微软BI 之SSIS 系列 - Lookup 中的字符串比较大小写处理 Case Sensitive or Insensitive
开篇介绍
前几天碰到这样的一个问题,在 Lookup 中如何设置大小写不敏感比较,即如何在 Lookup 中的字符串比较时不区分大小写?
实际上就这个问题已经有很多人提给微软了,但是得到的结果就是 Closed and Won’t fix。 说白了,这个就是 By Design,包括到现在的 2012 也没有这个配置选项。
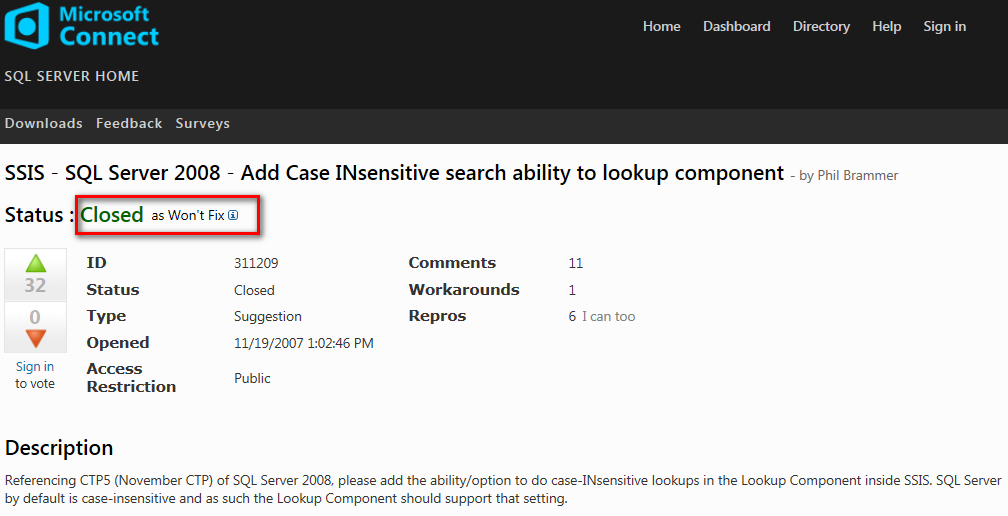
看看大家的抱怨,其实还是非常期望能够加上这个功能的。

Lookup 大小写的处理
还是来了解一下 Lookup 中这个特征吧。
通常情况下,我们一般选择的都是 Full Cache 全缓存模式(关于 Lookup 缓存的几种模式,大家可以参考我的另外一篇文章 - 微软BI 之SSIS 系列 - Lookup 组件的使用与它的几种缓存模式 - Full Cache, Partial Cache, NO Cache)。选择全缓存模式就意味着在这个 Task 真正执行之前,在 Lookup 中的数据将全部首先被缓存,缓存完成之后再开始执行操作。但是在这里就要注意,如果选择的是全缓存,默认的字符串比较就是区分大小写的 CASE SENSITIVE 模式。
Full Cache 的时候采用的是 Windows Collations 中的区分大小写的比较方式。只有不使用 Full Cache 的时候才能使用到 SQL Collations。那我们知道,除了 Full Cache 外,还有 Partial Cache 部分缓存和 No Cache 不缓存。也就是说,如果使用了 Partial Cache 和 No Cache 缓存模式,使用的就是 SQL Collations。
那是不是采用了 Partial Cache 和 No Cache 就可以不区分大小写进行字符串比较呢?这种说法也不全正确!
因为这要取决于你 Lookup 中数据库本身的 Collations 设置 –

如果选择的 Collation 使用的是CI就是不区分大小写 (Case Insensitive),如果是CS(Case Sensitive)就是区分大小写。一般情况下,默认的都是 CI,所以这也就是很多人认为选择了 Partial Cache 或者 No Cache 就能区分大小写的原因,但是这个观点需要被纠正一下。
如何在使用 Lookup 的时候不区分大小写?
方法一
使用 Partial Cache 或者 No Cache 并确认 Lookup 中连接的数据源数据库的 Collation 是 Case Insensitive 方式。但是这种方式就意味着要放弃 Lookup 的 Full Cache,而在通常情况下,使用 Full Cache 的效率更高一些,参看- 微软BI 之SSIS 系列 - Lookup 组件的使用与它的几种缓存模式 - Full Cache, Partial Cache, NO Cache。
方式二
还是使用 Full Cache,但是在进入 Lookup 的 Task 和 Lookup Task 本身的数据查询就不要使用表或者视图方式了,而是改为 T-SQL 查询的方式,那么通过设置两个比较源的 UPPER() / LOWER() 就可以达到忽略大小写比较的目的了! 当然如果上游数据是非数据表而是文件等其它类型,则可以使用其它比如 Derived Column 等使用函数来转变大小写也是可以的。
更多 BI 文章请参看 BI 系列随笔列表 (SSIS, SSRS, SSAS, MDX, SQL Server) 如果觉得这篇文章看了对您有帮助,请帮助推荐,以方便他人在 BIWORK 博客推荐栏中快速看到这些文章。
微软BI 之SSIS 系列 - Lookup 中的字符串比较大小写处理 Case Sensitive or Insensitive的更多相关文章
- 微软BI 之SSIS 系列 - 数据仓库中实现 Slowly Changing Dimension 缓慢渐变维度的三种方式
开篇介绍 关于 Slowly Changing Dimension 缓慢渐变维度的理论概念请参看 数据仓库系列 - 缓慢渐变维度 (Slowly Changing Dimension) 常见的三种类型 ...
- 微软BI 之SSIS 系列 - Lookup 组件的使用与它的几种缓存模式 - Full Cache, Partial Cache, NO Cache
开篇介绍 先简单的演示一下使用 Lookup 组件实现一个简单示例 - 从数据源表 A 中导出数据到目标数据表 B,如果 A 数据在 B 中不存在就插入新数据到B,如果存在就更新B 和 A 表数据保持 ...
- 微软BI 之SSIS 系列 - 再谈Lookup 缓存
开篇介绍 关于 Lookup 的缓存其实在之前的一篇文章中已经提到了 微软BI 之SSIS 系列 - Lookup 组件的使用与它的几种缓存模式 - Full Cache, Partial Cache ...
- 微软BI 之SSIS 系列 - 在 SSIS 中导入 ACCESS 数据库中的数据
开篇介绍 来自 天善学院 一个学员的问题,如何在 SSIS 中导入 ACCESS 数据表中的数据. 在 SSIS 中导入 ACCESS 数据库数据 ACCESS 实际上是一个轻量级的桌面数据库,直接使 ...
- 微软BI 之SSIS 系列 - MVP 们也不解的 Scrip Task 脚本任务中的一个 Bug
开篇介绍 前些天自己在整理 SSIS 2012 资料的时候发现了一个功能设计上的疑似Bug,在 Script Task 中是可以给只读列表中的变量赋值.我记得以前在 2008 的版本中为了弄明白这个配 ...
- 微软BI 之SSIS 系列 - 使用 Script Component Destination 和 ADO.NET 解析不规则文件并插入数据
开篇介绍 这一篇文章是 微软BI 之SSIS 系列 - 带有 Header 和 Trailer 的不规则的平面文件输出处理技巧 的续篇,在上篇文章中介绍到了对于这种不规则文件输出的处理方式.比如下图中 ...
- 微软BI 之SSIS 系列 - 使用 Script Task 访问非 Windows 验证下的 SMTP 服务器发送邮件
原文:微软BI 之SSIS 系列 - 使用 Script Task 访问非 Windows 验证下的 SMTP 服务器发送邮件 开篇介绍 大多数情况下我们的 SSIS 包都会配置在 SQL Agent ...
- 微软BI 之SSIS 系列 - 带有 Header 和 Trailer 的不规则的平面文件输出处理技巧
案例背景与需求介绍 之前做过一个美国的医疗保险的项目,保险提供商有大量的文件需要发送给比如像银行,医疗协会,第三方服务商等.比如像与银行交互的 ACH 文件,传送给协会的 ACH Credit 等文件 ...
- 微软BI 之SSIS 系列 - Merge, Merge Join, Union All 合并组件的使用以及Sort 排序组件同步异步的问题
开篇介绍 SSIS Data Flow 中有几个组件可以实现不同数据源的数据合并功能,比如 Merger, Merge Join 和 Union All.它们的功能比较类似,同时也比较容易混淆,下面是 ...
随机推荐
- hdu2838树状数组解逆序
离散化和排序后的序号问题搞得我实在是头痛 不过树状数组解逆序和偏序一类问题真的好用 更新:hdu的数据弱的真实,我交上去错的代价也对了.. 下面的代码是错的 /* 每个点的贡献度=权值*在这个点之前的 ...
- 性能测试三十六:内存溢出和JVM常见参数及JVM参数调优
堆内存溢出: 此种溢出,加内存只能缓解问题,不能根除问题,需优化代码堆内存中存在大量对象,这些对象都有被引用,当所有对象占用空间达到堆内存的最大值,就会出现内存溢出OutOfMemory:Java h ...
- js读取xml文件
假设我们现在要读取下面的 info.xml 文件 <?xml version="1.0" encoding="gb2312"?> <root& ...
- Spring启动研究2.AbstractApplicationContext.obtainFreshBeanFactory()研究
据说这个方法里面调用了loadBeanDefinitions,据说很重要,并且跟我感兴趣的标签解析有关,所以仔细看看 obtainFreshBeanFactory()这个方法在AbstractAppl ...
- react-router4 + webpack Code Splitting
项目升级为react-router4后,就尝试着根据官方文档进行代码分割.https://reacttraining.com/react-router/web/guides/code-splittin ...
- C语言程序内存的分区
本文转载自:https://blog.csdn.net/shulianghan/article/details/20472269 C语言程序内存分配 (1) 内存分区状况 栈区 (stack) : ...
- python套接字编程基础
python套接字编程 目录 socket是什么 套接字的工作流程 基于tcp的套接字 基于udp的套接字 socket是什么 客户端/服务器架构(C/S架构) 服务端:提供服务的一端 客户端:请求服 ...
- Spring框架学习03——Spring Bean 的详解
1.Bean 的配置 Spring可以看做一个大型工厂,用于生产和管理Spring容器中的Bean,Spring框架支持XML和Properties两种格式的配置文件,在实际开发中常用XML格式的配置 ...
- ESLint + lint-staged 禁用老项目中的es6
前言 ESLint作为插件化的javascript代码检测工具,为我们的平时的开发保驾护航,好处就不多说了详情查看官网. 问题 有这么一个五年前开发的老项目,机缘巧合到了我们这边来维护. 项目是zep ...
- 用js来实现那些数据结构02(数组篇02-数组方法)
上一篇文章简单的介绍了一下js的类型,以及数组的增删方法.这一篇文章,我们一起来看看数组还有哪些用法,以及在实际工作中我们可以用这些方法来做些什么.由于其中有部分内容并不常用,所以我尽量缩小篇幅.在这 ...