初窥scrapy爬虫
2017-10-30 21:49:55
前言:
初步使用scrapy爬虫框架,爬取各个网站信息
系统环境:
64位win10系统,装有64位python3.6,IDE为pycharm,使用cmd命令行工具
预备知识:
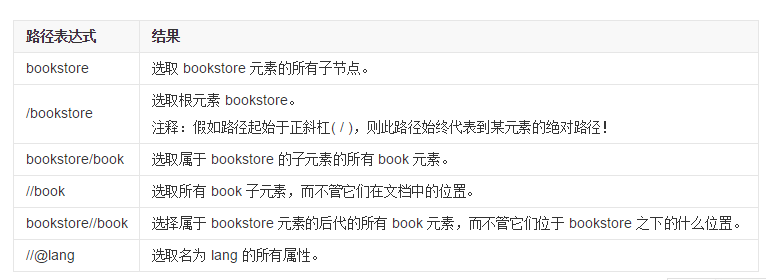
XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似,以下是最有用的路径表达式:

代码:
import scrapy class JulyeduSpider(scrapy.Spider):
name = 'julyedu'
start_urls = ['https://www.julyedu.com/category/index'] def parse(self,response):
for julyedu_class in response.xpath('//div[@class="course_info_box"]'):
print (julyedu_class.xpath('a/h4/text()').extract_first())
print (julyedu_class.xpath('a/p[@class="course-info-tip"]/text()').extract_first())
print (julyedu_class.xpath('a/p[@class="course-info-tip info-time"]/text()').extract_first()) yield {'title':julyedu_class.xpath('a/h4/text()').extract_first(),
'desc':julyedu_class.xpath('a/p[@class="course-info-tip"]/text()').extract_first(),
'time':julyedu_class.xpath('a/p[@class="course-info-tip info-time"]/text()').extract_first()}
代码解释:
首先建立一个文件名为“julyedu_spider”的py文件,导入scrapy框架,然后创建一个JulyeduSpider的类,名字为'juyedu',start_urls为起始的网址。
然后定义解析网页的方法parse,我们需要获取标题,描述,时间等信息,因此右键检查,
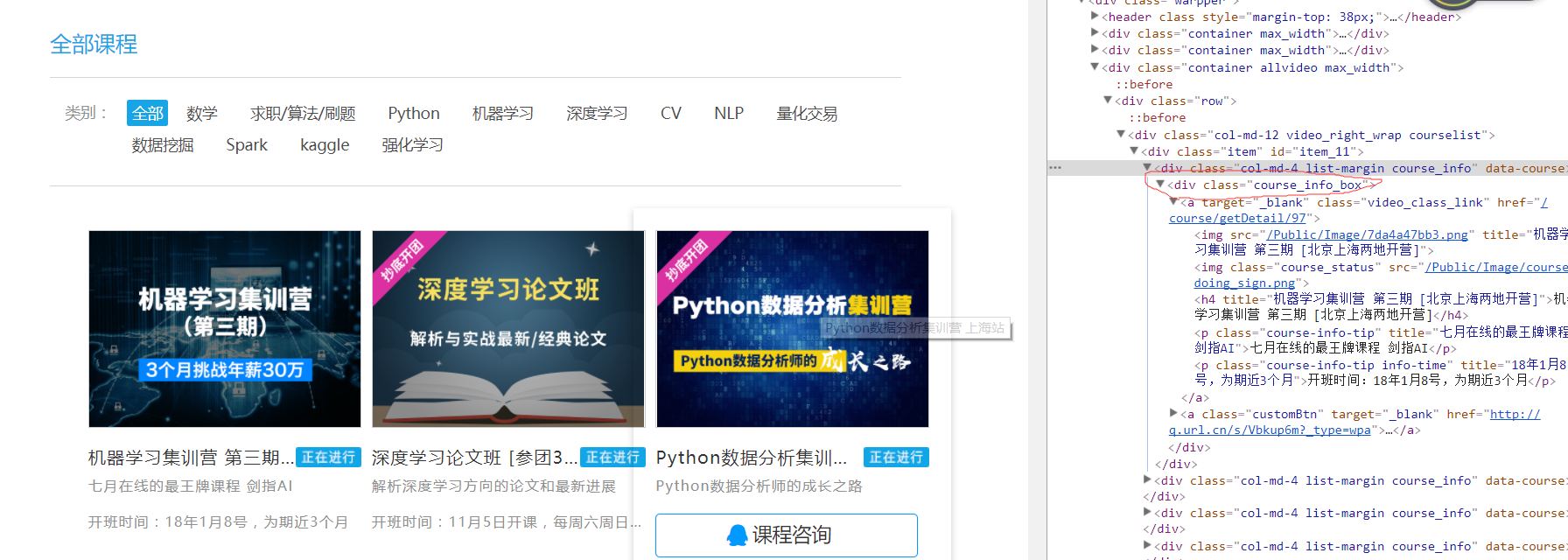
'//div[@class="course_info_box”]'表示选取属性为"course_info_box”标签的子元素,而不管他们的在文档中的位置
'a/h4/text()'表示a标签的子标签h4的文本内容
'a/p[@class="course-info-tip"]/text()'表示a标签的class属性为“..”的p标签的文本内容
'a/p[@class="course-info-tip info-time"]/text()'同理
yield表示创建对应的字典,将数据导入到json,xml,csv等格式的文件中
保存文件后,我们打开cmd窗口,注意要在py文件的目录下打开(按住shift右键即可),输入
scrapy runspider julyedu_spider.py
即可看到打印的内容
再输入
scrapy runspider julyedu_spider.py -o julyedu_class.csv
即可将爬取数据保存到CSV文件中
另外
再补充scrapy shell的用法,同样我们需要在进入项目的根目录,在命令行中输入:
scrapy shell 'https://www.julyedu.com/category/index'
即可加载shell,会获得一个response回应,然后输入
response.xpath('xpath路径')
即可得到所需的内容
初窥scrapy爬虫的更多相关文章
- python爬虫 scrapy2_初窥Scrapy
sklearn实战-乳腺癌细胞数据挖掘 https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campai ...
- scrapy2_初窥Scrapy
递归知识:oop,xpath,jsp,items,pipline等专业网络知识,初级水平并不是很scrapy,可以从简单模块自己写. 初窥Scrapy Scrapy是一个为了爬取网站数据,提取结构性数 ...
- Scrapy 1.4 文档 01 初窥 Scrapy
初窥 Scrapy Scrapy 是用于抓取网站并提取结构化数据的应用程序框架,其应用非常广泛,如数据挖掘,信息处理或历史存档. 尽管 Scrapy 最初设计用于网络数据采集(web scraping ...
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- [Python爬虫] scrapy爬虫系列 <一>.安装及入门介绍
前面介绍了很多Selenium基于自动测试的Python爬虫程序,主要利用它的xpath语句,通过分析网页DOM树结构进行爬取内容,同时可以结合Phantomjs模拟浏览器进行鼠标或键盘操作.但是,更 ...
- Scrapy001-框架初窥
Scrapy001-框架初窥 @(Spider)[POSTS] 1.Scrapy简介 Scrapy是一个应用于抓取.提取.处理.存储等网站数据的框架(类似Django). 应用: 数据挖掘 信息处理 ...
- scrapy爬虫结果插入mysql数据库
1.通过工具创建数据库scrapy
- 初窥Kaggle竞赛
初窥Kaggle竞赛 原文地址: https://www.dataquest.io/mission/74/getting-started-with-kaggle 1: Kaggle竞赛 我们接下来将要 ...
- Linux搭建Scrapy爬虫集成开发环境
安装Python 下载地址:http://www.python.org/, Python 有 Python 2 和 Python 3 两个版本, 语法有些区别,ubuntu上自带了python2.7. ...
随机推荐
- receiving error: 'Error: SSL Error: SELF_SIGNED_CERT_IN_CHAIN' while using npm
From:https://stackoverflow.com/questions/9626990/receiving-error-error-ssl-error-self-signed-cert-in ...
- windows和linux文件输 - ftp
1. linux到linux的复制直接用scp命令 但是windows下就麻烦点, 安装winscp, 配置用户名和密码即可随意拖拽了. 下载地址: 需要linux电脑的用户名和密码即可 2. win ...
- 阿里云k8s应用最新日志采集不到的问题
问题描述: 阿里云k8s应用日志之前一直都是可以正常的采集, 先出现一问题, 通过kibana 和阿里云的日志服务都没法展示最新的k8s应用的日志, 部分应用的最新日志有被采集到,但大部分应用日志没有 ...
- swift3 与 OC 语法区别
1.Swift还增加了Objective-C中没有的类型比如元组(Tuple). 元组可以让你创建或者传递一组数据,比如作为函数的返回值时,你可以用一个元组可以返回多个值. 元组(tuples)把多个 ...
- golang ----gc问题
go程序内存占用大的问题 这个问题在我们对后台服务进行压力测试时发现,我们模拟大量的用户请求访问后台服务,这时各服务模块能观察到明显的内存占用上升.但是当停止压测时,内存占用并未发生明显的下降.花了很 ...
- Atitit 快速开发体系建设路线图
Atitit 快速开发体系建设路线图 1.1. 项目类型划分 哑铃型 橄榄型 直板型(可以立即实行)1 1.2. 解决方案知识库 最佳实践库 最佳流程优化(已成,需要一些整理)2 1.3. 功能模板 ...
- [k8s] 最简单的集群小案例-记录本(tomcat+mysql)
启动一个简单的集群: tomcat+mysql myweb-pod.yaml apiVersion: v1 kind: Pod metadata: name: myweb labels: app: m ...
- Intent的作用和表现形式简单介绍
Intent的作用和表现形式简单介绍 1.描写叙述:Intent负责相应用中一次操作的动作,动作涉及的数据,附加数据进行描写叙述.系统或者应用依据此Intent的描写叙述,负责找到相应的组件,将Int ...
- 【spark 深入学习 06】RDD编程之旅基础篇02-Spaek shell
--------------------- 本节内容: · Spark转换 RDD操作实例 · Spark行动 RDD操作实例 · 参考资料 --------------------- 关于学习编程方 ...
- 【Spark 深入学习 02】- 我是一个凶残的spark
学一门新鲜的技术,其实过程都是相似的,先学基本的原理和概念,再学怎么使用,最后深究这技术是怎么实现的,所以本章节就带你认识认识spark长什么样的,帅不帅,时髦不时髦(这货的基本概念和原理),接着了解 ...