Selenium+PhantomJs 爬取网页内容
利用Selenium和PhantomJs 可以模拟用户操作,爬取大多数的网站。下面以新浪财经为例,我们抓取新浪财经的新闻版块内容。
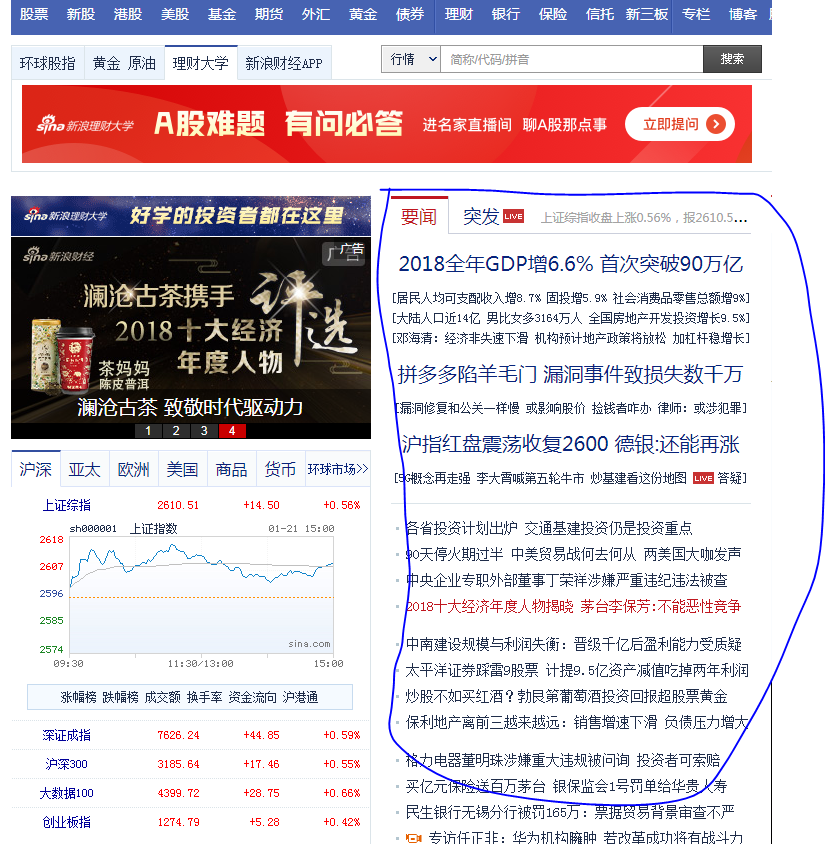
1.依赖的jar包。我的项目是普通的SSM单间的WEB工程。最后一个jar包是用来在抓取到网页dom后做网页内容解析的。
<!-- https://mvnrepository.com/artifact/org.seleniumhq.selenium/selenium-java -->
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>3.2.0</version>
</dependency> <dependency>
<groupId>javax</groupId>
<artifactId>javaee-web-api</artifactId>
<version>7.0</version>
<scope>provided</scope>
</dependency> <!-- https://mvnrepository.com/artifact/com.google.guava/guava -->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>20.0</version>
</dependency> <dependency>
<groupId>cn.wanghaomiao</groupId>
<artifactId>JsoupXpath</artifactId>
<version>2.2</version>
</dependency>
2.获取网页dom内容
package com.nsjr.grab.util; import java.util.List;
import java.util.concurrent.TimeUnit; import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.openqa.selenium.phantomjs.PhantomJSDriver;
import org.openqa.selenium.phantomjs.PhantomJSDriverService;
import org.openqa.selenium.remote.DesiredCapabilities; import cn.wanghaomiao.xpath.model.JXDocument; @SuppressWarnings("deprecation")
public class SeleniumUtil { public static JXDocument getDocument(String driverUrl,String pageUrl){
JXDocument jxDocument = null;
PhantomJSDriver driver = null;
try{
System.setProperty("phantomjs.binary.path", driverUrl);
System.setProperty("webdriver.chrome.driver", driverUrl); DesiredCapabilities dcaps = new DesiredCapabilities();
//ssl证书支持
dcaps.setCapability("acceptSslCerts", true);
//截屏支持
dcaps.setCapability("takesScreenshot", true);
//css搜索支持
dcaps.setCapability("cssSelectorsEnabled", true);
//js支持
dcaps.setJavascriptEnabled(true);
//驱动支持
dcaps.setCapability(PhantomJSDriverService.PHANTOMJS_EXECUTABLE_PATH_PROPERTY,driverUrl);
//创建无界面浏览器对象
driver = new PhantomJSDriver(dcaps);
//WebDriver driver = new ChromeDriver(dcaps);
driver.get(pageUrl);
driver.manage().timeouts().implicitlyWait(5, TimeUnit.SECONDS);
Document document = Jsoup.parse(driver.getPageSource());
jxDocument = new JXDocument(document);
}catch(Exception e){
e.printStackTrace();
}finally{
if(driver != null){
driver.quit();
}
}
return jxDocument;
} public static String getProperty(List<Object> list){
if(list.isEmpty()){
return "";
}else{
return list.get(0).toString();
}
}
}
3.解析并保存内容
JXDocument jxDocument = SeleniumUtil.getDocument(captureUrl.getDriverUrl(), captureUrl.getSinaNews());
//保存第一部分加粗新闻
List<Object> listh3 = jxDocument.sel("//div[@id='impNews1']/div[@id='fin_tabs0_c0']/div[@id='blk_hdline_01']/h3/a");
for(Object a :listh3){
JXDocument doc = new JXDocument(a.toString());
//System.out.println("地址:"+doc.sel("//a/@href"));
//System.out.println("标题:"+doc.sel("//text()"));
saveNews(SeleniumUtil.getProperty(doc.sel("//text()")), SeleniumUtil.getProperty(doc.sel("//a/@href")), Constant.NEWS_TYPE_BOTTOM, Constant.NEWS_SOURCE_SINA);
}
//保存其余新闻
List<Object> listP = jxDocument.sel("//div[@id='impNews1']/div[@id='fin_tabs0_c0']/div[@id='blk_hdline_01']/p/a");
for(Object a :listP){
JXDocument doc = new JXDocument(a.toString());
//System.out.println("地址:"+doc.sel("//a/@href"));
//System.out.println("标题:"+doc.sel("//text()"));
saveNews(SeleniumUtil.getProperty(doc.sel("//text()")), SeleniumUtil.getProperty(doc.sel("//a/@href")), Constant.NEWS_TYPE_BOTTOM, Constant.NEWS_SOURCE_SINA);
}
//保存第二部分新闻
List<Object> listpart2 = jxDocument.sel("//div[@id='impNews1']/div[@id='fin_tabs0_c0']/div[2]/ul");
for(Object a :listpart2){
JXDocument doc = new JXDocument(a.toString());
List<Object> alist = doc.sel("//li/a");
for(Object a2 :alist){
JXDocument doc2 = new JXDocument(a2.toString());
//System.out.println("地址:"+doc2.sel("//a/@href"));
//System.out.println("标题:"+doc2.sel("//text()"));
saveNews(
SeleniumUtil.getProperty(doc2.sel("//text()")),
SeleniumUtil.getProperty(doc2.sel("//a/@href")),
Constant.NEWS_TYPE_BOTTOM,
Constant.NEWS_SOURCE_SINA
);
}
}
4.解释
captureUrl.getDriverUrl(), captureUrl.getSinaNews() 这两个地址分别是PhantomJs工具的地址和要爬取的网站的地址,其中
sina_news = https://finance.sina.com.cn/
driverUrl= D:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe
关于PhantomJs 工具的下载可以直接去官网下载 http://phantomjs.org/download.html,有windows 和Linux版供下载。关于网页结构的解析使用JsoupXpath ,是一个国人写的html文档解析工具包,挺好用的。语法可以参考Xpath的相关语法进行节点的选取。
5.爬取结果。由于项目需求较为简单,对实时性和性能要求不高,所以只做到入库,即可满足需求。
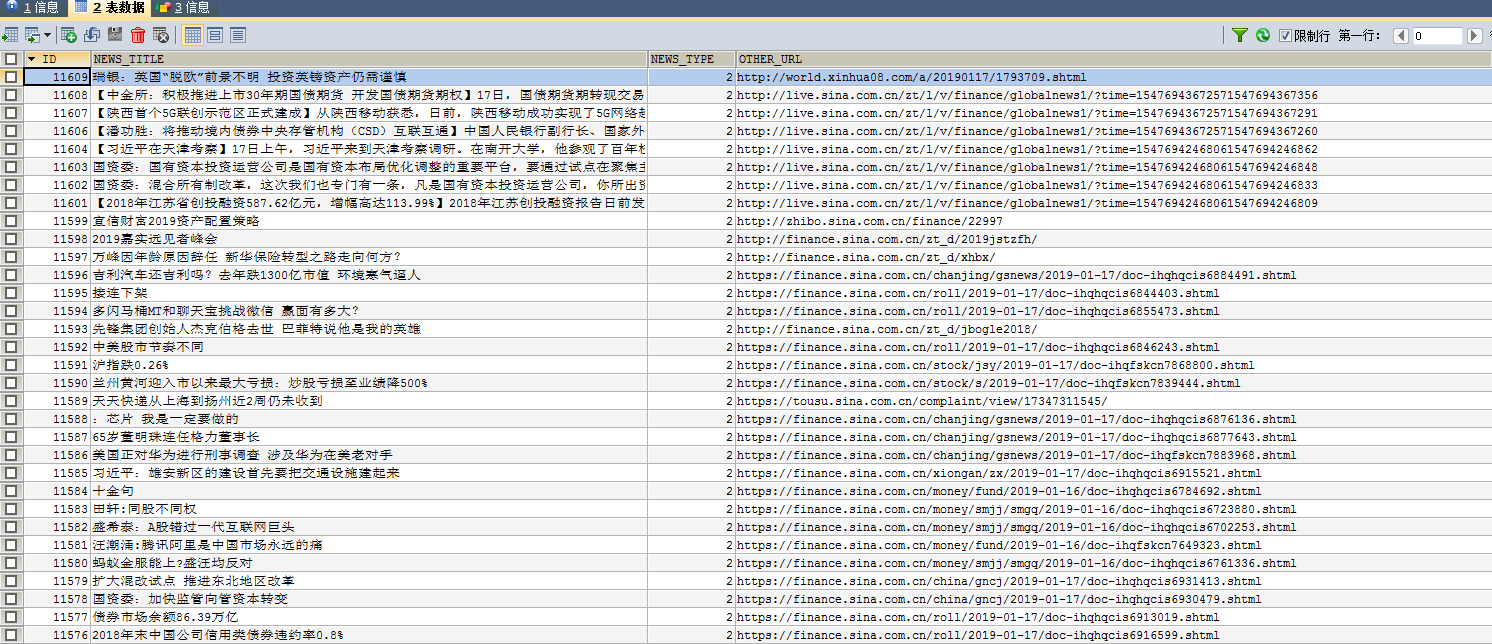
最后,刚开始接触爬虫类的东西,有的需求webmagic 可以满足,有的需要其他方式,需要具体问题具体分析。尚在摸索阶段,本文仅仅是提供一种解决思路。
Selenium+PhantomJs 爬取网页内容的更多相关文章
- Python3.x:Selenium+PhantomJS爬取带Ajax、Js的网页
Python3.x:Selenium+PhantomJS爬取带Ajax.Js的网页 前言 现在很多网站的都大量使用JavaScript,或者使用了Ajax技术.这样在网页加载完成后,url虽然不改变但 ...
- selenium+phantomjs爬取京东商品信息
selenium+phantomjs爬取京东商品信息 今天自己实战写了个爬取京东商品信息,和上一篇的思路一样,附上链接:https://www.cnblogs.com/cany/p/10897618. ...
- selenium+phantomjs爬取bilibili
selenium+phantomjs爬取bilibili 首先我们要下载phantomjs 你可以到 http://phantomjs.org/download.html 这里去下载 下载完之后解压到 ...
- python+selenium+PhantomJS爬取网页动态加载内容
一般我们使用python的第三方库requests及框架scrapy来爬取网上的资源,但是设计javascript渲染的页面却不能抓取,此时,我们使用web自动化测试化工具Selenium+无界面浏览 ...
- selenium + PhantomJS 爬取js页面
from selenium import webdriver import time _url="http://xxxxxxxx.com" driver = webdriver.P ...
- selenium + phantomjs 爬取落网音乐
题记: 作为一个业余程序猿,最大的爱好就是电影和音乐了,听音乐当然要来点有档次的.落网的音乐的逼格有点高,一听听了10年.学习python一久了,于是想用python技术把落网的音乐爬下来随便听. 目 ...
- Python3.x:Selenium+PhantomJS爬取带Ajax、Js的网页及获取JS返回值
前言 现在很多网站的都大量使用JavaScript,或者使用了Ajax技术.这样在网页加载完成后,url虽然不改变但是网页的DOM元素内容却可以动态的变化.如果处理这种网页是还用requests库或者 ...
- 看我怎么扒掉CSDN首页的底裤(python selenium+phantomjs爬取CSDN首页内容)
这里只是学习一下动态加载页面内容的抓取,并不适用于所有的页面. 使用到的工具就是python selenium和phantomjs,另外调试的时候还用了firefox的geckodriver.exe. ...
- selenium+phantomjs爬取动态页面数据
1.安装selenium pip/pip3 install selenium 注意依赖关系 2.phantomjs for windows 下载地址:http://phantomjs.org/down ...
随机推荐
- [Linux系统] (1)常用操作(CentOS 7.x)
一.Linux系统配置 1.修改主机名 [/etc/hostname] vi /etc/hostname 在其中将旧名字修改为新主机名,保存,重启生效. 2.本地DNS映射 [/etc/hosts] ...
- <image>的src属性的使用
刚接触前端不久.怎么用image显示图片是个问题,怎么使用数据流还是base64呢?小小的研究一下 <image src="url"> 1.接口返回数据流,src可以直 ...
- EasyPrtSc sec[1.2] 发布!
//HOMETAG #include<bits/stdc++.h> namespace EasilyPrtSc{ //this namespace is for you to be mor ...
- 如何将项目托管到Github上
将本地项目放到GitHub上托管并展示 传送门 利用Github Pages展示自己的项目 传送门 git Please tell me who you are解决方法 传送门 git config ...
- 深入理解Vuex 模块化(module)
todo https://www.jb51.net/article/124618.htm
- uswgi
1.安装uwsgi注意: 1)在系统环境安装,非虚拟环境 2)使用对应python版本安装 3)要先安装python开发包 ###sudo apt-get install python3.6-dev ...
- mongo 生命周期
监听MongoDB的生命周期,只需重写org.springframework.data.mongodb.core.mapping.event.AbstractMongoEventListener的子类 ...
- oj.1677矩形嵌套,动态规划 ,贪心
#include<iostream> #include<algorithm> #include<cstring> using namespace std; stru ...
- JavaScript 函数相关属性
1.name 既函数名 function test(){ console.log("Haha") }; console.log(test.name)//test 2.length属 ...
- LeetCode 56. 合并区间(Merge Intervals)
题目描述 给出一个区间的集合,请合并所有重叠的区间. 示例 1: 输入: [[1,3],[2,6],[8,10],[15,18]] 输出: [[1,6],[8,10],[15,18]] 解释: 区间 ...