[spark 快速大数据分析读书笔记] 第一章 导论
【序言】
Spark 基于内存的基本类型 (primitive)为一些应用程序带来了 100 倍的性能提升。Spark 允许用户程序将数据加载到 集群内存中用于反复查询,非常适用于大数据和机器学习。
目前,Spark 已经超越 Spark 核心,发展到了 Spark streaming、SQL、MLlib、 GraphX、SparkR 等模块。
Spark 对曾经引爆大数据产业革命的 Hadoop MapReduce 的改进主要体现在这几个方面:
1、Spark 速度更快;
2、Spark 丰富的 API 带来了更强大的易用性;
3、 Spark 不单单支持传统批处理应用,更支持交互式查询、流式计算、机器学习、图计算等各种应用,满足各种不同应用场景下的需求。而在 Spark 出现之前,我们需要学习各种各样的引擎来分别处理这些需求。
【目标】
搭建一个 Spark 集群
使用 Spark shell
何编写 Spark 应用程序来解决需要并行处理的问题
【简介】
Spark 是一个用来实现快速而通用的集群计算的平台。
在速度方面,Spark 扩展了广泛使用的 MapReduce 计算模型,而且高效地支持更多计算模式,包括交互式查询和流处理。在处理大规模数据集时,速度是非常重要的。速度快就意 味着我们可以进行交互式的数据操作,否则我们每次操作就需要等待数分钟甚至数小时。 Spark 的一个主要特点就是能够在内存中进行计算,因而更快。不过即使是必须在磁盘上 进行的复杂计算,Spark 依然比 MapReduce 更加高效。 总的来说,Spark 适用于各种各样原先需要多种不同的分布式平台的场景,包括批处理、 迭代算法、交互式查询、流处理。通过在一个统一的框架下支持这些不同的计算,Spark 使我们可以简单而低耗地把各种处理流程整合在一起。而这样的组合,在实际的数据分析 过程中是很有意义的。不仅如此,Spark 的这种特性还大大减轻了原先需要对各种平台分 别管理的负担。 Spark 所提供的接口非常丰富。除了提供基于 Python、Java、Scala 和 SQL 的简单易用的 API 以及内建的丰富的程序库以外,Spark 还能和其他大数据工具密切配合使用。例如, Spark 可以运行在 Hadoop 集群上,访问包括 Cassandra 在内的任意 Hadoop 数据源。
【一个大一统的软件栈】
Spark 项目包含多个紧密集成的组件。Spark 的核心是一个对由很多计算任务组成的、运行 在多个工作机器或者是一个计算集群上的应用进行调度、分发以及监控的计算引擎。由于 Spark 的核心引擎有着速度快和通用的特点,因此 Spark 还支持为各种不同应用场景专门 设计的高级组件,比如 SQL 和机器学习等。这些组件关系密切并且可以相互调用,这样你 就可以像在平常软件项目中使用程序库那样,组合使用这些的组件。
各组件间密切结合的设计原理有这样几个优点。首先,软件栈中所有的程序库和高级组件 都可以从下层的改进中获益。比如,当 Spark 的核心引擎新引入了一个优化时,SQL 和机 器学习程序库也都能自动获得性能提升。其次,运行整个软件栈的代价变小了。不需要运 行 5 到 10 套独立的软件系统了,一个机构只需要运行一套软件系统即可。这些代价包括 系统的部署、维护、测试、支持等。这也意味着 Spark 软件栈中每增加一个新的组件,使 用 Spark 的机构都能马上试用新加入的组件。这就把原先尝试一种新的数据分析系统所需 要的下载、部署并学习一个新的软件项目的代价简化成了只需要升级 Spark。
最后,密切结合的原理的一大优点就是,我们能够构建出无缝整合不同处理模型的应用。 例如,利用 Spark,你可以在一个应用中实现将数据流中的数据使用机器学习算法进行实 时分类。与此同时,数据分析师也可以通过 SQL 实时查询结果数据,比如将数据与非结 构化的日志文件进行连接操作。不仅如此,有经验的数据工程师和数据科学家还可以通过 Python shell 来访问这些数据,进行即时分析。其他人也可以通过独立的批处理应用访问这 些数据。IT 团队始终只需要维护一套系统即可。
Spark 的各个组件如图所示,下面来依次简要介绍它们。
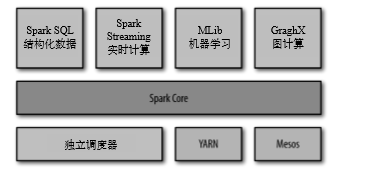
1、Spark Core
Spark Core 实现了 Spark 的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core 中还包含了对弹性分布式数据集(resilient distributed dataset,简 称 RDD)的 API 定义。RDD 表示分布在多个计算节点上可以并行操作的元素集合,是 Spark 主要的编程抽象。Spark Core 提供了创建和操作这些集合的多个 API。
2、Spark SQL
Spark SQL 是 Spark 用来操作结构化数据的程序包。通过 Spark SQL,我们可以使用 SQL 或者 Apache Hive 版本的 SQL 方言(HQL)来查询数据。Spark SQL 支持多种数据源,比 如 Hive 表、Parquet 以及 JSON 等。除了为 Spark 提供了一个 SQL 接口,Spark SQL 还支 持开发者将 SQL 和传统的 RDD 编程的数据操作方式相结合,不论是使用 Python、Java 还 是 Scala,开发者都可以在单个的应用中同时使用 SQL 和复杂的数据分析。通过与 Spark 所提供的丰富的计算环境进行如此紧密的结合,Spark SQL 得以从其他开源数据仓库工具 中脱颖而出。Spark SQL 是在 Spark 1.0 中被引入的。 在 Spark SQL 之前,加州大学伯克利分校曾经尝试修改 Apache Hive 以使其运行在 Spark 上,当时的项目叫作 Shark。现在,由于 Spark SQL 与 Spark 引擎和 API 的结合更紧密, Shark 已经被 Spark SQL 所取代。
3、Spark Streaming
Spark Streaming 是 Spark 提供的对实时数据进行流式计算的组件。比如生产环境中的网页 服务器日志,或是网络服务中用户提交的状态更新组成的消息队列,都是数据流。Spark Streaming 提供了用来操作数据流的 API,并且与 Spark Core 中的 RDD API 高度对应。这 样一来,程序员编写应用时的学习门槛就得以降低,不论是操作内存或硬盘中的数据,还 是操作实时数据流,程序员都更能应对自如。从底层设计来看,Spark Streaming 支持与 Spark Core 同级别的容错性、吞吐量以及可伸缩性。
4、MLlib
Spark 中还包含一个提供常见的机器学习(ML)功能的程序库,叫作 MLlib。MLlib 提供 了很多种机器学习算法,包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据 导入等额外的支持功能。MLlib 还提供了一些更底层的机器学习原语,包括一个通用的梯 度下降优化算法。所有这些方法都被设计为可以在集群上轻松伸缩的架构。
5、GraphX
GraphX 是用来操作图(比如社交网络的朋友关系图)的程序库,可以进行并行的图计算。 与 Spark Streaming 和 Spark SQL 类似,GraphX 也扩展了 Spark 的 RDD API,能用来创建 一个顶点和边都包含任意属性的有向图。GraphX 还支持针对图的各种操作(比如进行图分割的 subgraph 和操作所有顶点的 mapVertices),以及一些常用图算法(比如 PageRank 和三角计数)。
6、集群管理器
就底层而言,Spark 设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计 算。为了实现这样的要求,同时获得最大灵活性,Spark 支持在各种集群管理器(cluster manager)上运行,包括 Hadoop YARN、Apache Mesos,以及 Spark 自带的一个简易调度 器,叫作独立调度器。如果要在没有预装任何集群管理器的机器上安装 Spark,那么 Spark 自带的独立调度器可以让你轻松入门;而如果已经有了一个装有 Hadoop YARN 或 Mesos 的集群,通过 Spark 对这些集群管理器的支持,你的应用也同样能运行在这些集群上。第 章会详细探讨这些不同的选项以及如何选择合适的集群管理器。
【应用场景】
1、数据分析
Spark shell 通过提供 Python 和 Scala 的接 口,使我们方便地进行交互式数据分析。 Spark SQL 也提供一个独立的 SQL shell,我们可以在这个 shell 中使用 SQL 探索数据,也可以通过标准的 Spark 程序或者 Spark shell 来进 行 SQL 查询。机器学习和数据分析则通过 MLlib 程序库提供支持。 另外,Spark 还能支持 调用 R 或者 Matlab 写成的外部程序。
2、数据处理
Spark 为开发用于集群并行执行的程序提供了一条捷径。
通过封装,Spark 不需要开发者关注如何在分布式系统上编程这样的复杂问题,也无需过多关注网络通信和程序容错性。
Spark 已经为工程师提供了足够的接口来快速实现常见的任务,以及对应用进行监视、审查和性能调优。
其 API 模块化的特性(基于传递分布式的对象集)使得利用 程序库进行开发以及本地测试大大简化。
【简史、版本和发布】
Spark 从一开始就是为交互式查询和迭代算法设计的,同时还支持内存式存储和高效的容错机制。
2014 年 5 月,Spark 1.0 正式发布。
【存储层次】
Spark 不仅可以将任何 Hadoop 分布式文件系统(HDFS)上的文件读取为分布式数据集, 也可以支持其他支持 Hadoop 接口的系统,比如本地文件、亚马逊 S3、Cassandra、Hive、 HBase 等。 我们需要弄清楚的是,Hadoop 并非 Spark 的必要条件,Spark 支持任何实现 了 Hadoop 接口的存储系统。 Spark 支持的 Hadoop 输入格式包括文本文件、SequenceFile、 Avro、Parquet 等。
[spark 快速大数据分析读书笔记] 第一章 导论的更多相关文章
- [Spark快速大数据分析]阅读笔记
第2章 Spark分布式执行涉及的组件 每个Spark应用都由一个驱动程序来发起集群上的各种并行操作,驱动程序通过一个SparkContext对象访问Spark:驱动程序管理多个执行器节点,可以用Sp ...
- 《Spark快速大数据分析》—— 第六章 Spark编程进阶
这章讲述了Spark编程中的高级部分,比如累加器和广播等,以及分区和管道...
- 《Spark快速大数据分析》—— 第五章 数据读取和保存
由于Spark是在Hadoop家族之上发展出来的,因此底层为了兼容hadoop,支持了多种的数据格式.如S3.HDFS.Cassandra.HBase,有了这些数据的组织形式,数据的来源和存储都可以多 ...
- 《Spark快速大数据分析》—— 第三章 RDD编程
- 《Spark快速大数据分析》—— 第七章 在集群上运行Spark
- spark快速大数据分析学习笔记*初始化sparkcontext(一)
初始化SparkContext 1// 在java中初始化spark import org.apache.spark.SparkConf; import org.apache.spark.api.ja ...
- .net架构设计读书笔记--第一章 基础
第一章 基础 第一节 软件架构与软件架构师 简单的说软件架构即是为客户构建一个软件系统.架构师随便软件架构应运而生,架构师是一个角色. 2000年9月ANSI和IEEE发布了<密集性软件架构建 ...
- 《深入理解计算机系统》(CSAPP)读书笔记 —— 第一章 计算机系统漫游
本章通过跟踪hello程序的生命周期来开始对计算机系统进行学习.一个源程序从它被程序员创建开始,到在系统上运行,输出简单的消息,然后终止.我们将沿着这个程序的生命周期,简要地介绍一些逐步出现的关键概念 ...
- Getting Started With Hazelcast 读书笔记(第一章)
第一章:数据集群的演化与 早期的服务器架构 显然,应用是可扩展的,但是由于是集中式服务器,随着数据库性能达到极限,再想扩展就变得极端困难,于是出现了缓存. 缓存显然再次提升了可扩展性,减轻了数据 ...
随机推荐
- JDK1.5新特性,基础类库篇,扫描类(Scanner)用法
一. 背景 这是一个简单的文本扫描类,能够解析基本数据类型与字符串.它是StringTokenizer和Matcher类之间的某种结合. 最大的优点是读取控制台输入非常方便,其它功能,有点鸡肋. 二. ...
- Atitit it行业图像处理行业软件行业感到到迷茫的三大原因和解决方案
Atitit it行业图像处理行业软件行业感到到迷茫的三大原因和解决方案 1. 迷茫的原因最大原因是未知1 1.1. 我在哪里??自己的定位,1 1.2. 正确方向是什么??1 1.3. 虽然找到方向 ...
- 利用javapns对IOS进行推送
start package com.jynine.javapns; import java.io.FileNotFoundException; import java.io.IOException; ...
- zabbix 通过自定义key完成网卡监控
创建执行脚本: # cat /etc/zabbix/monitor_scripts/network.sh #!/bin/bash #set -x usage() { echo "Useage ...
- .net core 调用数字证书 使用X509Certificate2
.NET下面的 .netfromwork使用和asp.net core下使用方式不一样 配置文件中代码: public const string API_URL = "https://api ...
- PLSA及EM算法
前言:本文主要介绍PLSA及EM算法,首先给出LSA(隐性语义分析)的早期方法SVD,然后引入基于概率的PLSA模型,其参数学习采用EM算法.接着我们分析如何运用EM算法估计一个简单的mixture ...
- [整理]Unity3D游戏开发之Lua
原文1:[Unity3D]Unity3D游戏开发之Lua与游戏的不解之缘(上) 各位朋友,大家好,我是秦元培,欢迎大家关注我的博客,我地博客地址是blog.csdn.net/qinyuanpei.如果 ...
- 【流媒体】UPnP的工作过程
UPnP简介 通用即插即用(英语:Universal Plug and Play,简称UPnP)是由“通用即插即用论坛”(UPnP™ Forum)推广的一套网络协议. 该协议的目标是使家庭网络(数据共 ...
- Mac使用pyenv安装Python出现The Python zlib extension was not compiled. Missing the zlib错误
Mac使用pyenv安装Python出现The Python zlib extension was not compiled. Missing the zlib错误 参考这里,详细如下: On Mac ...
- Xtrabackup—InnoDB实现mysql热备份
前面Zabbix使用的数据库是mysql,数据库备份不用多说,必须滴,由于使用的是innodb引擎,既然做,那就使用第三方强大的Xtrabackup工具来热备吧,Xtrabackup的说明,参见htt ...