Writable序列化
序列化:将内存中的对象 转换成字节序列以便于存储在磁盘上或者用于网络传输。
反序列化:将磁盘或者从网络中接受到的字节序列,装换成内存中的对象。
自定义bean对象(普通java对象)要想序列化传输,必须实现序列化接口。
(1)必须实现Writable接口
(2)反序列化时,需要反射调用空参构造函数,所以必须有空参构造
(3)重写序列化方法
(4)重写反序列化方法
(5)注意反序列化的顺序和序列化的顺序完全一致
(6)要想把结果显示在文件中,需要重写toString(),且用”\t”分开,方便后续用
(7)如果需要将自定义的bean放在key中传输,则还需要实现comparable接口,因为mapreduce框中的shuffle过程一定会对key进行排序
package com.mapreduce.flow; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException; import org.apache.hadoop.io.Writable; /*
* 实现writable 接口
* 目的: 能够序列化和反序列化 用户自定义的bean对象( 用hadoop 的序列化机制 )
*
*/
public class FlowBean implements Writable { private long upFlow;
private long downFlow;
private long sumFlow; public FlowBean(){
super();
} /*
* 序列化对象
*
*/
public void write(DataOutput out) throws IOException {
out.writeLong(this.upFlow);
out.writeLong(this.downFlow);
out.writeLong(this.sumFlow);
}
/*
* 反序列化对象
*
*/
public void readFields(DataInput in) throws IOException { upFlow = in.readLong();
downFlow = in.readLong();
sumFlow = in.readLong();
} public String toString() {
return upFlow + "\t" + downFlow + "\t" + sumFlow;
}
//7 如果需要将自定义的bean放在key中传输,则还需要实现comparable接口,因为mapreduce框中的shuffle过程一定会对key进行排序
@Override
public int compareTo(FlowBean o) {
// 倒序排列,从大到小
return this.sumFlow > o.getSumFlow() ? -1 : 1;
}
}
}
Writable序列化的更多相关文章
- 为什么hadoop中用到的序列化不是java的serilaziable接口去序列化而是使用Writable序列化框架
继上一个模块之后,此次分析的内容是来到了Hadoop IO相关的模块了,IO系统的模块可谓是一个比较大的模块,在Hadoop Common中的io,主要包括2个大的子模块构成,1个是以Writable ...
- MapReduce框架原理-Writable序列化
序列化和反序列化 序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储(持久化)和网络传输. 反序列化就是将收到字节序列(或其他数据传输协议)或者是硬盘的持久化数据,转换成内存中的 ...
- hadoop学习第四天-Writable和WritableComparable序列化接口的使用&&MapReduce中传递javaBean的简单例子
一. 为什么javaBean要继承Writable和WritableComparable接口? 1. 如果一个javaBean想要作为MapReduce的key或者value,就一定要实现序列化,因为 ...
- hadoop中典型Writable类详解
本文地址:http://www.cnblogs.com/archimedes/p/hadoop-writable.html,转载请注明源地址. Hadoop将很多Writable类归入org.apac ...
- Hadoop中Writable类
1.Writable简单介绍 在前面的博客中,经常出现IntWritable,ByteWritable.....光从字面上,就可以看出,给人的感觉是基本数据类型 和 序列化!在Hadoop中自带的or ...
- hadoop中的序列化
此文已由作者肖凡授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 最近在学习hadoop,发现hadoop的序列化过程和jdk的序列化有很大的区别,下面就来说说这两者的区别都有 ...
- MapReduce02 序列化
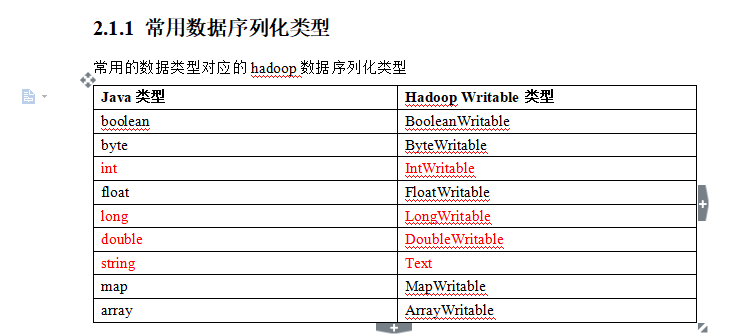
目录 MapReduce 序列化 概述 自定义序列化 常用数据序列化类型 int与IntWritable转化 Text与String 序列化读写方法 自定义bean对象实现序列化接口(Writable ...
- Hadoop阅读笔记(七)——代理模式
关于Hadoop已经小记了六篇,<Hadoop实战>也已经翻完7章.仔细想想,这么好的一个框架,不能只是流于应用层面,跑跑数据排序.单表链接等,想得其精髓,还需深入内部. 按照<Ha ...
- 手机号流量统计---Mapreduce项目分析
文档显示: 每行依次是 ~手机号~上行流量~下行流量 需求分析: 需要统计各自的手机号,及上行.下行.总流量 具体做法: 1.定义map输入输出类型 通常情况下map的输入的key-value就是lo ...
随机推荐
- javascript arguments介绍
来源于: https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Functions/arguments https://g ...
- 地图组件上的自定义区域叠加层显示 ArcGis + GeoJson
最近参与了一个IOT环境项目,需要对某个城市的某几个区域做环境监控与治理,其中就用到了地图叠加层的功能,粗看很复杂,其实很简单,先来看一下效果,然后再来讲一下如何实现的: 中间的黄色轮廓线包括的几块区 ...
- ASP.NET CORE下用盛派微信SDK取微信openid
用CORE做项目用到微信的相关东西,听说那个盛派微信SDK很火,自己弄了下,只是简单的用用,用户访问页面取微信openid
- 图解ByteBuffer
https://www.cnblogs.com/ruber/p/6857159.html https://www.e-learn.cn/content/qita/750752 https://blog ...
- flink 获取上传的Jar源码
package org.apache.flink.runtime.webmonitor.handlers; /** * Handles .jar file uploads. */public clas ...
- Source Insight 有用设置配置
source insight代码对齐Tab键终极版 以前也写过一个source insight代码对齐,由于自己理解不够深刻,只能解决部分问题,不能根治在source insight中对齐的代码在XX ...
- MinGW 使用 mintty 终端替代默认终端以解决界面上复制与粘贴的问题
使用了一段时间的 cygwin,挺开心的,又尝试了下同类工具 Msys + MinGW,安装好之后发现它居然使用默认的 cmd 作为终端,界面输出内容的复制与粘贴极其不便,我记得 Cygwin 使用的 ...
- 关于启动过程及log
1.tomcat的启动过程及log 2.webapp的启动过程及log 3.spring的启动过程及log 4.springmvc的启动过程及log 5.web.xml的启动过程及log
- CALayer 知识:创建带阴影效果的圆角图片图层和创建自定义绘画内容图层
效果如下: KMLayerDelegate.h #import <UIKit/UIKit.h> @interface KMLayerDelegate : NSObject @end KML ...
- 巧妙解决windows下 copy命令不接受太长路径的问题
今天遇到了写的bat文件中执行xcopy成功,但是部分文件丢失的问题,查看日志,发现很多提示 : “the system can not find the path specified.“ 但是去指定 ...