Linux云服务器安装Elasticsearch
安装Elasticsearch
注:本人服务器为CentOS7.3镜像
1、下载JDK
在安装JDK之前需要检查是否已存在其他版本JDK。
采用如下命令可查看当前已存在JDK版本:
java -version
安装新的JDK之前需卸载原有JDK,具体操作可baidu。
这里给一个链接:https://www.cnblogs.com/xinjie10001/p/6287124.html
注:由于我的服务器是pure 镜像,所以不存在JDK,因此没有卸载JDK这一步操作。
JDK下载链接:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
下载之后上传到服务器某一目录,本人放置在/opt目录。
使用tar命令进行解压:
tar zxf jdk-8u161-linux-x64.tar.gz
接下来配置JAVA环境变量,先使用如下命令打开环境变量配置文件:
vim /etc/profile
在打开后的profile中,输入字符i对文档进行编辑,在文件末尾插入如下内容:
export JAVA_HOME=/opt/jdk1.8.0_161
export JAVA_BIN=/opt/jdk1.8.0_161/bin
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOME JAVA_BIN PATH CLASSPATH
插入完成后按ESC键再输入:wq或:x保存文件并退出。
注:/opt/jdk1.8.0_161为JDK解压后的文件所放置的目录
2、下载Elasticsearch
Linux系统下直接可采用如下命令进行下载:
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.2.3.tar.gz
另外,也可直接在官网下载后上传到服务器某一目录。
下载Elasticsearch后使用如下命令进行解压:
tar zxf elasticsearch-6.2.3.tar.gz
进入elasticsearch-6.2.3的bin目录,使用如下命令执行脚本elasticsearch:
./elasticsearch
3、内存不足问题
按上述操作此时会出现如下问题:

此时应该是表示内存不足
解决方法:
进入elasticsearch-6.2.3的config目录,使用如下命令进入jvm.options配置文件:
vim ./jvm.options
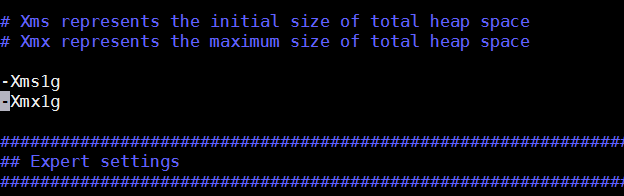
将文件中下图所示的-Xms1g和-Xmx1g改为-Xms200m和-Xmx200m
4、root用户不能执行elasticsearch脚本问题
此时返回bin目录重新运行脚本elasticsearch会出现如下问题:
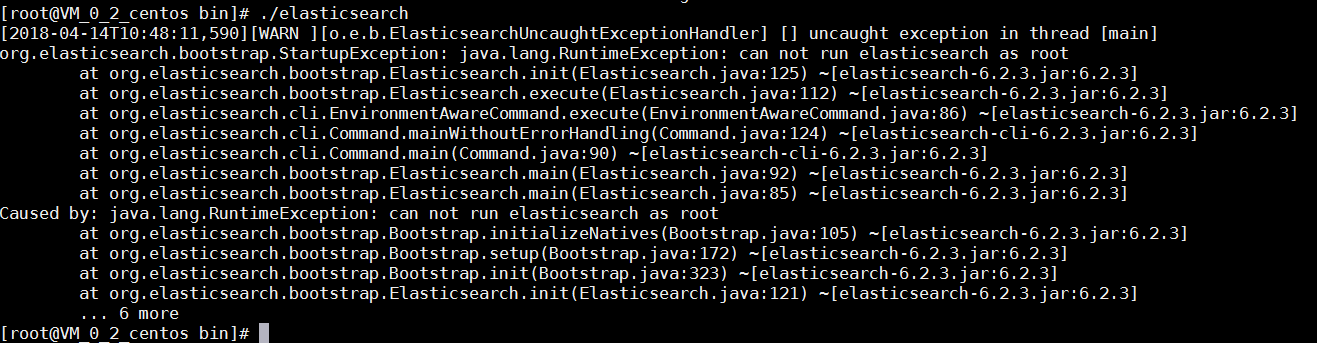
该问题表示不能使用root用户运行该脚本,为此我们可以为elasticsearch新建一个用户ES。
具体操作见下图:

使用如下命令为该用户获取访问/opt目录的权限:
chown ES /opt -R
切换到用户ES,执行bin目录下的elasticsearch脚本,具体操作见下图:
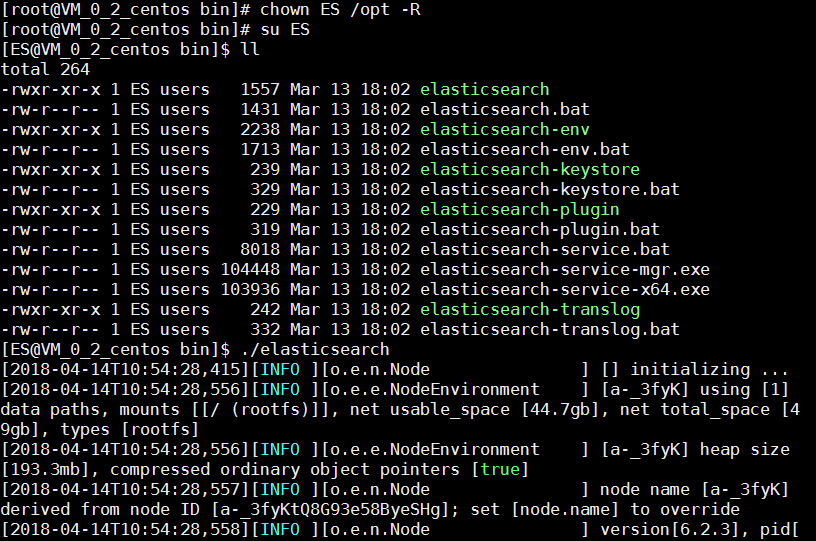
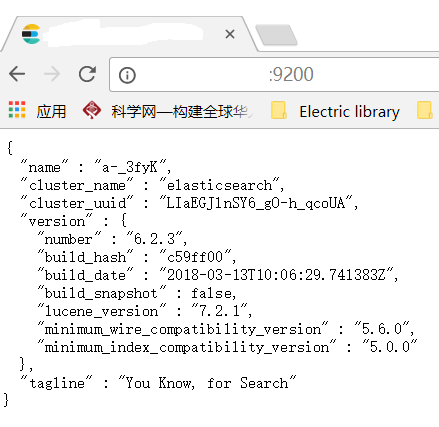
这说明elasticsearch启动成功,但不要激动得太早,我们需要通过9200端口访问elasticsearch服务,具体操作见下图:
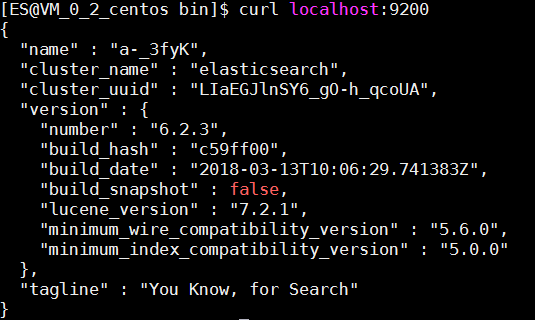
如果出现上图所示的JSON信息,说明Elasticsearch启动成功。
5、外网访问云服务器的Elasticsearch
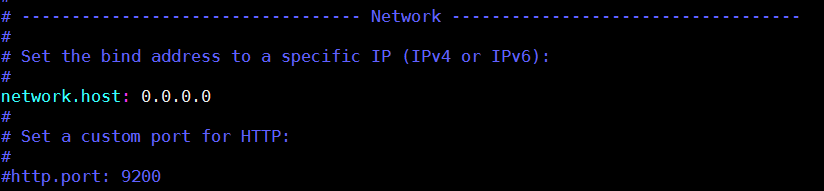
进入config目录将elasticsearch.yml配置文件中的network.host修改为0.0.0.0并去掉其前面的#号,命令为:
vim ./elasticsearch.yml
具体修改操作如下图所示:
返回bin目录重新运行elasticsearch脚本,此时会出现如下问题:

针对问题1:

解决方法:
使用如下命令打开/etc/security/limits.conf:
vim /etc/security/limits.conf
在该配置文件中添加如下内容:
* soft nproc 4096
* hard nproc 4096
具体见下图:
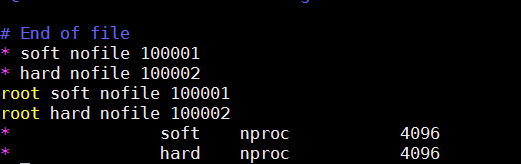
注:这里文件的打开需要切换到root用户,因为ES用户不能改变该配置文件。
针对问题2:

解决方法:
使用如下命令打开/etc/sysctl.conf:
vim /etc/sysctl.conf
增加配置vm.max_map_count=262144
具体见下图:

执行命令sysctl -p生效。
重新启动服务器,再运行elasticsearch脚本,此时便没有错误了。
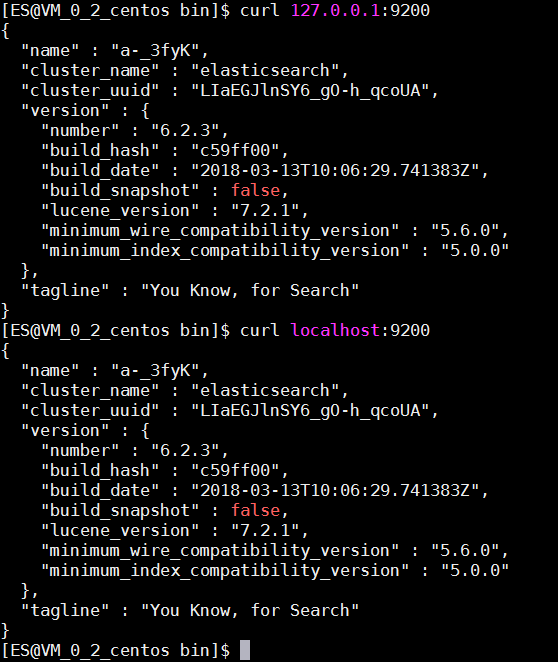
本地访问9200端口:
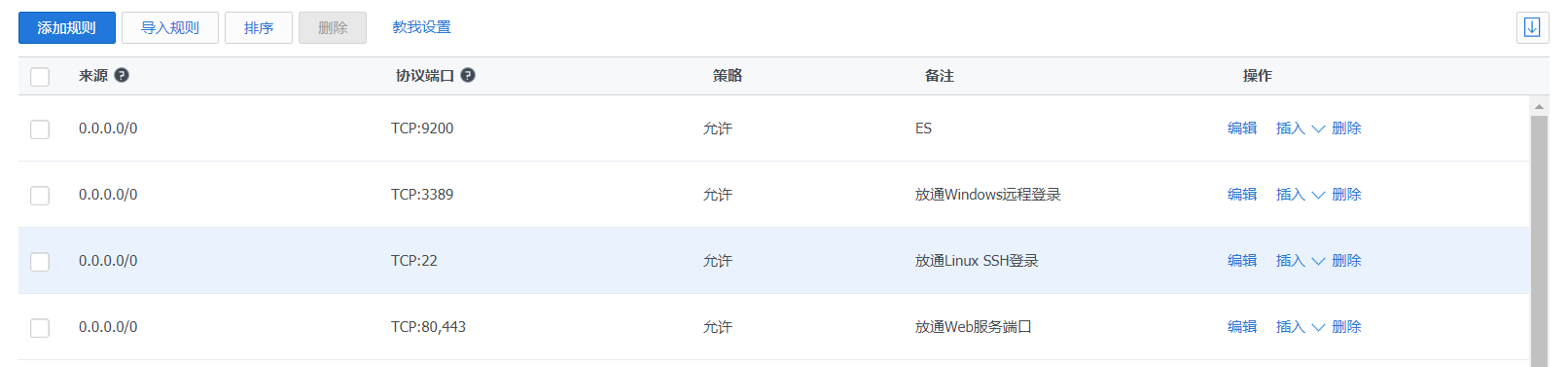
在云服务器安全组打开9200端口:
外网浏览器访问服务器9200端口:
此外,还可能遇到问题3:
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
解决方法:
使用如下命令打开/etc/security/limits.conf:
vim /etc/security/limits.conf
在该配置文件中添加如下内容:
* soft nofile 65536
* hard nofile 65536
后台运行Elasticsearch命令:
./elasticsearch -d
Reference
[1]. https://www.jianshu.com/p/658961f707d8
[2]. http://kael-aiur.com/elk/ES配置给外部机器通过ip访问.html
[3]. https://www.cnblogs.com/zhi-leaf/p/8484337.html
[4]. https://blog.csdn.net/u010781176/article/details/79489151
Linux云服务器安装Elasticsearch的更多相关文章
- Linux云服务器安装tomcat
安装tomcat需要安装JDK 1.上传 把下载好的tomcat压缩包(apache-tomcat-7.0.tar.gz)和jdk(jdk-7u76-linux-x64.tar.gz)压缩包上传到/u ...
- 阿里云服务器Linux系统安装配置ElasticSearch搜索引擎
近几篇ElasticSearch系列: 1.阿里云服务器Linux系统安装配置ElasticSearch搜索引擎 2.Linux系统中ElasticSearch搜索引擎安装配置Head插件 3.Ela ...
- Linux系统中ElasticSearch搜索引擎安装配置Head插件
近几篇ElasticSearch系列: 1.阿里云服务器Linux系统安装配置ElasticSearch搜索引擎 2.Linux系统中ElasticSearch搜索引擎安装配置Head插件 3.Ela ...
- 记录云服务器安装node
今天买了台云服务器,准备玩玩,对于之前没接触过Linux的我是一头雾水,登陆后进去就是一个黑黑的终端,一点也不友好,所以特地记录一下登陆以及安装node的过程 先记录一下登陆 登陆方式一: 那就是账号 ...
- 阿里云服务器安装Docker并部署nginx、jdk、redis、mysql
阿里云服务器安装Docker并部署nginx.jdk.redis.mysql 一.安装Docker 1.安装Docker的依赖库 yum install -y yum-utils device-map ...
- linux云主机怎么安装WDCP
linux云主机 教你成功安装WDCP的2个方法(第一个不成功就试第2个) 工具/原料 Xshell 云服务器 方法/步骤 1 先用Xshell连接你的服务器 2 输入一下代码 wget ...
- Linux云主机安装JDK,配置hadoop的详细方式
云主机我使用的是青云的,还有好多其他品牌,比如阿里云 unitedstack 等等. 注册完青云后,会有试用券发到账户,可以利用此券试用其服务. 1 首先创建好一个主机,按照提示选择好系统,创建好一个 ...
- 记录Linux下安装elasticSearch时遇到的一些错误
记录Linux下安装elasticSearch时遇到的一些错误 http://blog.sina.com.cn/s/blog_c90ce4e001032f7w.html (2016-11-02 22: ...
- Linux云自动化运维第三课
Linux云自动化运维第三课 一.正则表达式 1.匹配符 * ###匹配0到任意字符 ? ###匹配单个字符 [[:alpha:]] ###匹配单个字母 [[:lower:]] ###匹配单个小写字母 ...
随机推荐
- Mybatis转义字符
Mybatis的sql语句中需要用到'>'或者'<'时,不能直接使用. < < 小于号 > > 大于号 & & 和 ' ' 单引号 ...
- Tomcat优化内存以及连接数
公司的一个服务器使用Tomcat6默认配置,在后台一阵全点击服务器就报废了,查了一下就要是PERMSIZE默认值过小造成(16-64) TOMCAT_HOME/bin/catalina.sh 添加一行 ...
- java操作数据库的通用的类
package cn.dao; import java.lang.reflect.InvocationTargetException; import java.lang.reflect.Method; ...
- Dom属性方法
一.javascript的三大核心 1.ECMAScript js的语法标准 2.DOM Document object Model 文档对象模型,提供的方法可以让js操作html标签 3.BOM B ...
- 原生js封装添加class,删除class
一.添加class function addClass(ele,cName) { var arr = ele.className.split(' ').concat(cName.split(" ...
- RESTFul API设计指南及使用说明
RESTFul API设计指南及使用说明 一. 协议 API与用户的通信协议,使用HTTP协议. 二. 域名 应尽量将API部署在专用域名之下(http://api.example.com) 也可以将 ...
- python全栈学习--day11(函数高级应用)
一,函数名是什么? 函数名是函数的名字,本质:变量,特殊的变量. 函数名()执行此函数 ''' 在函数的执行(调用)时:打散. *可迭代对象(str,tuple,list,dict(key))每一个元 ...
- 初学MySQL基础知识笔记--02
查询部分 1> 查询数据中所有数据:select * from 表名 2> 查询数据中某项的数据:eg:select id,name from students; 3> 消除重复行: ...
- 第十四,十五周PTA作业
1.第十四周part1 7-3 #include<stdio.h> int main() { int n; scanf("%d",&n); int a[n]; ...
- lambda及参数绑定
一.介绍 对于STL中的算法,我们都可以传递任何类别的可调用对象.对于一个对象或一个表达式,如果可以对其使用调用运算符,则称它为可调用的.即,如果e是一个可调用的表达式,则我们可以编写代码e(ar ...