Storm入门(七)可靠性机制代码示例
一、关联代码
使用maven,代码如下。
pom.xml 参考 http://www.cnblogs.com/hd3013779515/p/6970551.html
MessageTopology.java

package cn.ljh.storm.reliability; import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.utils.Utils; public class MessageTopology {
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder(); builder.setSpout("MessageSpout", new MessageSpout(), 1);
builder.setBolt("SpilterBolt", new SpliterBolt(), 5).shuffleGrouping("MessageSpout");
builder.setBolt("WriterBolt", new WriterBolt(), 1).shuffleGrouping("SpilterBolt"); Config conf = new Config();
conf.setDebug(false); LocalCluster cluster = new LocalCluster();
cluster.submitTopology("messagetest", conf, builder.createTopology());
Utils.sleep(20000);
cluster.killTopology("messagetest");
cluster.shutdown();
}
}
MessageSpou.java
package cn.ljh.storm.reliability; import org.apache.storm.topology.OutputFieldsDeclarer; import java.util.Map;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values; import org.slf4j.Logger;
import org.slf4j.LoggerFactory; public class MessageSpout extends BaseRichSpout {
public static Logger LOG = LoggerFactory.getLogger(MessageSpout.class);
private SpoutOutputCollector _collector; private int index = 0;
private String[] subjects = new String[]{
"Java,Python",
"Storm,Kafka",
"Spring,Solr",
"Zookeeper,FastDFS",
"Dubbox,Redis"
}; public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
_collector = collector;
} public void nextTuple() { if(index < subjects.length){
String sub = subjects[index];
//使用messageid参数,使可靠性机制生效
_collector.emit(new Values(sub), index);
index++;
}
} public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("subjects"));
} @Override
public void ack(Object msgId) {
LOG.info("【消息发送成功!】(msgId = " + msgId + ")");
} @Override
public void fail(Object msgId) {
LOG.info("【消息发送失败!】(msgId = " + msgId + ")");
LOG.info("【重发进行中。。。】");
_collector.emit(new Values(subjects[(Integer)msgId]), msgId);
LOG.info("【重发成功!】");
} }
SpliterBolt.java
package cn.ljh.storm.reliability; import java.util.Map; import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values; public class SpliterBolt extends BaseRichBolt {
OutputCollector _collector;
private boolean flag = false; public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
_collector = collector;
} public void execute(Tuple tuple) { try{
String subjects = tuple.getStringByField("subjects"); // if(!flag && subjects.equals("Spring,Solr")){
// flag = true;
// int a = 1/0;
// } String[] words = subjects.split(",");
for(String word : words){
//注意:要携带tuple对象,用于处理异常时重发策略。
_collector.emit(tuple, new Values(word));
} //对tuple进行ack
_collector.ack(tuple);
}catch(Exception ex){
ex.printStackTrace();
//对tuple进行fail,使重发。
_collector.fail(tuple);
}
} public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
} }
WriterBolt.java
package cn.ljh.storm.reliability; import java.io.FileWriter;
import java.io.IOException;
import java.util.Map; import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Tuple;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory; public class WriterBolt extends BaseRichBolt {
private static Logger LOG = LoggerFactory.getLogger(WriterBolt.class);
OutputCollector _collector; private FileWriter fileWriter;
private boolean flag = false; public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
_collector = collector; if(fileWriter == null){
try {
fileWriter = new FileWriter("D:\\test\\"+"words.txt");
} catch (IOException e) {
e.printStackTrace();
}
} } public void execute(Tuple tuple) {
try {
String word = tuple.getStringByField("word"); // if(!flag && word.equals("Kafka")){
// flag = true;
// int a = 1/0;
// }
fileWriter.write(word + "\r\n");
fileWriter.flush();
} catch (Exception e) {
e.printStackTrace();
//对tuple进行fail,使重发。
_collector.fail(tuple);
}
//对tuple进行ack
_collector.ack(tuple);
} public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
二、执行效果
1、代码要点说明
MessageSpout.java
(1)发射tuple时要设置messageId来使可靠性机制生效
_collector.emit(new Values(sub), index);
(2)重写ack和fail方法
@Override
public void ack(Object msgId) {
LOG.info("【消息发送成功!】(msgId = " + msgId + ")");
} @Override
public void fail(Object msgId) {
LOG.info("【消息发送失败!】(msgId = " + msgId + ")");
LOG.info("【重发进行中。。。】");
_collector.emit(new Values(subjects[(Integer)msgId]), msgId);
LOG.info("【重发成功!】");
}
SpliterBolt.java
(1)发射新tuple时设置输入tuple参数,以使新tuple和输入tuple为一个整体
_collector.emit(tuple, new Values(word));
(2)完成处理后进行ack,失败时进行fail
_collector.ack(tuple); _collector.fail(tuple);
WriterBolt.java
(1)完成处理后进行ack,失败时进行fail
_collector.ack(tuple); _collector.fail(tuple);
2、正常处理结果

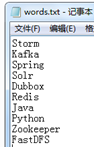
3、放开SpliterBolt 的错误代码
结果显示能够正确的重发。
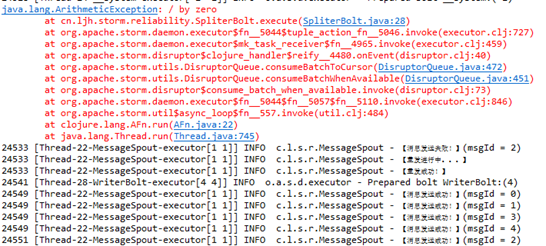
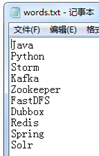
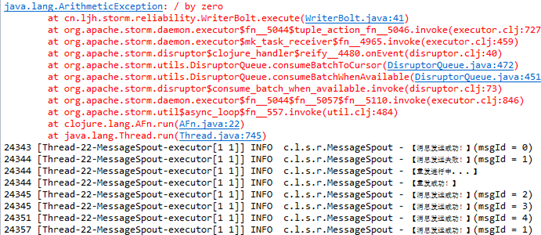
4、放开SpliterBolt 的错误代码
能够正确进行重发,但是文件中storm字符串出现了两次。

5、总结
通过以上测试,如果在第一个bolt处理时出现异常,可以让整个数据进行重发,如果第二个bolt处理时出现异常,也可以让整个数据进行重发,但是同时出现了重复处理的事务性问题,需要进行特殊的处理。
(1)如果数据入库的话,可以把messageId也进行入库保存。此messageId可以用来判断是否重复处理。
(2)事务性tuple尽量不要拆分。
(3)使用storm的Trident框架。
Storm入门(七)可靠性机制代码示例的更多相关文章
- Storm入门(四)WordCount示例
一.关联代码 使用maven,代码如下. pom.xml 和Storm入门(三)HelloWorld示例相同 RandomSentenceSpout.java /** * Licensed to t ...
- Linux信号机制代码示例
1 基本功能: 本Blog创建了两个进程(父子进程): 父进程: 执行文本复制操作,当收到 SIGUSR1信号后,打印出现在文件复制的进度: 子进程: 每个固定时间段向父进程发送一个 SIGUSR1 ...
- Storm入门(三)HelloWorld示例
一.配置开发环境 storm有两种操作模式: 本地模式和远程模式.使用本地模式的时候,你可以在你的本地机器上开发测试你的topology, 一切都在你的本地机器上模拟出来; 用远程模式的时候你提交的t ...
- <MyBatis>入门七 缓存机制
缓存机制 MyBatis包含强大的查询缓存特性,它可以非常方便的定制和配置.缓存可以极大的提升查询效率. MyBatis默认定义了两级缓存:一级缓存和二级缓存 1.默认情况下,只有一级缓存(sqlSe ...
- Storm入门(六)深入理解可靠性机制
转自http://blog.csdn.net/zhangzhebjut/article/details/38467145 一 可靠性简介 Storm的可靠性是指Storm会告知用户每一个消息单元是否在 ...
- My.Ioc 代码示例——使用观察者机制捕获注册项状态的变化
在 My.Ioc 中,要想在服务注销/注册时获得通知,可以通过订阅 ObjectBuilderRegistered 和 ObjectBuilderUnregistering 这两个事件来实现.但是,使 ...
- 中文代码示例之Angular入门教程尝试
原址: https://zhuanlan.zhihu.com/p/30853705 原文: 中文代码示例教程之Angular尝试 为了检验中文命名在Angular中的支持程度, 把Angular官方入 ...
- 中文代码示例之Vuejs入门教程(一)
原址: https://zhuanlan.zhihu.com/p/30917346 为了检验中文命名在主流框架中的支持程度, 在vuejs官方入门教程第一部分的示例代码中尽量使用了中文命名. 所有演示 ...
- 2017-10-31 中文代码示例教程之Vuejs入门&后续计划
"中文编程"知乎专栏原链 为了检验中文命名在主流框架中的支持程度, 这里把vuejs官方入门教程第一部分的示例代码中尽量使用了中文命名. 过程中有一些发现, 初步看来Vuejs对中 ...
随机推荐
- CentOS6.5系统挂载NTFS分区的硬盘
下载rpmforge,下载对应的版本,就是对应CentOS版本,还有32位与64位也要对应上.rpmforge拥有4000多种CentOS的软件包,被CentOS社区认为是最安全也是最稳定的一个软件仓 ...
- RabbitMQ入门:认识并安装RabbitMQ(以Windows系统为例)
最近在学习Spring Cloud,其中消息总线Spring Cloud Bus是必不可少的,但是Spring Cloud Bus目前只支持RabbitMQ和kafka,因此学习RabbitMQ势在必 ...
- mongo Shell初体验
mongo shell是一个MongoDB的交互式JavaScript接口.您可以使用mongo shell来查询和更新数据以及执行管理操作. 打开cmd命令行,输入mongo,就可以进入mongo ...
- ajax跨域问题(php)
ajax出现请求跨域错误问题,主要原因就是因为浏览器的"同源策略". 解决方法(我只用过下面这3种): 1. 架设服务器代理:即浏览器请求同源服务器,再由后者请求外部服务(之前博主 ...
- 你不知道的JavaScript--Item20 作用域与作用域链(scope chain)
作用域是JavaScript最重要的概念之一,想要学好JavaScript就需要理解JavaScript作用域和作用域链的工作原理.今天这篇文章对JavaScript作用域和作用域链作简单的介绍,希望 ...
- app后端设计(14)--LBS的偏移问题
刚开始做LBS的时候,有一个问题,通过手机获取的坐标,放到百度地图或高德地图上,总是会出现偏移,例如,当时是在微信的前总部"南方通讯大厦"附近获取的坐标,那是把坐标放到百度地图上却 ...
- Android 框架练成 教你打造高效的图片加载框架
转载请标明出处:http://blog.csdn.net/lmj623565791/article/details/41874561,本文出自:[张鸿洋的博客] 1.概述 优秀的图片加载框架不要太多, ...
- MySQL 大表优化方案
当MySQL单表记录数过大时,增删改查性能都会急剧下降,可以参考以下步骤来优化: 单表优化 除非单表数据未来会一直不断上涨,否则不要一开始就考虑拆分,拆分会带来逻辑.部署.运维的各种复杂度,一般以整型 ...
- Nginx重新编译添加新模块
找到nginx的安装包目录,如果没有的话去官网重新下载 查看ngixn版本极其编译参数 /usr/local/nginx/sbin/nginx -V 进入nginx源码目录,重新设置nginx ./c ...
- STM32基于固件库新建MDK工程模板(精简版)
上个博文理论讲解的东西太多,太复杂,这里把所有步骤全部贴出 1.新建一个工程文件夹LED 2.LED文件夹下建立如下文件夹 3.Project –>New Uvision Project 到US ...