大数据和hadoop的一些基础知识
一、前言
大数据这个概念不用我提大家也听过很多了,前几年各种公开论坛、会议等场合言必及大数据,说出来显得很时髦似的。有意思的是最近拥有这个待遇的名词是“人工智能/AI”,当然这是后话。
众所周知,大数据的发展是来源于Google三驾马车,分别是:
- Google File System(GFS) —2003
- MapReduce —2004
- Bigtable —2006
不得不说,Google真的是一家牛逼的公司,开源了这些思想造福了全球的IT事业。不过有意思的是,这三篇论文一开始并不是大数据相关的,而是为了更好地服务谷歌自家的搜索业务。基于此,出现了传统的大数据框架三大组件:HDFS、MapReduce、Hbase,这就是Hadoop最开始的样子。
二、Hadoop简介
Hadoop是一个用Java编写的Apache开源框架,现在我们提到Hadoop可能有两种所指,一种是Hadoop几个基本模块,另一种是可以安装在Hadoop之上的附加软件包的集合,例如Hive、Impala、Oozie、Hue等等等等,也称之为Hadoop家族。所以说,Hadoop技术产品是十分丰富并且在一直不停地演化,有些技术可能几年后不流行了,又或者产生了新的技术。所以在大数据领域是需要不断地学习的,这也导致了大数据领域的工作一般待遇都很丰厚,因为要求真的还蛮高的,需要掌握的技术线比较长。
随便丢张图了解下(图随便找的,有些技术可能已经不流行了,有些目前流行的技术没有):

Hadoop基本框架介绍
- Hadoop Common:这些是其他Hadoop模块所需的Java库和实用程序。这些库提供文件系统和操作系统级抽象,并包含启动Hadoop所需的Java文件和脚本;
- Hadoop YARN:这是一个用于作业调度和集群资源管理的框架;
- Hadoop Distributed File System (HDFS™):分布式文件系统,提供对应用程序数据的高吞吐量访问;
- Hadoop MapReduce:这是基于YARN的用于并行处理大数据集的系统。
MapReduce
实际上是两个不同的任务:
Map(映射):把读入的数据用相同的方法拆分成小数据块,然后把这些小数据块分发到不同的工作节点上。每一个节点循环处理同样的事,这就是一个分布式计算的过程。
Reduce(归并):此任务将map任务的输出作为输入,并将这些数据元组合并为较小的元组集合。 reduce任务总是在map任务之后执行。
图解:

HDFS
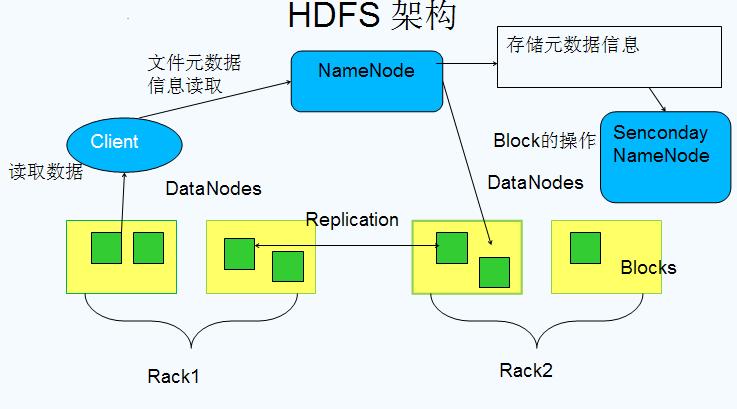
HDFS是GFS的开源实现,它使用主/从结构,其中主节点由管理文件系统元数据的单个NameNode和存储实际数据的一个或多个从节点DataNode组成。HDFS命名空间中的文件被拆分为几个块,这些块存储在一组DataNode中。 NameNode决定块到DataNode的映射。DataNodes负责与文件系统的读写操作。它们还根据NameNode给出的指令来处理块创建,删除和复制。
HDFS架构图:
YARN
旧的MapReduce过程是通过JobTracker和TaskTracker来完成的:
- JobTracker: 负责资源管理,跟踪资源消耗和可用性,作业生命周期管理(调度作业任务,跟踪进度,为任务提供容错)
- TaskTracker: 加载或关闭任务,定时报告任务状态旧MapReduce图示:

可以一眼看出JobTracker是核心所在,存在单点问题和资源利用率问题。所以出现了新的YARN架构。
YARN将JobTracker的职责进行拆分,将资源管理和任务调度监控拆分成独立的进程:一个全局的资源管理和一个单点的作业管理。ResourceManager和NodeManager提供了计算资源的分配和管理,而ApplicationMaster则完成应用程序的运行。
- ResourceManager: 全局资源管理和任务调度
- NodeManager: 单个节点的资源管理和监控
- ApplicationMaster: 单个作业的资源管理和任务监控
YARN架构图示:

现在的Hadoop架构长这样:

可以看出,一些Hadoop家族的技术产品也是通过YARN和Hadoop联动的,YARN作为资源调度器起到一个中央管理的作用,这么多技术工具都在同一个集群上运转,大家互相配合协调有序工作,就是依赖于YARN的分配管理。
三、Hadoop家族产品介绍
大数据领域的技术产品茫茫多,挑几个我用过的或者很重要的组件简单介绍下。
Hive
MapReduce的程序写起来是一点都不方便,所以需要更高层更抽象的语言来描述算法和数据处理过程。于是Hive诞生了,它用类SQL语言来描述MapReduce,称之为HQL。这简直是个伟大发明。大量的数据分析人员终于也能直接使用Hadoop技术,我的SQL入门就是在Hive上操作的。Hive现在是Hadoop大数据仓库的核心工具,它是由Facebook贡献的,感谢脸书,感恩。
Impala
跟Hive一样,也提供类SQL语言来查询处理数据,称之为Impala SQL。它是一种实时交互的查询工具,不经由MapReduce批处理,而是通过使用分布式查询引擎直接读取HDFS或HBase中的内容,大大降低延迟。总结下,Hive适合于长时间的批处理查询分析,而Impala适合于实时交互式SQL查询。
就我个人的使用体会看,Impala的容错性没有Hive好,很多Hive能运行的SQL,在Impala中可能报错,不过Impala的查询速度的确甩开Hive很多,这也是MapReduce的局限性所在(这也导致了后续Spark的诞生),而且Impala也不支持UDF(自定义函数扩展,实现很多SQL难以实现或不好实现的功能)。所以在很多时候,我们都是Hive和Impala配合着使用,各有优劣。
Oozie
一个基于工作流引擎的开源框架。它能够提供对Hadoop MapReduce和Pig Jobs的任务调度与协调。当我们需要让一些数据处理过程自动周期地运行时会需要它,在Oozie上设定好工作流后,可以实现数据的自动导入HDFS-清洗-处理-导出同步的过程。
HBase
构建在HDFS之上的分布式,面向列的数据库。HDFS缺乏随即读写操作,HBase正是为此而出现。在需要实时读写、随机访问超大规模数据集时,可以使用HBase。它不是关系型数据库,也不支持SQL,它是一种典型的NoSQL(Not Only SQL)。也是Google经典论文Bigtable的开源实现。
Storm
流计算平台,为了达到更快更实时的数据更新,在数据流进来的时候就进行处理。流计算基本无延迟,但劣势是不灵活,你想要处理的数据必须预先设计好,所以并不能完全替代批处理系统。
Spark
一个快速、通用的大规模数据处理引擎,在Hadoop的整个生态系统中,Spark和MapReduce在同一个层级,即主要解决分布式计算框架的问题。至于为什么会产生Spark,是因为Hadoop的计算框架MapReduce存在着局限性和不足。比如抽象层次低,代码不好写;表达力欠缺、中间结果存储在HDFS中,速度不够快;延时高,只适合批处理不适合交互处理和实时处理。所以Spark的诞生就是为了解决这些问题,它的中间输出结果可以保存在内存中(内存放不下会写入磁盘),避免了对HDFS的大量的读写,减少了I/O的开销。
可以说,Spark是对Hadoop MapReduce的改进,同时又兼容Hadoop家族,它可以运行在YARN之上,负责存储的仍然是HDFS,它替代的是MapReduce计算框架,获取更高更快更强的计算速度。上层的话也有用对SQL的支持,叫做Spark SQL,也有Hive ON Spark的项目继续使用我们可爱的Hive。所以说,Spark是有一定的野心来对Hadoop取而代之的,而且这样的趋势来越来越明显。
其他
还有些我不太了解的就简单提及:Zookeeper是高一致性的分布存取协同系统;Mahout是分布式机器学习库;Sqoop是异构数据源海量数据交互工具。当然这个工具我没用过,我用的是阿里开源的数据同步工具:DataX。
四、后话—Hadoop版本
Hadoop的部署是比较麻烦的,我自己也只是实现过伪分布式模式的部署,还是按照教程一步步来的,很多步骤都不是很明白到底在做什么,对于Linux和Java精通的程序员来说可能过程会比较友好。
Hadoop实际上有很多版本,有Apache Hadoop,这是开源版本,也叫社区版。实际上所有其他的发行版都是基于此衍生出来的。因为Apache Hadoop是开源的,允许任何人修改并作为商业版本发布。
最有名的发行版当属Cloudera版本(CDH)和Hortonworks版本(HDP)了,其中Cloudera可是贡献了很多Hadoop家族产品技术的公司,CDH也成为了很多人的选择。有意思的是这些发行版也是免费的。
对于大公司来说,为了灵活和实现高度的定制化,基本会选择Apache Hadoop,不过这需要一个Hadoop开发团队来维护,小公司就会选择付费的商业版,有专门的技术支持来解决疑问,也不用维持一个团队,保留少量的管理员即可。
参考资料:https://blog.csdn.net/zhchs2012/article/details/80356920
大数据和hadoop的一些基础知识的更多相关文章
- 大数据和Hadoop生态圈
大数据和Hadoop生态圈 一.前言: 非常感谢Hadoop专业解决方案群:313702010,兄弟们的大力支持,在此说一声辛苦了,经过两周的努力,已经有啦初步的成果,目前第1章 大数据和Hadoop ...
- Hadoop专业解决方案-第1章 大数据和Hadoop生态圈
一.前言: 非常感谢Hadoop专业解决方案群:313702010,兄弟们的大力支持,在此说一声辛苦了,经过两周的努力,已经有啦初步的成果,目前第1章 大数据和Hadoop生态圈小组已经翻译完成,在此 ...
- 细细品味大数据--初识hadoop
初识hadoop 前言 之前在学校的时候一直就想学习大数据方面的技术,包括hadoop和机器学习啊什么的,但是归根结底就是因为自己太懒了,导致没有坚持多长时间,加上一直为offer做准备,所以当时重心 ...
- 大数据和Hadoop平台介绍
大数据和Hadoop平台介绍 定义 大数据是指其大小和复杂性无法通过现有常用的工具软件,以合理的成本,在可接受的时限内对其进行捕获.管理和处理的数据集.这些困难包括数据的收入.存储.搜索.共享.分析和 ...
- 大数据之Hadoop技术入门汇总
今天,小编对Hadoop入门学习知识进行了汇总,帮助大家更好地入手大数据.小编关于Hadoop入门总共发写了12篇原创文章,文章是参照尚硅谷大数据视频教程来进行撰写的. 今天,小编带你解锁正确的阅读顺 ...
- 大数据技术Hadoop入门理论系列之一----hadoop生态圈介绍
Technorati 标记: hadoop,生态圈,ecosystem,yarn,spark,入门 1. hadoop 生态概况 Hadoop是一个由Apache基金会所开发的分布式系统基础架构. 用 ...
- 大数据和hadoop有什么关系?
本文资料来自百度文库相关文档 Hadoop,Spark和Storm是目前最重要的三大分布式计算系统,Hadoop常用于离线的复杂的大数据处理,Spark常用于离线的快速的大数据处理,而Storm常用于 ...
- 大数据除了Hadoop还有哪些常用的工具?
大数据除了Hadoop还有哪些常用的工具? 1.Hadoop大数据生态平台Hadoop 是一个能够对大量数据进行分布式处理的软件框架.但是 Hadoop 是以一种可靠.高效.可伸缩的方式进行处理的.H ...
- [Hadoop 周边] 浅谈大数据(hadoop)和移动开发(Android、IOS)开发前景【转】
原文链接:http://www.d1net.com/bigdata/news/345893.html 先简单的做个自我介绍,我是云6期的,黑马相比其它培训机构的好偶就不在这里说,想比大家都比我清楚: ...
随机推荐
- Spring对Bean装配详解
1.Spring提供了三种装配bean的方式: 2.自动装配bean: 3.通过Java代码装配bean 4.通过XML装配bean 前言:创建对象的协作关系称为装配,也就是DI(依赖注入)的本质.而 ...
- 前端 HTML form表单标签 input标签 type属性 file 上传文件
加上上传文件功能 input type='file' - 依赖form表单里一个属性 enctype="multipart/form-data" 加上这个属性表示把你上次文件一点 ...
- 20190223 Hadoop生态圈,关于大数据
周六参加了一场,大数据基础培训,讲得比较详细.培训的讲师对于互联网行业职位萎缩也有相对的解释,也还介绍了新的职位的诞生. 以前对于大数据的理解,就是超大的数据量,但对大数据开发不甚了解. 大数据平台的 ...
- Linux Shell的18条常用命令整理
1. ls: 类似于dos下的dir命令 ls最常用的参数有三个:-a -l -F. ls –a Linux上的文件以.开头的文件被系统视为隐藏文件,仅用ls命令是看不到他们的,而用ls -a除了 ...
- 循环匹配出图片地址(即src属性)
<script type="text/javascript"> //思路分两步:作者(yanue). //1,匹配出图片img标签(即匹配出所有图片),过滤其他不需要的 ...
- 无法连接 MKS:套接字连接尝试次数太多正在放弃
我的电脑 -> 右键 -> 管理 -> 服务和应用程序 -> 服务: 开启下面的服务: 服务启动成功后,重启虚拟机; 或者先挂起虚拟机,等服务启动后,继续运行挂起的虚拟机:
- k8s 高级调度 亲和力和反亲和力、绑定标签、污点容忍污点
通过标签绑定 spec: nodeSelector: bigdata-node: bigdata containers: - env: pod只能运行在有bigdata-node: bigdata 标 ...
- 第一天 Linux基础篇
课程介绍 1.认识Linux的不同版本 2.以及应用领域 3.文件和目录 4.Linux命令概述 5.Linux命令-文件 6.Linux命令-系统管理-磁盘管理 认识Linux 什么是操作系统 生 ...
- mybatis 调用 oracle 存储过程 select into 无记录时NO_DATA_FOUND异常处理分析
首先根据这篇文章:http://www.cnblogs.com/coolzdp/p/7717332.html 我们知道存储过程中 SELECT * INTO 如果没有记录是不会往下执行的,直接抛出NO ...
- 4个项目带你学习ThinkPHP
ThinkPHP是一个快速.兼容而且简单的轻量级国产PHP开发框架,这里分享4个项目教程,带你掌握ThinkPHP,并能够在实践开发中应用. ThinkPHP框架实践 这个教程从ThinkPHP的入门 ...