zList一个块状链表算法可以申请和释放同种对象指针,对于大数据量比直接new少需要差不多一半内存
zList是一个C++的块状内存链表,特点:
1、对于某种类别需要申请大量指针,zList是一个很好的帮手,它能比new少很多内存。
2、它对内存进行整体管理,可以将数据和文件快速互操作
3、和vector对象存储对比,vector存储的对象不能使用其指针,因为vector内容变化时vector存储对象的指针会变化
4、zList也可以当做顺序的数组使用,它有自己的迭代器,可以遍历整个数组
下面是申请5千万个RECT指针对比结果:
zList申请五千万RECT指针内存占用: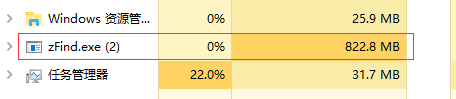
直接new五千万RECT指针内存占用: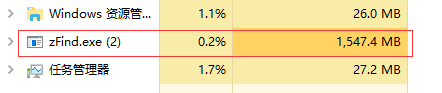
从对比看节省了724.6M的内存
下面是zList实现代码:
#include "stdafx.h"
#include <set>
#include <map>
#include <string>
#include <vector>
#include <windows.h>
using namespace std; template <class T>
struct zElem
{
zElem() { memset(this, , sizeof(zElem)); }
int has() //查找空闲的位置
{
return extra < ? extra : -;
}
bool empty() { return == size; };
bool full() { return == size; };
T *add(int i, const T &r)
{
bit[i] = ;
R[i] = r;
size++;
if (extra == i)//指向下一个位置
{
extra++;
while (extra < )
{
if (bit[extra] == )break;
extra++;
}
}
return R + i;
}
void remove(T *r)
{
int i = (int)(r - R);
if (i >= && i < )
{
bit[i] = ;
if (extra > i)extra = (unsigned short)i;
size--;
}
}
bool in(T *r)
{
int i = (int)(r - R);
return i >= && i < ;
}
T* get(int i)
{
int ind = getInd(i);
return ind == - ? NULL : R + ind;
}
int getInd(int i)
{
if (i >= && i < extra)return i;
int k = extra + , t = extra;
while (k < )
{
if (bit[k] != )
{
if (t == i)return k;
t++;
}
k++;
}
return -;
}
bool getInd(size_t &ind, size_t &off, size_t n)
{
if (ind + n < extra)
{
ind += n;
off = ind;
return true;
}
while (++ind < )
{
if (bit[ind] != )
{
n--;
off++;
if (n==)return true;
}
}
return false;
}
unsigned short extra;//指向当前空闲位置
unsigned short size; //当前已有数据个数
byte bit[]; //标记是否使用
T R[]; //数据存储
};
template <class T>
struct zList
{
struct iterator
{
T* operator *()
{
return p ? &p->head[ind]->R[zind] : NULL;
}
T* operator ->()
{
return p ? &p->head[ind]->R[zind] : NULL;
}
iterator& operator ++()
{
bool bend = true;
if (p&&p->head.size() > ind)
{
for (; ind < p->head.size(); ind++)
{
zElem<T>*a = p->head[ind];
if (zsize + < a->size)
{
a->getInd(zind,zsize,);
bend = false;
break;
}
zind = zsize = -;
}
}
if (bend)
{
ind = zsize = zind = ; p = ;
}
return (*this);
}
bool operator ==(const iterator &data)const
{
return ind == data.ind&&zind == data.zind&&zsize == data.zsize&&p == data.p;
}
bool operator !=(const iterator &data)const
{
return ind != data.ind||zind != data.zind||zsize != data.zsize||p != data.p;
}
explicit operator bool() const
{
return (!p);
}
size_t ind; //p的位置
size_t zind; //zElem中的R位置
size_t zsize; //zElem中zind位置所在的次序
zList *p; //指向链表的指针
};
zList() :size(), extra() { }
~zList()
{
for (auto &a: head)
{
delete a;
}
}
T *add(const T &r)
{
zElem<T>* e;
if (extra >= head.size())
{
e = new zElem<T>();
head.push_back(e);
}
else
{
e = head[extra];
}
int i = e->has();
T *R = e->add(i, r);
size++;
while (extra < head.size() && e->full())
{
e = head[extra];
extra++;
}
return R;
}
void remove(T *r)
{
if (r == NULL)return;
zElem<T> *rem;
size_t i = ;
for (; i < head.size(); i++)
{
rem = head[i];
if (rem->in(r))
{
size--;
rem->remove(r);
if (rem->empty())//删除当前节点
{
head.erase(head.begin() + i);
if (extra == i)
{
//往后查找空闲的位置
while (extra < head.size())
{
if (!head[extra]->full())break;
extra++;
}
}
delete rem;
}
else if(extra > i)
{
extra = i;
}
break;
}
}
}
T* get(int i)
{
for (auto &a : head)
{
if (i < a->size)
{
return a->get(i);
}
i -= a->size;
}
return NULL;
}
void clear()
{
for (auto &a : head)
{
delete a;
}
head.clear();
size = extra = ;
}
iterator begin()
{
iterator it = { ,,,NULL };
if (head.size() > )
{
int i = ;
for (;it.ind < head.size(); it.ind++)
{
zElem<T>*a = head[it.ind];
if (i < a->size)
{
it.p = this;
it.zind = a->getInd(i);
break;
}
i -= a->size;
}
}
return it;
}
iterator end()
{
iterator it = {,,,NULL};
return it;
}
size_t size; //个数
vector<zElem<T>*> head; //开头
size_t extra; //有空余位置的
};
使用方法如下:
int main()
{
zList<RECT> z;
for (int i = ; i < ; i++)
{
//1、申请内存
RECT r = { rand(), rand(), rand(), rand() };
RECT *p = z.add(r);
//2、可以对p进行使用...
//3、释放内存
z.remove(p);
}
getchar();
return ;
}
对zList进行元素遍历,迭代器方法:
int t = ;
zList<RECT>::iterator its = z.begin();
zList<RECT>::iterator ite = z.end();
for (; its != ite; ++its)
{
RECT *p = *its;
t = p->left;
}
对zList进行随机访问遍历,效率没有迭代器高:
int t = ;
for (int i = ; i < z.size; i++)
{
RECT *p = z.get(i);
t = p->left;
}
zList一个块状链表算法可以申请和释放同种对象指针,对于大数据量比直接new少需要差不多一半内存的更多相关文章
- php 大数据量及海量数据处理算法总结
下面的方法是我对海量数据的处理方法进行了一个一般性的总结,当然这些方法可能并不能完全覆盖所有的问题,但是这样的一些方法也基本可以处理绝大多数遇到的问题.下面的一些问题基本直接来源于公司的面试笔试题目, ...
- 解决WCF大数据量传输 ,System.Net.Sockets.SocketException: 远程主机强迫关闭了一个现有的连接
开发中所用的数据需要通过WCF进行数据传输,结果就遇到了WCF大量传输问题 也就是提示System.Net.Sockets.SocketException: 远程主机强迫关闭了一个现有的连接 网上解决 ...
- 大数据量表中,增加一个NOT NULL的新列
这次,发布清洗列表功能,需要对数据库进行升级.MailingList表加个IfCleaning字段,所有的t_User*表加个IfCleaned字段. 脚本如下 对所有的t_User表执行 a ...
- 【POJ2887】【块状链表】Big String
Description You are given a string and supposed to do some string manipulations. Input The first lin ...
- 读<大数据日知录:架构与算法>有感
前一段时间, 一个老师建议我能够学学 '大数据' 和 '机器学习', 他说这必定是今后的热点, 学会了, 你就是香饽饽.在此之前, 我对大数据, 机器学习并没有非常深的认识, 总觉得它们是那么的缥缈, ...
- php获胜的算法的概率,它可用于刮,大转盘等彩票的算法
php获胜的算法的概率,它可用于刮,大转盘等彩票的算法. easy,代码里有具体凝视说明.一看就懂 <?php /* * 经典的概率算法, * $proArr是一个预先设置的数组. * 假设数组 ...
- 滴滴大数据算法大赛Di-Tech2016参赛总结
https://www.jianshu.com/p/4140be00d4e3 题目描述 建模方法 特征工程 我的几次提升方法 从其他队伍那里学习到的提升方法 总结和感想 神经网络方法的一点思考 大数据 ...
- parquet文件格式——本质上是将多个rows作为一个chunk,同一个chunk里每一个单独的column使用列存储格式,这样获取某一row数据时候不需要跨机器获取
Parquet是Twitter贡献给开源社区的一个列数据存储格式,采用和Dremel相同的文件存储算法,支持树形结构存储和基于列的访问.Cloudera Impala也将使用Parquet作为底层的存 ...
- 教你做一个牛逼的DBA(在大数据下)
一.基本概念 大数据量下,搞mysql,以下概念需要先达成一致 1)单库,不多说了,就是一个库 2)分片(sharding),水平拆分,用于解决扩展性问题,按天拆分表 3)复制(replication ...
随机推荐
- DDD领域驱动设计理论篇 - 学习笔记
一.Why DDD? 在加入X公司后,开始了ASP.NET Core+Docker+Linux的技术实践,也开始了微服务架构的实践.在微服务的学习中,有一本微软官方出品的<.NET微服务:容器化 ...
- JAVA SPI(Service Provider Interface)原理、设计及源码解析(其一)
背景 团队内部轮流技术分享,其他人都是分享源码,我每次都是设计和架构,感觉自己太特立独行.这次我要合群点,分享点源码. 概念 Service Provider Interface:服务提供方接口.是一 ...
- String求求你别秀了
小鲁班今年计算机专业大四了,在学校可学了不少软件开发的东西,也自学了一些JAVA的后台框架,踌躇满志,一心想着找个好单位实习.当投递了无数份简历后,终于收到了一个公司发来的面试通知,小鲁班欣喜若狂. ...
- Python爬虫使用lxml模块爬取豆瓣读书排行榜并分析
上次使用了BeautifulSoup库爬取电影排行榜,爬取相对来说有点麻烦,爬取的速度也较慢.本次使用的lxml库,我个人是最喜欢的,爬取的语法很简单,爬取速度也快. 本次爬取的豆瓣书籍排行榜的首页地 ...
- 【我们一起写框架】MVVM的WPF框架(五)—完结篇
前言 这篇文章是WPF框架系列的最后一篇,在这里我想阐述一下我对框架设计的理解. 我对框架设计的理解是这样的: 框架设计不应该局限于任何一种设计模式,我们在设计框架时,应该将设计模式揉碎,再重组:这样 ...
- 解决 Vue 动态生成 el-checkbox 点击无法赋值问题
博客地址:https://ainyi.com/68 最近遇到一个问题,在一个页面需要动态渲染页面内的表单,其中包括 checkbox 表单类型,并且使用 Element 组件 UI 时,此时 v-mo ...
- Dapper 链式查询 扩展
Dapper 链式查询扩展 DapperSqlMaker Github地址:https://github.com/mumumutou/DapperSqlMaker 欢迎大佬加入 Demo: 查询 ...
- SQL 横转竖 、竖专横(转载) 列转行 行转列
普通行列转换 问题:假设有张学生成绩表(tb)如下: 姓名 课程 分数 张三 语文 张三 数学 张三 物理 李四 语文 李四 数学 李四 物理 想变成(得到如下结果): 姓名 语文 数学 物理 --- ...
- SQL优化--inner、left join替换in、not in、except
新系统上线,用户基数16万,各种查询timeout.打开砂锅问到底,直接看sql语句吧,都是泪呀,一大堆in\not in\except.这里总结一下,怎么替换掉in\not in\except. 1 ...
- 教程二 网页和lua交互修改openwrt
硬件 http://zhan.renren.com/h5/entry/3602888498044209332 GL-iNet 1 首先安装 webserver之lighttpd ,openwrt自带 ...