第七章——集成学习和随机森林(Ensemble Learning and Random Forests)
俗话说,三个臭皮匠顶个诸葛亮。类似的,如果集成一系列分类器的预测结果,也将会得到由于单个预测期的预测结果。一组预测期称为一个集合(ensemble),因此这一技术被称为集成学习(Ensemble Learning)。集成学习算法称作集成方法(Ensemble method)。
例如,可以基于训练集的不同随机子集,训练一组决策树分类器。做预测是,首先拿到每一个决策树的预测结果,得票数最多的一个类别作为最终结果,这就是随机森林。
此外,通常还可以在项目的最后使用集成方法。比如已经创建了几个不错的分类器,可以将其集成为一个更优秀的分类器。
本章介绍了最手欢迎的分类器,包括bagging,boosting,stacking。
7.1 投票分类器(Voting Classifiers)
假如训练了一些分类器,如图7-1所示,
7-1. 训练不同的分离器
根据每一分类器的预测结果,我们选择得票最多的分类器作为最终预测结果,如图7-2所示。这种多数票决分类器被称作硬投票(hard voting)分类器。
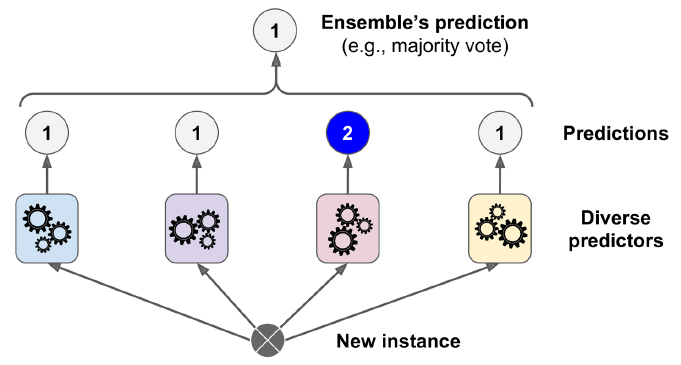
7-2. 硬投票分类器
一般情况下,投票分类器会优于它所集成的每一个分类器。即使每一个单独的分类器都很弱(预测结果仅仅略高于随机猜测),集成分类器也可以很强,只要弱分类器是多种多样不同的分类器。
为什么会这么神奇呢?假设一枚硬币有缺陷,会导致51%的概率正面朝上,49%的概率反面朝上。如果投掷1000次,大约会有510次正面朝上,490次反面朝上,大多是是朝上的。通过数学计算可知,投掷1000次,大部分正面朝上的概率是75%(可以根据林德贝格-勒维中心极限定理求得)。投掷的次数越多,这一概率越高(投掷10000次,这一概率是97%)。这是由于大数定律:在重复试验中,随着试验次数的增加,事件发生的频率趋于其期望。
类似的,假设有1000个分类器,其单独的正确率仅有51%,通过多数票决预测分类,其正确率可达75%。不过,这需要分类器完全独立,错误不相关。但由于是在同样的数据集训练的,错误的类型可能相同,从而降低了正确率。
如果分类器可以给出类别的概率(也就是具有predict_proba()方法),那么可以使Scikit-Learn的最终预测结果为平均概率最高的那一类别。这被称作软投票(soft voting)。软投票的性能一般优于硬投票。
7.2 Bagging and Pasting
另一种获得不同分类器的方法是,训练算法虽然是相同的,但训练数据确是从训练集中随机选取的不同子集。如果子集的选取是有放回采样(sampling with replacement。replace在这里是复位、归还的意思,不是代替的意思。),这一方法称为bagging(bootstrap aggregating的简称。在统计学上,有放回采样称为bootstrapping)。如果是无放回采样(sampling without replacement),则称之为pasting。
7.2.1 Bagging and Pasting in Scikit-Learn
介绍了如何使用BaggingRegressor
如图7-5所示,集成树和单个子树有大致相当的bias,但是前者的variance更小。(二者在训练集上的误差大致相当,但是集成树边界更规则,更容易一般化。)
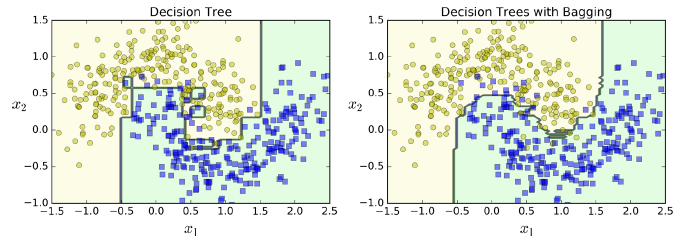
图7-5. 一棵决策树 Vs 500棵决策树bagging集成
有放回抽样(Bootstrapping)生成的子集之间更具多样性,因此bagging比pasting具有稍高的bias,但是预测期之间的相关性也较小从而集成后的variance会减小。总体来说,bagging更优一些。
7.2.2 Out-of-Bag评估
使用bagging时,对于某一个预测器,某些样本可能被抽样多次,也有些样本可能从没被抽样到。事实上,对于每一个预测期,平均有63%的样本会被抽样到,剩下的从没有被抽到的37%样本称为out-of-bag (oob)样本。注意,对每个预测器,这是不同的37%样本。
可以证明为什么平均37%的样本不会被抽到。假设样本总数是$m$,在$m$次有放回抽样中,一个样本始终没有被抽中的概率为$P(oob)= (1 - \frac{1}{m})^m$,当$m$足够大时,
\begin{align*}
\lim_{m \rightarrow +\infty}(1 - \frac{1}{m})^m &= \lim_{m \rightarrow +\infty}(\frac{m - 1}{m})^m \\
&= \lim_{m \rightarrow +\infty}(\frac{1}{\frac{m}{m-1}})^m \\
&= \lim_{m \rightarrow +\infty}(\frac{1}{1 + \frac{1}{m-1}})^m \\
&= \lim_{m \rightarrow +\infty}\frac{1}{(1 + \frac{1}{m-1})(1 + \frac{1}{m-1})^{m-1}} \\
&= \lim_{m \rightarrow +\infty}\frac{1}{(1 + \frac{1}{m-1})e} \\
&= \frac{1}{e} \\
&\approx 0.37
\end{align*}
对于某一个预测器来说,它并没有使用oob样本,因此该预测器可以使用oob样本进行评估,而不用专门划分出校验集。
7.3 Random Patches and Random Subspaces
BaggingClassifier也支持特征抽样,这通过超参数max_features和bootstrap_features控制。工作原理与max_samples和bootstrap类似,只不过把样本抽样替换成了特征抽样。
这一方法在高维度输入(比如图像)是很有用。样本和特征均抽样称为Random Patches method,只对特征抽样称为Random Subspaces method。
7.4 随机森林(Random Forests)
随机森林是一系列决策树的集成,一般使用bagging方法。
7.4.1 Extra-Trees
在随机森林中生成一棵决策树时,会使用随机选择的特征子集,来切分数据集。还可以通过使用随机的阈值来增加随机性。这种更为随机的森林被称作Extremely Randomized Tree sensemble(简称Extra-Trees)。
7.4.2 特征重要性(Feature Importance)
如果观察一棵决策树,会发现越靠近根节点的特征越重要。可以通过计算一个特征在森林中的平均深度来评估其重要性。
7.5 Boosting
Boosting (最初被称作hypothesis boosting)是指所有可以联合一系类弱学习器使其成为强学习器的方法。其基本思想是循环地训练预测器,每一次都尝试更新其预测。现在有很多Boosting方法,最有名的是AdaBoost(Adaptive Boosting的简称)和Gradient Boosting。
7.5.1 AdaBoost
这一技术技术在训练的时候,多关照一下预测错的实例 。例如,创建一个AdaBoost分类器。第一个分类器在训练集上训练并作出预测。然后误分类实例的权重就会增加。第二个分类器会在权重更新后的训练集上训练,然后预测、更新权重。重复这一过程,如图7-7所示。
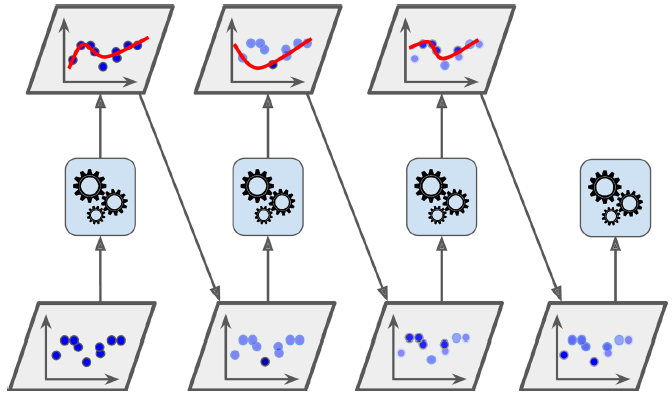
图7-7. AdaBoost更新实例权重并连续训练
等所有预测器训练完成后,预测过程类似于bagging或者pasting,只不过每一个预测期根据其总体精度,会有不同的权重。
AdaBoost算法存在一个劣势,那就是不能并行运算,因为后面预测器的训练,需要用到之前预测器的预测结果。
AdaBoost详解:
训练样本大小$m$,每一个实例权重$w^{(i)}$初始化设置为$\frac{1}{m}$。第一个预测器进行训练,并计算训练集的加权误差率(weighted error rate)$r_1$。
第$j$个预测器的加权误差率:
\begin{align*}
r_j = \frac{\sum_{i=1,\hat{y}_j^{(i)} \neq y^{(i)}}^{m}w^{(i)}}{\sum_{i=1}^{m}w^{(i)}}
\end{align*}
其中,$\hat{y}_j^{(i)}$ 是第$j$个预测器对第$i$个实例的预测值。
预测器权重:
\begin{align*}
\alpha_j = \eta \, log \, \frac{1-r_j}{r_i}
\end{align*}
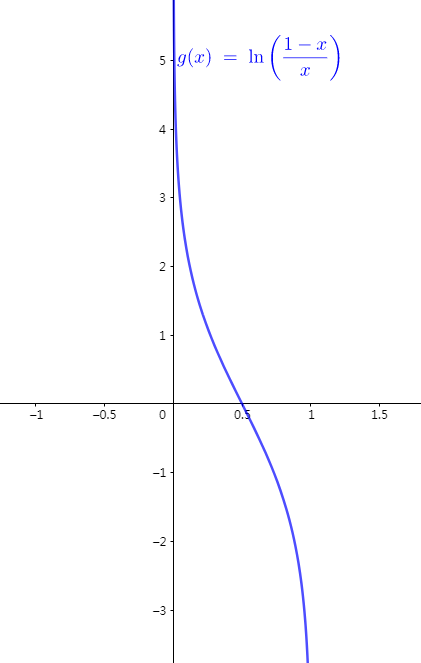
其中,$\eta$是学习率超参数(默认是1)。错误率越低,权重越大。错误率接近50%(也就是随机猜测),权重接近0。错误率低于50%,则权重是负的。可参考下图。
实例的权重将按照如下方式更新:
\begin{align*}
&for\ i = 1, 2, \cdots ,m \\
&w_{(i)} \leftarrow \left\{\begin{matrix}
w^{(i)} &if \ \hat{y}_j^{(i)} = y_{(i)} \\
w^{(i)}\ exp(a_j) &if \ \hat{y}_j^{(i)} \neq y_{(i)}
\end{matrix}\right.
\end{align*}
然后权重还要进行标准化。(也就是除以$\sum_{i=1}^{m}w^{(i)}$)
紧接着,一个新的预测试会使用更新后的权重,重复这一训练过程。如果预测器个数超过预定值,或者预测结果已经足够好,算法将会停止。
AdaBoost算法的预测:
\begin{align*}
\mathop{\arg\max}\limits_{k}\mathop{\sum_{j=1}^{N}}\limits_{\hat{y}_j(X)=k} a_j
\end{align*}
其中,N是预测器个数。
事实上,Scikit-Learn使用的是一用被称作SAMME(Stagewise Additive Modeling using a Multiclass Exponential loss function)的多分类版本 AdaBoost。如果仅仅是二分类,SAMME和AdaBoost是等价的。
如果发现AdaBoost在训练集上过拟合,可以减少评估器的数量,或者增加更强的正则约束。
7.5.2 Gradient Boosting
与AdaBoost类似,Gradient Boosting也是不停地增加预测器。不同的是,Gradient Boosting新增加的预测器,回去拟合其前任的残差(residual errors)。该算法处理回归任务表现很好,被称作Gradient Tree Boosting或者Gradient Boosted Regression Trees (GBRT,梯度提升决策树)。
与之类似的GBDT (Gradient Boosting Decision Tree)好像更出名一些。有空学习一下GBDT。
7.6 Stacking
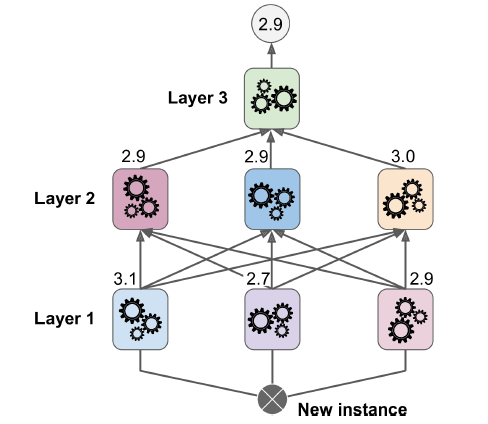
stacking(stacked generalization的简称)是本章最后一个集成方法。该方法思想很简单:与其使用简陋的集成方法(比如硬投票),何不专门训练一个集成方法?图7-12展示了这一预测过程。底部的三个预测器给出了3个不同的结果(3.1、2.7、2.9),上面一个预测器(被称作混合器,blendor)根据这3个结果,给出了最终的预测(3.0)。
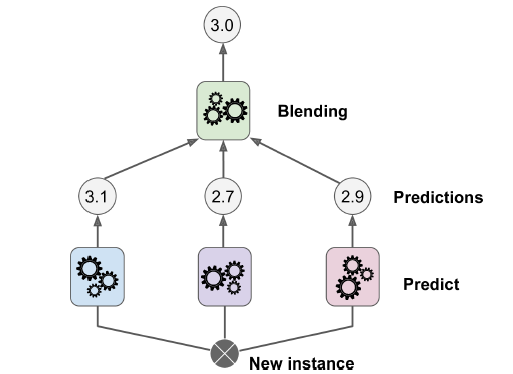
图7-12. 通过混合预测器进行集成预测
为了训练blender,常用的方法是使用一个hold-out数据集(hold-out set)。其工作方式如下:
首先将训练集划分为两个子集,第一个子集用于训练第一层的预测器,如图7-13所示:
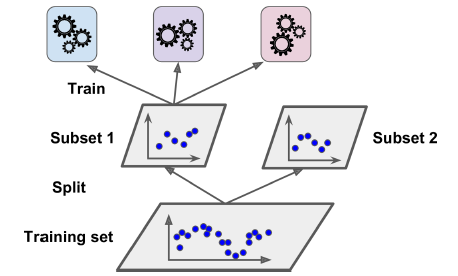
图7-13. 训练第一层
然后,使用第一层训练出的预测器对第二个子集(也成为hold-out集)进行预测。现在hold-out集有三个预测值。这三个预测值和hold-out集的目标值组成新的训练集,用于训练blender,如图7-14所示。
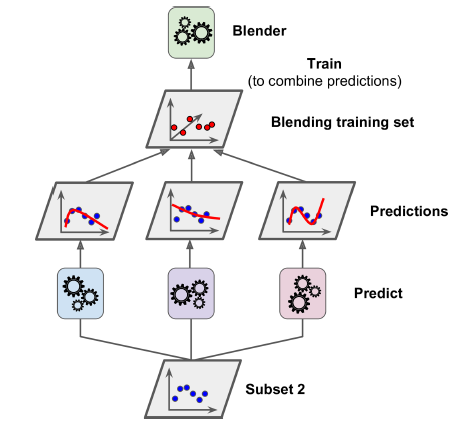
图7-14. 训练blender
此外,也可以再复杂一点,训练多个blender。把训练集分为3份。第一份训练第一层,第二份用于产生第二层的训练集,第三份用于产生第三次的训练集。其预测过程如图7-15所示。
7-15. 多层stacking ensemble预测流程
Scikit-Learn并不直接支持stacking,不过github有开源实现:https://github.com/viisar/brew
第七章——集成学习和随机森林(Ensemble Learning and Random Forests)的更多相关文章
- bagging与boosting集成学习、随机森林
主要内容: 一.bagging.boosting集成学习 二.随机森林 一.bagging.boosting集成学习 1.bagging: 从原始样本集中独立地进行k轮抽取,生成训练集.每轮从原始样本 ...
- 大白话5分钟带你走进人工智能-第二十九节集成学习之随机森林随机方式 ,out of bag data及代码(2)
大白话5分钟带你走进人工智能-第二十九节集成学习之随机森林随机方式 ,out of bag data及代码(2) 上一节中我们讲解了随机森林的基本概念,本节的话我们讲解随机森 ...
- 【机器学习实战】第7章 集成方法(随机森林和 AdaBoost)
第7章 集成方法 ensemble method 集成方法: ensemble method(元算法: meta algorithm) 概述 概念:是对其他算法进行组合的一种形式. 通俗来说: 当做重 ...
- 《机器学习实战(基于scikit-learn和TensorFlow)》第七章内容学习心得
本章主要讲述了“集成学习”和“随机森林”两个方面. 重点关注:bagging/pasting.boosting.stacking三个方法. 首先,提出一个思想,如果想提升预测的准确率,一个很好的方法就 ...
- [ML学习笔记] 决策树与随机森林(Decision Tree&Random Forest)
[ML学习笔记] 决策树与随机森林(Decision Tree&Random Forest) 决策树 决策树算法以树状结构表示数据分类的结果.每个决策点实现一个具有离散输出的测试函数,记为分支 ...
- 机器学习之路:python 集成回归模型 随机森林回归RandomForestRegressor 极端随机森林回归ExtraTreesRegressor GradientBoostingRegressor回归 预测波士顿房价
python3 学习机器学习api 使用了三种集成回归模型 git: https://github.com/linyi0604/MachineLearning 代码: from sklearn.dat ...
- 机器学习之——集成算法,随机森林,Bootsing,Adaboost,Staking,GBDT,XGboost
集成学习 集成算法 随机森林(前身是bagging或者随机抽样)(并行算法) 提升算法(Boosting算法) GBDT(迭代决策树) (串行算法) Adaboost (串行算法) Stacking ...
- 【Python机器学习实战】决策树与集成学习(七)——集成学习(5)XGBoost实例及调参
上一节对XGBoost算法的原理和过程进行了描述,XGBoost在算法优化方面主要在原损失函数中加入了正则项,同时将损失函数的二阶泰勒展开近似展开代替残差(事实上在GBDT中叶子结点的最优值求解也是使 ...
- 深度学习Bible学习笔记:第七章 深度学习中的正则化
一.正则化介绍 问题:为什么要正则化? NFL(没有免费的午餐)定理: 没有一种ML算法总是比别的好 好算法和坏算法的期望值相同,甚至最优算法跟随机猜测一样 前提:所有问题等概率出现且同等重要 实际并 ...
随机推荐
- Java 继承Thread类和实现Runnable接口的区别
ava中线程的创建有两种方式: 1. 通过继承Thread类,重写Thread的run()方法,将线程运行的逻辑放在其中 2. 通过实现Runnable接口,实例化Thread类 在实际应用中,我 ...
- 【Java编程】Java中的字符串匹配
在Java中,字符串的匹配可以使用下面两种方法: 1.使用正则表达式判断字符串匹配 2.使用Pattern类和Matcher类判断字符串匹配 正则表达式的字符串匹配: ...
- Linux文件系统构成(第二版)
Linux文件系统构成 /boot目录: 内核文件.系统自举程序文件保存位置,存放了系统当前的内核[一般128M即可] 如:引导文件grub的配置文件等 /etc目录: 系统常用的配置文件,所以备份系 ...
- javascript加RoR实现JSONP
我们知道不同域中的js代码受同源策略的限制,不同域中的AJAX同样受此限制,不过使用html中的script远程脚本可以跳过该限制,下面我们实际看一下利用RoR和js如何实现所谓的JSONP. 这里只 ...
- unix下对于字符串变量的各种操作总结
在unix like系统的shell中,提供了很多操作字符串变量的灵活语法,我们接下来依次来看一看. apple@kissAir: ~$path=$PATH apple@kissAir: ~$echo ...
- 数据准备<2>:数据质量检查-实战篇
上一篇文章:<数据质量检查-理论篇>主要介绍了数据质量检查的基本思路与方法,本文作为补充,从Python实战角度,提供具体的实现方法. 承接上文,仍然从重复值检查.缺失值检查.数据倾斜问题 ...
- 使用 Helm - 每天5分钟玩转 Docker 容器技术(163)
Helm 安装成功后,可执行 helm search 查看当前可安装的 chart. 这个列表很长,这里只截取了一部分.大家不禁会问,这些 chart 都是从哪里来的? 前面说过,Helm 可以像 a ...
- 如何卸载Centos自带jdk
1.搜索安装的jdk: rpm -qa|grep jdk 结果如下: java-1.7.0-openjdk-1.7.0.45-2.4.3.3.el6.x86_64 java-1.6.0-openjdk ...
- java中面试可能会问的问题
为了明年的面试,把面试中可能遇到的关于java的问题记录在下面,纯个人理解,如果有误,请指正! 1.java中拷贝的三种方式,以及他们的区别. 这三种方式分别是:直接赋值,浅拷贝,深拷贝.第一种直接赋 ...
- C#学习笔记 day_two
C#学习笔记 day two Chapter 2 c#基本概念 2.1编译与运行hello world应用程序 点击f5或者vs2010中的运行图标即可 2.3C#的概念拓展 (1)继承性:一个类含有 ...