java8学习之groupingBy源码分析
继续接着上一次【http://www.cnblogs.com/webor2006/p/8366083.html】来分析Collectors中的各种收集器的实现, 对里它里面有个groupingby()方法,这个之前咱们也已经对它详细使用过,但是!!它的实现是比较复杂的,所以这次来仔细分析一下该方法的实现细节,纵览一下它,存在几个重载方式:

先来从最基础的开始分析,如下:
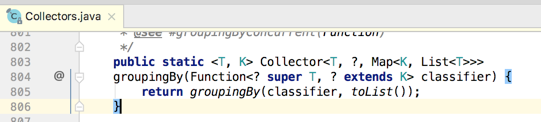
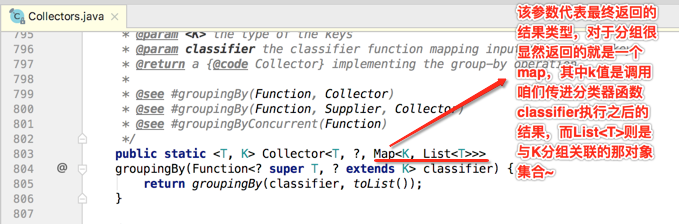
其中先来看一下该方法返回值所携带泛型的含义:

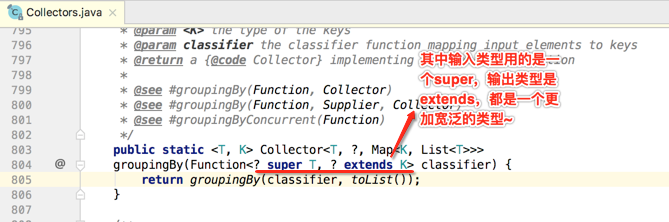
接着看下方法的参数,既提供一个分类器:
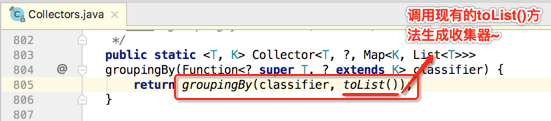
接着方法的实现是调用了另外一个groupingBy():
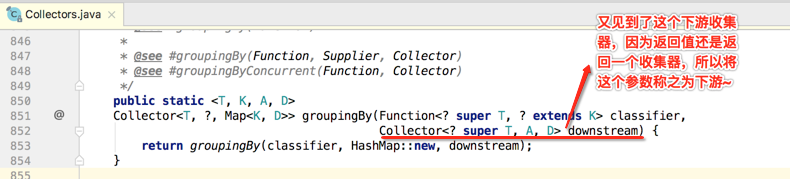
那像这种有下游收集器的方法实现的一个大致思路是怎样的呢?downstream既然已经是一个收集器了,所以就会有收集器的那几个重要的方法,而还有一个分类器参数,其实就是将这个分类器应用到这个下游收集器当中,使得收集器进行了一系列的转换,而最终转换成的收集器则就是方法要返回的收集器啦,所以但凡方法中带有一个收集器然后又返回一个收集器其构造思路都类似。
目前这个groupingBy()有四个泛型了,下面先来对每个泛型有个认知:

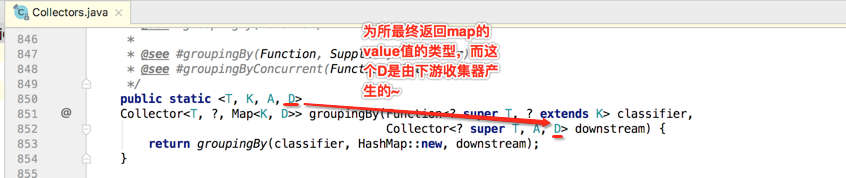
接着再来看这个方法的具体实现,发现又调用了另外一个groupingBy()方法,如下:

而可以看到第二个参数实例化了一个HashMap对象,先不去看它所调用的另外一个重载groupingBy()方法的定义,从这个字面就能知道第二个参数肯定是做为最终的结果容器对象,所以说如果咱们在使用时是使用了第一个最简单的groupingBy()来对数据进行分组,最终返回的肯定是HashMap对象,而如果咱们想自己定义最终返回的类型比如:TreeMap,那这时就得使用最复杂的最后一个groupingBy()方法啦,所以下面将焦点转移到这个最复杂方法上面,先来贴出这个方法的实现先来感受一下其复杂性:
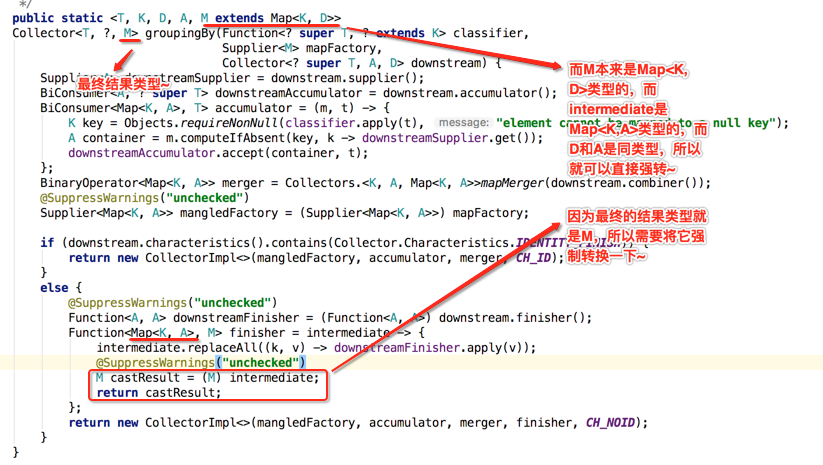
public static <T, K, D, A, M extends Map<K, D>>
Collector<T, ?, M> groupingBy(Function<? super T, ? extends K> classifier,
Supplier<M> mapFactory,
Collector<? super T, A, D> downstream) {
Supplier<A> downstreamSupplier = downstream.supplier();
BiConsumer<A, ? super T> downstreamAccumulator = downstream.accumulator();
BiConsumer<Map<K, A>, T> accumulator = (m, t) -> {
K key = Objects.requireNonNull(classifier.apply(t), "element cannot be mapped to a null key");
A container = m.computeIfAbsent(key, k -> downstreamSupplier.get());
downstreamAccumulator.accept(container, t);
};
BinaryOperator<Map<K, A>> merger = Collectors.<K, A, Map<K, A>>mapMerger(downstream.combiner());
@SuppressWarnings("unchecked")
Supplier<Map<K, A>> mangledFactory = (Supplier<Map<K, A>>) mapFactory; if (downstream.characteristics().contains(Collector.Characteristics.IDENTITY_FINISH)) {
return new CollectorImpl<>(mangledFactory, accumulator, merger, CH_ID);
}
else {
@SuppressWarnings("unchecked")
Function<A, A> downstreamFinisher = (Function<A, A>) downstream.finisher();
Function<Map<K, A>, M> finisher = intermediate -> {
intermediate.replaceAll((k, v) -> downstreamFinisher.apply(v));
@SuppressWarnings("unchecked")
M castResult = (M) intermediate;
return castResult;
};
return new CollectorImpl<>(mangledFactory, accumulator, merger, finisher, CH_NOID);
}
}
艾玛~~先不看实现,看到泛型的定义就立马蒙圈,确实够复杂的,所以接下来准备一行行代码来理解它的具体实现,先来看一下它的参数定义:

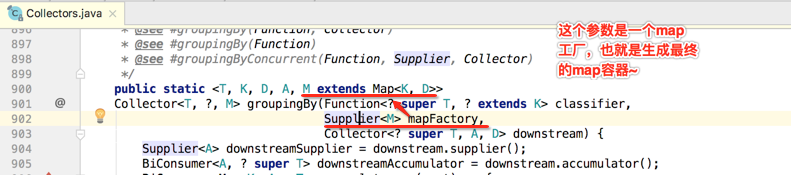
而对于第二个groupingBy()方法在调用这个groupingBy()时,对于这个mapFactory传递的是:


接着简单的看一下它的javadoc:
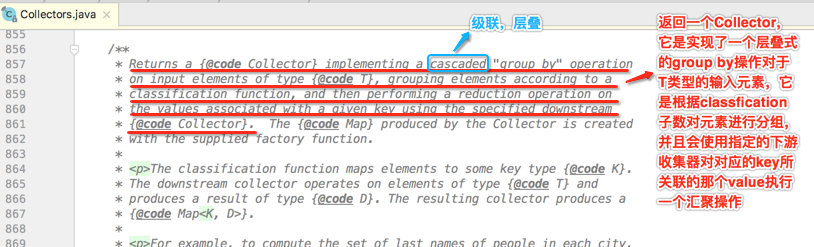
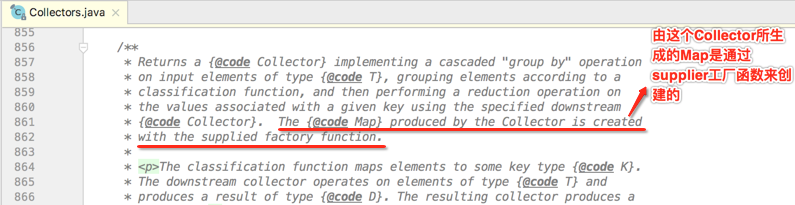
上面这句话说的就是这个参数:



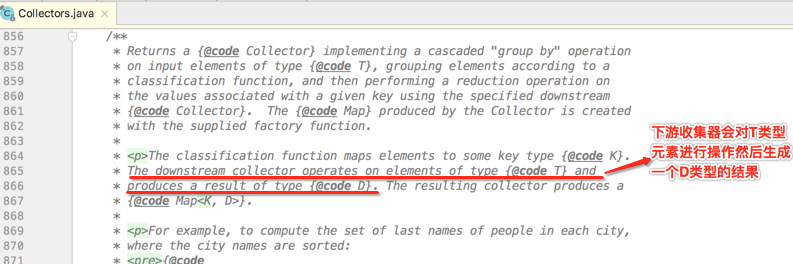

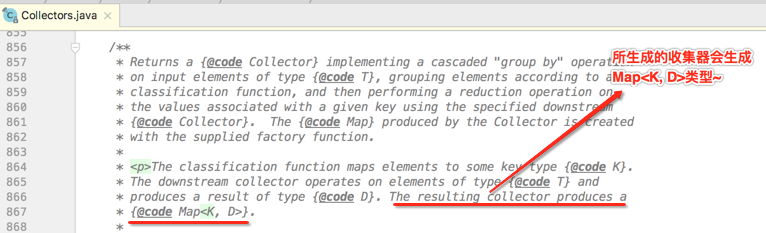
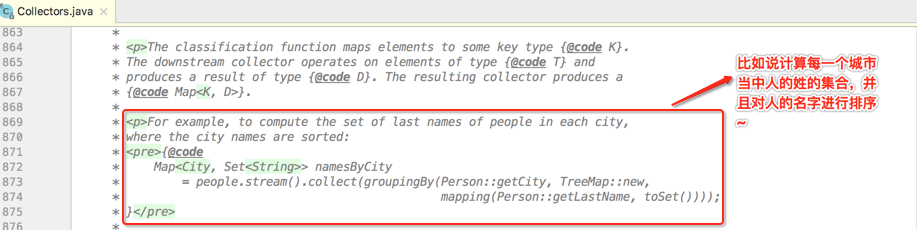
其中可以发现,因为要带排序功能,所以得用TreeMap,所以此时调用的groupingBy就是用的第三个最复杂的,因为自由的来决定最终返回的结果容器。


关于上面提到的groupingByConcurrent()函数也是有几个重载的,如下:

这个并行的分组函数待将groupingBy()函数分析完之后再对它进行分析。
好了,通过阅读javadoc已经对这个函数有了一定的认识,接下来则硬着头皮来分析它的具体实现啦,如下:

那从上游收集器中获取这些对象是干嘛用的呢?其实如开始所说,因为最终要返回一个Collector,所以最终的Collector的新对象是需要依赖于这个下游收集器来生成的,接着继续往下看:
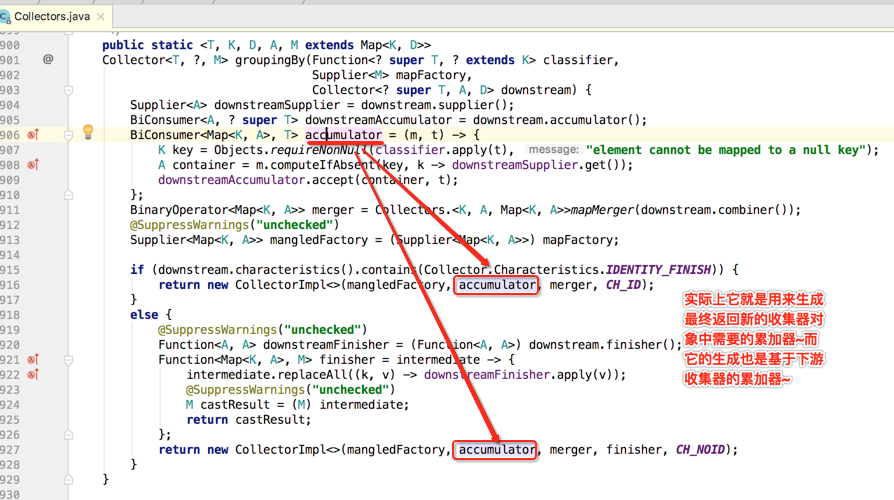
下面具体看一下累加器的构建过程:

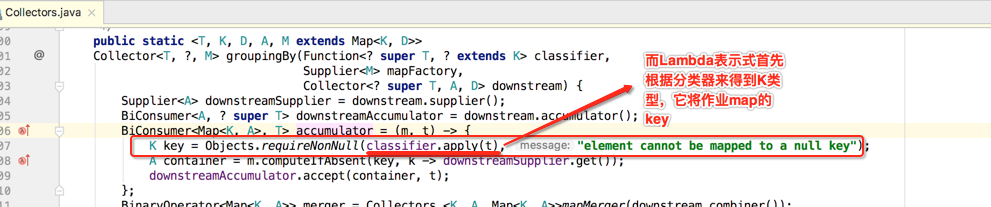
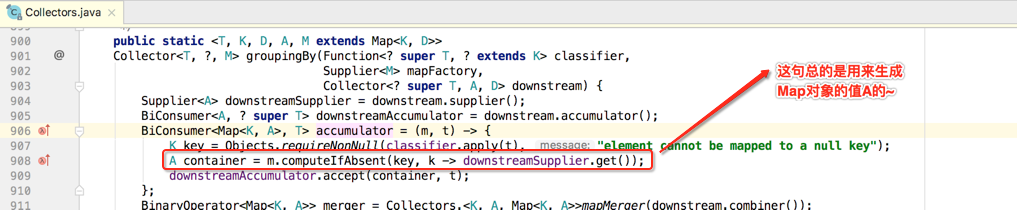
而其中用到卫个新的Map的方法:computeIfAbsent(),这是java1.8推出的,如下:

所以有必要理解一下这个方法是干嘛用的,先看一下它的javadoc:

言外之意就是说:如果值不存在才会进行计算,否则就直接返回了,而计算的值如果不为null,那么就将它放到map当中,那它的具体实现是怎样的呢?
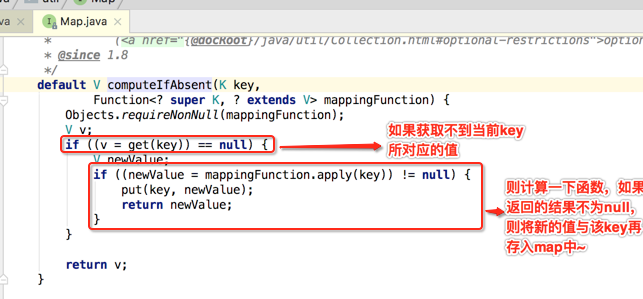
嗯~~该函数理解了,接着再回到咱们所关的groupingBy()的这句代码上来:
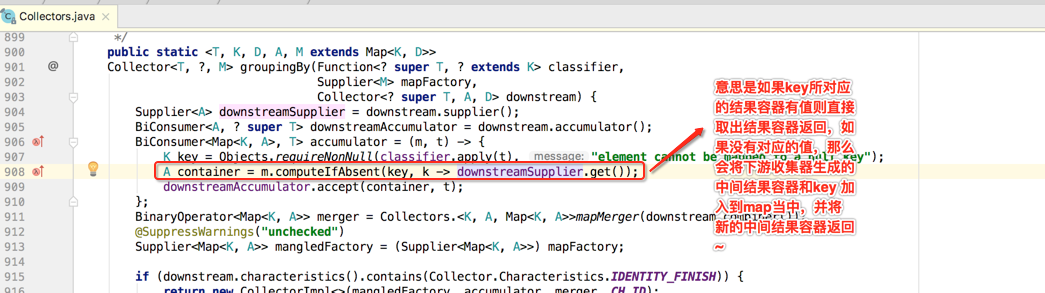


其中使用到了一个mapMerger()的私有方法如下:


这个合并过程就不多说了,不难,重点知道这个函数的作用就是将两个Map进行数据合并,接着再回到主代码流程:
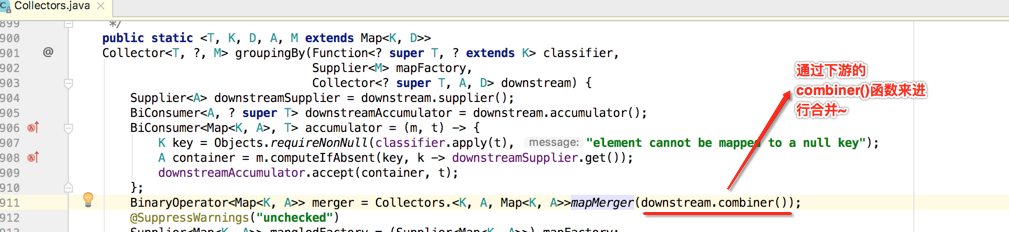
接着就到了一句比较难理解的代码了,如下:



理解这句代码的关键是要以生成一个新的收集器的角度去思考,而不要以groupingBy()传的那个mapFactory角度来理解,如下:
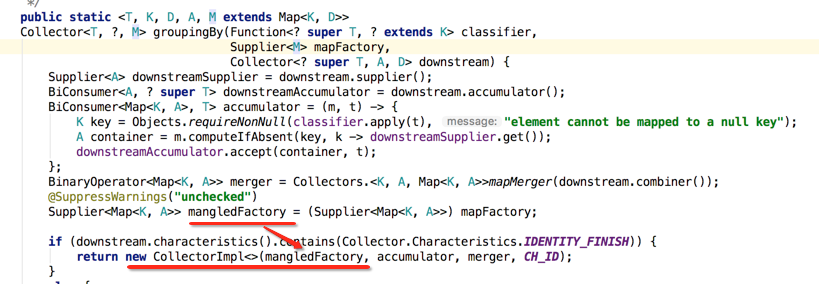
好了,一些新收集器需要的参数都已经准备好了,接下来就是将其实例化之后将其返回,如下:

接着再来看一下else的情况:很显然是下游收集器中不包含有"IDENTITY_FINISH"这个特性,那证明中间结果容器跟最终结果的类型是不一样的,最终肯定需要调用收集器的finisher()方法,所以生成的CollectorImpl是带有finihser的构造,如下:

其中特性也发生了变化,这里传了一个空的特性:

由于其它参数跟if中的一模一样,所以在else中主要是为了生成finisher,那下面看一下生成的具体细节:

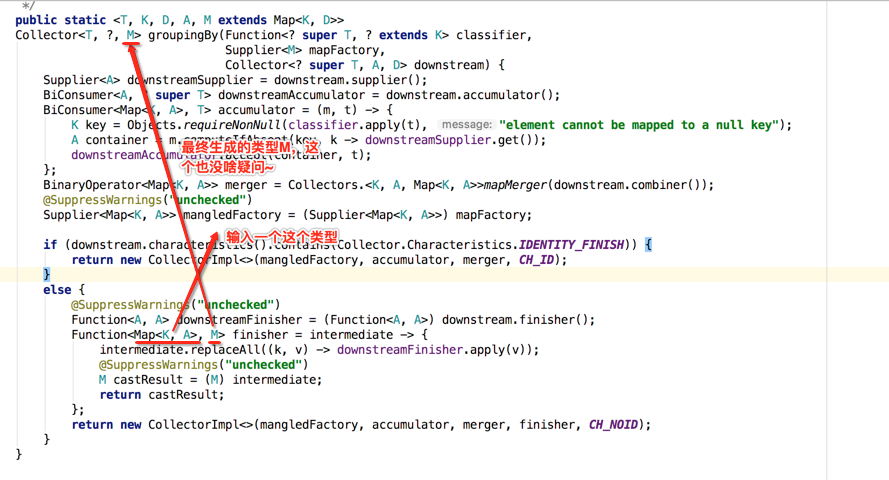
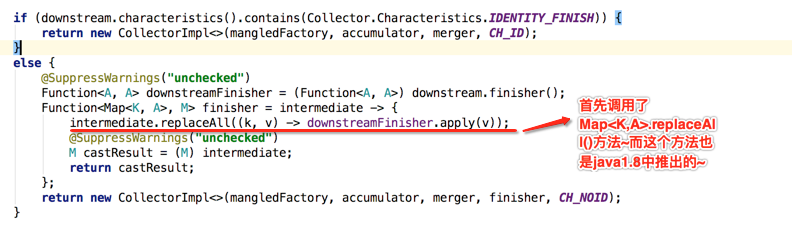
那下面来看一下这个replaceAll方法:

其中接收一个BiFunction函数式接口,先看一下该方法的javadoc描述:
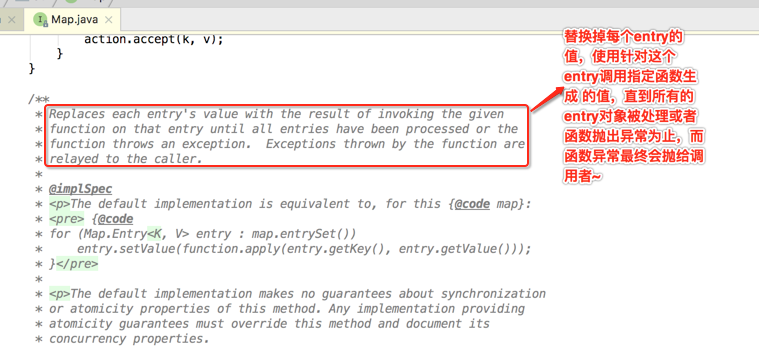
总而言之就是将map中的key对应的value值给替换掉,明白了此方法的作用之后,再回到咱们要分析的代码处:

此是intermediate对象就发生变化了,接着对它进行强制类型转换并但值返回:
至此最为复杂的groupingBy的方法就完完整整的分析完成,虽说这些实现在实际我们使用时完全不用去关心这些细节,但是!!通过分析底层的具体实现可以让我们对收集器理解得更加扎实,而且对于函数式编程也能够进一步巩固~所以说是有利无害的~
java8学习之groupingBy源码分析的更多相关文章
- java8学习之Collector源码分析与收集器核心
之前已经对流在使用上已经进行了大量应用了,也就是说对于它的应用是比较熟悉了,但是比较欠缺的是对于它底层的实现还不太了解,所以接下来准备大量通过阅读官方的javadoc反过来加深对咱们已经掌握这些知识更 ...
- java8学习之Stream源码分析
上一次已经将Collectors类中的各种系统收集器的源代码进行了完整的学习,而在之前咱们已经花了大量的篇幅对其Stream进行了详细的示例学习,如: 那接下来则通过源代码的角度来对Stream的运作 ...
- Java8集合框架——LinkedList源码分析
java.util.LinkedList 本文的主要目录结构: 一.LinkedList的特点及与ArrayList的比较 二.LinkedList的内部实现 三.LinkedList添加元素 四.L ...
- Nginx学习笔记4 源码分析
Nginx学习笔记(四) 源码分析 源码分析 在茫茫的源码中,看到了几个好像挺熟悉的名字(socket/UDP/shmem).那就来看看这个文件吧!从简单的开始~~~ src/os/unix/Ngx_ ...
- MQTT再学习 -- MQTT 客户端源码分析
MQTT 源码分析,搜索了一下发现网络上讲的很少,多是逍遥子的那几篇. 参看:逍遥子_mosquitto源码分析系列 参看:MQTT libmosquitto源码分析 参看:Mosquitto学习笔记 ...
- Redis学习——ae事件处理源码分析
0. 前言 Redis在封装事件的处理采用了Reactor模式,添加了定时事件的处理.Redis处理事件是单进程单线程的,而经典Reator模式对事件是串行处理的.即如果有一个事件阻塞过久的话会导致整 ...
- Java多线程学习之ThreadLocal源码分析
0.概述 ThreadLocal,即线程本地变量,是一个以ThreadLocal对象为键.任意对象为值的存储结构.它可以将变量绑定到特定的线程上,使每个线程都拥有改变量的一个拷贝,各线程相同变量间互不 ...
- springMVC源码学习之addFlashAttribute源码分析
本文主要从falshMap初始化,存,取,消毁来进行源码分析,springmvc版本4.3.18.关于使用及验证请参考另一篇jsp取addFlashAttribute值深入理解即springMVC发r ...
- 大数据学习--day14(String--StringBuffer--StringBuilder 源码分析、性能比较)
String--StringBuffer--StringBuilder 源码分析.性能比较 站在优秀博客的肩上看问题:https://www.cnblogs.com/dolphin0520/p/377 ...
随机推荐
- java7:(Files.walkFileTree())
1.Files.walkFileTree(): 顺序:顺序访问,碰到目录会一直递归下去 package com.test; import java.io.File; import java.io.IO ...
- Python爬虫学习==>第一章:Python3+Pip环境配置
前置操作 软件名:anaconda 版本:Anaconda3-5.0.1-Windows-x86_64清华镜像 下载链接:https://mirrors.tuna.tsinghua.edu.cn/ ...
- 【HANA系列】【第三篇】SAP HANA XS的JavaScript安全事项
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[HANA系列][第三篇]SAP HANA XS ...
- Smarty快速入门
1.Smarty是用纯php语言写的类 2.功能是实现前后端分离 3.Smarty简洁高效 4.快速入门案例 1.下载 smarty源码 https://www.smarty.net/ 2.搭建PHP ...
- 【Python开发】Python中的class继承
继承是面向对象的重要特征之一,继承是两个类或者多个类之间的父子关系,子进程继承了父进程的所有公有实例变量和方法.继承实现了代码的重用.重用已经存在的数据和行为,减少代码的重新编写,python在类名后 ...
- 数据库 ----jdbc连接池的弊端
jdbc连接池的弊端 1.数据库连接,使用时就创建,不使用立即释放,对数据库进行频繁连接开启和关闭,造成数据库资源浪费,影响 数据库性能.设想:使用数据库连接池管理数据库连接.2.将sql语句硬编码到 ...
- aws 基于延迟策略配置dns故障切换
前提:由于国内访问首尔地区经常出现不稳定情况,现将请求从nginx(sz)转发到nginx(hk)再转发到首尔地区,在基于不改变nginx(seoul)的配置的前提下,引入aws的延迟策略,同时保证国 ...
- [c++] 链表各类操作详解
链表概述 链表是一种常见的重要的数据结构.它是动态地进行存储分配的一种结构.它可以根据需要开辟内存单元.链表有一个“头指针”变量,以head表示,它存放一个地址.该地址指向一个元素.链表中每一个元素称 ...
- 小记---------spring框架之IOC理解
Spring是一个开源框架,是一个轻量级的Java开发框架. Spring的核心是控制发转(IOC)和面向切面(AOP) 控制发转(IOC):指的是 对象的创建权反转(交给)给 Spring. 作 ...
- 什么是云数据库RDS PostgreSQL 版
PostgreSQL被业界誉为“最先进的开源数据库”,面向企业复杂SQL处理的OLTP在线事务处理场景,支持NoSQL数据类型(JSON/XML/hstore).支持GIS地理信息处理. 优点 NoS ...