Python爬取南京市往年天气预报,使用pyecharts进行分析
上一次分享了使用matplotlib对爬取的豆瓣书籍排行榜进行分析,但是发现python本身自带的这个绘图分析库还是有一些局限,绘图不够美观等,在网上搜索了一波,发现现在有很多的支持python的绘图库可以使用,本次尝试使用pyecharts对爬取的数据进行分析,然后发现这个库实在是太好用了,生成的库也很好看,还能生成动态图,简直是进行数据分析的一大神器!
pyecharts: pyecharts是一个封装百度开源图表库echarts的包,使用pyecharts可以生成独立的网页,也可以在flask、django中集成使用。
本次爬取的首页地址是:
http://www.tianqihoubao.com/lishi/nanjing.html
爬取步骤:
- 爬取主网页,获取进入每个南京市具体年份月份的天气数据的链接
- 爬取上方获取的具体链接的数据
- 存储数据
- 对数据进行筛选后使用pyecharts进行分析
话不多说,马上开始吧!
- 步骤一
从上图可知,我们需要先获取进入每个具体月份的链接,才能爬取想要的数据,所以首先定义获取具体链接的函数,然后在爬取会方便很多;查看网页源代码查找目标所在位置,本次我依然是使用lxml库来进行数据的爬取(PS:感觉习惯了lxml其他库就不好用了),这里需要注意的是,我是将获得的结果一个一个的存入列表,这种方法很笨,但作为菜鸟的我确实不知道其他方法了,还有就是发现爬取的部分链接缺了一点,所以又定义了一个函数来补上。
具体代码如下: 注:转载代码请标明出处
def get_mainurl(url): #定义获取月份天气的详细url 函数
res = requests.get(url, headers=headers)
main_url = []
if res.status_code == 200: #判断请求状态
selector = etree.HTML(res.text)
htmlurls = selector.xpath('//div[contains(@id,"content")]/div') #循环点
try:
for htmlurl in htmlurls:
Jan = htmlurl.xpath('ul[1]/li[2]/a/@href')[0] #一月份天气url
main_url.append(Jan) #将网址放入列表中,一个一个放是很蠢的方法,但我也确实不知道其他方法了,下同
Feb = htmlurl.xpath('ul[1]/li[3]/a/@href')[0] #二月份天气url
main_url.append(Feb)
Mar = htmlurl.xpath('ul[1]/li[4]/a/@href')[0] #同上,下类推
main_url.append(Mar)
Apr = htmlurl.xpath('ul[2]/li[2]/a/@href')[0]
main_url.append(Apr)
May = htmlurl.xpath('ul[2]/li[3]/a/@href')[0]
main_url.append(May)
June = htmlurl.xpath('ul[2]/li[4]/a/@href')[0]
main_url.append(June)
July = htmlurl.xpath('ul[3]/li[2]/a/@href')[0]
main_url.append(July)
Aug = htmlurl.xpath('ul[3]/li[3]/a/@href')[0]
main_url.append(Aug)
Sep = htmlurl.xpath('ul[3]/li[4]/a/@href')[0]
main_url.append(Sep)
Oct = htmlurl.xpath('ul[4]/li[2]/a/@href')[0]
main_url.append(Oct)
Nov = htmlurl.xpath('ul[4]/li[3]/a/@href')[0]
main_url.append(Nov)
Dec = htmlurl.xpath('ul[4]/li[4]/a/@href')[0]
main_url.append(Dec) time.sleep(0.5) #休眠0.5s
except IndexError:
pass
return main_url #将存了所有url的列表返回
else:
pass def link_url(url): #上面获取的url是不完整的,此函数使其完整
final_urls= []
list_urls = get_mainurl(url)
for list_url in list_urls:
if len(list_url) < 30: #因为获取的url有一些少了‘/lishi/’,所以需要判断一下
list_url = 'http://www.tianqihoubao.com/lishi/' + list_url
final_urls.append(list_url)
else:
list_url = 'http://www.tianqihoubao.com' + list_url
final_urls.append(list_url)
return final_urls
- 步骤二
接下来是获取所需的数据,遍历所在节点就行了,需要注意的是要跳过第一个节点,因为其内部没有内容。
代码如下:
def get_infos(detail_url): #爬取月份天气详细数据函数
main_res = requests.get(detail_url, headers=headers)
main_sele = etree.HTML(main_res.text)
main_infos = main_sele.xpath('//div[@class="hd"]/div[1]/table/tr')
i = True
try:
for info in main_infos:
if i: #此处i的作用是跳过第一次循环,因为第一个是非天气数据
i = False
continue
else:
date = info.xpath('td[1]/a/text()')[0].replace("\r\n", '').replace(' ', '') #去掉换行符、空格等,下同
weather = info.xpath('td[2]/text()')[0].replace("\r\n", '').replace(' ', '')
temps = info.xpath('td[3]/text()')[0].replace('\r\n', '').replace(' ', '')
clouds = info.xpath('td[4]/text()')[0].replace("\r\n", '').replace(' ', '')
with open('Nanjing.csv', 'a+', newline='', encoding='utf-8')as fp: #存入csv文件
writer = csv.writer(fp)
writer.writerow((date, weather, temps, clouds))
except IndexError:
pass
- 步骤三
接下来执行主程序存储就行了,使用了多进程来爬取加快速度,所以爬取的数据排列可能不按顺序,使用wps或excel自行排序即可。
下方附上剩余代码:
import requests
from lxml import etree
import time
import csv
from multiprocessing import Pool #请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
} if __name__ == '__main__': #执行主程序
url = 'http://www.tianqihoubao.com/lishi/nanjing.html' #获取月份天气url的网址
get_mainurl(url)
details = link_url(url)
with open('Nanjing.csv', 'a+', newline='', encoding='utf-8')as ff: #写入第一行作为表头
writer = csv.writer(ff)
writer.writerow(('日期', '天气状况', '气温', '风力风向'))
pool = Pool(processes=4) #使用多进程爬取
pool.map(get_infos, details) #需要注意爬取结果并不是按顺序的,可以用excel进行排序
部分数据如下:

- 步骤四
进行数据分析之前,先用pandas的read_csv()方法将数据读出,然后将2011-2018年的温度和天气状况提取出来进行分析,这里温度需要将数字提取出来,天气状况需要将 ‘/’去掉,还有因为一天的天气数据是多个的(例如一天气温有最高温和最低温),所以后面分析时发现数据量大于8年总天数,这是正常的。
由于我也是第一次使用pyecharts,所以话不多说,直接上代码:
import pandas as pd
from pyecharts import Line, Pie, Page, Bar page = Page(page_title='南京气温分析') #page 使多个图位于一个网页,网页名 pd.set_option('display.max_rows', None) #设置使dataframe 所有行都显示
df = pd.read_csv('Nanjing.csv') #读取天气数据 #获取最高气温
Max_temps = []
for max_data in df['气温']:
Max_temps.append(int(max_data[0:2].replace('℃','')))
Max_temps = Max_temps[:-109] #获取最低气温
Low_temps = []
for low_data in df['气温']:
Low_temps.append(int(low_data[-3:-1].replace('/', '')))
Low_temps = Low_temps[:-109] #获取2011年一月气温数据
attr = ['{}号'.format(str(i))for i in range(1,32)]
Jan_Htemps = Max_temps[:31]
Jan_Ltemps = Low_temps[:31]
#绘制气温折线图
line = Line('南京市2011年一月气温变化') #赋予将折线图对象, 命名
line.add('当日最高气温', attr, Jan_Htemps, mark_point=['average', 'max', 'min'], #显示平均、最大/小值
mark_point_symbol='diamond', #特殊点用钻石形状显示
mark_point_textcolor='red', #标注点颜色
is_smooth=True #图像光滑
)
line.add('当日最低气温', attr, Jan_Ltemps, mark_point=['average', 'max', 'min'],
mark_point_symbol='arrow',
mark_point_textcolor='blue'
)
line.use_theme('dark') #背景颜色
line.show_config() #调试输出pyecharts的js配置信息
page.add_chart(line) #添加到page #统计2011-2018年的每天最高温的气温分布情况,分四个阶梯
Hzero_down = Hthrity_up = Hzup_fifdown = Hfifup_thrdown = 0
for i in Max_temps:
if i <= 0:
Hzero_down += 1
elif i<=15:
Hzup_fifdown += 1
elif i<=30:
Hfifup_thrdown += 1
else:
Hthrity_up +=1 #统计2011-2018年的每天最高温的气温分布情况分,分四个阶层
Lfiv_down = L25_up = Lfiv_tendown = Ltenup_25down = 0
for i in Low_temps:
if i <= -5:
Lfiv_down += 1
elif i<=10:
Lfiv_tendown += 1
elif i<=25:
Ltenup_25down += 1
else:
L25_up +=1 #绘图
attr2 = ['0℃及以下', '0-15℃', '15-30℃', '30℃及以上'] #标签属性
H_data = [Hzero_down, Hzup_fifdown, Hfifup_thrdown, Hthrity_up] #数据
pie = Pie('南京市2011年-2018年每日最高气温分布', title_pos='center', title_color='red') #绘制饼图,标题位于中间,标题颜色
pie.add('',attr2, H_data, is_label_show=True, #展示标签
legend_pos='right', legend_orient='vertical', #标签位置,标签排列
label_text_color=True, legend_text_color=True, #标签颜色
)
pie.show_config()
page.add_chart(pie, name='饼图') #绘制环形图
attr3 = ['-5℃及以下', '-5-10℃', '10-25℃', '25℃及以上']
L_data = [Lfiv_down, Lfiv_tendown, Ltenup_25down, L25_up]
pie2 = Pie('南京市2011年-2018年每日最低气温分布', title_pos='center')
pie2.add('',attr3, L_data, radius=[30, 70], is_label_show=True, #radius环形图内外圆半径
label_text_color=None, legend_orient='vertical',
legend_pos='left', legend_text_color=None
)
pie2.show_config()
page.add_chart(pie2, name='环形图') #绘制南京2011-2018年天气状况条形统计图
Weather_NJ = []
for Weathers in df['天气状况']:
Weather_s = Weathers.split('/')
Weather_NJ.append(Weather_s[0])
Weather_NJ.append(Weather_s[1])
Weather_NJ = Weather_NJ[:-218] sunny = rainy = yin_cloudy = lightening = duo_cloudy = snowy = 0
for t in Weather_NJ:
if t == '晴':
sunny += 1
elif t == '阴':
yin_cloudy += 1
elif t == '多云':
duo_cloudy += 1
elif t == '雷阵雨':
lightening += 1
elif '雨' in t and t != '雨夹雪':
rainy += 1
elif '雪' in t:
snowy += 1
else:
pass
Weather_attr = ['晴', '雨天', '多云', '阴天', '雷阵雨', '雪天']
Weather_datas = [sunny, rainy, duo_cloudy, yin_cloudy, lightening, snowy]
bar = Bar('南京市2011-2018年天气情况统计', '注意:一天有两个天气变化,部分日期天气情况可能丢失', title_pos='center')
bar.add('天气状况', Weather_attr, Weather_datas, is_more_utils=True,
mark_point=['max', 'min'], legend_pos='right'
)
bar.show_config()
page.add_chart(bar) page.render('all_analysis.html') #网页地址
图像结果如下:

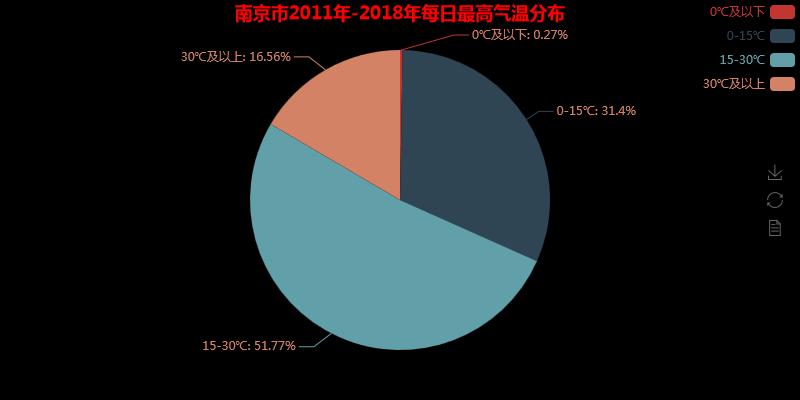
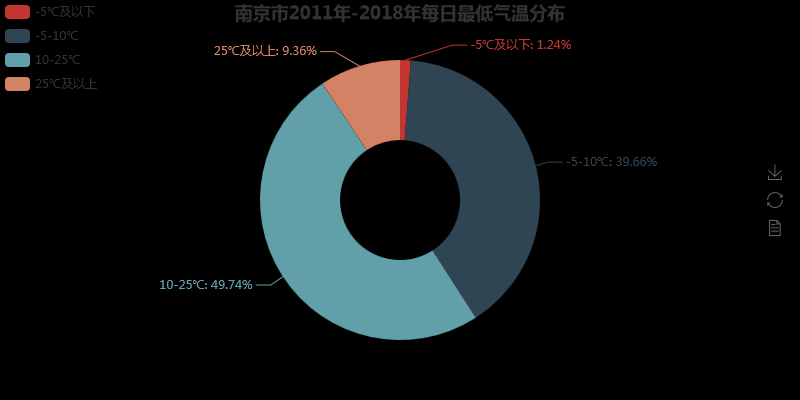

是不是发现使用pyecharts得到的图表更加好看,这里上传的图片是静态的,在网页打开的时查看其实是动态的。
这里只爬取了南京市的历史天气,感兴趣的朋友可以尝试爬取更多城市的,甚至可以在此基础上编写一个小软件,随时随地查看不同地区的历史天气,不过前提是该网站的源代码不发生大变动。
本次分享就到此为止,如果有错误或者疑问或者是建议欢迎大家随时指正,我也会积极回应。
Python爬取南京市往年天气预报,使用pyecharts进行分析的更多相关文章
- Python学习-使用Python爬取陈奕迅新歌《我们》网易云热门评论
<后来的我们>上映也有好几天了,一直没有去看,前几天还爆出退票的事件,电影的主题曲由陈奕迅所唱,特地找了主题曲<我们>的MV看了一遍,还是那个感觉.那天偶然间看到Python中 ...
- python爬取网站数据保存使用的方法
这篇文章主要介绍了使用Python从网上爬取特定属性数据保存的方法,其中解决了编码问题和如何使用正则匹配数据的方法,详情看下文 编码问题因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这 ...
- Python爬取跑男的评论,看看大家都在看谁吧
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. 以下文章来源于菜J学Python,作者: J哥 Python爬取爬取腾讯视频弹幕视频讲解 http ...
- 毕设之Python爬取天气数据及可视化分析
写在前面的一些P话:(https://jq.qq.com/?_wv=1027&k=RFkfeU8j) 天气预报我们每天都会关注,我们可以根据未来的天气增减衣物.安排出行,每天的气温.风速风向. ...
- Python 爬取所有51VOA网站的Learn a words文本及mp3音频
Python 爬取所有51VOA网站的Learn a words文本及mp3音频 #!/usr/bin/env python # -*- coding: utf-8 -*- #Python 爬取所有5 ...
- python爬取网站数据
开学前接了一个任务,内容是从网上爬取特定属性的数据.正好之前学了python,练练手. 编码问题 因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了. 问题要从文字的编码讲 ...
- python爬取某个网页的图片-如百度贴吧
python爬取某个网页的图片-如百度贴吧 作者:vpoet mail:vpoet_sir@163.com 注:随意copy,不用告诉我 #coding:utf-8 import urllib imp ...
- Python:爬取乌云厂商列表,使用BeautifulSoup解析
在SSS论坛看到有人写的Python爬取乌云厂商,想练一下手,就照着重新写了一遍 原帖:http://bbs.sssie.com/thread-965-1-1.html #coding:utf- im ...
- 使用python爬取MedSci上的期刊信息
使用python爬取medsci上的期刊信息,通过设定条件,然后获取相应的期刊的的影响因子排名,期刊名称,英文全称和影响因子.主要过程如下: 首先,通过分析网站http://www.medsci.cn ...
随机推荐
- Jersey VS Django-Rest
在对Restful服务框架做对比前,主要先说说Restful设计的三大主要元素:以资源为核心的资源方法.资源状态.关系链接超媒体表述. 辅助的有内容协商.安全.版本化设计等. Jersey作为Java ...
- 移动 Web 的用户界面设计
http://www.ibm.com/developerworks/cn/mobile/wa-interface/index.html 简介 在创新者试图探索新的可能性的同时,新兴技术也在经历快速变化 ...
- Python自学编程开发路线图(文中有免费资源)
Python核心编程 免费视频资源<Python入门教程>:http://yun.itheima.com/course/145.html Python 基础学习大纲 所处阶段 主讲内容 技 ...
- HTML 学习笔记 day three
HTML学习笔记 Day three 7.2插入多媒体元素 插入音乐 语法结构:<embed src=”音乐文件的路径”></embed> 属性: Autostart:他只有 ...
- ES入门笔一
ES6一共有6种声明变量的方法 --ES5只有var 和 function --ES6新增了let.const.import和class四种 ES6新增let和const,用来声明变量,是对var的扩 ...
- Nginx 的安装与配置
一.下载 Linux:CentOS 7.3 64位 Nginx:nginx-1.13.1 安装目录:/usr/local/ wget http://nginx.org/download/nginx-1 ...
- 循环中else的用法
name = 'hello' for x in name: print(x) if x == 'l': break #退出for循环 else: print("==for循环过程中,如果没有 ...
- printf输出格式介绍(转)
格式代码 A ABC ABCDEFGH %S A ABC ABCDEFGH %5S ####A ##ABC ABCDEFGH %.5S A ABC ABCDE %5.5S ####A ##ABC AB ...
- 【转】Javascript错误处理——try…catch
无论我们编程多么精通,脚本错误怎是难免.可能是我们的错误造成,或异常输入,错误的服务器端响应以及无数个其他原因. 通常,当发送错误时脚本会立刻停止,打印至控制台. 但try...catch语法结构可以 ...
- 微信小程序AES解密失败
微信小程序分享群获取群id时后端接口返回"微信AES解密失败",后来定位到原因是服务端用于解密的session_key失效.用户获取到openID存在缓存后,就不会每次login获 ...