Python多进程、多线程和协程简介
1.进程和线程
进程是一个执行中的程序。每个进程都拥有自己的地址空间、内存、数据栈以及其他用于跟踪执行的辅助数据。在单核CPU系统中的多进程,内存中可以有许多程序,但在给定一个时刻只有一个程序在运行;就是说,可能这一秒在运行进程A,下一秒在运行进程B,虽然两者都在内存中,都没有真正同时运行。
线程从属于进程,是程序的实际执行者。一个进程至少包含一个主线程,也可以有更多的子线程。Python可以运行多线程,但和单核CPU多进程一样,在给定时刻只有一个线程会执行。
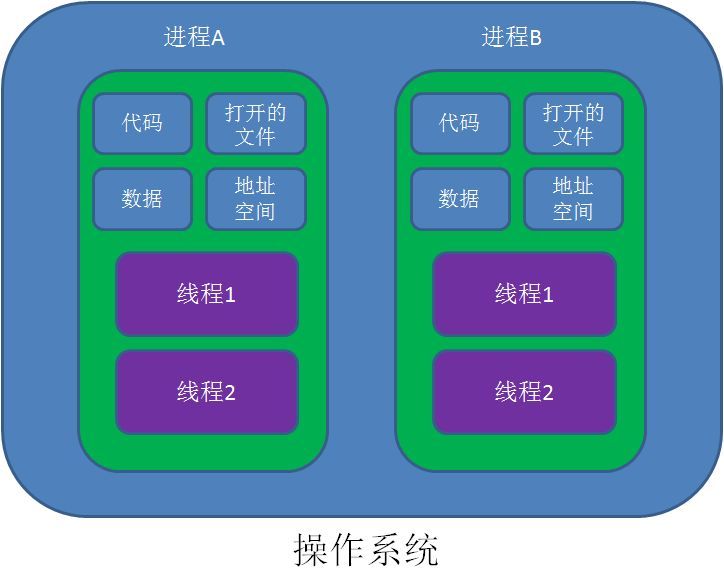
Python 提供了多个模块来支持多线程编程,包括thread、threading 和Queue 模块等。程序是可以使用thread 和threading 模块来创建与管理线程;推荐用threading模块,它更先进,有更好的线程支持。thread 模块提供了基本的线程和锁定支持,在Python3 中该模块被重命名为_thread;threading 模块提供了更高级别、功能更全面的线程管理。使用Queue 模块,用户可以创建一个队列数据结构,用于在多线程之间进行共享。
2.多进程
2.1利用Process来创建子进程
可以使用multiprocessing模块中的Process来创建子进程,该模块还有更高级的封装,例如批量启动进程的进程池(Pool)、用于进程间通信的队列(Queue)和管道(Pipe)等。
# -*- coding:utf-8 -*-
from multiprocessing import Process
from time import ctime, sleep
def loop(nloop, nsec):
print("start loop", nloop, "at:", ctime())
sleep(nsec)
print("loop", nloop, "done at:", ctime()) if __name__=="__main__":
p1 = Process(target=loop, args=(1, 4))
p2 = Process(target=loop, args=(2, 3))
p1.start()
p2.start()
p1.join()
p2.join()
print("finished")
2.1.1利用进程池
2.1.1Pool
Pool是用于批量启动进程的进程池,我们可以使用它来启动多进程
# -*- coding:utf-8 -*-
from multiprocessing import Pool
from time import ctime, sleep
def loop(nloop, nsec):
print("start loop", nloop, "at:", ctime())
sleep(nsec)
print("loop", nloop, "done at:", ctime()) if __name__=="__main__":
pool = Pool(processes=3)
for i, j in zip([1,2],[4,3]):
# 维持执行的进程总数为processes,当一个进程执行完毕后会添加新的进程进去
pool.apply_async(loop, args=(i, j))
pool.close()
# 调用join之前,先调用close函数,否则会出错。执行完close后不会有新的进程加入到pool,join函数等待所有子进程结束
pool.join()
2.1.2ProcessPoolExecutor
从Python3.2开始,标准库 concurrent.futures 模块提供了ProcessPoolExecutor (进程池)供我们使用
# -*- coding:utf-8 -*-
from concurrent.futures import ProcessPoolExecutor
from time import ctime, sleep
def loop(nloop, nsec):
print("start loop", nloop, "at:", ctime())
sleep(nsec)
print("loop", nloop, "done at:", ctime()) if __name__=="__main__":
with ProcessPoolExecutor(max_workers=3) as executor:
all_task = [executor.submit(loop, i, j) for i, j in zip([1,2],[4,3])]
3.多线程
3.1利用Thread创建子线程
# -*- coding:utf-8 -*-
import threading
from time import sleep, ctime, time def loop(nloop, nsec):
print("start loop", nloop, "at:", ctime())
sleep(nsec)
print("loop", nloop, "done at:", ctime()) def main():
threads = []
for i, j in zip([1,2],[4,3]):
t = threading.Thread(target=loop, args=(i, j))
threads.append(t)
# 线程开始执行
for t in threads:
t.start()
# 等待所有线程执行完成
for t in threads:
t.join() if __name__ == "__main__":
start = time()
main()
print("time: ", time()-start)
当所有线程都分配完成之后,通过调用每个线程的start()方法让它们开始执行,而不是在这之前就会执行。join()方法将等待线程结束,或者在提供了超时时间的情况下,达到超时时间。相比于管理一组锁(分配、获取、释放、检查锁状态等)而言,使用join()方法要比等待锁释放的无限循环更加清晰(这也是这种锁又称为自旋锁的原因)。
对于 join()方法而言,其另一个重要方面是其实它根本不需要调用。一旦线程启动,它们就会一直执行,直到给定的函数完成后退出。如果主线程还有其他事情要去做,而不是等待这些线程完成(例如其他处理或者等待新的客户端请求),就可以不调用join()。join()方法只有在你需要等待线程完成的时候才是有用的。
我们可以创建一个类继承threading.Thead,让这个类更加通用,而不只是针对loop()函数,如果我们有别的函数也可以用这个类来使用多线程。我们需要覆写Thread的__init__()和run()方法,或者调用父类的__init__()然后覆写run()方法。
Python官方文档:https://docs.python.org/3/library/threading.html#thread-objects
# -*- coding:utf-8 -*-
import threading
from time import sleep, ctime
class MyThread(threading.Thread):
def __init__(self, func, args, name=""):
threading.Thread.__init__(self)
self.name = name
self.func = func
self.args = args
def run(self):
self.func(*self.args) def loop(nloop, nsec):
print("start loop", nloop, "at:", ctime())
sleep(nsec)
print("loop", nloop, "done at:", ctime()) def main():
print("starting at:", ctime())
threads = []
for i, j in zip([1,2],[4,3]):
t = MyThread(loop, args=(i, j), name=loop.__name__)
threads.append(t) # 线程开始执行
for t in threads:
t.start() # 等待所有线程执行完成
for t in threads:
t.join() print("all DONE at:", ctime()) if __name__ == "__main__":
main()
3.2利用线程池
3.2.1ThreadPool
# -*- coding:utf-8 -*-
from multiprocessing.dummy import Pool as ThreadPool
from time import ctime, sleep
def loop(nloop, nsec):
print("start loop", nloop, "at:", ctime())
sleep(nsec)
print("loop", nloop, "done at:", ctime()) if __name__=="__main__":
pool = ThreadPool(processes=3)
for i, j in zip([1,2],[4,3]):
pool.apply_async(loop, args=(i, j))
pool.close()
pool.join()
3.2.2ThreadPoolExecutor
从Python3.2开始,标准库 concurrent.futures 模块提供了ThreadPoolExecutor (线程池)供我们使用
# -*- coding:utf-8 -*-
from concurrent.futures import ThreadPoolExecutor
from time import ctime, sleep
def loop(nloop, nsec):
print("start loop", nloop, "at:", ctime())
sleep(nsec)
print("loop", nloop, "done at:", ctime()) if __name__=="__main__":
with ThreadPoolExecutor(max_workers=3) as executor:
all_task = [executor.submit(loop, i, j) for i, j in zip([1,2],[4,3])]
4.协程
协程,英文Coroutines,是一种比线程更加轻量级的存在。正如一个进程可以拥有多个线程一样,一个线程也可以拥有多个协程。最重要的是,协程不是被操作系统内核所管理,而完全是由程序所控制(也就是在用户态执行)。
这样带来的好处就是性能得到了很大的提升,不会像线程切换那样消耗资源。
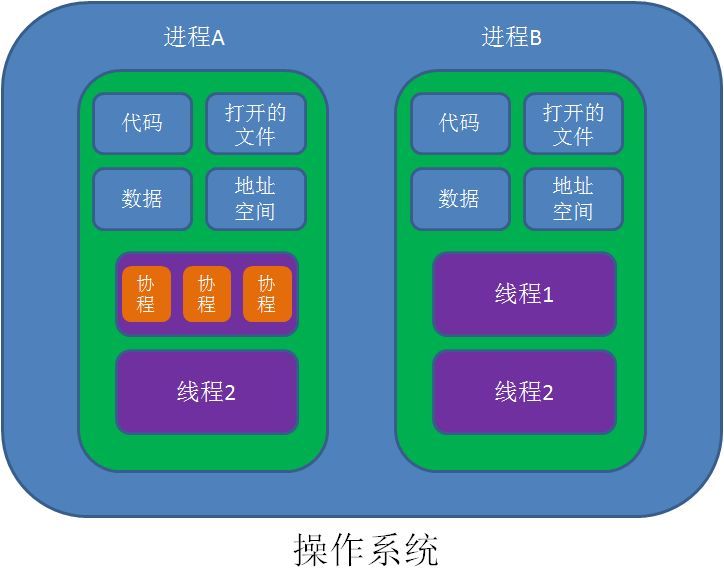
4.1引入
带有yield的函数不再是普通函数,而是生成器。send可以把一个函数的结果传给另外一个函数,以此实现单线程内程序之间的切换。
# -*- coding:utf-8 -*-
def consumer():
r = ''
while True:
n = yield r
if not n:
return
print('[CONSUMER] Consuming %s...' % n)
r = '200 OK' def produce(c):
c.send(None) # 等价于next(c)
n = 0
while n < 5:
n = n + 1
print('[PRODUCER] Producing %s...' % n)
r = c.send(n)
print('[PRODUCER] Consumer return: %s' % r)
c.close() c = consumer()
produce(c)
这里,produce先用 c.send(None) 启动生成器,consumer() 执行到 yield r 便停下来,并将r返回 给调用它的函数(比如next()或send());这时候consumer()被挂起,produce继续执行,当运行到 r=c.send(n) 时又让consumer()执行 ;此时consumer()将r赋值给n,并继续往下运行,执行print()函数,并将 '200 OK' 赋值给 r ;之后进入下一个while循环,又到了 yield r ,这时就跟前面一样了,停下了将r返回给调用它的函数,这时produce()里 r=c.send(n);不断重复上面,直到循环结束,c.close()关闭生成器。
4.2asyncio
asyncio是Python 3.4版本引入的标准库,直接内置了对异步IO的支持。
asyncio的编程模型就是一个消息循环。我们从asyncio模块中直接获取一个EventLoop的引用,然后把需要执行的协程扔到EventLoop中执行,就实现了异步IO。
# -*- coding:utf-8 -*-
import asyncio @asyncio.coroutine
def hello():
print("Hello world!")
# 异步调用asyncio.sleep(1):
r = yield from asyncio.sleep(1)
print("Hello again!") # 获取EventLoop:
loop = asyncio.get_event_loop()
# 执行coroutine
loop.run_until_complete(hello())
loop.close()
@asyncio.coroutine把一个生成器标记为coroutine类型,然后,我们就把这个coroutine扔到EventLoop中执行。
yield from语法可以让我们方便地调用另一个生成器。由于asyncio.sleep()也是一个coroutine,所以线程不会等待asyncio.sleep(),而是直接中断并执行下一个消息循环。当asyncio.sleep()返回时,线程就可以从yield from拿到返回值(此处是None),然后接着执行下一行语句。
把asyncio.sleep(1)看成是一个耗时1秒的IO操作,在此期间,主线程并未等待,而是去执行EventLoop中其他可以执行的coroutine了,因此可以实现并发执行。
我们用asyncio的异步网络连接来获取sina、sohu和163的网站首页:
import asyncio @asyncio.coroutine
def wget(host):
print('wget %s...' % host)
connect = asyncio.open_connection(host, 80)
reader, writer = yield from connect
header = 'GET / HTTP/1.0\r\nHost: %s\r\n\r\n' % host
writer.write(header.encode('utf-8'))
yield from writer.drain()
while True:
line = yield from reader.readline()
if line == b'\r\n':
break
print('%s header > %s' % (host, line.decode('utf-8').rstrip()))
# Ignore the body, close the socket
writer.close() loop = asyncio.get_event_loop()
tasks = [wget(host) for host in ['www.sina.com.cn', 'www.sohu.com', 'www.163.com']]
loop.run_until_complete(asyncio.wait(tasks))
loop.close()
4.3async/await
从Python 3.5开始引入了新的语法async和await,可以让代码更简洁易读。asyncio是用来编写并发的代码库。
# -*- coding:utf-8 -*-
import asyncio async def slow_operation(n):
await asyncio.sleep(1)
print("Slow operation {} completed".format(n)) async def main():
await asyncio.wait([
slow_operation(1),
slow_operation(2),
slow_operation(3),
]) loop = asyncio.get_event_loop()
loop.run_until_complete(main())
再看一个例子,这里的aiohttp实现了HTTP客户端和HTTP服务器的功能,对异步操作提供了非常好的支持,有兴趣可以阅读它的官方文档
import asyncio
import aiohttp async def download(url):
print('Fetch:', url)
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
print(url, '--->', resp.status)
print(url, '--->', resp.cookies)
print('\n\n', await resp.text()) def main():
loop = asyncio.get_event_loop()
urls = [
'https://www.baidu.com',
'http://www.sohu.com/',
'http://www.sina.com.cn/',
'https://www.taobao.com/',
'https://www.jd.com/'
]
tasks = [download(url) for url in urls]
loop.run_until_complete(asyncio.wait(tasks))
loop.close() if __name__ == '__main__':
main()
参考资料:
https://www.cnblogs.com/friendwrite/articles/10414273.html
https://www.jianshu.com/p/a69dec87e646
https://www.cnblogs.com/sui776265233/p/9325996.html
https://www.liaoxuefeng.com/wiki/1016959663602400/1017968846697824
《Python核心编程》
https://www.jianshu.com/p/7be32bf906fb
https://github.com/jackfrued/Python-100-Days/blob/master/Day66-75/69.%E5%B9%B6%E5%8F%91%E4%B8%8B%E8%BD%BD.md
https://docs.python.org/zh-cn/3/library/asyncio.html#module-asyncio
Python多进程、多线程和协程简介的更多相关文章
- 也说性能测试,顺便说python的多进程+多线程、协程
最近需要一个web系统进行接口性能测试,这里顺便说一下性能测试的步骤吧,大概如下 一.分析接口频率 根据系统的复杂程度,接口的数量有多有少,应该优先对那些频率高,数据库操作频繁的接口进行性能测试,所以 ...
- python基础整理5——多进程多线程和协程
进程与线程 1.进程 我们电脑的应用程序,都是进程,假设我们用的电脑是单核的,cpu同时只能执行一个进程.当程序处于I/O阻塞的时候,CPU如果和程序一起等待,那就太浪费了,cpu会去执行其他的程序, ...
- python 多进程/多线程/协程 同步异步
这篇主要是对概念的理解: 1.异步和多线程区别:二者不是一个同等关系,异步是最终目的,多线程只是我们实现异步的一种手段.异步是当一个调用请求发送给被调用者,而调用者不用等待其结果的返回而可以做其它的事 ...
- python 多进程,多线程,协程
在我们实际编码中,会遇到一些并行的任务,因为单个任务无法最大限度的使用计算机资源.使用并行任务,可以提高代码效率,最大限度的发挥计算机的性能.python实现并行任务可以有多进程,多线程,协程等方式. ...
- 深入浅析python中的多进程、多线程、协程
深入浅析python中的多进程.多线程.协程 我们都知道计算机是由硬件和软件组成的.硬件中的CPU是计算机的核心,它承担计算机的所有任务. 操作系统是运行在硬件之上的软件,是计算机的管理者,它负责资源 ...
- Cpython解释器下实现并发编程——多进程、多线程、协程、IO模型
一.背景知识 进程即正在执行的一个过程.进程是对正在运行的程序的一个抽象. 进程的概念起源于操作系统,是操作系统最核心的概念,也是操作系统提供的最古老也是最重要的抽象概念之一.操作系统的其他所有内容都 ...
- Python并发编程二(多线程、协程、IO模型)
1.python并发编程之多线程(理论) 1.1线程概念 在传统操作系统中,每个进程有一个地址空间,而且默认就有一个控制线程 线程顾名思义,就是一条流水线工作的过程(流水线的工作需要电源,电源就相当于 ...
- Python并发编程——多线程与协程
Pythpn并发编程--多线程与协程 目录 Pythpn并发编程--多线程与协程 1. 进程与线程 1.1 概念上 1.2 多进程与多线程--同时执行多个任务 2. 并发和并行 3. Python多线 ...
- python单线程,多线程和协程速度对比
在某些应用场景下,想要提高python的并发能力,可以使用多线程,或者协程.比如网络爬虫,数据库操作等一些IO密集型的操作.下面对比python单线程,多线程和协程在网络爬虫场景下的速度. 一,单线程 ...
随机推荐
- Edit the AlarmClock in AOSP with android-studio
1. git the AlarmClock source code on AOSP 2. select 'import project' by android-studio & we will ...
- JS中对象数据类型的基本结构和操作
Object类型 ECMAScript中的队形其实就是一组数据和功能的集合.对象可以通过执行new操作符后跟要创建的对象类型的名称来创建.而创建Object类型的示例并为其添加属性和(或)方法,就可以 ...
- ECMAScript严格模式
ECMAScript 第5个版本 1. 严格模式: 什么是: 比普通js运行机制,要求更严格的模式 为什么: js语言本身具有很多广受诟病的缺陷 何时: 今后所有的js程序,必须运行在严格模式下! 如 ...
- 解析天启rk3288源码 /kernel/drivers/char/virtd
virtd为编译后产生的中间文件,可使用ELF格式逆向 1.ELF文件内容解析readelf: 可解析ELF文件的所有内容;strings: 查看ELF文件中的字符串;file : 查看ELF文件 ...
- elk系统生成请求数据测试承载量、宕机瓶颈shell
elk-gen-data.sh: #!/usr/bin/bash#----------------------------------------------------# Comment: to g ...
- 无法用另一台电脑上的navicat链接主机数据库lost connection toMYSQl server at "handshake":reading inital communication packet,system error:34
同事要用navicat登陆我的数据库,主机地址和密码都没错,但是报错,lost connection toMYSQl server at "handshake":reading i ...
- procixx和最近调试的坑
流程: 1.procixx/vivado 配置soc硬件信息,导出FSBL.out: 2.配置uboot dts,生成u-boot (需要打开的硬件 配置为status = "okay&qu ...
- MFC的DoModal(转)
DoModal会产生模态对话框(有模式的对话框,有“是”或者“否”供用户选择),函数运行到此处后不会马上返回,会等待用户的响应(响应后对话框销毁),在此对话框未销毁前,其他窗口不会接收到用户的输入(注 ...
- python基础:10.多线程装饰器模式下的单例模式
with def __enter__ def __close__ 闭包: 装饰器: 闭包的延迟绑定: 单例模式的应用:
- uCOS的软件定时器、uCOS时钟节拍和滴答定时器的关系
uCOS2.81后的版本中有软件定时器的概念,如果要开启定时器任务,需要在OS_CFG.H文件中 #define OS_TMR_EN 1 软件定时器其实跟硬件中断是相 ...