scrapy项目4:爬取当当网中机器学习的数据及价格(CrawlSpider类)
scrapy项目3中已经对网页规律作出解析,这里用crawlspider类对其内容进行爬取;
项目结构与项目3中相同如下图,唯一不同的为book.py文件
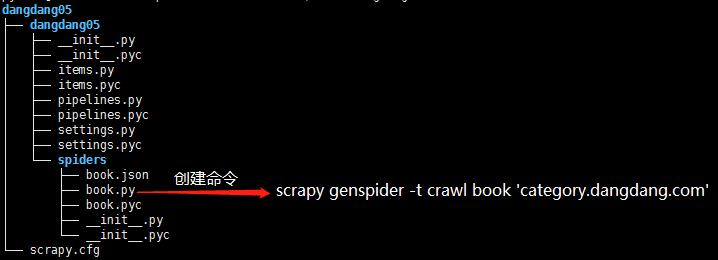
crawlspider类的爬虫文件book的生成命令为:scrapy genspider -t crawl book 'category.dangdang.com'
book.py代码如下:
# -*- coding: utf-8 -*-
import scrapy
# 创建用于提取响应中连接的对象
from scrapy.linkextractors import LinkExtractor
# Rule 用于发送从 LinkExtractor 中提取的连接
from scrapy.spiders import CrawlSpider, Rule
from dangdang05.items import Dangdang05Item class BookSpider(CrawlSpider):
name = 'book'
allowed_domains = ['category.dangdang.com']
start_urls = ['http://category.dangdang.com/cp01.54.12.00.00.00.html']
# 提取连接信息,并将提取到的向提取到的url发送请求,调用回调函数处理请求
# 注意follow表示是否继续对response中的连接进行提取,True表示提取,False表示不再提取
# 当未指定回调函数时,follow的默认值为True,当指定回调函数时follow的默认值为False
rules = [Rule(LinkExtractor(allow=r'/pg\d+-cp01.54.12.00.00.00.html'),callback='parse_item',follow=True)] def parse_item(self, response):
# 实例化items中的类
item = Dangdang05Item()
# 网页解析第一步,返回selector对对象
book_list = response.xpath('//ul[@class="bigimg"]/li') for book_info in book_list:
# 书籍名称
item['name'] = book_info.xpath('./p[@class="name"]/a/@title').extract()[0]
# 书籍价格
item['price'] = book_info.xpath('./p[@class="price"]/span[1]/text()').extract()[0]
yield item
scrapy项目4:爬取当当网中机器学习的数据及价格(CrawlSpider类)的更多相关文章
- scrapy项目3:爬取当当网中机器学习的数据及价格(spider类)
1.网页解析 当当网中,人工智能数据的首页url如下为http://category.dangdang.com/cp01.54.12.00.00.00.html 点击下方的链接,一次观察各个页面的ur ...
- Scrapy爬虫(5)爬取当当网图书畅销榜
本次将会使用Scrapy来爬取当当网的图书畅销榜,其网页截图如下: 我们的爬虫将会把每本书的排名,书名,作者,出版社,价格以及评论数爬取出来,并保存为csv格式的文件.项目的具体创建就不再多讲 ...
- python爬虫06 | 你的第一个爬虫,爬取当当网 Top 500 本五星好评书籍
来啦,老弟 我们已经知道怎么使用 Requests 进行各种请求骚操作 也知道了对服务器返回的数据如何使用 正则表达式 来过滤我们想要的内容 ... 那么接下来 我们就使用 requests 和 re ...
- 网络爬虫之定向爬虫:爬取当当网2015年图书销售排行榜信息(Crawler)
做了个爬虫,爬取当当网--2015年图书销售排行榜 TOP500 爬取的基本思想是:通过浏览网页,列出你所想要获取的信息,然后通过浏览网页的源码和检查(这里用的是chrome)来获相关信息的节点,最后 ...
- python爬取当当网的书籍信息并保存到csv文件
python爬取当当网的书籍信息并保存到csv文件 依赖的库: requests #用来获取页面内容 BeautifulSoup #opython3不能安装BeautifulSoup,但可以安装Bea ...
- python爬取返利网中值得买中的数据
先使用以前的方法将返利网的数据爬取下来,scrapy框架还不熟练,明日再战scrapy 查找目标数据使用的是beautifulsoup模块. 1.观察网页,寻找规律 打开值得买这块内容 1>分析 ...
- java爬虫,爬取当当网数据
背景:女票快毕业了(没错!我是有女票的!!!),写论文,主题是儿童性教育,查看儿童性教育绘本数据死活找不到,没办法,就去当当网查询下数据,但是数据怎么弄下来呢,首先想到用Python,但是不会!!百 ...
- 【转】java爬虫,爬取当当网数据
背景:女票快毕业了(没错!我是有女票的!!!),写论文,主题是儿童性教育,查看儿童性教育绘本数据死活找不到,没办法,就去当当网查询下数据,但是数据怎么弄下来呢,首先想到用Python,但是不会!!百 ...
- selenium自动化测试工具模拟登陆爬取当当网top500畅销书单
selenium自动化测试工具可谓是爬虫的利器,基本动态加载的网页都能抓取,当然随着大型网站的更新,也出现针对selenium的反爬,有些网站可以识别你是否用的是selenium访问,然后对你加以限制 ...
随机推荐
- python 并发编程 协程 协程介绍
协程:是单线程下的并发,又称微线程,纤程.英文名Coroutine.一句话说明什么是线程:协程是一种用户态的轻量级线程,即协程是由用户程序自己控制调度的 需要强调的是: 1. python的线程属于内 ...
- 2019ICPC徐州游记
裂开QAQ 热身赛听隔壁电科的猛男们说赛前别做题,结果我们3个憨憨还是跑到网吧打哈尔滨的重现赛.结果真的炸裂了,队友D被E题卡哭了,我和队友Z被I题搞炸. 回宾馆的路上都害怕明天裂开. 果然想什么坏事 ...
- 洛谷 P4779 单源最短路径(标准版) 题解
题面 这道题就是标准的堆优化dijkstra: 注意堆优化的dijkstra在出队时判断vis,而不是在更新时判断vis #include <bits/stdc++.h> using na ...
- 用ansible修改用户密码并给予挂载点
--- - hosts: myjob gather_facts: false tasks: - name: chage user passwd user: name={{ item.name }} p ...
- Radio Button误区
在同一个父容器下,Radio Button控件默认只能选择一个,所以无需多余代码管控 如果将Radio Button的多个子对象存入NSArray列表,发现长度为0(巨坑),因此通过列表对其初始化不可 ...
- LeetCode_9_回文数字
回文数(LeetCode 9) 1.题目 判断一个整数是否是回文数.回文数是指正序(从左向右)和倒序(从右向左)读都是一样的整数. 示例 1: 输入: 121 输出: true 示例 2: 输入: - ...
- PHP的htmlspecialchars、strip_tags、addslashes
PHP的htmlspecialchars.strip_tags.addslashes是网页程序开发中常见的函数,今天就来详细讲述这些函数的用法: 1.函数strip_tags:去掉 HTML 及 PH ...
- 终于明白上一篇的一顿误操作是什么了,是$,不是S !!!!!
1,在命令行中输入export PATH=/usr/bin:/usr/sbin:/bin:/sbin:/usr/X11R6/bin这样可以保证命令行命令暂时可以使用.命令执行完之后先不要关闭终端2. ...
- mysql占用磁盘IO过高的解决办法
一.现象 最近发现Mysql服务器磁盘IO一直很高 [root@push-- ~]# iostat -k -d -x Linux -.el7.x86_64 (push--) 2019年07月05日 _ ...
- 使用IL DASM来查看接口内的自动属性
在我的本地地址中 C:\Program Files (x86)\Microsoft SDKs\Windows\v10.0A\bin\NETFX 4.6.2 Tools\x64下有一个文件 ildas ...