python全栈开发,Day40(进程间通信(队列和管道),进程间的数据共享Manager,进程池Pool)
昨日内容回顾
进程
multiprocess
Process —— 进程 在python中创建一个进程的模块
start
daemon 守护进程
join 等待子进程执行结束 锁 Lock
acquire release
锁是一个同步控制的工具
如果同一时刻有多个进程同时执行一段代码,
那么在内存中的数据是不会发生冲突的
但是,如果涉及到文件,数据库就会发生资源冲突的问题
我们就需要用锁来把这段代码锁起来
任意一个进程执行了acquire之后,
其他所有的进程都会在这里阻塞,等待一个release 信号量 semaphore
锁 + 计数器
同一时间只能有指定个数的进程执行同一段代码 事件 Event
set clear is_set 控制对象的状态
wait 根据状态不同执行效果也不同
状态是True ---> pass
状态是False --> 阻塞
一般wait是和set clear放在不同的进程中
set/clear负责控制状态
wait负责感知状态
我可以在一个进程中控制另外一个或多个进程的运行情况 IPC通信
队列 Queue
管道 PIPE
一、进程间通信(队列和管道)
判断队列是否为空
from multiprocessing import Process,Queue
q = Queue()
print(q.empty())
执行输出:True
判断队列是否满了
from multiprocessing import Process,Queue
q = Queue()
print(q.full())
执行输出:False
如果队列已满,再增加值的操作,会被阻塞,直到队列有空余的
from multiprocessing import Process,Queue
q = Queue(10) # 创建一个只能放10个value的队列
for i in range(10):
q.put(i) # 增加一个value
print(q.qsize()) # 返回队列中目前项目的正确数量
print(q.full()) # 如果q已满,返回为True
q.put(111) # 再增加一个值
print(q.empty())
执行输出:
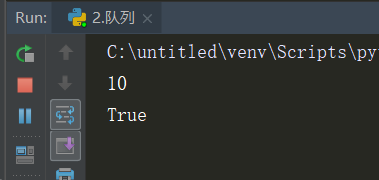
可以看出程序并没有结束,q.put(111)之后的代码被阻塞了。
总结:
队列可以在创建的时候指定一个容量
如果在程序运行的过程中,队列已经有了足够的数据,再put就会发生阻塞
如果队列为空,再get就会发生阻塞
为什么要指定队列的长度呢?是为了防止内存爆炸。
一个队列,不能无限制的存储。毕竟内存是有限制的。
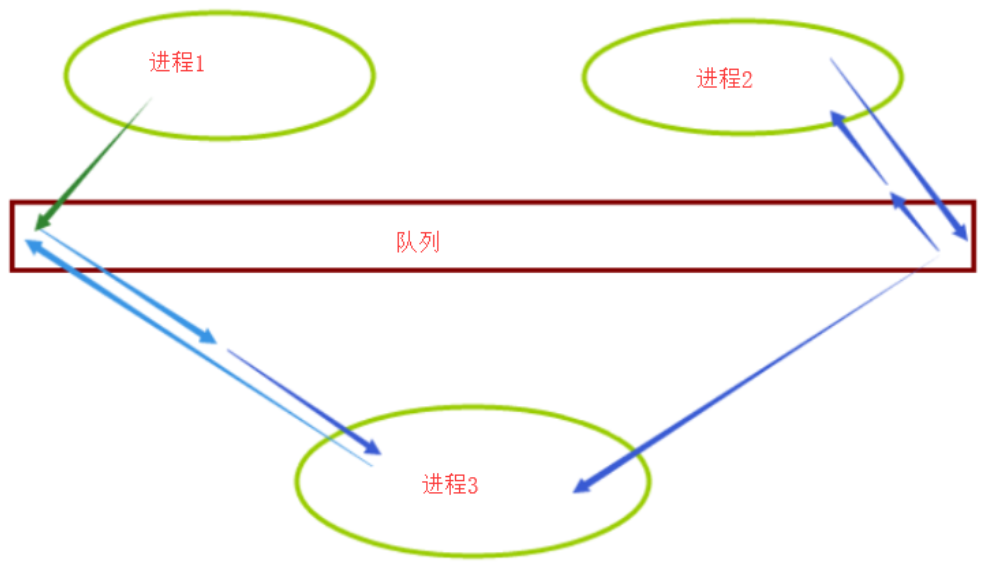
上面提到的put、get、qsize、full、empty都是不准的。
因为在返回结果和在稍后程序中使用结果之间,队列中可能添加或删除了项目。在某些系统上,此方法可能引发NotImplementedError异常。
如果其它进程或线程正在往队列中添加项目,结果是不可靠的。也就是说,在返回和使用结果之间,队列中可能已经加入新的项目。
import time
from multiprocessing import Process,Queue
def wahaha(q):
print(q.get())
q.put(2) # 增加数字2 if __name__ == '__main__':
q = Queue()
p = Process(target=wahaha,args=[q,])
p.start()
q.put(1) # 增加数字1
time.sleep(0.2)
print(q.get())
执行输出:
1
2
先执行主进程的q.get(),再执行子进程的q.get()
在进程中使用队列可以完成双向通信
队列是进程安全的,内置了锁来保证队列中的每一个数据都不会被多个进程重复取
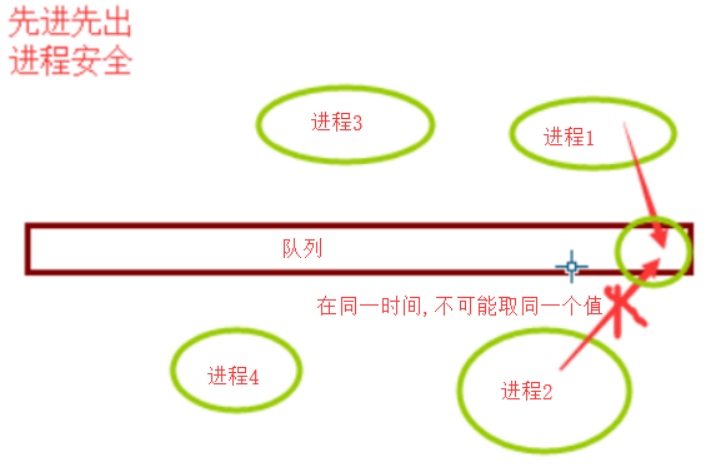
在同一时刻,只能有一个进程来取值,它内部有一个锁的机制。那么另外一个进程就会阻塞一会,但是阻塞的时间非常短,队列能保证数据安全,同一个数据,不能被多个进程获取。
生产者消费者模型
解决数据供需不平衡的情况
from multiprocessing import Process, Queue def producer(q, name, food):
for i in range(5):
print('{}生产了{}{}'.format(name, food, i)) if __name__ == '__main__':
q = Queue()
Process(target=producer, args=(q, '康师傅', '红烧牛肉')).start()
Process(target=producer, args=(q, '郑师傅', '红烧鱼块')).start()
执行输出:

增加一个消费者
import time
import random
from multiprocessing import Process, Queue def producer(q, name, food):
for i in range(5):
time.sleep(random.random()) # 模拟生产时间
print('{}生产了{}{}'.format(name, food, i))
q.put('{}{}'.format(food, i)) # 放入队列 def consumer(q, name):
for i in range(10):
food = q.get() # 获取队列
time.sleep(random.random()) # 模拟吃的时间
print('{}吃了{}'.format(name, food)) if __name__ == '__main__':
q = Queue()
Process(target=producer, args=(q, '康师傅', '红烧牛肉')).start()
Process(target=producer, args=(q, '郑师傅', '红烧鱼块')).start()
Process(target=consumer, args=(q, 'xiao')).start()
执行输出:

消费者,必须是有的吃,才能吃。没有吃的,就等着。一个消费者,明显消费不过来,再加一个消费者
import time
import random
from multiprocessing import Process, Queue def producer(q, name, food):
for i in range(5):
time.sleep(random.random()) # 模拟生产时间
print('{}生产了{}{}'.format(name, food, i))
q.put('{}{}'.format(food, i)) # 放入队列 def consumer(q, name):
for i in range(5): # 修改为5,因为有2个人
food = q.get() # 获取队列
time.sleep(random.random()) # 模拟吃的时间
print('{}吃了{}'.format(name, food)) if __name__ == '__main__':
q = Queue()
Process(target=producer, args=(q, '康师傅', '红烧牛肉')).start()
Process(target=producer, args=(q, '郑师傅', '红烧鱼块')).start()
Process(target=consumer, args=(q, 'xiao')).start()
Process(target=consumer, args=(q, 'lin')).start()
执行输出:

注意:必须将消费者的range(10)修改为5,否则程序会卡住。为什么呢?因为队列已经是空的,再取就会阻塞,这样才能解决供需平衡
那么问题来了,如果有一个消费者,吃的比较快呢?
再修改range值?太Low了
能者多老嘛,不能使用q.empty(),它是是不准确的
看下图,有可能一开始,队列就空了
下面的0.1更快
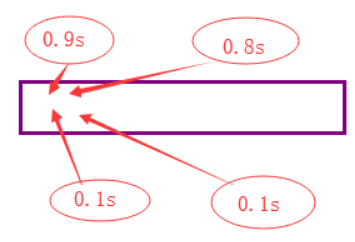
看下面的解决方案:
import time
import random
from multiprocessing import Process, Queue def producer(q, name, food):
for i in range(5):
time.sleep(random.random()) # 模拟生产时间
print('{}生产了{}{}'.format(name, food, i))
q.put('{}{}'.format(food, i)) # 放入队列 def consumer(q, name):
while True:
food = q.get() # 获取队列
if food == 'done': break # 当获取的值为done时,结束循环
time.sleep(random.random()) # 模拟吃的时间
print('{}吃了{}'.format(name, food)) if __name__ == '__main__':
q = Queue() # 创建队列对象,如果不提供maxsize,则队列数无限制
p1 = Process(target=producer, args=(q, '康师傅', '红烧牛肉'))
p2 = Process(target=producer, args=(q, '郑师傅', '红烧鱼块'))
p1.start() # 启动进程
p2.start()
Process(target=consumer, args=(q, 'xiao')).start()
Process(target=consumer, args=(q, 'lin')).start()
p1.join() # 保证子进程结束后再向下执行
p2.join()
q.put('done') # 向队列添加一个值done
q.put('done')
执行输出:

为什么要有2个done?因为有2个消费者
为什么要有2个join?因为必须要等厨师做完菜才可以。
最后输出2个done,表示通知2个顾客,菜已经上完了,顾客要结账了。
2个消费者,都会执行break。通俗的来讲,亲,您一共消费了xx元,请付款!
上面的解决方案,代码太长了,有一个消费者,旧的done一次。
下面介绍JoinableQueue
JoinableQueue([maxsize])
创建可连接的共享进程队列。这就像是一个Queue对象,但队列允许项目的使用者通知生产者项目已经被成功处理。通知进程是使用共享的信号和条件变量来实现的。
JoinableQueue的实例p除了与Queue对象相同的方法之外,还具有以下方法: q.task_done()
使用者使用此方法发出信号,表示q.get()返回的项目已经被处理。如果调用此方法的次数大于从队列中删除的项目数量,将引发ValueError异常。 q.join()
生产者将使用此方法进行阻塞,直到队列中所有项目均被处理。阻塞将持续到为队列中的每个项目均调用q.task_done()方法为止。
下面的例子说明如何建立永远运行的进程,使用和处理队列上的项目。生产者将项目放入队列,并等待它们被处理。
JoinableQueue队列实现消费者生产者 模型
import time
import random
from multiprocessing import Process, JoinableQueue def producer(q, name, food):
for i in range(5):
time.sleep(random.random())
print('{}生产了{}{}'.format(name, food, i))
q.put('{}{}'.format(food, i))
q.join() # 等到所有的数据都被task_done才结束 def consumer(q, name):
while True:
food = q.get() # 获取队列
time.sleep(random.random()) # 模拟吃的时间
print('{}吃了{}'.format(name, food))
q.task_done() # 向q.join()发送一次信号,证明一个数据已经被取走了 if __name__ == '__main__':
q = JoinableQueue() # 创建可连接的共享进程队列
# 生产者们:即厨师们
p1 = Process(target=producer, args=(q, '康师傅', '红烧牛肉'))
p2 = Process(target=producer, args=(q, '郑师傅', '红烧鱼块'))
p1.start() # 启动进程
p2.start()
# 消费者们:即吃货们
c1 = Process(target=consumer, args=(q, 'xiao'))
c2 = Process(target=consumer, args=(q, 'lin'))
c1.daemon = True # 设置守护进程
c2.daemon = True
c1.start() # 启动进程
c2.start()
p1.join() # 保证子进程结束后再向下执行
p2.join()
执行输出:

总结:
producer
put
生产完全部的数据就没有其他工作了
在生产数据方:允许执行q.join
join会发起一个阻塞,直到所有当前队列中的数据都被消费
consumer
get 获取到数据
处理数据
q.task_done() 告诉q,刚刚从q获取的数据已经处理完了 consumer每完成一个任务就会给q发送一个taskdone
producer在所有的数据都生产完之后会执行q.join()
producer会等待consumer消费完数据才结束
主进程中对producer进程进行join
主进程中的代码会等待producer执行完才结束
producer结束就意味着主进程代码的结束
consumer作为守护进程结束 结束顺序:
consumer中queue中的所有数据被消费
producer join结束
主今晨过的代码结束
consumer结束
主进程结束
管道(了解):
介绍:
#创建管道的类:
Pipe([duplex]):在进程之间创建一条管道,并返回元组(conn1,conn2),其中conn1,conn2表示管道两端的连接对象,强调一点:必须在产生Process对象之前产生管道
#参数介绍:
dumplex:默认管道是全双工的,如果将duplex射成False,conn1只能用于接收,conn2只能用于发送。
#主要方法:
conn1.recv():接收conn2.send(obj)发送的对象。如果没有消息可接收,recv方法会一直阻塞。如果连接的另外一端已经关闭,那么recv方法会抛出EOFError。
conn1.send(obj):通过连接发送对象。obj是与序列化兼容的任意对象
#其他方法:
conn1.close():关闭连接。如果conn1被垃圾回收,将自动调用此方法
conn1.fileno():返回连接使用的整数文件描述符
conn1.poll([timeout]):如果连接上的数据可用,返回True。timeout指定等待的最长时限。如果省略此参数,方法将立即返回结果。如果将timeout射成None,操作将无限期地等待数据到达。 conn1.recv_bytes([maxlength]):接收c.send_bytes()方法发送的一条完整的字节消息。maxlength指定要接收的最大字节数。如果进入的消息,超过了这个最大值,将引发IOError异常,并且在连接上无法进行进一步读取。如果连接的另外一端已经关闭,再也不存在任何数据,将引发EOFError异常。
conn.send_bytes(buffer [, offset [, size]]):通过连接发送字节数据缓冲区,buffer是支持缓冲区接口的任意对象,offset是缓冲区中的字节偏移量,而size是要发送字节数。结果数据以单条消息的形式发出,然后调用c.recv_bytes()函数进行接收 conn1.recv_bytes_into(buffer [, offset]):接收一条完整的字节消息,并把它保存在buffer对象中,该对象支持可写入的缓冲区接口(即bytearray对象或类似的对象)。offset指定缓冲区中放置消息处的字节位移。返回值是收到的字节数。如果消息长度大于可用的缓冲区空间,将引发BufferTooShort异常。
pipe初使用:
from multiprocessing import Process, Pipe def f(conn):
conn.send("Hello The_Third_Wave")
conn.close() if __name__ == '__main__':
parent_conn, child_conn = Pipe()
p = Process(target=f, args=(child_conn,))
p.start()
print(parent_conn.recv())
p.join() pipe初使用
应该特别注意管道端点的正确管理问题。如果是生产者或消费者中都没有使用管道的某个端点,就应将它关闭。这也说明了为何在生产者中关闭了管道的输出端,在消费者中关闭管道的输入端。如果忘记执行这些步骤,程序可能在消费者中的recv()操作上挂起。管道是由操作系统进行引用计数的,必须在所有进程中关闭管道后才能生成EOFError异常。因此,在生产者中关闭管道不会有任何效果,除非消费者也关闭了相同的管道端点。

from multiprocessing import Pipe
left,right = Pipe()
left.send('1234')
print(right.recv())
执行输出:1234
管道实例化之后,形成2端。默认情况下,管道是双向的
左边send,右边recv
一端send和recv,会阻塞
它不是走TCP和UDP
它是一台机器的多个进程
引发EOFError,程序卡住
from multiprocessing import Process,Pipe
def f(parent_conn,child_conn):
parent_conn.close() # 不写close将不会引发EOFError
while True:
try:
print(child_conn.recv())
except EOFError:
child_conn.close()
break
if __name__ == '__main__':
# 在进程之间创建一条管道,并返回元组(conn1,conn2),其中conn1和conn2是表示管道两端的Connection对象
parent_conn,child_conn = Pipe()
p = Process(target=f,args=(parent_conn,child_conn))
p.start()
child_conn.close() # 关闭连接
parent_conn.send('hello')
parent_conn.send('hello')
parent_conn.send('hello')
parent_conn.close()
p.join() # 等待子进程结束
执行输出:
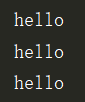
from multiprocessing import Process,Pipe def consumer(p,name):
produce, consume=p
produce.close()
while True:
try:
baozi=consume.recv()
print('%s 收到包子:%s' %(name,baozi))
except EOFError:
break def producer(seq,p):
produce, consume=p
consume.close()
for i in seq:
produce.send(i) if __name__ == '__main__':
produce,consume=Pipe() c1=Process(target=consumer,args=((produce,consume),'c1'))
c1.start() seq=(i for i in range(10))
producer(seq,(produce,consume)) produce.close()
consume.close() c1.join()
print('主进程')
pipe实现生产者消费者模型
from multiprocessing import Process,Pipe,Lock def consumer(p,name,lock):
produce, consume=p
produce.close()
while True:
lock.acquire()
baozi=consume.recv()
lock.release()
if baozi:
print('%s 收到包子:%s' %(name,baozi))
else:
consume.close()
break def producer(p,n):
produce, consume=p
consume.close()
for i in range(n):
produce.send(i)
produce.send(None)
produce.send(None)
produce.close() if __name__ == '__main__':
produce,consume=Pipe()
lock = Lock()
c1=Process(target=consumer,args=((produce,consume),'c1',lock))
c2=Process(target=consumer,args=((produce,consume),'c2',lock))
p1=Process(target=producer,args=((produce,consume),10))
c1.start()
c2.start()
p1.start() produce.close()
consume.close() c1.join()
c2.join()
p1.join()
print('主进程')
多个消费之之间的竞争问题带来的数据不安全问题
进程之间的数据共享
展望未来,基于消息传递的并发编程是大势所趋
即便是使用线程,推荐做法也是将程序设计为大量独立的线程集合,通过消息队列交换数据。
这样极大地减少了对使用锁定和其他同步手段的需求,还可以扩展到分布式系统中。
但进程间应该尽量避免通信,即便需要通信,也应该选择进程安全的工具来避免加锁带来的问题。
以后我们会尝试使用数据库来解决现在进程之间的数据共享问题。
进程间数据是独立的,可以借助于队列或管道实现通信,二者都是基于消息传递的
虽然进程间数据独立,但可以通过Manager实现数据共享,事实上Manager的功能远不止于此 A manager object returned by Manager() controls a server process which holds Python objects and allows other processes to manipulate them using proxies. A manager returned by Manager() will support types list, dict, Namespace, Lock, RLock, Semaphore, BoundedSemaphore, Condition, Event, Barrier, Queue, Value and Array.
Manager模块介绍
Manager是一种较为高级的多进程通信方式,他能支持Python支持的任何数据结构。
它的原理是:先启动一个ManagerServer进程,这个进程是阻塞的,它监听一个socket,然后其他进程(ManagerClient)通过socket来连接到ManagerServer,实现通信。
from multiprocessing import Manager, Process def func(dic):
print(dic) if __name__ == '__main__':
m = Manager() # 创建一个server进程
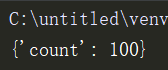
dic = m.dict({'count': 100}) # 这是一个特殊的字典
p = Process(target=func, args=(dic,))
p.start()
p.join()
执行输出:
修改字典的值
from multiprocessing import Manager, Process def func(dic):
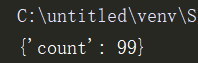
dic['count'] = dic['count'] - 1
print(dic) if __name__ == '__main__':
m = Manager() # 创建一个server进程
dic = m.dict({'count': 100}) # 这是一个特殊的字典
p = Process(target=func, args=(dic,))
p.start()
p.join()
输出:
循环修改
from multiprocessing import Manager, Process def func(dic):
dic['count'] = dic['count'] - 1 # 每次减1 if __name__ == '__main__':
m = Manager() # 创建一个server进程
dic = m.dict({'count': 100}) # 这是一个特殊的字典
p_lst = [] # 定义一个空列表
for i in range(100): # 启动100个进程
p = Process(target=func, args=(dic,))
p_lst.append(p) # 进程追加到列表中
p.start() # 启动进程
for p in p_lst: p.join() # 等待100个进程全部结束
print(dic) # 打印dic的值
重复执行5次,输出
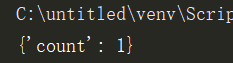
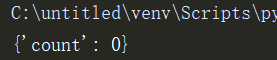
发现每次结果不一致,数据已经出现错乱了,为什么呢?因为同一个时间内有多个进程操作dic,就会发生数据错乱。
为了解决这个问题,需要加锁
from multiprocessing import Manager, Process, Lock def func(dic, lock):
lock.acquire() # 取得锁
dic['count'] = dic['count'] - 1 # 每次减1
lock.release() # 释放锁 if __name__ == '__main__':
m = Manager() # 创建一个server进程
lock = Lock() # 创建锁
dic = m.dict({'count': 100}) # 这是一个特殊的字典
p_lst = [] # 定义一个空列表
for i in range(100): # 启动100个进程
p = Process(target=func, args=(dic, lock))
p_lst.append(p) # 进程追加到列表中
p.start() # 启动进程
for p in p_lst: p.join() # 等待100个进程全部结束
print(dic) # 打印dic的值
重复执行5次,输出结果为:

另外一种写法,使用上下文管理
from multiprocessing import Manager, Process, Lock def func(dic, lock):
with lock: # 上下文管理:必须有一个开始动作和一个结束动作的时候
dic['count'] = dic['count'] - 1 # 每次减1 if __name__ == '__main__':
m = Manager() # 创建一个server进程
lock = Lock() # 创建锁
dic = m.dict({'count': 100}) # 这是一个特殊的字典
p_lst = [] # 定义一个空列表
for i in range(100): # 启动100个进程
p = Process(target=func, args=(dic, lock))
p_lst.append(p) # 进程追加到列表中
p.start() # 启动进程
for p in p_lst: p.join() # 等待100个进程全部结束
print(dic) # 打印dic的值
重复执行,效果同上。
之前学到的文件管理,有用到上下文管理。这里也可以使用上下文管理。有2个必要条件
1. 提供了with方法。
2. 必须有一个开始和结束动作。
这里的开始和结束动作,分别指的是acquire和release
同一台机器上 : 使用Queue
在不同台机器上 :使用消息中间件
进程池和multiprocess.Pool模块
进程池
为什么要有进程池?进程池的概念。
在程序实际处理问题过程中,忙时会有成千上万的任务需要被执行,闲时可能只有零星任务。那么在成千上万个任务需要被执行的时候,我们就需要去创建成千上万个进程么?首先,创建进程需要消耗时间,销毁进程也需要消耗时间。第二即便开启了成千上万的进程,操作系统也不能让他们同时执行,这样反而会影响程序的效率。因此我们不能无限制的根据任务开启或者结束进程。那么我们要怎么做呢?
在这里,要给大家介绍一个进程池的概念,定义一个池子,在里面放上固定数量的进程,有需求来了,就拿一个池中的进程来处理任务,等到处理完毕,进程并不关闭,而是将进程再放回进程池中继续等待任务。如果有很多任务需要执行,池中的进程数量不够,任务就要等待之前的进程执行任务完毕归来,拿到空闲进程才能继续执行。也就是说,池中进程的数量是固定的,那么同一时间最多有固定数量的进程在运行。这样不会增加操作系统的调度难度,还节省了开闭进程的时间,也一定程度上能够实现并发效果。
multiprocess.Pool模块
概念介绍
Pool([numprocess [,initializer [, initargs]]]):创建进程池
进程池,是很重要的知识点
1 numprocess:要创建的进程数,如果省略,将默认使用cpu_count()的值
2 initializer:是每个工作进程启动时要执行的可调用对象,默认为None
3 initargs:是要传给initializer的参数组
参数介绍
p.apply(func [, args [, kwargs]]):在一个池工作进程中执行func(*args,**kwargs),然后返回结果。
'''需要强调的是:此操作并不会在所有池工作进程中并执行func函数。如果要通过不同参数并发地执行func函数,必须从不同线程调用p.apply()函数或者使用p.apply_async()''' p.apply_async(func [, args [, kwargs]]):在一个池工作进程中执行func(*args,**kwargs),然后返回结果。
'''此方法的结果是AsyncResult类的实例,callback是可调用对象,接收输入参数。当func的结果变为可用时,将理解传递给callback。callback禁止执行任何阻塞操作,否则将接收其他异步操作中的结果。''' p.close():关闭进程池,防止进一步操作。如果所有操作持续挂起,它们将在工作进程终止前完成 P.jion():等待所有工作进程退出。此方法只能在close()或teminate()之后调用
主要方法
方法apply_async()和map_async()的返回值是AsyncResul的实例obj。实例具有以下方法
obj.get():返回结果,如果有必要则等待结果到达。timeout是可选的。如果在指定时间内还没有到达,将引发一场。如果远程操作中引发了异常,它将在调用此方法时再次被引发。
obj.ready():如果调用完成,返回True
obj.successful():如果调用完成且没有引发异常,返回True,如果在结果就绪之前调用此方法,引发异常
obj.wait([timeout]):等待结果变为可用。
obj.terminate():立即终止所有工作进程,同时不执行任何清理或结束任何挂起工作。如果p被垃圾回收,将自动调用此函数
其他方法(了解)
代码实例
import time
from multiprocessing import Pool def fc(i):
time.sleep(0.5)
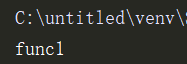
print('func%s' % i) if __name__ == '__main__':
p = Pool(5)
p.apply(func=fc, args=(1,))
执行输出:
import time
from multiprocessing import Pool def fc(i):
time.sleep(0.5)
print('func%s' % i) if __name__ == '__main__':
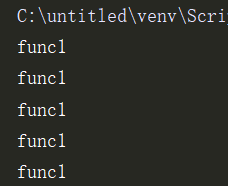
p = Pool(5)
for i in range(5):
p.apply(func=fc, args=(1,)) # 同步调用
# p.apply_async(func=fc,args=(1,)) # 异步调用
执行输出:
import time
import random
from multiprocessing import Pool def fc(i):
print('func%s' % i)
time.sleep(random.randint(1, 3))
return i ** 2 if __name__ == '__main__':
p = Pool(5) # 创建拥有5个进程数量的进程池
ret_l = []
for i in range(5):
# p.apply(func=fc,args=(1,)) # 同步调用
ret = p.apply_async(func=fc, args=(i,)) # 异步调用
ret_l.append(ret)
for ret in ret_l: print(ret.get()) # 打印返回结果
执行输出:
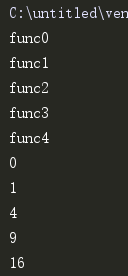
后面的结果都是平方的值
import os,time
from multiprocessing import Pool def work(n):
print('%s run' %os.getpid())
time.sleep(3)
return n**2 if __name__ == '__main__':
p=Pool(3) #进程池中从无到有创建三个进程,以后一直是这三个进程在执行任务
res_l=[]
for i in range(10):
res=p.apply(work,args=(i,)) # 同步调用,直到本次任务执行完毕拿到res,等待任务work执行的过程中可能有阻塞也可能没有阻塞
# 但不管该任务是否存在阻塞,同步调用都会在原地等着
print(res_l)
进程池的同步调用
import os
import time
import random
from multiprocessing import Pool def work(n):
print('%s run' %os.getpid())
time.sleep(random.random())
return n**2 if __name__ == '__main__':
p=Pool(3) #进程池中从无到有创建三个进程,以后一直是这三个进程在执行任务
res_l=[]
for i in range(10):
res=p.apply_async(work,args=(i,)) # 异步运行,根据进程池中有的进程数,每次最多3个子进程在异步执行
# 返回结果之后,将结果放入列表,归还进程,之后再执行新的任务
# 需要注意的是,进程池中的三个进程不会同时开启或者同时结束
# 而是执行完一个就释放一个进程,这个进程就去接收新的任务。
res_l.append(res) # 异步apply_async用法:如果使用异步提交的任务,主进程需要使用jion,等待进程池内任务都处理完,然后可以用get收集结果
# 否则,主进程结束,进程池可能还没来得及执行,也就跟着一起结束了
p.close()
p.join()
for res in res_l:
print(res.get()) #使用get来获取apply_aync的结果,如果是apply,则没有get方法,因为apply是同步执行,立刻获取结果,也根本无需get
进程池的异步调用
练习
# Pool内的进程数默认是cpu核数,假设为4(查看方法os.cup_count())
# 开启6个客户端,会发现2个客户端处于等待状态
# 在每个进程内查看pid,会发现pid使用为4个,即多个客户端供用4个进程
from socket import *
from multiprocessing import Pool
import os server = socket(AF_INET, SOCK_STREAM)
server.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
server.bind(('127.0.0.1', 8080))
server.listen(5) def talk(conn):
print('进程pid:%s' % os.getpid())
while True:
try:
msg = conn.recv(1024)
if not msg: break
conn.send(msg.upper())
except Exception:
break if __name__ == '__main__':
p = Pool(4)
while True:
conn, *_ = server.accept()
p.apply_async(talk, args=(conn,))
# p.apply(talk,args=(conn,client_addr)) # 同步的话,则同一时间只有一个客户端能访问
server:进程池版socket并发聊天
from socket import * client = socket(AF_INET, SOCK_STREAM)
client.connect(('127.0.0.1', 8080))
while True:
msg = input('>>>').strip()
if not msg: continue
client.send(msg.encode('utf-8'))
msg = client.recv(1024)
print(msg.decode('utf-8'))
client
发现:并发开启多个客户端,服务端同一时间只有4个不同的pid,只能结束一个客户端,另外一个客户端才会进来。
信号量和进程池的区别:
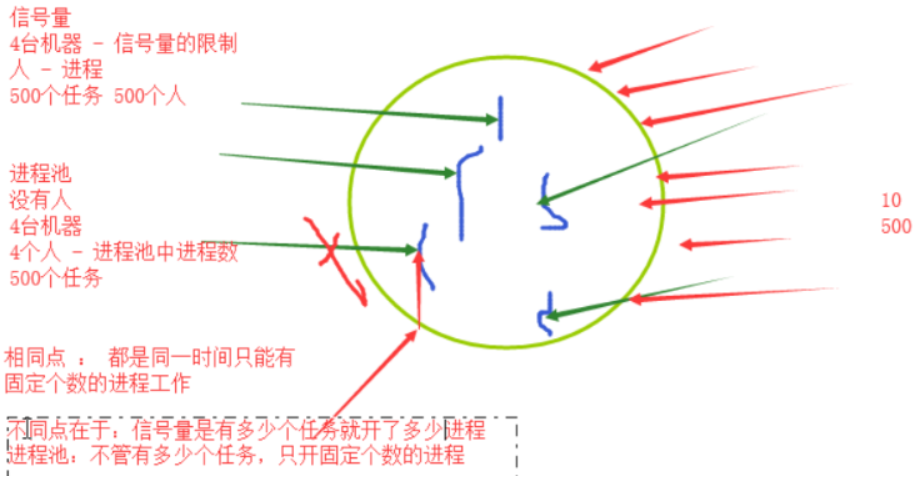
回调函数
需要回调函数的场景:进程池中任何一个任务一旦处理完了,就立即告知主进程:我好了额,你可以处理我的结果了。主进程则调用一个函数去处理该结果,该函数即回调函数 我们可以把耗时间(阻塞)的任务放到进程池中,然后指定回调函数(主进程负责执行),这样主进程在执行回调函数时就省去了I/O的过程,直接拿到的是任务的结果。
进程池的数量一般为CPU的个数加1
简单爬虫例子:
import os
from urllib.request import urlopen
from multiprocessing import Pool def get_url(url):
print('-->',url,os.getpid(),'get_url进程')
ret = urlopen(url) # 打开url
content = ret.read() # 读取网页内容
return content def call(url): # 回调函数
#分析
print(url,os.getpid(),'回调函数') if __name__ == '__main__':
print(os.getpid(),'主进程') # 主进程id
l = [
'http://www.baidu.com',
'http://www.sina.com',
'http://www.sohu.com',
'http://www.sogou.com',
'http://www.qq.com',
'http://www.bilibili.com',
]
p = Pool(5)
ret_l = []
for url in l:
ret = p.apply_async(func=get_url,args=[url,],callback=call) # 异步
ret_l.append(ret) # 将进程追加到列表中
for ret in ret_l:ret.get() # 获取进程返回值
执行输出:
/www.sohu.com/a/231538578_115362" target="_blank"
...
输出了一堆内容,但是get_url函数并没有print,那么由谁输出的呢?
是由call打印的
回调函数
在进程池中,起了一个任务,这个任务对应的函数在执行完毕之后
的返回值会自动作为参数返回给回调函数
回调函数就根据返回值再进行相应的处理
回调函数 是在主进程执行的
看下图
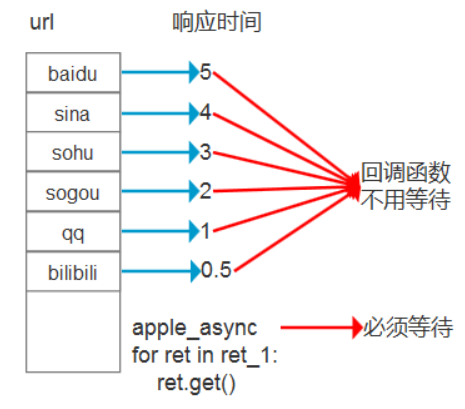
有6个url,每一个url的响应时间是不一样的。假设第一个url访问很慢,那么必须等待任务结束,才能执行分析函数。如果使用回调函数,谁最快范围,优先执行回调函数。那么最慢的url,最后执行。
这样效率就提升了很多。
回调函数是瞬间执行的,网络延时才是最耗最长的。
回调函数是主 进程执行的,不是子进程执行的。
怎么证明呢?修改get_url的return值
import os
from urllib.request import urlopen
from multiprocessing import Pool def get_url(url):
print('-->',url,os.getpid(),'get_url进程')
ret = urlopen(url) # 打开url
content = ret.read() # 读取网页内容
return url def call(url): # 回调函数
#分析
print(url,os.getpid(),'回调函数') if __name__ == '__main__':
print(os.getpid(),'主进程') # 主进程id
l = [
'http://www.baidu.com',
'http://www.sina.com',
'http://www.sohu.com',
'http://www.sogou.com',
'http://www.qq.com',
'http://www.bilibili.com',
]
p = Pool(5)
ret_l = []
for url in l:
ret = p.apply_async(func=get_url,args=[url,],callback=call) # 异步
ret_l.append(ret) # 将进程追加到列表中
for ret in ret_l:ret.get() # 获取进程返回值
执行输出:
13764 主进程
--> http://www.baidu.com 14820 get_url进程
--> http://www.sina.com 12144 get_url进程
--> http://www.sohu.com 10868 get_url进程
--> http://www.sogou.com 4072 get_url进程
--> http://www.qq.com 3924 get_url进程
--> http://www.bilibili.com 14820 get_url进程
http://www.baidu.com 13764 回调函数
http://www.qq.com 13764 回调函数
http://www.sohu.com 13764 回调函数
http://www.sogou.com 13764 回调函数
http://www.bilibili.com 13764 回调函数
http://www.sina.com 13764 回调函数
执行回调函数的进程id都是13764,这个进程正好是主进程。
from multiprocessing import Pool
import requests
import json
import os def get_page(url):
print('<进程%s> get %s' %(os.getpid(),url))
respone=requests.get(url)
if respone.status_code == 200:
return {'url':url,'text':respone.text} def pasrse_page(res):
print('<进程%s> parse %s' %(os.getpid(),res['url']))
parse_res='url:<%s> size:[%s]\n' %(res['url'],len(res['text']))
with open('db.txt','a') as f:
f.write(parse_res) if __name__ == '__main__':
urls=[
'https://www.baidu.com',
'https://www.python.org',
'https://www.openstack.org',
'https://help.github.com/',
'http://www.sina.com.cn/'
] p=Pool(3)
res_l=[]
for url in urls:
res=p.apply_async(get_page,args=(url,),callback=pasrse_page)
res_l.append(res) p.close()
p.join()
print([res.get() for res in res_l]) #拿到的是get_page的结果,其实完全没必要拿该结果,该结果已经传给回调函数处理了 '''
打印结果:
<进程3388> get https://www.baidu.com
<进程3389> get https://www.python.org
<进程3390> get https://www.openstack.org
<进程3388> get https://help.github.com/
<进程3387> parse https://www.baidu.com
<进程3389> get http://www.sina.com.cn/
<进程3387> parse https://www.python.org
<进程3387> parse https://help.github.com/
<进程3387> parse http://www.sina.com.cn/
<进程3387> parse https://www.openstack.org
[{'url': 'https://www.baidu.com', 'text': '<!DOCTYPE html>\r\n...',...}]
'''
使用多进程请求多个url来减少网络等待浪费的时间
import re
from urllib.request import urlopen
from multiprocessing import Pool def get_page(url,pattern):
response=urlopen(url).read().decode('utf-8')
return pattern,response def parse_page(info):
pattern,page_content=info
res=re.findall(pattern,page_content)
for item in res:
dic={
'index':item[0].strip(),
'title':item[1].strip(),
'actor':item[2].strip(),
'time':item[3].strip(),
}
print(dic)
if __name__ == '__main__':
regex = r'<dd>.*?<.*?class="board-index.*?>(\d+)</i>.*?title="(.*?)".*?class="movie-item-info".*?<p class="star">(.*?)</p>.*?<p class="releasetime">(.*?)</p>'
pattern1=re.compile(regex,re.S) url_dic={
'http://maoyan.com/board/7':pattern1,
} p=Pool()
res_l=[]
for url,pattern in url_dic.items():
res=p.apply_async(get_page,args=(url,pattern),callback=parse_page)
res_l.append(res) for i in res_l:
i.get()
爬虫实例
如果在主进程中等待进程池中所有任务都执行完毕后,再统一处理结果,则无需回调函数
参考资料
http://www.cnblogs.com/linhaifeng/articles/6817679.html
https://www.jianshu.com/p/1200fd49b583
https://www.jianshu.com/p/aed6067eeac
明日默写:
import time
import random
from multiprocessing import Process, Queue def consumer(q, name):
while True:
food = q.get()
if food == 'done': break
time.sleep(random.random())
print('{}吃了{}'.format(name, food)) def producer(q, name, food):
for i in range(10):
time.sleep(random.random())
print('{}生产了{}{}'.format(name, food, i))
q.put('{}{}'.format(food, i)) if __name__ == '__main__':
q = Queue()
p1 = Process(target=producer, args=(q, 'Egon', '泔水'))
p2 = Process(target=producer, args=(q, 'Yuan', '骨头鱼刺'))
p1.start()
p2.start()
Process(target=consumer, args=(q, 'alex')).start()
Process(target=consumer, args=(q, 'wusir')).start()
p1.join()
p2.join()
q.put('done')
q.put('done')
python全栈开发,Day40(进程间通信(队列和管道),进程间的数据共享Manager,进程池Pool)的更多相关文章
- python 全栈开发,Day40(进程间通信(队列和管道),进程间的数据共享Manager,进程池Pool)
昨日内容回顾 进程 multiprocess Process —— 进程 在python中创建一个进程的模块 start daemon 守护进程 join 等待子进程执行结束 锁 Lock acqui ...
- Python全栈开发【面向对象进阶】
Python全栈开发[面向对象进阶] 本节内容: isinstance(obj,cls)和issubclass(sub,super) 反射 __setattr__,__delattr__,__geta ...
- Python全栈开发【面向对象】
Python全栈开发[面向对象] 本节内容: 三大编程范式 面向对象设计与面向对象编程 类和对象 静态属性.类方法.静态方法 类组合 继承 多态 封装 三大编程范式 三大编程范式: 1.面向过程编程 ...
- Python全栈开发【模块】
Python全栈开发[模块] 本节内容: 模块介绍 time random os sys json & picle shelve XML hashlib ConfigParser loggin ...
- Python全栈开发【基础四】
Python全栈开发[基础四] 本节内容: 匿名函数(lambda) 函数式编程(map,filter,reduce) 文件处理 迭代器 三元表达式 列表解析与生成器表达式 生成器 匿名函数 lamb ...
- Python全栈开发【基础三】
Python全栈开发[基础三] 本节内容: 函数(全局与局部变量) 递归 内置函数 函数 一.定义和使用 函数最重要的是减少代码的重用性和增强代码可读性 def 函数名(参数): ... 函数体 . ...
- Python全栈开发【基础二】
Python全栈开发[基础二] 本节内容: Python 运算符(算术运算.比较运算.赋值运算.逻辑运算.成员运算) 基本数据类型(数字.布尔值.字符串.列表.元组.字典) 其他(编码,range,f ...
- Python全栈开发【基础一】
Python全栈开发[第一篇] 本节内容: Python 的种类 Python 的环境 Python 入门(解释器.编码.变量.input输入.if流程控制与缩进.while循环) if流程控制与wh ...
- python 全栈开发之路 day1
python 全栈开发之路 day1 本节内容 计算机发展介绍 计算机硬件组成 计算机基本原理 计算机 计算机(computer)俗称电脑,是一种用于高速计算的电子计算机器,可以进行数值计算,又可 ...
随机推荐
- SpringBoot 集成mongodb(1)单数据源配置
新项目要用到mongodb,于是在个人电脑上的虚拟环境linux上安装了下mongodb,练习熟悉下. 1.虚拟机上启动mongodb. 首先查看虚拟机ip地址,忘了哈~~ 命令行>ifconf ...
- java poi 导入导出Excel xsl xslx
import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.IOException; import ...
- 《图解设计模式》读书笔记8-2 MEMENTO模式
目录 Memento模式 示例代码 程序类图 代码 角色和类图 模式类图 角色 思路拓展 接口可见性 保存多少个Memento 划分Caretaker和Originator的意义 Memento模式 ...
- 《深入浅出WPF》学习总结之XAML标签语言一
一.XMAL概览 1.XAML在桌面开发及富媒体网络程序的开发中扮演了HTML+CSS+JS的角色. 2.XAML可以将UI和逻辑代码分离,降低耦合度. 3.XAML是一种单纯的申明形语言 4.XAM ...
- STL 配接器(adapters)
定义 配接器(adapters):将一个class的接口,转换为另一个class的接口,使得原来不能一起使用相互兼容的classes,可以一起协同工作. 配接器是一种设计模式. STL中提供的各种配接 ...
- java面向对象基础总结
本周学习了java面向对象的一些基本概念,介绍了它三个主要特性,封装性.继承性.多态性,类与对象的关系,栈堆的关系,三个特性中主要讲了封装性,其他两个后面再讲. 类实际上是表示一个客观世界某类群体的一 ...
- MySQL练习与小结
当你专注一件事的时候,时间总是过得很快! foreign key 练习 -- 切换数据库 use stumgr -- 删除班级表 drop table t_class1 -- 创建一个班级表 crea ...
- accept()出的socket不会使用新的端口号
1 标识一个socket的是四元组,不只是端口号 client ip : client port : server ip : server port 2 accept出的新的socket仍然使用和li ...
- [BZOJ 2820] YY的gcd(莫比乌斯反演+数论分块)
[BZOJ 2820] YY的gcd(莫比乌斯反演+数论分块) 题面 给定N, M,求\(1\leq x\leq N, 1\leq y\leq M\)且gcd(x, y)为质数的(x, y)有多少对. ...
- [常用类]时间内Date、SimpleDateFormat、Calendar类
Date类的概述是util包下的,不能导入sql包的.* 类 Date 表示特定的瞬间,精确到毫秒. *构造方法 * public Date() * public Date(long date) 如果 ...