大数据笔记(三十一)——SparkStreaming详细介绍,开发spark程序
Spark Streaming: Spark用于处理流式数据的模块,类似Storm
核心:DStream(离散流),就是一个RDD
============================================
一、Spark Streaming基础
1、什么是Spark Streaming?
(*)Spark Streaming makes it easy to build scalable fault-tolerant streaming applications.
(*)常见的流式处理框架
(1)Apache Storm
(2)Spark Streaming
(3)JStorm:阿里巴巴
(4)Flink:可以很好的管理内存
(*)离线计算和流式计算各自的特点
典型代表 数据的采集 数据源(结果)
离线计算: MR、Spark Core Sqoop 批量操作
流式计算: Storm等等 Flume(Kafka) 实时性
(*)典型的流式计算的框架:参考Hadoop的课件:P91
2、简介Spark Streaming内部结构
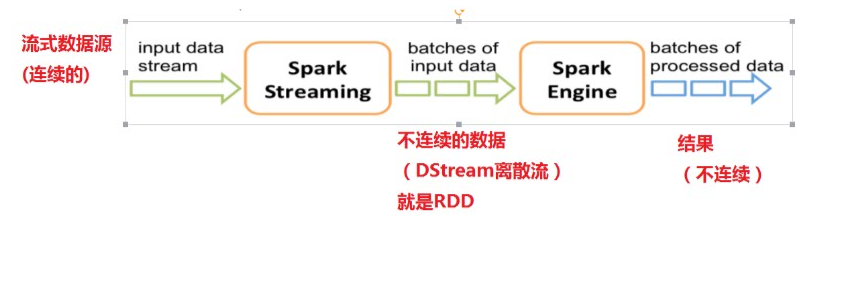
3、演示Demo:NetworkWordCount 处理的是流式数据
(*)工具:netcat
(*)文档:http://spark.apache.org/docs/latest/streaming-programming-guide.html#a-quick-example
(*)步骤:启动两个窗口
第一个窗口中:
bin/run-example streaming.NetworkWordCount bigdata11 9999
第二个窗口中:启动消息服务器(先启动)
nc -l -p 9999
注意:如果要演示成功,保证虚拟机的CPU的核数至少2以上
运行:

4、开发自己的NetworkWordCount程序
package main.scala.demo import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext} /**
* Created by YOGA on 2018/2/27.
*/
object MyNetworkWordCount {
def main(args: Array[String]) {
//核心:通过StreamingContext对象,去创建一个DStream
//DStream从外部接收数据(使用的是Linux上的netcat工具) //创建一个SparkConf对象
//local[2]:相当于有两个工作线程,一个接收一个发送
val sparkconf = new SparkConf()
.setAppName("MyNetworkWordCount")
.setMaster("local[2]") //创建StreamContext,表示每隔三秒采集一次数据
val ssc = new StreamingContext(sparkconf,Seconds(3)) //创建DStream,看成一个输入流
//IP,端口,缓存到硬盘 val lines = ssc.socketTextStream("192.168.153.11",1234,StorageLevel.MEMORY_AND_DISK_SER) //执行WordCount
val words = lines.flatMap(_.split(" ")) //使用transform完成同样的计数,相当于map操作
//val wordPair = words.transform(x=>x.map(x=>(x,1)))
//val wordCount = wordPair.reduceByKey(_+_)
val wordCount = words.map((_,1)).reduceByKey(_+_) /*
* 参数一:执行运算
* 参数二:窗口的大小
* 参数三:创建滑动的距离
*
* 例子:每9秒钟,把过去30秒的数据进行wordcount
* 注意:第二个参数 第三个参数 必须是采样频率的整数倍
* */
//val wordCount = words.map((_,1)).reduceByKeyAndWindow((a:Int,b:Int)=>(a+b),Seconds(30),Seconds(9))
//输出
wordCount.print() //启动StreamingContext
ssc.start() //等待计算完成
ssc.awaitTermination()
} }
二、Spark Streaming进阶
bin/spark-shell --master spark://bigdata11:7077
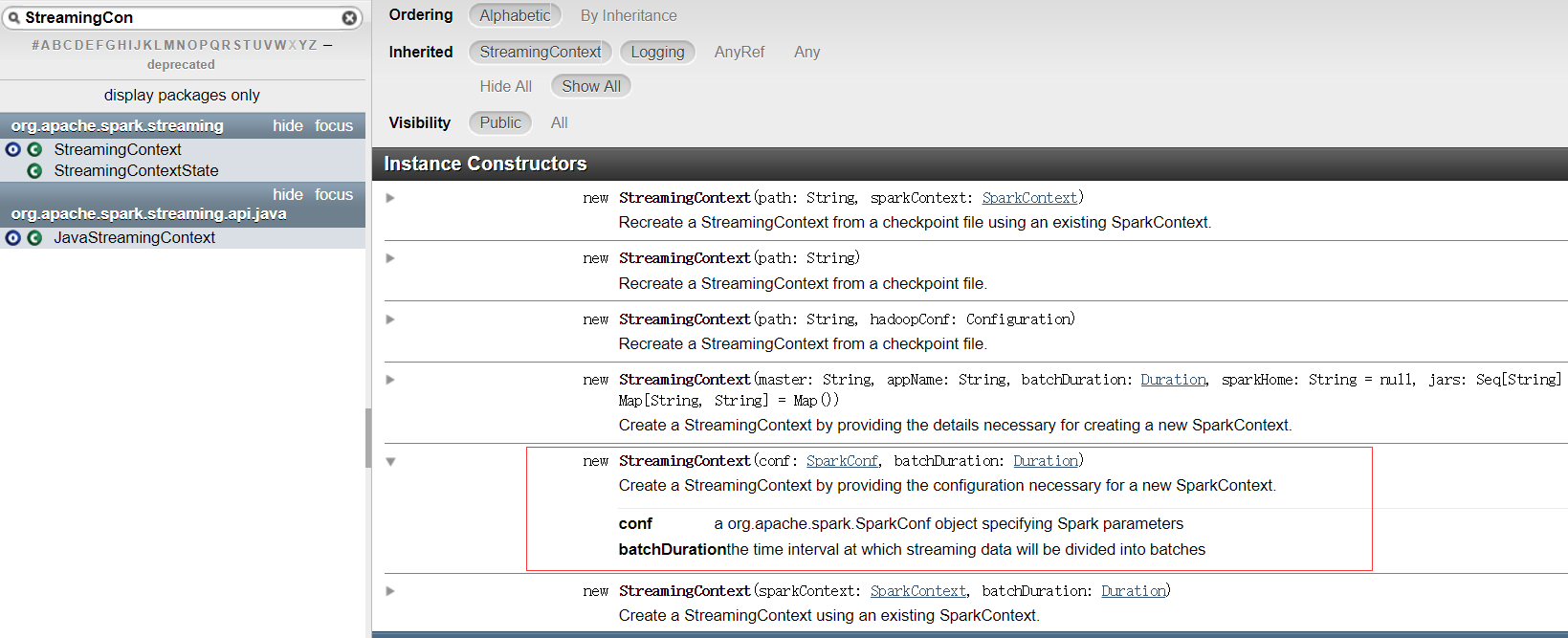
1、类:StreamingContext(类似:Spark Context、SQLContext)
上下文对象
创建的方式:
(1)通过SparkConf来创建
val sparkconf = new SparkConf().setAppName("MyNetworkWordCount").setMaster("local[2]")
//创建StreamingContext,表示每隔3秒采集一次数据
val ssc = new StreamingContext(sparkconf,Seconds(3))
(2)通过SparkContext对象来创建
import org.apache.spark.streaming.{Seconds, StreamingContext}
val ssc = new StreamingContext(sc,Seconds(3))
说明:
(1)setMaster("local[2]")
(2)当创建StreamingContext对象,内部会创建一个SparkContext对象
(3)当StreamingContext开始执行,不能添加新的任务
(4)同一个时刻上,JVM只能有一个活动的StreamingContext
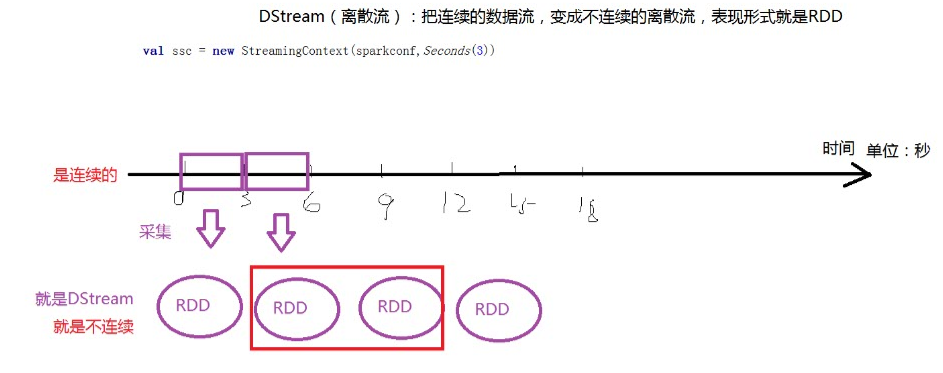
2、DStream(离散流):把连续的数据流,变成不连续的离散流,表现形式就是RDD
简单来说:把连续的变成不连续的
操作:Transformation和Action
(*)transform(func)
通过RDD-to-RDD函数作用于源DStream中的各个RDD,可以是任意的RDD操作,从而返回一个新的RDD
改写上面WordCount例子,屏蔽35行
//使用transform完成同样的计数,相当于map操作
33 val wordPair = words.transform(x=>x.map(x=>(x,1)))
34 val wordCount = wordPair.reduceByKey(_+_)
(*)updateStateByKey(func)
可以进行累加操作。方法:设置检查点,定义一个累加功能的函数
package main.scala.demo import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext} /**
* Created by YOGA on 2018/2/28.
*/
object MyTotalNetworkWordCount {
def main(args: Array[String]) {
val sparkconf = new SparkConf()
.setAppName("MyNetworkWordCount")
.setMaster("local[2]") //创建StreamContext,表示每隔三秒采集一次数据
val ssc = new StreamingContext(sparkconf,Seconds(3)) //注意:如果累计,在执行计算的时候,需要保持之前的状态信息
//设置检查点
ssc.checkpoint("hdfs://192.168.153.11:9000/spark/checkpoint0228") //创建DStream,看成一个输入流
val lines = ssc.socketTextStream("192.168.153.11",1234,StorageLevel.MEMORY_AND_DISK_SER) //执行WordCount
val words = lines.flatMap(_.split(" ")) //每个单词记一次数
val pairs = words.map((_,1)) //定义一个函数,进行累加
//参数:1、当前的值 2、之前的值
val addFunc = (currentValues:Seq[Int],preValues:Option[Int]) =>{
//得到当前的值
val currentCount = currentValues.sum //先得到之前的值
val preCount = preValues.getOrElse(0) //返回累加结果
Some(currentCount + preCount)
} //统计每个单词出现的频率:累计
val totalCount = pairs.updateStateByKey(addFunc)
totalCount.print() //启动任务
ssc.start()
ssc.awaitTermination() }
}
3、窗口操作
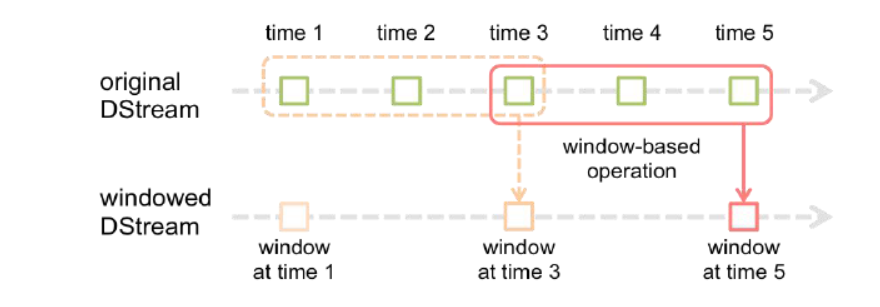

例子:每9秒钟,把过去30秒的数据进行WordCount
注释上面的代码35行,放开下面一行代码
/*
38 * 参数一:执行运算
39 * 参数二:窗口的大小
40 * 参数三:创建滑动的距离
41 *
42 * 例子:每9秒钟,把过去30秒的数据进行wordcount
43 * 注意:第二个参数 第三个参数 必须是采样频率的整数倍,采样频率3s
44 * */
45 val wordCount = words.map((_,1)).reduceByKeyAndWindow((a:Int,b:Int)=>(a+b),Seconds(30),Seconds(9))
4、输入和输出
(1)输入:接收器接收外部数据源的数据
(*)基本数据源:文件流、RDD队列流、Socket流
(*)高级数据源:Kafka、Flume
文件流:监听一个目录,当目录下的文件发生变化的时候,将变化的数据读入DStream
package main.scala.demo import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext} /**
* Created by YOGA on 2018/2/28.
*/
object MyFileDStream {
def main(args: Array[String]) {
//创建一个SparkConf对象
//local[2]:相当于有两个工作线程,一个接收一个发送
val sparkconf = new SparkConf()
.setAppName("MyNetworkWordCount")
.setMaster("local[2]") //创建StreamContext,表示每隔三秒采集一次数据
val ssc = new StreamingContext(sparkconf,Seconds(3)) //监听一个目录,当目录下的文件发生变化的时候,将变化的数据读入DStream
val lines = ssc.textFileStream("D:\\temp\\aaa") lines.print() ssc.start()
ssc.awaitTermination()
}
}
RDD队列流queueStream
:定义一个for循环,生成RDD放入队列
package main.scala.demo import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext} import scala.collection.mutable
import scala.collection.mutable.Queue
import org.apache.spark.rdd.RDD
/**
* Created by YOGA on 2018/2/28.
*/
object MyRDDQueueDStream {
def main(args: Array[String]){
val sparkconf = new SparkConf()
.setAppName("MyNetworkWordCount")
.setMaster("local[2]") //创建StreamContext,表示每隔三秒采集一次数据
val ssc = new StreamingContext(sparkconf,Seconds(3)) //创建一个队列,把生成RDD放入队列
val rddQueue = new mutable.Queue[RDD[Int]]()
//初始化
for(i <- 1 to 3){
rddQueue += ssc.sparkContext.makeRDD(1 to 10) //让线程睡几秒
Thread.sleep(3000) } //创建一个RDD的DStream
val inputStream = ssc.queueStream(rddQueue)
//处理:乘以10
val result = inputStream.map(x=> (x,x*10))
result.print() ssc.start()
ssc.awaitTermination()
}
}
运行:
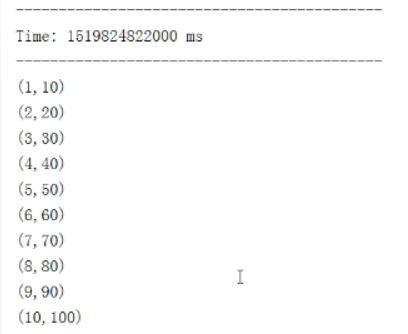
(2)输出操作

5、集成DataFrame和SQL: 使用SparkSQL的方式处理流式数据
把RDD转换成DataFrame,并生成临时表,然后就可以进行SQL查询
先在虚拟机开启1234端口:
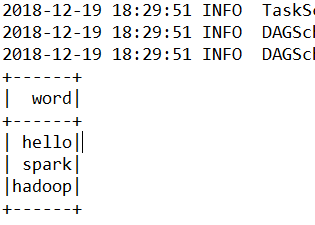
[root@test ~]# nc -l -p 1234
hello spark hello hadoop
结果:
package main.scala.demo import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext} /**
* Created by YOGA on 2018/2/28.
*/
object MyNetWorkWordCountBySQL {
def main(args: Array[String]) {
//核心:通过StreamingContext对象,去创建一个DStream
//DStream从外部接收数据(使用的是Linux上的netcat工具) //创建一个SparkConf对象
//local[2]:相当于有两个工作线程,一个接收一个发送
val sparkconf = new SparkConf()
.setAppName("MyNetworkWordCount")
.setMaster("local[2]") //创建StreamContext,表示每隔三秒采集一次数据
val ssc = new StreamingContext(sparkconf,Seconds(3)) //创建DStream,看成一个输入流
val lines = ssc.socketTextStream("192.168.153.11",1234,StorageLevel.MEMORY_AND_DISK_SER) //得到的所有单词
val words = lines.flatMap(_.split(" "))
//val wordPair = words.transform(x=> x.map(x=>(x,1)))
//val wordCount = wordPair.reduceByKey(_+_) //使用sparkSQL处理Spark Streaming的数据
words.foreachRDD(rdd =>{
//使用SparkSession来创建
val spark = SparkSession.builder()
.config(rdd.sparkContext.getConf)
.getOrCreate() //需要把RDD转成一个DataFrame
import spark.implicits._
val wordCountDF = rdd.toDF("word") //注册成一个表
wordCountDF.createOrReplaceTempView("words") //执行SQL
val result = spark.sql("select * from words group by word")
result.show() Thread.sleep(5000)
}) //启动StreamingContext
ssc.start() //等待计算完成
ssc.awaitTermination()
}
}
大数据笔记(三十一)——SparkStreaming详细介绍,开发spark程序的更多相关文章
- 大数据笔记(二十八)——执行Spark任务、开发Spark WordCount程序
一.执行Spark任务: 客户端 1.Spark Submit工具:提交Spark的任务(jar文件) (*)spark提供的用于提交Spark任务工具 (*)example:/root/traini ...
- 大数据笔记(三十)——一篇文章读懂SparkSQL
Spark SQL:类似Hive ======================================================= 一.Spark SQL基础 1.什么是Spark SQ ...
- angular学习笔记(三十一)-$location(2)
之前已经介绍了$location服务的基本用法:angular学习笔记(三十一)-$location(1). 这篇是上一篇的进阶,介绍$location的配置,兼容各版本浏览器,等. *注意,这里介绍 ...
- angular学习笔记(三十一)-$location(1)
本篇介绍angular中的$location服务的基本用法,下一篇介绍它的复杂的用法. $location服务的主要作用是用于获取当前url以及改变当前的url,并且存入历史记录. 一. 获取url的 ...
- 学习Hadoop+Spark大数据巨量分析与机器学习整合开发-windows利用虚拟机实现模拟多节点集群构建
记录学习<Hadoop+Spark大数据巨量分析与机器学习整合开发>这本书. 第五章 Hadoop Multi Node Cluster windows利用虚拟机实现模拟多节点集群构建 5 ...
- 大数据笔记(三十二)——SparkStreaming集成Kafka与Flume
三.集成:数据源 1.Apache Kafka:一种高吞吐量的分布式发布订阅消息系统 (1) (*)消息的类型 Topic:主题(相当于:广播) Queue:队列(相当于:点对点) (*)常见的消息系 ...
- 大数据笔记(一)——Hadoop的起源与背景知识
一.大数据的5个特征(IBM提出): Volume(大量) Velocity(高速) Variety(多样) Value(价值) Varacity(真实性) 二.OLTP与OLAP 1.OLTP:联机 ...
- 大数据学习(18)—— Flume介绍
老规矩,学习新东西先上官网瞅瞅Apache Flume Flume是什么 Flume是一个分布式.可靠的大规模高效日志收集.汇聚和传输的这么一个服务.它的架构基于流式数据,配置简单灵活.它具备可调节的 ...
- 大数据学习(06)——Ozone介绍
前面几篇文章把Hadoop常用的模块都学习了,剩下一个新模块Ozone,截止到今天最新版本是0.5.0Beta,还没出正式版.好在官方网站有文档,还是中文版的,但是中文版资料没有翻译完整,我试着把它都 ...
- 我眼中的大数据(三)——MapReduce
这次来聊聊Hadoop中使用广泛的分布式计算方案--MapReduce.MapReduce是一种编程模型,还是一个分布式计算框架. MapReduce作为一种编程模型功能强大,使用简单.运算内容不 ...
随机推荐
- [ZJOI2007]时态同步 题解
题面 这道题是一道比较水的XXOI题: 我们可以发现,反着思考题目就变为了让所有叶子节点同时发出信号,然后这些信号同时到达根节点: 可以证明,这样答案不会改变: 那么我们可以自下而上dfs(),设f[ ...
- Spring Cloud 入门概括介绍
出处: 拜托!面试请不要再问我Spring Cloud底层原理 概述 毫无疑问,Spring Cloud是目前微服务架构领域的翘楚,无数的书籍博客都在讲解这个技术.不过大多数讲解还停留在对Spring ...
- 简述在Ubuntu终端打开文件的几种不同方法与区别
一· 在Ubuntu下,通常用命令行打开文本文件,比如用命令gedit.more.cat.vim.less. gedit:在文本软件下打开文件,可直接修改. more ,cat 和 less :类似, ...
- vue2-brace-editor代码编辑器添加自定义代码提示(修改源码)
下载vue2-brace-editor源代码,先执行npm install安装项目依赖 在ace.component.vue组件的methods添加setCustomPrompts方法 修改完源码后, ...
- iOS 10 下 Plus 启动APP 导致Icon 铺满全屏问题
1.解决方法,添加LacuchScreen 启动图需要手动适配 http://stackoverflow.com/questions/39571694/ipad-application-shows-a ...
- docker inspect命令查看镜像详细信息
使用 inspect 命令查看镜像详细信息,包括制作者.适应架构.各层的数字摘要等. # docker inspect --help Usage: docker inspect [OPTIONS] N ...
- 电脑系统win7和samba服务器连接不上解决办法
1.修改本地安全策略运行secpol.msc打开“本地安全策略”窗体,依次点开“本地策略”->“安全选项”,修改“网络安全: LAN 管理器身份验证级别”的值为“发送 LM 和 NTLM – 如 ...
- C#使用反射机制获取类信息
1.用反射动态创建类实例,并调用其公有成员函数. //新建一个类库项目,增加一个GetSum方法. using System; namespace ClassLibrary1 { publi ...
- GPT-2,吓坏创造者的「深度造假写手」
简评: 今年二月份刷屏的 GPT-2 着实厉害,那个生成续写故事的例子更是效果好到吓人一跳,它到底有多厉害,本文略微讲讲.更详细的信息可参考文末 OpenAI 的博客链接. 你能从下面这两段文字里品味 ...
- Ubuntu16.04下安装httpd+svn+viewVC
一.安装httpd 1.下载httpd 网址:http://httpd.apache.org/download.cgi#apache24 下载这一条---Source: httpd-2.4.39.ta ...