MobileNet_v2
研究动机: 神经网络彻底改变了机器智能的许多领域,实现了超人的准确性。然而,提高准确性的驱动力往往需要付出代价:现代先进网络需要高度计算资源,超出许多移动和嵌入式应用的能力。
主要贡献: 发明了一个新的层模块, 具有线性瓶颈的倒置残差(inverted residual)。
相关工作: 里面介绍了近来整个领域的发展概况, 看论文就看介绍的吧.
基本概念
深度可分离卷积
Depthwise Separable Convolutions = depthwise + pointwise
如果卷积核大小为 3x3, 深度可分离卷积的计算量为常规卷积的 (1/9, 1/8)
流形(manifold)
花书 <<深度学习>> 介绍:
\(\color{red}{流形(manifold)}\) 指连接在一起的区域。数学上,它是指一组点,且每个点都 有其邻域。给定一个任意的点,其流形局部看起来像是欧几里得空间。日常生活中, 我们将地球视为二维平面,但实际上它是三维空间中的球状流形。
每个点周围邻域的定义暗示着存在变换能够从一个位置移动到其邻域位置。例 如在地球表面这个流形中,我们可以朝东南西北走。
尽管术语 “流形’’ 有正式的数学定义, 但是机器学习倾向于更松散地定义一组 点,只需要考虑少数嵌入在高维空间中的自由度或维数就能很好地近似。每一维都对应着局部的变化方向。如图 5.11 所示, 训练数据位于二维空间中的一维流形中。 在机器学习中,我们允许流形的维数从一个点到另一个点有所变化。这经常发生于流形和自身相交的情况中。例如,数字 "8" 形状的流形在大多数位置只有一维,但 在中心的相交处有两维。
\(\color{red}{流形学习(manifold\space learning)}\) 算法假设: 该假设认为 \(R^n\) 中大部分区域都是无效的输入,有意义的输入只分布在包 含少量数据点的子集构成的一组流形中,而学习函数的输出中,有意义的变化都沿着流形的方向或仅发生在我们切换到另一流形时。
数据位于低维流形的假设并不总是对的或者有用的。我们认为在人工智能的一 些场景中,如涉及到处理图像、声音或者文本时,流形假设至少是近似对的。
Linear Bottlenecks
Linear Bottlenecks 理论支持:
考虑由 n 层 \(L_i\) 组成的深层神经网络,其中每一层都具有尺寸为 \(h_i×w_i×d_i\)的激活张量。在本节中,我们将讨论这些激活张量的基本属性,我们将其视为具有 \(d_i\) 维度的 \(h_i×w_i\)“像素”的容器。非正式地说,对于输入的一组真实图像,我们说层激活(对于任何层 \(L_i\))形成一个“流形”。由于这种流形通常不能用分析方法描述,因此我们将凭经验研究它们的性质。例如,长期以来一直认为神经网络中感兴趣的流形可以嵌入到低维子空间中。换句话说,当我们查看深卷积层的所有单个通道像素时,这些值中编码的信息实际上位于某个流形中,而这又可嵌入到低维子空间中。
乍一看,这样的事实可以通过简单地减少层的维度来捕获和利用,从而降低操作空间的维度。这已经被 MobileNetV1 成功利用,通过宽度乘法器参数在计算和精度之间进行有效的折中. 遵循这种直觉,宽度乘法器方法允许减小激活空间的维度,直到感兴趣的流形横跨整个空间为止。然而,当我们回想到深度卷积神经网络实际上具有非线性的坐标变换(例如ReLU)时,这种直觉就会崩溃。例如,ReLU应用于1D空间中的线会产生'射线',在 \(R^n\) 空间中,其通常导致具有 n 截的分段线性曲线。
insight:
- 如果流形在ReLU变换后保持非零卷 (no-zero volume),则它对应于线性变换.
- ReLU能够保留关于输入流形的完整信息,但只有当输入流形位于输入空间的低维子空间时。
这两个见解为我们提供了一个优化现有神经架构的经验提示:假设感兴趣的流形是低维的,我们可以通过将线性瓶颈层插入卷积模块来捕获这一点。 实验证据表明,使用线性层非常重要,因为它可以防止非线性破坏太多的信息。
Inverted residuals
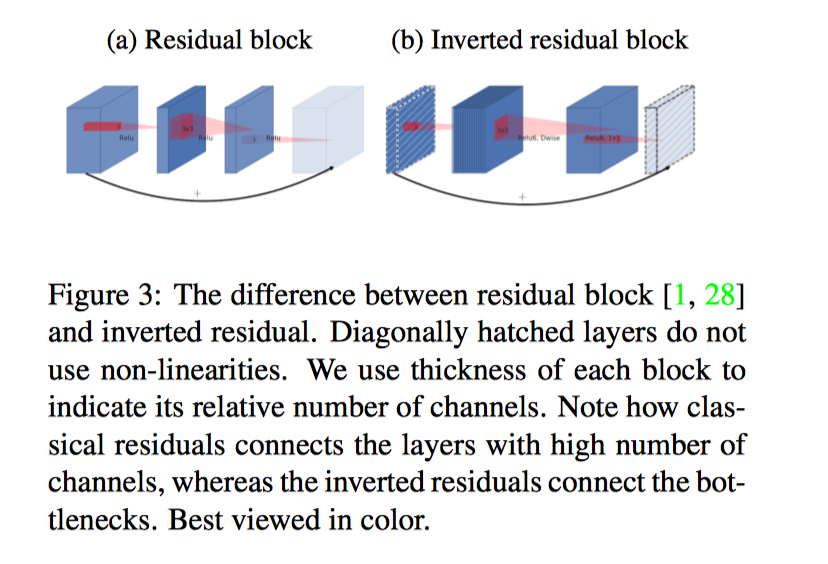 

We will refer to the ratio between the size of the input bottleneck and the inner size as the expansion ratio.
\(\color{red}{由于 Inverted \space residuals 两边 thin, 所以该设计想比较传统残差设计更加节省内存}\)
论文观点
架构的一个有趣特性是它在构建块(瓶颈层)的输入/输出域与层转换(这是一种将输入转换为输出的非线性函数)之间提供了自然分离. 前者(层输入/输出)可以看作是网络在每一层的容量,而后者(层转换)则是表达力。这与常规和可分离的传统卷积块相反,其中表现力和容量都缠结在一起,并且是输出层深度的函数。
\(\color{red}{在论文的最后提出}\):
On the theoretical side: the proposed convolutional block has a unique property that allows to separate the network expressivity (encoded by expansion layers) from its capacity (encoded by bottleneck inputs). Exploring this is an important direction for future research.
这种解释使我们能够独立于其容量研究网络的表现力,并且我们认为需要进一步探索这种分离,以便更好地理解网络性质.
我的理解:
- 由于文中在前面提到, 当流型存在于高维输入空间的低纬空间时, 通过 Relu 几乎可以保留全部信息
- 在 bottleneck inputs 之后的 expansion layers 会有 1x1 卷积升维操作, 所以认为经过 Relu 没有损失信息, 即模型的容量不变, expansion layers的操作可以看做是层的表达力, 然后通过 Linear Bottlenecks, 也没有损失信息, 故全程保持模型的容量不变, 可以通过调节 expansion ratio, t 来调节模型的表达力
网络结构
实现细节:
base learning rate = 0.045
weight decay = 0.00004
t = 5 - 10
dropout + bn + relu6
RMSPropOptimizer momentum = 0.9 decay = 0.9
网络结构
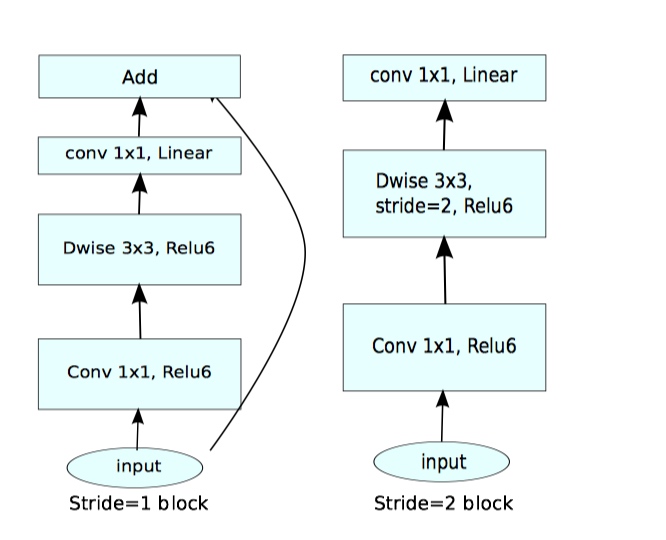 

 

表中错误已修正
内存节约型 inference
计算图 G, 在推导时(inference ), 内存总量和边界如下:
M(G) &= \max_{op \in G}\left[\sum_{A\in op_{input}}A + \sum_{B\in op_{output}}B + |op| \right] \\
\end{align*}
\]
内存占用量是所有操作对应输入和输出张量的总大小与操作本身所占内存之和决定。 如果我们将瓶颈残差块视为单一操作(并将内部卷积视为一次性张量[即用完就丟]),则总内存量将由瓶颈张量的大小决定,而不是瓶颈内部张量的大小决定
MobileNet_v2的更多相关文章
- 实践案例丨基于ModelArts AI市场算法MobileNet_v2实现花卉分类
概述 MobileNetsV2是基于一个流线型的架构,它使用深度可分离的卷积来构建轻量级的深层神经网,此模型基于 MobileNetV2: Inverted Residuals and Linear ...
- MobileNet系列之MobileNet_v2
MobileNet系列之MobileNet_v1 Inception系列之Inception_v1 Inception系列之Batch Normalization Inception系列之Ince ...
- 『高性能模型』轻量级网络MobileNet_v2
论文地址:MobileNetV2: Inverted Residuals and Linear Bottlenecks 前文链接:『高性能模型』深度可分离卷积和MobileNet_v1 一.Mobil ...
- TensorFlow从1到2(九)迁移学习
迁移学习基本概念 迁移学习是这两年比较火的一个话题,主要原因是在当前的机器学习中,样本数据的获取是成本最高的一块.而迁移学习可以有效的把原有的学习经验(对于模型就是模型本身及其训练好的权重值)带入到新 ...
- TensorFlow从1到2(五)图片内容识别和自然语言语义识别
Keras内置的预定义模型 上一节我们讲过了完整的保存模型及其训练完成的参数. Keras中使用这种方式,预置了多个著名的成熟神经网络模型.当然,这实际是Keras的功劳,并不适合算在TensorFl ...
- tensorflow用pretrained-model做retrain
最近工作里需要用到tensorflow的pretrained-model去做retrain. 记录一下. 为什么可以用pretrained-model去做retrain 这个就要引出CNN的本质了.C ...
- MACE(3)-----工程化
作者:十岁的小男孩 QQ:929994365 能下者,上. 前言 本文是MACE的第三步即MACE环境编译出来的库在Android工程中的使用.在第一篇博文中通过mace官方提供的安卓工程进行调试,本 ...
- MACE(2)-----模型编译
作者:十岁的小男孩 QQ:929994365 无用 本文仅用于学习研究,非商业用途,欢迎大家指出错误一起学习,文章内容翻译自 MACE 官方手册,记录本人阅读与开发过程,力求不失原意,但推荐阅读原文. ...
- MACE(1)-----环境搭建
作者:十岁的小男孩 QQ:929994365 无为 本文仅用于学习研究,非商业用途,欢迎大家指出错误一起学习,文章内容翻译自 MACE 官方手册,记录本人阅读与开发过程,力求不失原意,但推荐阅读原文. ...
随机推荐
- 【BZOJ4195】【NOI2015】程序自动分析(并查集)
[BZOJ4195][NOI2015]程序自动分析(并查集) 题面 Description 在实现程序自动分析的过程中,常常需要判定一些约束条件是否能被同时满足. 考虑一个约束满足问题的简化版本:假设 ...
- [BZOJ2002] [Hnoi2010] Bounce 弹飞绵羊 (LCT)
Description 某天,Lostmonkey发明了一种超级弹力装置,为了在他的绵羊朋友面前显摆,他邀请小绵羊一起玩个游戏.游戏一开始,Lostmonkey在地上沿着一条直线摆上n个装置,每个装置 ...
- Java学习第一周
第一周学习了JDK的安装和环境的配置,初步了解了Java与C的不同之处,学习了Java的变量.基本数据类型.以及面向对象的基础.并且自行完成了一些简单Java程序的编写. (1)学习了为什么使用抽象类 ...
- 大三小学期 Android开发的一些经验
1.同一个TextView几种颜色的设置: build=(TextView)findViewById(R.id.building); SpannableStringBuilder style = ne ...
- 在Debian系列Linux系统Ubuntu上安装配置yum的试验
用习惯了Red Hat系统的都知道我们习惯于三种安装方式:一种是rpm包的方式安装,一种就是tar包的方式来安装,还有一种方式就是yum源的安装. 首先rpm包的用法,我们一般是在Red Hat光驱里 ...
- 【解高次同余方程】51nod1038 X^A Mod P
1038 X^A Mod P 基准时间限制:1 秒 空间限制:131072 KB 分值: 320 X^A mod P = B,其中P为质数.给出P和A B,求< P的所有X. 例如:P = 11 ...
- 基于python创建一个简单的HTTP-WEB服务器
背景 大多数情况下主机资源只有开发和测试相关人员可以登录直接操作,且有些特定情况"答辩.演示.远程"等这些场景下是无法直接登录主机的.web是所有终端用户都可以访问了,解决了人员权 ...
- 解决IAR printf函数输出中文字符乱码问题
首先看一下IAR的中文字符的坑 这会对调试造成很大的干扰,因为眼见不一定为实. 你所期望的中文打印输出都成了乱码,心在滴血.... 解决方法详细,纯属个人摸索 1.新建notepad++文件,编码方式 ...
- unity A*寻路 (一)导出NavMesh数据
使用unity的API NavMesh.CalculateTriangulation 可以获取NavMesh数据 首先 我们创建一个新的工程 保存一个test场景 然后在场景中添加一个Plane作 ...
- 写了个批量查询qs的软件
因为需要,自己写了个批量查询qs的小软件.从网站中抓出需要的数据,格式化显示: 对字符串进行检测处理,先用Replace函数去掉字符串的空格,再用正则表达式匹配,返回匹配的字符串,如果没有匹配,则返回 ...