Logic回归总结
转自http://blog.csdn.net/dongtingzhizi/article/details/15962797
当我第一遍看完台大的机器学习的视频的时候,我以为我理解了逻辑回归,可后来越看越迷糊,直到看到了这篇文章,豁然开朗
基本原理
Logistic Regression和Linear Regression的原理是相似的,按照我自己的理解,可以简单的描述为这样的过程:
(1)找一个合适的预测函数(Andrew Ng的公开课中称为hypothesis),一般表示为h函数,该函数就是我们需要找的分类函数,它用来预测输入数据的判断结果。这个过程时非常关键的,需要对数据有一定的了解或分析,知道或者猜测预测函数的“大概”形式,比如是线性函数还是非线性函数。
(2)构造一个Cost函数(损失函数),该函数表示预测的输出(h)与训练数据类别(y)之间的偏差,可以是二者之间的差(h-y)或者是其他的形式。综合考虑所有训练数据的“损失”,将Cost求和或者求平均,记为J(θ)函数,表示所有训练数据预测值与实际类别的偏差。
(3)显然,J(θ)函数的值越小表示预测函数越准确(即h函数越准确),所以这一步需要做的是找到J(θ)函数的最小值。找函数的最小值有不同的方法,Logistic Regression实现时有的是梯度下降法(Gradient Descent)。
具体过程
(1) 构造预测函数
Logistic Regression虽然名字里带“回归”,但是它实际上是一种分类方法,用于两分类问题(即输出只有两种)。根据第二章中的步骤,需要先找到一个预测函数(h),显然,该函数的输出必须是两个值(分别代表两个类别),所以利用了Logistic函数(或称为Sigmoid函数),函数形式为:

对应的函数图像是一个取值在0和1之间的S型曲线(图1)。

图1
接下来需要确定数据划分的边界类型,对于图2和图3中的两种数据分布,显然图2需要一个线性的边界,而图3需要一个非线性的边界。接下来我们只讨论线性边界的情况。

图2

图3
对于线性边界的情况,边界形式如下:

构造预测函数为:

hθ(x)函数的值有特殊的含义,它表示结果取1的概率,因此对于输入x分类结果为类别1和类别0的概率分别为:

(2)构造Cost函数
Andrew Ng在课程中直接给出了Cost函数及J(θ)函数如式(5)和(6),但是并没有给出具体的解释,只是说明了这个函数来衡量h函数预测的好坏是合理的。


实际上这里的Cost函数和J(θ)函数是基于最大似然估计推导得到的。下面详细说明推导的过程。(4)式综合起来可以写成:

取似然函数为:

对数似然函数为:

最大似然估计就是要求得使l(θ)取最大值时的θ,其实这里可以使用梯度上升法求解,求得的θ就是要求的最佳参数。但是,在Andrew Ng的课程中将J(θ)取为(6)式,即:

因为乘了一个负的系数-1/m,所以J(θ)取最小值时的θ为要求的最佳参数。
(3)梯度下降法求J(θ)的最小值
求J(θ)的最小值可以使用梯度下降法,根据梯度下降法可得θ的更新过程:

式中为α学习步长,下面来求偏导:

上式求解过程中用到如下的公式:

因此,(11)式的更新过程可以写成:

因为式中α本来为一常量,所以1/m一般将省略,所以最终的θ更新过程为:

之后,参数更新为:
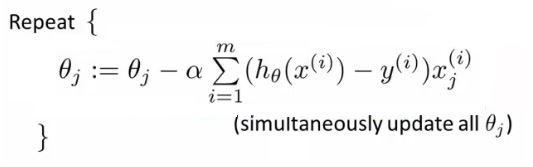
终止条件:
目前指定迭代次数。后续会谈到更多判断收敛和确定迭代终点的方法。
另外,补充一下,3.2节中提到求得l(θ)取最大值时的θ也是一样的,用梯度上升法求(9)式的最大值,可得:

观察上式发现跟(14)是一样的,所以,采用梯度上升发和梯度下降法是完全一样的,这也是《机器学习实战》中采用梯度上升法的原因。
Logic回归总结的更多相关文章
- 逻辑回归(logic regression)的分类梯度下降
首先明白一个概念,什么是逻辑回归:所谓回归就是拟合,说明x是连续的:逻辑呢?就是True和False,也就是二分类:逻辑回归即使就是指对于二分类数据的拟合(划分). 那么什么是模型呢?模型其实就是函数 ...
- MlLib--逻辑回归笔记
批量梯度下降的逻辑回归可以参考这篇文章:http://blog.csdn.net/pakko/article/details/37878837 看了一些Scala语法后,打算看看MlLib的机器学习算 ...
- Apache Spark源码走读之22 -- 浅谈mllib中线性回归的算法实现
欢迎转载,转载请注明出处,徽沪一郎. 概要 本文简要描述线性回归算法在Spark MLLib中的具体实现,涉及线性回归算法本身及线性回归并行处理的理论基础,然后对代码实现部分进行走读. 线性回归模型 ...
- AI - TensorFlow - 分类与回归(Classification vs Regression)
分类与回归 分类(Classification)与回归(Regression)的区别在于输出变量的类型.通俗理解,定量输出称为回归,或者说是连续变量预测:定性输出称为分类,或者说是离散变量预测. 回归 ...
- 机器学习-逻辑回归与SVM的联系与区别
(搬运工) 逻辑回归(LR)与SVM的联系与区别 LR 和 SVM 都可以处理分类问题,且一般都用于处理线性二分类问题(在改进的情况下可以处理多分类问题,如LR的Softmax回归用在深度学习的多分类 ...
- 神经网络、logistic回归等分类算法简单实现
最近在github上看到一个很有趣的项目,通过文本训练可以让计算机写出特定风格的文章,有人就专门写了一个小项目生成汪峰风格的歌词.看完后有一些自己的小想法,也想做一个玩儿一玩儿.用到的原理是深度学习里 ...
- SVM分类与回归
SVM(支撑向量机模型)是二(多)分类问题中经常使用的方法,思想比较简单,但是具体实现与求解细节对工程人员来说比较复杂,如需了解SVM的入门知识和中级进阶可点此下载.本文从应用的角度出发,使用Libs ...
- 原创:去繁存简,回归本源:微信小程序公开课信息分析《一》
以前我开过一些帖子,我们内部也做过一些讨论,我们从张小龙的碎屏图中 ,发现了重要讯息: 1:微信支付将成为重要场景: 2:这些应用与春节关系不小,很多应用在春节时,有重要的场景开启可能性: 3:春节是 ...
- [占位-未完成]scikit-learn一般实例之十:核岭回归和SVR的比较
[占位-未完成]scikit-learn一般实例之十:核岭回归和SVR的比较
随机推荐
- CFile CStdioFile CArchive 文件操作之异同(详细)
两者的主要区别: 一. CFile类操作文件默认的是Binary模式,CStdioFile类操作文件默认的是Text模式. 在Binary模式下我们必须输入'\r\n',才能起到回车换行的效果, ...
- SQL才是世界上最牛逼的语言!
身处互联网行业,SQL 可能是你需要掌握的核心技能之一. 最早的时候,SQL 作为一门查询数据库的语言,是程序员的必备技能,运维.开发.Web 以及数据等从业人员都需要用到 SQL,毕竟只有查询到正确 ...
- pthread_create()的一个错误示例
//pthread_create()函数的错误示例 //新建线程同时传入线程号.线程号总和和消息 #include <stdio.h> #include <pthread.h> ...
- 使用allure2生成精美报告
安装:brew install allure pip install allure-pytest 在测试执行期间收集结果 pytest -s –q --alluredir=./result/ 测试完成 ...
- python之求字典最值
本例子求字典最小值 首先字典分为键和值 eg: {键:值} prices = { 'ACME': 45.23, 'AAPL': 612.78, 'IBM': 205.55, 'HPQ': 37.20, ...
- opensns功能详解
<!DOCTYPE html> opensns功能详解 wmd-preview h1 { color: #0077bb; /* 将标题改为蓝色 */ } opensns功能详解 软件工程 ...
- 检查目录下 文件的权限-linux shell脚本
#!/bin/bash #History: #2019/07/23 Fsq #This Program will check Permissions on dir PATH=/bin:/sbin ...
- 【Leetcode周赛】从contest1开始。(一般是10个contest写一篇文章)
注意,以前的比赛我是自己开了 virtual contest.这个阶段的目标是加快手速,思考问题的能力和 bug-free 的能力. 前面已经有了100个contest.计划是每周做三个到五个cont ...
- 微信小程序 封装接口
1.util-util.js //封装接口 let baseURL = 'http://127.0.0.1:3000/'; //接口路径 let request = function (url, op ...
- 正规式α向有限自动机M的转换
[注:这一节是在学习东南大学廖力老师的公开课时,所记录的一些知识点截屏,谢谢廖力老师的辛劳付出] 引入3条正规式分裂规则来分裂α,所得到的是NFA M(因为包含ε弧,之后进行确定化就是所需要求得DF ...