酷伯伯实时免费HTTP代理ip爬取(端口图片显示+document.write)
分析
打开页面http://www.coobobo.com/free-http-proxy/,端口数字一看就不对劲,老规律ctrl+shift+c选一下:
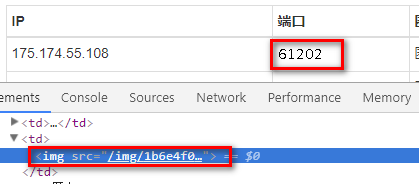
这就很悲剧了,端口数字都是用图片显示的:
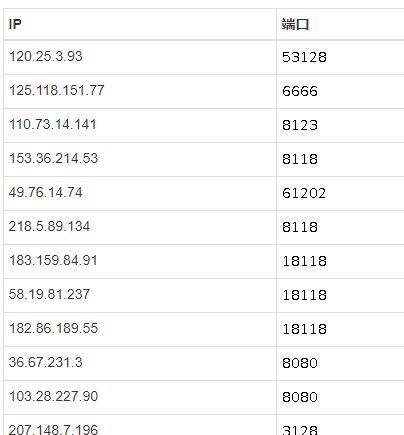
不过没关系,看这些图片长得这么清秀纯天然无杂质,识别是很容易的。
然后再来选一下ip地址:
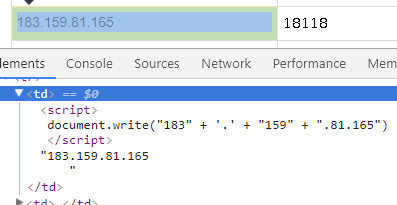
很可能ip地址是用这个js现写进来的,要确定的话还得看一眼返回的原始html,查看源码定位这一个ip:

看来只能从这段js中提取ip地址了,并不是很难,只需要把引号、加号、括号、document.write、空白符抹掉即可,一个正则表达式可以搞定。
代码实现
端口图片比较麻烦,之前写过一个类似的小工具库,对于这种简单字符的识别可以节省一些工作量,这里就使用这个工具库。
因为识别原理就是先收集一些图片标记好谁是啥字符作为依据,然后后面再来的新的都来参考这些已经标记好的,所以需要先收集一些图片来标记:
/**
* 收集需要标注的字符图片
*/
public static void grabTrainImage(String basePath) {
for (int i = 1; i <= 10; i++) {
System.out.println("page " + i);
Document document = getDocument(url + i);
Elements images = document.select("table.table-condensed tbody tr img");
images.forEach(elt -> {
String imgLink = host + elt.attr("src");
byte[] imgBytes = download(imgLink);
try {
String outputPath = basePath + System.currentTimeMillis() + ".png";
BufferedImage img = ImageIO.read(new ByteArrayInputStream(imgBytes));
ImageIO.write(img, "png", new File(outputPath));
System.out.println(imgLink);
} catch (IOException e) {
e.printStackTrace();
}
});
}
}
抓取图片到本地并生成要标注的图片:
public static void main(String[] args) throws IOException {
String rawImageSaveDir = "E:/test/proxy/kubobo/raw/";
String distinctCharSaveDir = "E:/test/proxy/kubobo/char/";
grabTrainImage(rawImageSaveDir);
ocrUtil.init(rawImageSaveDir, distinctCharSaveDir);
}
然后打开E:/test/proxy/kubobo/char/,之前下载的全部图片中用到的所有字符都被分割出来放到了这个目录下:

现在需要将文件名修改为这张图片表示的意思:

需要注意不要标记错了不然后面的就全是错的了。
然后告诉ocrUtil上面这个目录的位置让其知道去哪里加载:
ocrUtil.loadDictionaryMap("E:/test/proxy/kubobo/char/");
然后就可以使用了,只需要把图片传入给ocrUtil.ocr(BufferedImage)即返回这种图片对应的字符,完整的代码如下:
package org.cc11001100.t1; import cc11001100.ocr.OcrUtil;
import org.apache.commons.lang3.StringUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements; import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.ByteArrayInputStream;
import java.io.File;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List; import static java.util.stream.Collectors.toList; /**
* @author CC11001100
*/
public class KuboboProxyGrab { private static String host = "http://www.coobobo.com";
private static String url = "http://www.coobobo.com/free-http-proxy/"; private static OcrUtil ocrUtil; static {
ocrUtil = new OcrUtil();
ocrUtil.loadDictionaryMap("E:/test/proxy/kubobo/char/");
} /**
* 收集需要标注的字符图片
*/
public static void grabTrainImage(String basePath) {
for (int i = 1; i <= 10; i++) {
System.out.println("page " + i);
Document document = getDocument(url + i);
Elements images = document.select("table.table-condensed tbody tr img");
images.forEach(elt -> {
String imgLink = host + elt.attr("src");
byte[] imgBytes = download(imgLink);
try {
String outputPath = basePath + System.currentTimeMillis() + ".png";
BufferedImage img = ImageIO.read(new ByteArrayInputStream(imgBytes));
ImageIO.write(img, "png", new File(outputPath));
System.out.println(imgLink);
} catch (IOException e) {
e.printStackTrace();
}
});
}
} private static Document getDocument(String url) {
byte[] responseBytes = download(url);
String html = new String(responseBytes, StandardCharsets.UTF_8);
return Jsoup.parse(html);
} private static byte[] download(String url) {
for (int i = 0; i < 3; i++) {
try {
return Jsoup.connect(url).execute().bodyAsBytes();
} catch (IOException e) {
e.printStackTrace();
}
}
return new byte[0];
} public static List<String> grabProxyIpList() {
List<String> resultList = new ArrayList<>();
for (int i = 1; i <= 10; i++) {
System.out.println("page " + i);
Document document = getDocument(url + i);
Elements ipElts = document.select("table.table-condensed tbody tr");
List<String> pageIpList = ipElts.stream().map(elt -> {
String rawText = elt.select("td:eq(0) script").first().data();
String ip = rawText.replaceAll("document.write|[\'\"()+]|\\s+", "").trim(); String imgLink = host + elt.select("td:eq(1) img").attr("src");
byte[] imgBytes = download(imgLink);
try {
BufferedImage img = ImageIO.read(new ByteArrayInputStream(imgBytes));
String port = ocrUtil.ocr(img);
return ip + ":" + port;
} catch (IOException e) {
e.printStackTrace();
}
return "";
}).filter(StringUtils::isNotEmpty).collect(toList());
resultList.addAll(pageIpList);
}
return resultList;
} public static void main(String[] args) throws IOException { // String rawImageSaveDir = "E:/test/proxy/kubobo/raw/";
// String distinctCharSaveDir = "E:/test/proxy/kubobo/char/";
// grabTrainImage(rawImageSaveDir);
// ocrUtil.init(rawImageSaveDir, distinctCharSaveDir); grabProxyIpList().forEach(System.out::println); } }
酷伯伯实时免费HTTP代理ip爬取(端口图片显示+document.write)的更多相关文章
- requests 使用免费的代理ip爬取网站
import requests import queue import threading from lxml import etree #要爬取的URL url = "http://xxx ...
- 蚂蚁代理免费代理ip爬取(端口图片显示+token检查)
分析 蚂蚁代理的列表页大致是这样的: 端口字段使用了图片显示,并且在图片上还有各种干扰线,保存一个图片到本地用画图打开观察一下: 仔细观察蓝色的线其实是在黑色的数字下面的,其它的干扰线也是,所以这幅图 ...
- 代理IP爬取和验证(快代理&西刺代理)
前言 仅仅伪装网页agent是不够的,你还需要一点新东西 今天主要讲解两个比较知名的国内免费IP代理网站:西刺代理&快代理,我们主要的目标是爬取其免费的高匿代理,这些IP有两大特点:免费,不稳 ...
- 代理IP爬取,计算,发放自动化系统
IoC Python端 MySQL端 PHP端 怎么使用 这学期有一门课叫<物联网与云计算>,于是我就做了一个大作业,实现的是对代理IP的爬取,计算推荐,发放给用户等任务的的自动化系统.由 ...
- Scrapy爬取美女图片第三集 代理ip(上) (原创)
首先说一声,让大家久等了.本来打算那天进行更新的,可是一细想,也只有我这样的单身狗还在做科研,大家可能没心思看更新的文章,所以就拖到了今天.不过忙了521,522这一天半,我把数据库也添加进来了,修复 ...
- Scrapy爬取美女图片第四集 突破反爬虫(上)
本周又和大家见面了,首先说一下我最近正在做和将要做的一些事情.(我的新书<Python爬虫开发与项目实战>出版了,大家可以看一下样章) 技术方面的事情:本次端午假期没有休息,正在使用fl ...
- 百度图片爬虫-python版-如何爬取百度图片?
上一篇我写了如何爬取百度网盘的爬虫,在这里还是重温一下,把链接附上: http://www.cnblogs.com/huangxie/p/5473273.html 这一篇我想写写如何爬取百度图片的爬虫 ...
- Python爬取谷歌街景图片
最近有个需求是要爬取街景图片,国内厂商百度高德和腾讯地图都没有开放接口,查询资料得知谷歌地图开放街景api 谷歌捷径申请key地址:https://developers.google.com/maps ...
- Python爬虫学习(6): 爬取MM图片
为了有趣我们今天就主要去爬取以下MM的图片,并将其按名保存在本地.要爬取的网站为: 大秀台模特网 1. 分析网站 进入官网后我们发现有很多分类: 而我们要爬取的模特中的女模内容,点进入之后其网址为:h ...
随机推荐
- Java8新特性第3章(Stream API)
Stream作为Java8的新特性之一,他与Java IO包中的InputStream和OutputStream完全不是一个概念.Java8中的Stream是对集合功能的一种增强,主要用于对集合对象进 ...
- Linux命令-权限
Linux命令权限 1.新建用户natasha,uid为1000, gid为555, 备注信息为"master" 2.修改natasha用户的家目录为/Natasha 3.查看 ...
- Flume报 Space for commit to queue couldn't be acquired. Sinks are likely not keeping up with sources, or the buffer size is too tight
报这个错误 需要一个是flume堆内存不够.还有一个就是把channel的容器调大 在channel加配置 type - 组件类型名称必须是memory capacity 100 存储在 Channe ...
- bcrypt对密码加密的一些认识(学习笔记)
学习nodejs和mongoDB的时候,接触了用户注册和登录的一些知识. 1.关于增强用户密码的安全性 用户的密码肯定不能保存为明文,避免撞库攻击. 撞库攻击:撞库是一种针对数据库的攻击方式,方法是通 ...
- SQL外连接
1.左外连接 取出左侧关系中所有与右侧关系中任一元组都不匹配的元组,用空值null充填所有来自右侧关系的属性,构成新的元组,将其加入自然连接的结果中 2.右外连接 取出右侧关系中所有与左侧关系中任一元 ...
- Python中的上下文管理器和with语句
Python2.5之后引入了上下文管理器(context manager),算是Python的黑魔法之一,它用于规定某个对象的使用范围.本文是针对于该功能的思考总结. 为什么需要上下文管理器? 首先, ...
- C#之冒泡排序
以前在学校的时候看过冒泡排序,看的时候挺明白的,但是自己写的时候就写不出来,在网上搜索了一下,发现网上的冒泡排序算法几乎都不符合冒泡排序的原理,虽然也能实现,但是不正宗. 冒泡排序从字面意思理解:应该 ...
- php一句话反弹bash shell
来源:https://www.leavesongs.com/PHP/backshell-via-php.html 用到了,记录一下 $sock = fsockopen($ip, $port); $de ...
- [AHOI 2016初中组]自行车比赛
Description 小雪非常关注自行车比赛,尤其是环滨湖自行车赛.一年一度的环滨湖自行车赛,需要选手们连续比赛数日,最终按照累计得分决出冠军.今年一共有 N 位参赛选手.每一天的比赛总会决出当日的 ...
- [NOI 2010]航空管制
Description 世博期间,上海的航空客运量大大超过了平时,随之而来的航空管制也频频发生.最近,小X就因为航空管制,连续两次在机场被延误超过了两小时.对此,小X表示很不满意. 在这次来烟台的路上 ...