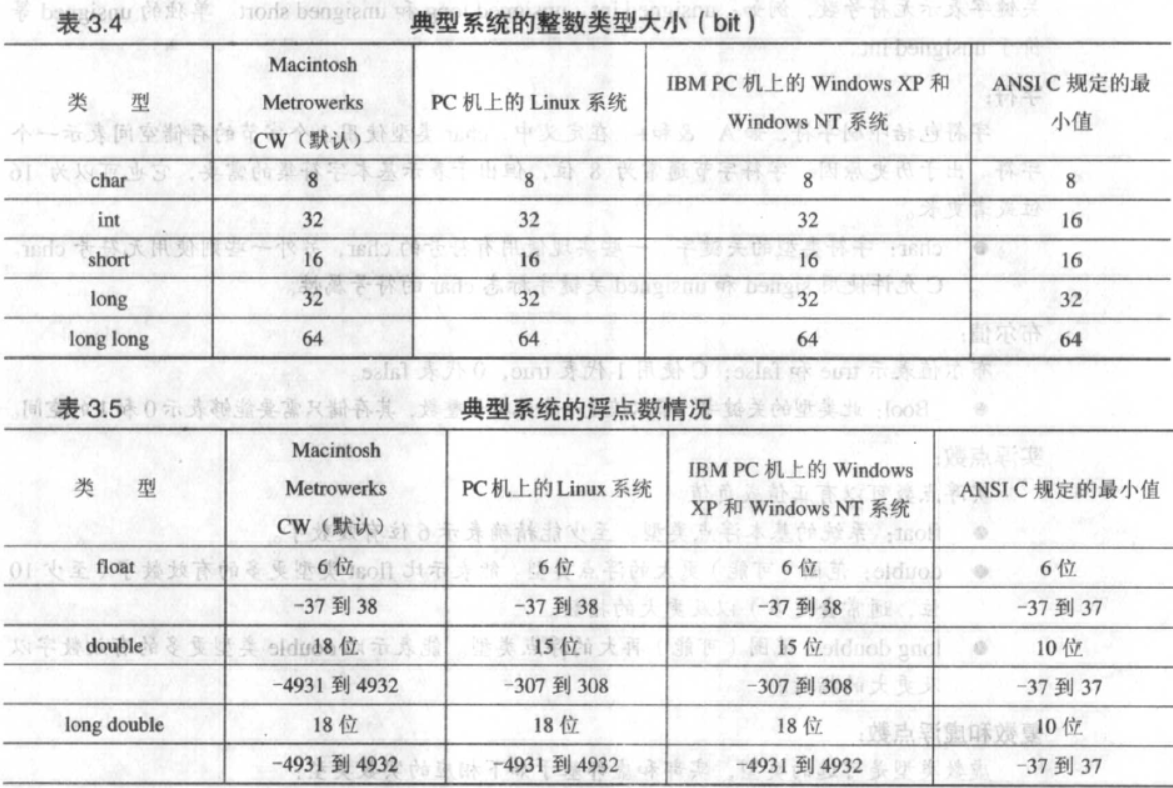
尤其是最常用的int和long。
通常应该显示进行指定确保平台间的通用。还有一点比较注意的是,c++没有byte类型,也可以认为c/c++中的char其实就是java中的byte。c/c++中的char/wchar_t对应java中的char,取决于他们是单字节字符还是多字节字符。为此,标准定义了一个inttypes.h头文件,其中定义了平台无关的数据类型别名,比如int32_t。VC在basetsd.h定义了类似的类型别名,msinttypes.h提供了兼容的别名。
2、在c++中,char占一个字节,这样的话很多字符比如中文就没法存储在一个char中,这样就需要使用wchar_t。在java中,字符天然就是unicode表示,所以char就天然的可以保持人类理解的char。
所以,对于非西方国家来说,wchar_t是个使用极为频繁的类型,如果将中文存储在char中,会导致溢出而出现不可预期的字符如乱码。
其次,因为在内部,任何的字符都是存储为数字编码,所以要在c++中输出wchar_t类型的值,还必须显示告诉它要怎么显示,比如:
char sc = '测';
wchar_t wsc = L'测';
wchar_t wsca[] = L"大中华区";
cout << sc << "\n";
wcout.imbue(locale("chs"));
wcout << wsc << "\n";
在java中,因为原生就是当做unicode表示,所以就没有了这个必要。cout用于处理单字节字符,wcout对应于宽字节字符。
3、在java中,string的使用是如此的频繁,以至于对于需要字符串的地方,几乎没有人会去使用char[]数组。而在c++中,有大量的程序其实使用标准c而非c++的语法,以至于不得不在这两者间来回,以'\0'结尾的char[]等价于string,反之就不是(在判断string长度的时候,这一点必须考虑到)。比如cout就是以'\0'作为结束的标志,这对于新手来说,char[]和string的关系和转换必须足够的重视。虽然可以用char str[] = "abc";进行初始化。但后续要修改还是要一个个下表进行修改,比如如下:
char st[] = "abc";
st[] = '';
而不能st = "bcd"; 也不能st = another_st; --因为在c++中,数组(array是标准库里面的类型)不是对象,而在java中,数组也是对象,这是允许的。
如果确定在c++编译器下运行的话,应该用string类型的字符串(但是得注意,毕竟string等属于stl的东西,性能上可能会有一定的下降,这估计也是个重要的原因,所以实际主流仍然是char[]),string str = "abc"; str = "abcd"; str = str + L"测试"; 这样可以省去不必要繁琐的细节。但是用到string还得注意,c++有string和wstring之分,它分别对应了char和wchar_t的差别。总之,如果说在java中,绝大部分开发人员不用关心编码的话,在c++下,绝大部分开发人员必须关心编码以及对应的SDK。
此外,判断长度的时候,对于以字符串初始化的数组,strlen仅考虑实际的字符长度,而sizeof则数组的长度。比如:
char st[] = "aaaaaaabc";
st[] = '';
cout << st << "\n"; cout << strlen(st) << "\n";
cout << sizeof st << "\n";
输出:
9
10
就字符串来说,通常情况下,无论对于一些临时需要的字符串上下文变量亦或是结构体中的成员变量,其长度都是根据不同的请求而不同,所以实际中真正的使用固定长度的数组写死是很少的,不少情况下都是根据实际的大小动态申请内存,赋值给临时变化或者成员变量,然后用完的时候进行free,并不是教科书中使用的很大一部分固定长度的数组。
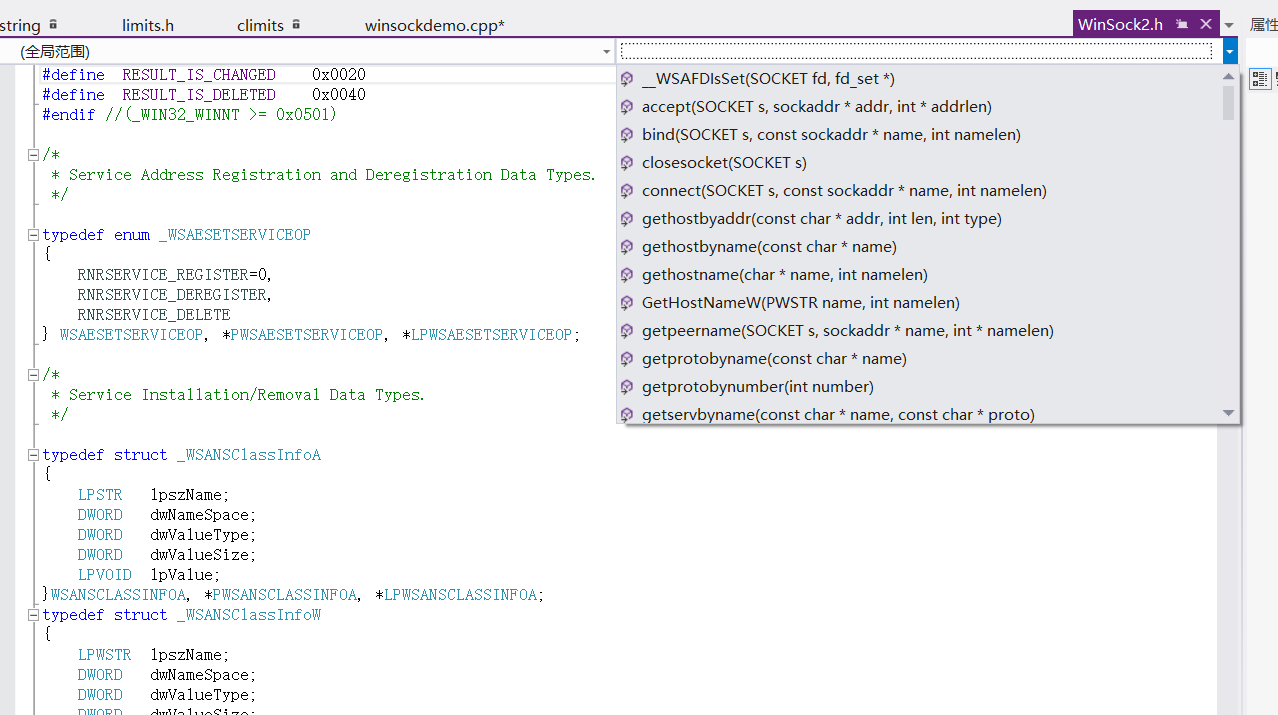
PS:从IDE的角度来说,使用原生类型和OO的差别在于前者没有上下文信息,后者具有上下文信息,意味着使用前者开发完全取决于对标准库的熟悉,而OO的话,IDE有足够的上下文进行代码提示从而一定程度上降低了开发要求,从开发的角度来说,这又像是apache提供的各种工具类或者数据库提供的函数亦或是运维管理员天天打交道的命令,你必须去熟悉API。通常之所以觉得c++难,一种原因通常是隔行如隔山,习惯了java的各种ide后,c++的ide不怎么熟悉,要是ue打开,无法各种智能跳转和hint,那要想熟悉可想而知。。。如果有好的IDE帮助,在任何代码位置,可以快速跳转到定义,确定对象来自于标准类库、三方类库或者应用公用库,进一步得到完整的上下文信息,再通过API注释,很快能够猜测的八九不离十。就vs而言,如果要查看一个头文件中的所有定义,可如下:

查看函数原型:
4、名称空间,简单的理解就是java的包,你可以在import之后直接调用某个类的方法,也可以通过全路径的引用。只不过c++除了include外,还需要加一个using namespace XXX而已,纯c则没有必要。还需要注意的是,在java中,无论class/还是interface都可以import,在c/c++中,一般只能import .h头文件。一般来说,每个c编译器或者IDE都有自己搜索头文件的约定,ansi c无明文规定。
5、在java中,除了创建pojo和在某些地方使用帮助变量会用原生类型外,大部分情况下打交道的就是object了,因为pojo通常代表着领域中的实体。虽然C++是oo语言,但是前文提过,绝大部分的c++程序其实很大一部分代码都是标准c代码(所以,在生产系统中,可以发现通常是绝大部分c代码夹杂着偶小小部分c++ oo代码。比如redis用c写的,mysql用c++写的,postgresql用c写的。)所以,在c/c++中,struct可能是使用最频繁的类型之一了,自然也是极为重要。
java定义类用的是class ObjName。在c++中,一样要先定义struct。和class一样,你可以在方法内部定义结构,也可以在文件级别独立定义结构,唯一的差别只是可见范围,相当于内部类的性质。
struct NodeInfo
{
int id;
char name1[];
}; int main() {
NodeInfo nodeInfo = {
,
"name1"
};
cout << nodeInfo.id << "\n";
struct NodeInfo
{
int id;
char name[];
}; struct NodeInfo cNodeInfo; //c风格
cNodeInfo.id = ;
cNodeInfo.name[] = '';
cout << nodeInfo.id << "\n"; NodeInfo cppNodeInfo; //c++风格,强调的是这是一种新的类型
不同于对象的构造器,如果在声明变量时没有初始化结构,后面只能一个个成员赋值,这和不使用getter/setter,直接用public字段性质类似。
既然定义了结构体,通常是常用的领域对象,应该跟oo一样的思路,声明在文件级别,这样可以全局公用,变量以及函数同理。
结构体变量可以直接赋值,而且是值拷贝,比较接近于java中Object.clone(),试具体实现而定。
在定义结构体的时候甚至可以直接声明变量,如下:
struct NodeInfo
{
int id;
char name1[];
} g_nodeInfo1,g_nodeInfo2; //典型语法糖
在c++的实现中,结构体还可以有成员函数,这通常来说属于OO的范畴了。通常,生产中用的并不多。
6、基本类型、结构、数组之后,从数据结构的角度来说,重要的就是他们的组合了。毕竟,在实际的系统中,集合的处理占了很大一部分比例。他们中,又以结构数组为主。
NodeInfo nodeInfoA[];
nodeInfoA[].id = ;
nodeInfoA[].id = ;
实际上,这种用法在生产系统中并不多,因为在绝大部分情况下,无法提前预知会有几个元素。所以,通常需要动态确定,而标准c里面没有提供类似于java list的集合类。
7、上面说到数组其实并不是那么的实用,这个时候就要讲到c/c++编程中最重要的一个部分,内存的动态分配、释放和操作这些内存的指针了。我们应该说,很多c++教科书里面那基本抄写c参考手册的组织真是不合理,先从简单变量的地址开始讲解指针绝对是个没脑子的想出来的,很明显,应该从分配和释放内存以及引用传递、值传递、函数指针开始(至于动态分配还是静态分配无所谓,但必须找到足够合适的上下文阐明不得不使用指针的场景),讲解指针才是合乎逻辑的。因为实际的系统任何时候内存需求都是动态变化的,这才是核心,否则都静态确定,能用得着指针?
在c/c++中,动态分配内存有两种方式,malloc/free库函数或new/delete操作符。其实用哪个不重要的,重要的是不要让指针指向不确定的地址,也就是:
int *bad_pt; -- 默认这个时候指针指向哪里是不确定的,取决于bad_pt中当前的值指向哪里,确保动态指针通过malloc初始化是非常重要的
int *good_pt = new int;
以及及时释放指向的内存块:
delete bad_pt;
malloc与free是C++/C语言的标准库函数,new/delete是C++的运算符。它们都可用于申请动态内存和释放内存。
对于非内部数据类型的对象而言,光用maloc/free无法满足动态对象的要求。对象在创建的同时要自动执行构造函数,对象在消亡之前要自动执行析构函数。由于malloc/free是库函数而不是运算符,不在编译器控制权限之内,不能够把执行构造函数和析构函数的任务强加于malloc/free。
大部分的现行c/c++代码都使用malloc和free。
操作普通类型的指针变量并不复杂,重点是数组指针(主要是涉及遍历),结构体指针的操作。
动态创建数组:
int *bad_pt;
int *good_pt = new int;
delete good_pt; int *arrayPt = new int[]; // 指向第一个元素的地址
arrayPt[] = ; // 可以把指向数组的指针当数组使用,在内部,c/c++就是把数组当指针处理的
arrayPt[] = ;
arrayPt = arrayPt + ; //现在指向第二个元素,一般不建议这么用,不然delete的时候还得回去
arrayPt[] = ; //指向第三个元素
arrayPt = arrayPt - ;
delete [] arrayPt;
需要注意的一点是对于我们如此常用的arraylist,在c99标准中是定义了可变长度数组的,而实际中,在支持的c99 的编译器下运行如gcc vc不支持c99标准中的c语言变长数组,windows有时候对于开发者来说就是个奇葩。
动态创建结构体:
NodeInfo * node_info_pt = new NodeInfo;
node_info_pt->id = ;
node_info_pt->name[] = '';
(*node_info_pt).name[] = ''; NodeInfo *node_info = &cNodeInfo; //通常调用方法的时候都是这种用法,因为结构体按值传递
node_info->id = ; //通过结构指针访问属性
node_info->name[] = 's';
delete node_info_pt; NodeInfo *node_info_arr = new NodeInfo[]; //指向结构体数组的指针
node_info_arr[].id = ;
(node_info_arr + )->id = ;
malloc:
int* p = (int *) malloc ( sizeof(int) * 100 );
free:
free (p);
详细可参考:http://www.cplusplus.com/reference/cstdlib/malloc/。
c函数调用中,经常不通过返回值的方式进行,而是通过指针变量进行交互,常用的方式中,包括:传递指针变量,传递变量的地址。
&用于获取变量的地址(在OO的C++中,传对象引用会非常的普遍,在面向过程的c中,则没有那么的频繁),*用于获取指针指向的变量值,至于什么时候应该定义变量,传递变量的地址,什么时候又应该定义指针,并传递指针,这跟函数的实现方式有关系,从技术本身上而言,两者可以互换,比如对于getsockopt获取socket选项的函数,我们可以使用下列两种方式得到其值:
int optlen = ;
int optval = ;
sock = WSASocket(iFamily, iType, iProtocol, NULL, , dwFlags);
getsockopt(sock,SOL_SOCKET,SO_RCVBUF,(char*)&optval,&optlen);
或者:
int *optptr = new int;
int *valptr = new int;
memset(valptr,,sizeof(int));
*optptr = sizeof(int);
getsockopt(sock,SOL_SOCKET,SO_RCVBUF,(char*)valptr,optptr);
通常来说,内存的使用是谁是主动者谁负责分配和释放,库函数通常要求传递一个包含了最小长度的内存的指针,然后进行填充,顺便有可能返回或者通过指针告诉调用者实际的长度。
就函数调用而言,数组和指针可以说是等价的,下面的原型是等价的。

但是在函数内部,声明是数组时,pt++是不合法的,而声明是指针时,这是常用的。至于调用的时候是数组传递给指针声明还是反过来,无所谓,当前的马甲决定了可以执行什么操作。
讲到指针,就不得不讲指向指针的指针,指针数组。
7、函数和函数指针。c因为没有原生的层级组织方式,所以各种函数列表的管理更显得重要,比如可以使用功能号的概念。
函数分为两块,函数定义以及函数原型,简单地说,函数原型就相当于java接口,至于运行时有没有实现那是另外一回事。头文件就是典型的例子,其中包含了ANSI标准库的原型(他只是开发、编译时需要)。对于全局性的函数,应该首先在头文件中定义函数原型。
定义原型和java类似,包含声明不含实现。比如:
int calc(); int calc1_bad(int arr[]); int calc1_bad(const int arr[]); --不可变数组
c++建议将程序的整体结构包含在main中,并放在最前面。需要注意的是,因为数组名逻辑上等价于指针,所以默认情况下被调用函数可以修改传入的数组。因为通过指针通常无法知道数组的元素数即无法使用sizeof,所以通常的用法是指定数组的长度:
int calc1(const int arr[],int len);
传递结构以及结构指针,就实际可用性而言,这是使用指针的第二个很普遍的场景。因为结构是传值,所以一般都是传递结构指针,如下:
int transfer_strc(NodeInfo *nodeInfo);
传递指向数组的指针而不是数组的原因在于,数组可能会很大,而是用指针可以避免不必要的拷贝。
函数指针说得简单点就是个回调函数的入口。在jquery/事件编程中这是很常见的场景,对于系统灵活性而言,这是非常重要的。
在java中,函数指针就相当于传递接口。在jquery中可以传递函数或者匿名函数块。同理,在c++中,函数指针的步骤是:
1、声明函数指针;
简单地说,就是使用函数指针名代替函数声明即可:
int transfer_strc(NodeInfo *nodeInfo);
int (*pf) (NodeInfo*);
就常用而言,难度一般在于复杂的签名,如:
int call_func_func(int (*pf) (NodeInfo*));
维护现有代码时,有时候需要知道(*pf)到底是谁???
2、定义指向的地址(获取函数的地址);
只要函数名,不要括号和参数即可,否则就是函数调用了。比如:test_callback_func(be_called_func)
int (*pf) (NodeInfo*);
pf = be_called_func;
3、使用函数指针调用函数。
int abc = (*pf)(参数);
8、#defined、typedef。
预处理器在c/c++中是非常常用的工具,几乎任何的程序都会很大程度的时候用它。
使用极为广泛的另一点宏定义和别名定义,这在java中并不存在直接的API,你会发现几乎任何类库或者API里面都大量的使用了各种宏定义,比如:

#defined用于定义宏,简单地说就是快捷方式或者别名。
在大规模的开发过程中,特别是跨平台和系统的软件里,define最重要的功能是条件编译。
就是:
#ifdef WINDOWS
......
......
#endif
#ifdef Linux
......
......
#endif
跟java不同,c++中不能重复导入,所以在头文件中使用#ifdef和#ifndef是非常重要的,可以防止双重定义的错误。
在C/C++语言中,typedef常用来定义一个标识符及关键字的别名,它是语言编译过程的一部分。
#defined常用于定义类型别名之外的用途,一般来说,宏定义纯粹就是替换。typedef用于定义类型别名,并且typedef并不是纯粹的替换,特别是在涉及到指针相关的概念时,这也是很多代码绕来绕去的原因,直接替换就不正确了。
9、static,extern。static声明文件内部全局,非应用程序全局,默认是全局变量,类似于private类变量。extern声明变量定义在其他地方,通常声明应用全局,应定义在头文件中。如果说java文件之间的协作通过接口来组装的话,那c/c++文件间就是通过头文件进行黏合。对于标准库的头文件也是一样的,设计者认为相关的一组函数会放在同一个头文件中。
10、c/c++的另一点难处在于,不知出于什么原因,大量的头文件中中并没有说明这个struct以及函数原型的含义,以至于每次都要参考手册。如下:

只有签名,没有说明。
11、c/c++中常见的宏定义含义及以及参考:
__stdcall:Windows API默认的函数调用协议,vc下基本上都是这了。 Windows上使用dumpbin工具查看函数名字修饰。
__cdecl:C/C++默认的函数调用协议。
__fastcall:适用于对性能要求较高的场合。
extern "C" {}
extern "C" {
#endif
#ifndef _NLSCMP_DEFINED
#define _NLSCMPERROR 2147483647 /* currently == INT_MAX */
#define _NLSCMP_DEFINED
#endif
C++保留了一部分过程式语言的特点,因而它可以定义不属于任何类的全局变量和函数。但是,C++毕竟是一种面向对象的程序设计语言,为了支持函数的重载,C++对全局函数的处理方式与C有明显的不同。
extern "C"的主要作用就是为了能够正确实现C++代码调用其他C语言代码。加上extern "C"后,会指示编译器这部分代码按C语言的进行编译,而不是C++的。由于C++支持函数重载,因此编译器编译函数的过程中会将函数的参数类型也加到编译后的代码中,而不仅仅是函数名;而C语言并不支持函数重载,因此编译C语言代码的函数时不会带上函数的参数类型,一般之包括函数名。
比如说你用C 开发了一个DLL 库,为了能够让C ++语言也能够调用你的DLL输出(Export)的函数,你需要用extern "C"来强制编译器不要修改你的函数名。
而在C语言的头文件中,对其外部函数只能指定为extern类型,C语言中不支持extern "C"声明,在.c文件中包含了extern "C"时会出现编译语法错误。
在windows c++中,很多的函数原型可以看到声明了 FAR PASCAL,其含义可参见http://blog.csdn.net/gucas2008/article/details/2187992,当代处理器和OS基本可以忽略,其定义在很多头文件中,比如:

12、基本上c++代码中,有些是C++的驼峰式风格,有些是c的下划线风格,必须习惯。
13、很重要、也是导致c/c++学习难度大的一点在于各种数据类型之间的转换,初始化,传各种指针变量、变量的指针地址等等。
比如,经常代码中会有如下声明:
typeName *pt = NULL;
NULL是C++从C语言继承下来的预处理器变量,在cstdlib头文件中定义,值为0,。代表一个空指针,由系统保证空指针不指向任何实际的对象或者函数。 反过来说,任何对象或者函数的地址都不可能是空指针。”
就面向对象的特性来说,java中对象的传递(string除外),传递的是对象的引用,在c++中,实现上则是传递的对象的深拷贝,如果要实现引用传递,需要函数原型transferObjRef(Obj&),使用的时候跟普通对象没有区别,同java不同,c++接口定义中参数名可以省去。
14、c/c++中,通常用的类似log4j/log4net一样的方式不多,大都还是printf的方式,它和sprintf/fsprintf一样,都是为了用于格式化,跟java中MessageFormat类似,因为没有自成的toString()概念,所以printf的格式必须很了解。
15、现实的应用通常都是由大量的源码文件+头文件组成的,因此好的IDE是很有必要的,就如现在开发java,几乎没有人会直接用javac去编译,用记事本写代码,但是如同eclipse/idea均有不同的风格,vs和codeblock也不同。
16、常用头文件。
ctype.h:其中包含常用的判断比如字符类型的函数,类似apache commons相关的类库。
17、编译器的种类,常用的编译器有unix c编译器(主要在solaris、freebsd下),linux gcc编译器,visual c++编译器。vs通常以工程单位进行编译,而不是文件,意味着所有.c文件必须包含在工程中,而不包括头文件。在java中,虽有oracle jdk和ibm/hp各自的jdk,但基本上都是跟着JLS走的,而JLS还是很规范的,没那么多自由度。c这有点跟HTML/JS/CSS规范之于各种浏览器的实现。还有一点,c直接编译成了机器码,以至于通过接口,我们无法直接看到内部的实现,这一点不同于java和解释性语言,调用不正确的时候,我们可以看一下源码就知道问题可能是什么了。
18、预定义宏。
__DATE__
__FILE__
__LINE__
__STDC__
__TIME__
19、编译与链接。同java一样,在命令行进行编译的时候,可能需要指定各种javac编译选项,比如指定各种classpath以及jar的目录等等。只不过java开发来说,只需要编译成字节码就可以了,c/c++还需要将.o/obj链接成可执行程序,此时还会增加一个步骤,通常用IDE编译的话,熟悉之后可以自动链接,对于开源的项目,通常我们要download源码,自行编译configure,make,make install。
20、类库,同java一样,通常会引用第三方的类库和jvm的类库,只不过在java中,通常三方库打包成jar,运行时由classloader加载,相当于只有动态加载的概念。在c/c++中,分为动态库和静态库两种。windows下分别是dll和lib结尾,linux下则是so和a结尾。具体的用法可以参考http://www.cnblogs.com/skynet/p/3372855.html。
21、最后,最好的方式不是写个DEMO或者教科书中的例子,而是实现比较实际的功能,比如实现现有java/python的某个功能点,这么一折腾下来,很多问题就都能理解了。
最最最最最最最需要转换思路的一点是,作为使用最为频繁的字符串,在java中,除了socket和框架编程外,几乎所有人都会使用String类型,而在c++中,几乎所有的人都倾向于使用各种char变种指针,这一点导致的cpp代码与纯OO代码的差别估计占据了很大一部分的比例。
写给java程序员的c++与java实现的一些重要细微差别-附完整版pdf学习手册的更多相关文章
- Java程序员进阶路线-高级java程序员养成
1. 引言 搞Java的弟兄们肯定都想要达到更高的境界,用更少的代码解决更多的问题,用更清晰的结构为可能的传承和维护做准备.想想当初自己摸着石头过河,也看过不少人介绍的学习路线,十多年走过来多少还是有 ...
- Java程序员面试宝典1 ---Java基础部分(该博文为原创,转载请注明出处)
(该博文为原创,转载请注明出处 http://www.cnblogs.com/luyijoy/ by白手伊凡) 1. 基本概念 1) Java为解释性语言,运行过程:程序源 ...
- 十年Java程序员-带你走进Java虚拟机-类加载机制
类的生命周期 1.加载 将.class文件从磁盘读到内存 2.连接 2.1 验证 验证字节码文件的正确性 2.2 准备 给类的静态变量分配内存,并赋予默认值 2.3 解析 类装载器装入类所引用的其它所 ...
- 写给java程序员的c++与java实现的一些重要细微差别
0.其实常规的逻辑判断结构.工具类.文件读写.控制台读写这些的关系都不大,熟悉之后,这些都是灵活运用的问题. 学习c/c++需要预先知道的一个前提就是,虽然有ANSI C标准,但是每个c/c++编译器 ...
- java程序员面试宝典之——Java 基础部分(1~10)
基础部分的顺序:基本语法,类相关的语法,内部类的语法,继承相关的语法,异常的语法,线程的语法,集合的语法,io 的语法,虚拟机方面的语法. 1.一个".java"源文件中是否可以包 ...
- 写给Java程序员的Java虚拟机学习指南
大家好,我是极客时间<深入拆解Java虚拟机>作者.Oracle Labs高级研究员郑雨迪.有幸借这个专题的机会,能和大家分享为何Java工程师要学Java虚拟机?如何掌握Java虚拟机? ...
- 工作5年的Java程序员,才学会阅读源码,可悲吗?
最近一位5年开发经验的群友与我聊天 他说:最近慢慢的尝试去看spring的源码,学习spring,以前都只是会用就行了,但是越是到后面,发现只懂怎么用还不够,在面试的时候经常被问到一些开源框架的源码问 ...
- java程序员从小工到专家成神之路(2020版)
目录 必须掌握的基础知识 1. Git & Github 2. Linux 3. 数据结构和算法 4. HTTP / HTTPS 5. 设计模式 6. 计算机原理 java学习之路 1. 工具 ...
- 推荐给 Java 程序员的 7 本书
< Java 编程思想> 适合各个阶段 Java 程序员的必备读物.书中对 Java 进行了详尽的介绍,与其它语言做了对比,解释了 Java 很多特性出现的原因和解决的问题.初学者可以通过 ...
随机推荐
- 通过 Kubernetes 和容器实现 DevOps
https://mp.weixin.qq.com/s/1WmwisSGrVyXixgCYzMA1w 直到 Docker 的出现(2008 年),容器才真正具备了较好的可操作性和实用性.容器技术的概念最 ...
- logstash自己的日志保存到文件中:log4j2.properties
status = error dest = err name = PropertiesConfig property.filename = /gwlog/data/logstash/logs appe ...
- Python Cookbook 笔记--12章并发编程
<Python Cookbook(第3版)中文版> 1.队列queue的有些方法是线程不安全的,在多线程中最好别用 2.需要限制一段代码的并发访问量时,用信号量.不要把信号量当做普通的锁来 ...
- Java GUI程序设计
在实际应用中,我们见到的许多应用界面都属于GUI图形型用户界面.如:我们点击QQ图标,就会弹出一个QQ登陆界面的对话框.这个QQ图标就可以被称作图形化的用户界面. 其实,用户界面的类型分为两类:Com ...
- (3.13)mysql基础深入——mysql日志分析工具之mysqlsla【待完善】
(3.13)mysql基础深入——mysql 日志分析工具之mysqlsla 关键字:Mysql日志分析工具.mysqlsla 常用工具 [1]mysqldumpslow:官方提供的慢查询日志分析工具 ...
- mysql 数据表操作 存储引擎介绍
一 什么是存储引擎? 存储引擎就是表的类型. mysql中建立的库===>文件夹 库中建立的表===>文件 现实生活中我们用来存储数据的文件有不同的类型,每种文件类型对应各自不同的处理机制 ...
- OC convertRect
举个例子: redView = [[UIView alloc]initWithFrame:CGRectMake(50, 100, 100, 100)]; redView.backgroundColor ...
- vertx读取配置文件,获得端口号
1:在src/conf目录下创建conf.json { } 2:创建Verticle, config().getInteger("http.port", 8080),将会读取配置文 ...
- Mybatis的多对多映射
一.Mybatis的多对多映射 本例讲述使用mybatis开发过程中常见的多对多映射查询案例.只抽取关键代码和mapper文件中的关键sql和配置,详细的工程搭建和Mybatis详细的流程代码可参见& ...
- Tesseract-OCR 训练过程 V3.02
软件: jTessBoxEditor Version 0.9 (30 April 2013) Tesseract-OCR win32 v3.02 with Leptonica 训练步骤: 1. ...