Python推荐算法学习1
1.闵可夫斯基距离:计算用户相似度
闵可夫斯基距离可以概括曼哈顿距离与欧几里得距离。

from math import sqrt
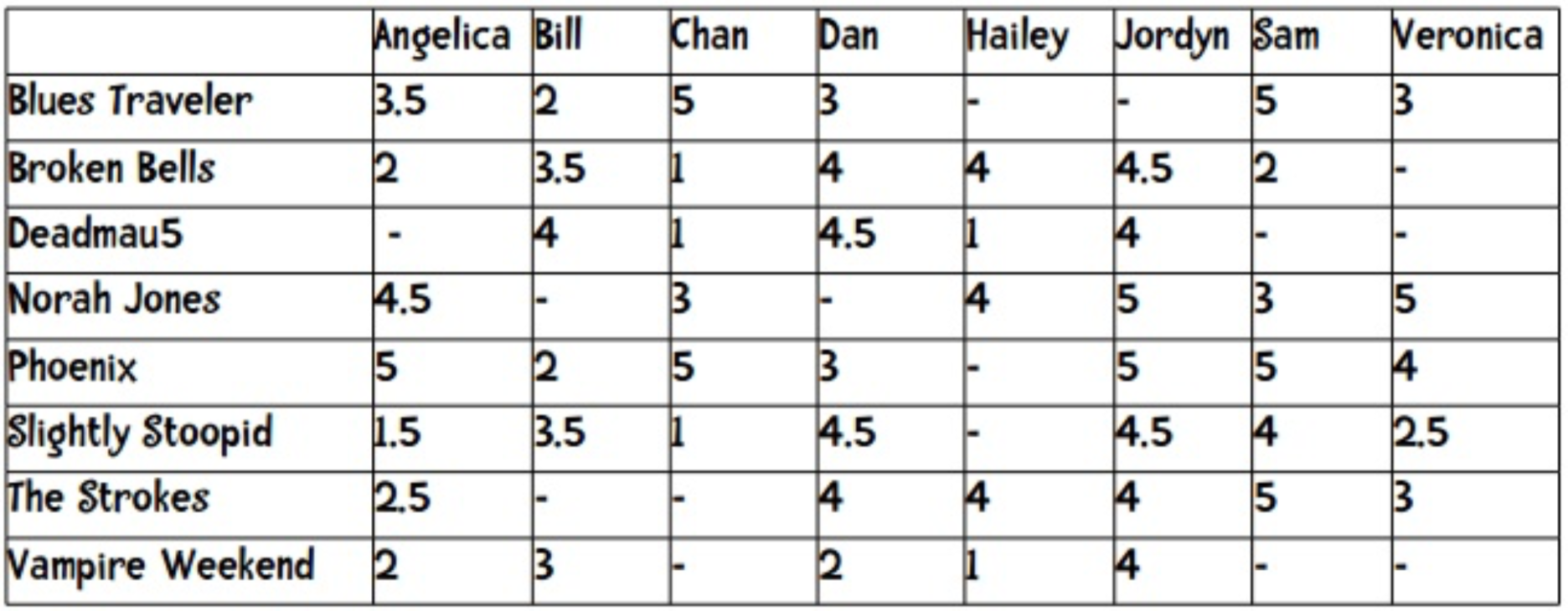
users = {"Angelica": {"Blues Traveler": 3.5, "Broken Bells": 2.0, "Norah Jones": 4.5, "Phoenix": 5.0, "Slightly Stoopid": 1.5, "The Strokes": 2.5, "Vampire Weekend": 2.0},
"Bill":{"Blues Traveler": 2.0, "Broken Bells": 3.5, "Deadmau5": 4.0, "Phoenix": 2.0, "Slightly Stoopid": 3.5, "Vampire Weekend": 3.0},
"Chan": {"Blues Traveler": 5.0, "Broken Bells": 1.0, "Deadmau5": 1.0, "Norah Jones": 3.0, "Phoenix": 5, "Slightly Stoopid": 1.0},
"Dan": {"Blues Traveler": 3.0, "Broken Bells": 4.0, "Deadmau5": 4.5, "Phoenix": 3.0, "Slightly Stoopid": 4.5, "The Strokes": 4.0, "Vampire Weekend": 2.0},
"Hailey": {"Broken Bells": 4.0, "Deadmau5": 1.0, "Norah Jones": 4.0, "The Strokes": 4.0, "Vampire Weekend": 1.0},
"Jordyn": {"Broken Bells": 4.5, "Deadmau5": 4.0, "Norah Jones": 5.0, "Phoenix": 5.0, "Slightly Stoopid": 4.5, "The Strokes": 4.0, "Vampire Weekend": 4.0},
"Sam": {"Blues Traveler": 5.0, "Broken Bells": 2.0, "Norah Jones": 3.0, "Phoenix": 5.0, "Slightly Stoopid": 4.0, "The Strokes": 5.0},
"Veronica": {"Blues Traveler": 3.0, "Norah Jones": 5.0, "Phoenix": 4.0, "Slightly Stoopid": 2.5, "The Strokes": 3.0}
}
def minkefu(rating1, rating2, n):
"""Computes the Manhattan distance. Both rating1 and rating2 are dictionaries
of the form {'The Strokes': 3.0, 'Slightly Stoopid': 2.5}"""
distance = 0
commonRatings = False
for key in rating1:
if key in rating2:
distance += abs((rating1[key] - rating2[key])**n)
commonRatings = True
if commonRatings:
return distance**1/n
else:
return -1 #Indicates no ratings in common
def computeNearestNeighbor(username, users):
"""creates a sorted list of users based on their distance to username"""
distances = []
for user in users:
if user != username:
distance = minkefu(users[user], users[username], 2)
distances.append((distance, user))
# sort based on distance -- closest first
distances.sort()
return distances
def recommend(username, users):
"""Give list of recommendations"""
# first find nearest neighbor
nearest = computeNearestNeighbor(username, users)[0][1]
recommendations = []
# now find bands neighbor rated that user didn't
neighborRatings = users[nearest]
userRatings = users[username]
for artist in neighborRatings:
if not artist in userRatings:
recommendations.append((artist, neighborRatings[artist]))
# using the fn sorted for variety - sort is more efficient
return sorted(recommendations, key=lambda artistTuple: artistTuple[1], reverse = True)
# examples - uncomment to run
print( recommend('Hailey', users))
2.皮尔逊相关系数:如何解决主观评价差异带来的推荐误差
在第一部分提到r越大,单个维度差值大小会对整体产生更大的影响。因此,我们需要有一个解决方案来应对个体的主观评价差异。这个东西就是皮尔逊相关系数。
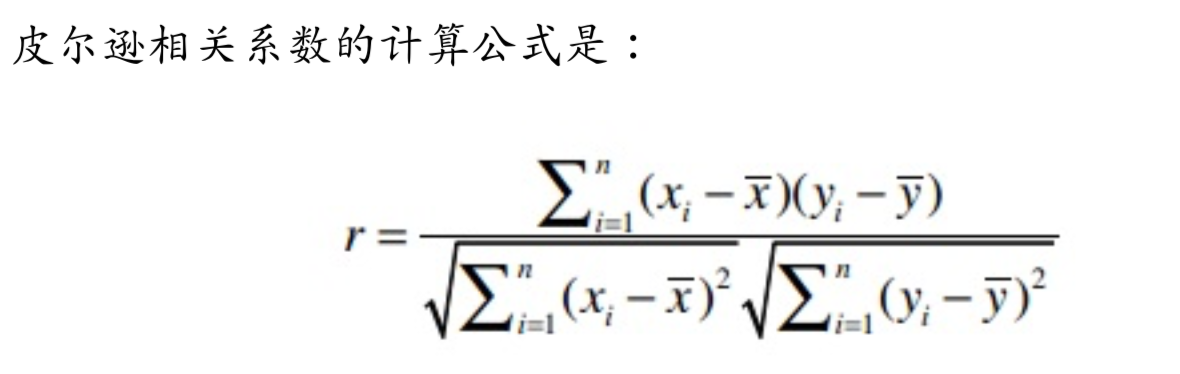
上述公式计算复杂度很大,需要进行n!*m!次遍历,后续有一个近似计算公式可以大大降低算法复杂度。
皮尔逊相关系数(-1,1)用于衡量两个向量(用户)的相关性,如两个用户意见基本一致,那皮尔逊相关系数靠近1,如果两个用户意见基本相反,那皮尔逊相关系数结果靠近-1。在这里,我们需要弄明白两个问题:
(1)怎么确定多维向量之间的皮尔逊相关系数
(2)怎么利用闵可夫斯基距离结合起来,优化我们的推荐模型
对第(1)问题,在这里有一个近似计算公式
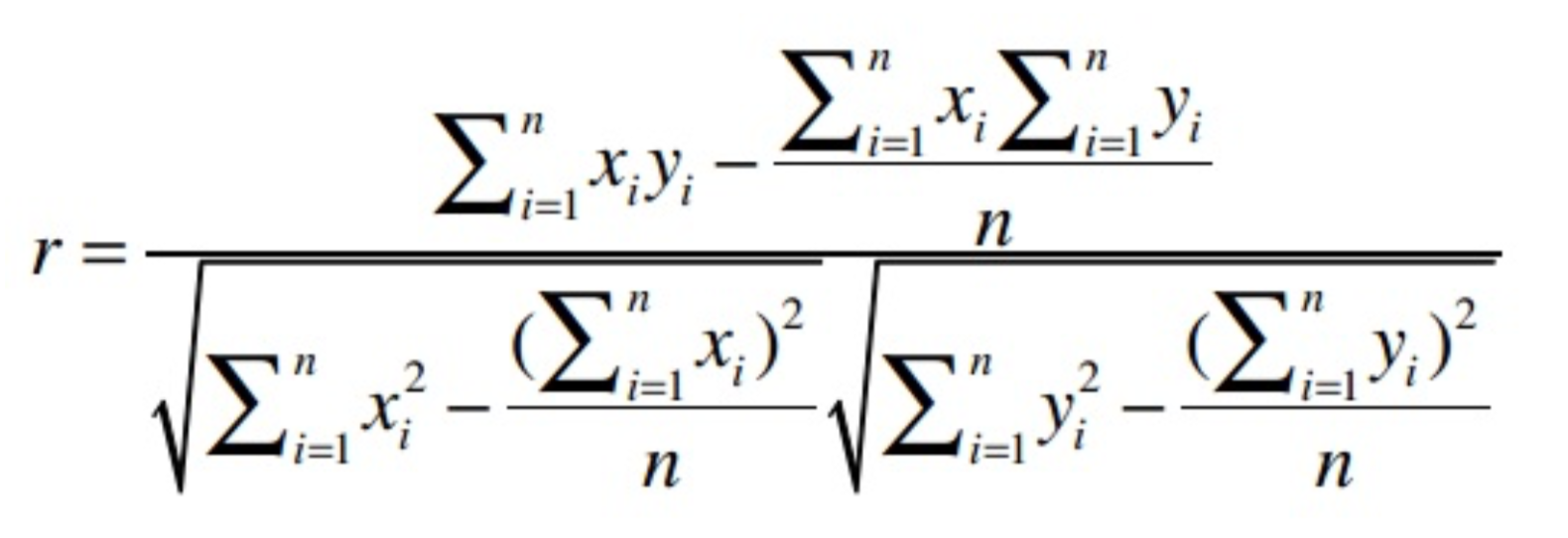
用代码来表示则为
def pearson(rating1, rating2):
sum_xy = 0
sum_x = 0
sum_y = 0
sum_x2 = 0
sum_y2 = 0
n = 0
for key in rating1:
if key in rating2:
n += 1
x = rating1[key]
y = rating2[key]
sum_xy += x * y
sum_x += x
sum_y += y
sum_x2 += pow(x, 2)
sum_y2 += pow(y, 2)
# now compute denominator
denominator = sqrt(sum_x2 - pow(sum_x, 2) / n) * sqrt(sum_y2 - pow(sum_y, 2) / n)
if denominator == 0:
return 0
else:
return (sum_xy - (sum_x * sum_y) / n) / denominator
(2)对于问题2,假设一个场景:
现在Anne需要听一首歌,从相似的三个相似用户中可以看出他们的皮尔逊系数为:

三个人对这首歌的推荐均有贡献,那我们怎么确认比重呢?由于0.8+0.7+0.5=2,因此可以按1的百分比取,则
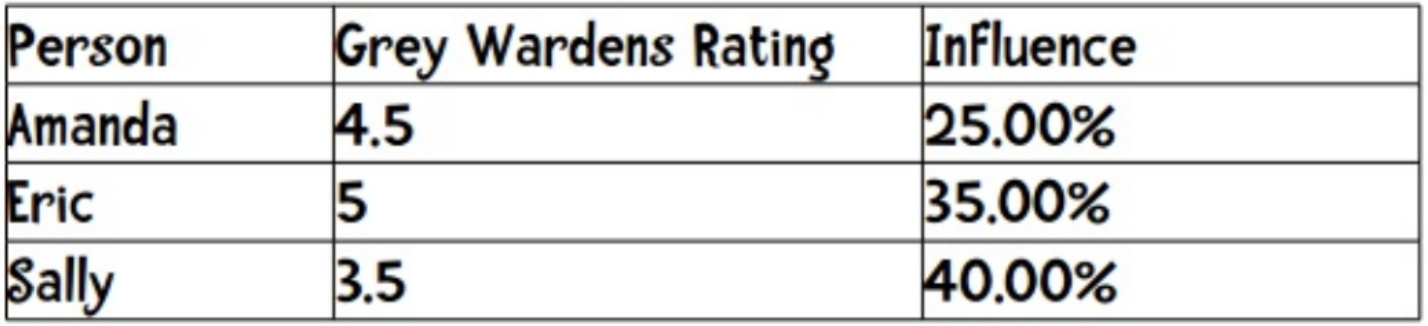
因此,这首歌的最后得分是4.5*0.25+5*0.35+3.5*0.4=4.275
这样计算的好处是将多个用户推荐权重整合起来,这样不会因为单一用户的个人喜好或者经历导致推荐失误。这也是接下来要说的K临近算法。
3.稀疏矩阵的处理办法:余弦相似度
如果数据是密集的,则用闵可夫斯基距离来计算距离;
如果数据是稀疏的,则使用余弦相似度来计算相似度(-1,1)

4.避免个人因素而生成的错误推荐:K临近算法
见2中的例子(2)
python已有现成的KNN算法库,本质是找到跟目标最近距离的几个点,详情可以参考:http://python.jobbole.com/83794/
Python推荐算法学习1的更多相关文章
- python 推荐算法
每个人都会有这样的经历:当你在电商网站购物时,你会看到天猫给你弹出的“和你买了同样物品的人还买了XXX”的信息:当你在SNS社交网站闲逛时,也会看到弹出的“你可能认识XXX“的信息:你在微博添加关注人 ...
- 微博推荐算法学习(Weibo Recommend Algolrithm)
原文:http://hijiangtao.github.io/2014/10/06/WeiboRecommendAlgorithm/ 基础及关联算法 作用:为微博推荐挖掘必要的基础资源.解决推荐时的通 ...
- python常用算法学习(4)——数据结构
数据结构简介 1,数据结构 数据结构是指相互之间存在着一种或多种关系的数据元素的集合和该集合中数据元素之间的关系组成.简单来说,数据结构就是设计数据以何种方式组织并存贮在计算机中.比如:列表,集合与字 ...
- Python—kmeans算法学习笔记
一. 什么是聚类 聚类简单的说就是要把一个文档集合根据文档的相似性把文档分成若干类,但是究竟分成多少类,这个要取决于文档集合里文档自身的性质.下面这个图就是一个简单的例子,我们可以把不同的文档聚合 ...
- python 常用算法学习(1)
算法就是为了解决某一个问题而采取的具体有效的操作步骤 算法的复杂度,表示代码的运行效率,用一个大写的O加括号来表示,比如O(1),O(n) 认为算法的复杂度是渐进的,即对于一个大小为n的输入,如果他的 ...
- python常用算法学习(3)
1,什么是算法的时间和空间复杂度 算法(Algorithm)是指用来操作数据,解决程序问题的一组方法,对于同一个问题,使用不同的算法,也许最终得到的结果是一样的,但是在过程中消耗的资源和时间却会有很大 ...
- R语言实现关联规则与推荐算法(学习笔记)
R语言实现关联规则 笔者前言:以前在网上遇到很多很好的关联规则的案例,最近看到一个更好的,于是便学习一下,写个学习笔记. 1 1 0 0 2 1 1 0 0 3 1 1 0 1 4 0 0 0 0 5 ...
- python 常用算法学习(2)
一,算法定义 算法(Algorithm)是指解题方案的准确而完整的描述,是一系列解决问题的清晰指令,算法代表着用系统的方法描述解决问题的策略机制.也就是说,能够对一定规范的输入,在有限时间内获得所要求 ...
- python数据结构算法学习自修第一天【数据结构与算法引入】
1.算法引入: #!/usr/bin/env python #! _*_ coding:UTF-8 _*_ from Queue import Queue import time que = Queu ...
随机推荐
- 使用elk转存储日志
ELK指的是由Elastic公司提供的三个开源组件Elasticsearch.Logstash和Kibana. Logstash:开源的服务器端数据处理管道,能够同时 从多个来源采集数据.转换数据,然 ...
- 51 Nod 1027 大数乘法【Java大数乱搞】
1027 大数乘法 基准时间限制:1 秒 空间限制:131072 KB 分值: 0 难度:基础题 给出2个大整数A,B,计算A*B的结果. Input 第1行:大数A 第2行:大数B (A,B的长度 ...
- Gym 100952C&&2015 HIAST Collegiate Programming Contest C. Palindrome Again !!【字符串,模拟】
C. Palindrome Again !! time limit per test:1 second memory limit per test:64 megabytes input:standar ...
- HDU6166-Senior Pan-Dijkstra迪杰斯特拉算法(添加超源点,超汇点)+二进制划分集合-2017多校Team09
学长好久之前讲的,本来好久好久之前就要写题解的,一直都没写,懒死_(:з」∠)_ Senior Pan Time Limit: 12000/6000 MS (Java/Others) Memor ...
- UVa 725 简单枚举+整数转换为字符串
Division Write a program that finds and displays all pairs of 5-digit numbers that between them use ...
- oracle修改表列名和列类型
--修改列名alter table 表名 rename column 旧列名 to 新列名;--修改列类型alter table 表名 modify (列名varchar(255));
- vuethink 在本地没问题,在服务器报错 , php5.6与php5.5之间的大坑
将环境换为php5.6即可
- 如何把域名解析到网站空间IP上?
建立网站首要就是要有一个域名和网站空间,怎么把这两者联系在一起呢?这就要通过域名解析,把域名指向空间的IP,让我们能够通过域名访问网站空间.通过域名解析把我们容易记住的域名转化成IP地址,由DNS服务 ...
- url加密,一般只对参数加密
首先,很不推荐你使用get方式发送密码,最好是使用post. 原因是,你通过一个连接把用户名和密码发送到后台,即便密码不是明文,别人获取不到密码明文,但是,只要你这个连接成功登陆过,别人就可以拿这个连 ...
- DedeCMS实现自定义表单提交后发送指定QQ邮箱法
https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&tn=monline_3_dg&wd=dedecms 邮箱&oq=d ...