Python中的Django框架中prefetch_related()函数对数据库查询的优化
实例的背景说明
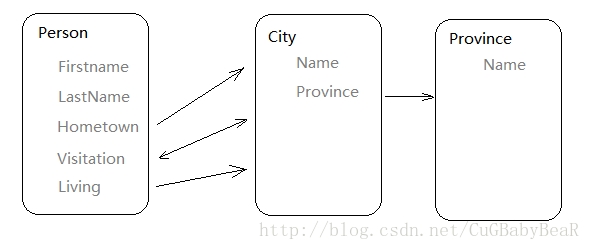
假定一个个人信息系统,需要记录系统中各个人的故乡、居住地、以及到过的城市。数据库设计如下:
Models.py 内容如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
from django.db import models class Province(models.Model): name = models.CharField(max_length=10) def __unicode__(self): return self.name class City(models.Model): name = models.CharField(max_length=5) province = models.ForeignKey(Province) def __unicode__(self): return self.name class Person(models.Model): firstname = models.CharField(max_length=10) lastname = models.CharField(max_length=10) visitation = models.ManyToManyField(City, related_name = "visitor") hometown = models.ForeignKey(City, related_name = "birth") living = models.ForeignKey(City, related_name = "citizen") def __unicode__(self): return self.firstname + self.lastname |
注1:创建的app名为“QSOptimize”
注2:为了简化起见,`qsoptimize_province` 表中只有2条数据:湖北省和广东省,`qsoptimize_city`表中只有三条数据:武汉市、十堰市和广州市
prefetch_related()
对于多对多字段(ManyToManyField)和一对多字段,可以使用prefetch_related()来进行优化。或许你会说,没有一个叫OneToManyField的东西啊。实际上 ,ForeignKey就是一个多对一的字段,而被ForeignKey关联的字段就是一对多字段了。
作用和方法
prefetch_related()和select_related()的设计目的很相似,都是为了减少SQL查询的数量,但是实现的方式不一样。后者是通过JOIN语句,在SQL查询内解决问题。但是对于多对多关系,使用SQL语句解决就显得有些不太明智,因为JOIN得到的表将会很长,会导致SQL语句运行时间的增加和内存占用的增加。若有n个对象,每个对象的多对多字段对应Mi条,就会生成Σ(n)Mi 行的结果表。
prefetch_related()的解决方法是,分别查询每个表,然后用Python处理他们之间的关系。继续以上边的例子进行说明,如果我们要获得张三所有去过的城市,使用prefetch_related()应该是这么做:
|
1
2
3
4
|
>>> zhangs = Person.objects.prefetch_related('visitation').get(firstname=u"张",lastname=u"三")>>> for city in zhangs.visitation.all() :... print city... |
上述代码触发的SQL查询如下:
|
1
2
3
4
5
6
7
8
9
10
|
SELECT `QSOptimize_person`.`id`, `QSOptimize_person`.`firstname`,`QSOptimize_person`.`lastname`, `QSOptimize_person`.`hometown_id`, `QSOptimize_person`.`living_id`FROM `QSOptimize_person`WHERE (`QSOptimize_person`.`lastname` = '三' AND `QSOptimize_person`.`firstname` = '张'); SELECT (`QSOptimize_person_visitation`.`person_id`) AS `_prefetch_related_val`, `QSOptimize_city`.`id`,`QSOptimize_city`.`name`, `QSOptimize_city`.`province_id`FROM `QSOptimize_city`INNER JOIN `QSOptimize_person_visitation` ON (`QSOptimize_city`.`id` = `QSOptimize_person_visitation`.`city_id`)WHERE `QSOptimize_person_visitation`.`person_id` IN (1); |
第一条SQL查询仅仅是获取张三的Person对象,第二条比较关键,它选取关系表`QSOptimize_person_visitation`中`person_id`为张三的行,然后和`city`表内联(INNER JOIN 也叫等值连接)得到结果表。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
+----+-----------+----------+-------------+-----------+| id | firstname | lastname | hometown_id | living_id |+----+-----------+----------+-------------+-----------+| 1 | 张 | 三 | 3 | 1 |+----+-----------+----------+-------------+-----------+1 row in set (0.00 sec) +-----------------------+----+-----------+-------------+| _prefetch_related_val | id | name | province_id |+-----------------------+----+-----------+-------------+| 1 | 1 | 武汉市 | 1 || 1 | 2 | 广州市 | 2 || 1 | 3 | 十堰市 | 1 |+-----------------------+----+-----------+-------------+3 rows in set (0.00 sec) |
显然张三武汉、广州、十堰都去过。
又或者,我们要获得湖北的所有城市名,可以这样:
|
1
2
3
4
|
>>> hb = Province.objects.prefetch_related('city_set').get(name__iexact=u"湖北省")>>> for city in hb.city_set.all():... city.name... |
触发的SQL查询:
|
1
2
3
4
5
6
7
|
SELECT `QSOptimize_province`.`id`, `QSOptimize_province`.`name`FROM `QSOptimize_province`WHERE `QSOptimize_province`.`name` LIKE '湖北省' ; SELECT `QSOptimize_city`.`id`, `QSOptimize_city`.`name`, `QSOptimize_city`.`province_id`FROM `QSOptimize_city`WHERE `QSOptimize_city`.`province_id` IN (1); |
得到的表:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
+----+-----------+| id | name |+----+-----------+| 1 | 湖北省 |+----+-----------+1 row in set (0.00 sec) +----+-----------+-------------+| id | name | province_id |+----+-----------+-------------+| 1 | 武汉市 | 1 || 3 | 十堰市 | 1 |+----+-----------+-------------+2 rows in set (0.00 sec) |
我们可以看见,prefetch使用的是 IN 语句实现的。这样,在QuerySet中的对象数量过多的时候,根据数据库特性的不同有可能造成性能问题。
使用方法
*lookups 参数
prefetch_related()在Django < 1.7 只有这一种用法。和select_related()一样,prefetch_related()也支持深度查询,例如要获得所有姓张的人去过的省:
|
1
2
3
4
5
|
>>> zhangs = Person.objects.prefetch_related('visitation__province').filter(firstname__iexact=u'张')>>> for i in zhangs:... for city in i.visitation.all():... print city.province... |
触发的SQL:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
SELECT `QSOptimize_person`.`id`, `QSOptimize_person`.`firstname`,`QSOptimize_person`.`lastname`, `QSOptimize_person`.`hometown_id`, `QSOptimize_person`.`living_id`FROM `QSOptimize_person`WHERE `QSOptimize_person`.`firstname` LIKE '张' ; SELECT (`QSOptimize_person_visitation`.`person_id`) AS `_prefetch_related_val`, `QSOptimize_city`.`id`,`QSOptimize_city`.`name`, `QSOptimize_city`.`province_id` FROM `QSOptimize_city`INNER JOIN `QSOptimize_person_visitation` ON (`QSOptimize_city`.`id` = `QSOptimize_person_visitation`.`city_id`)WHERE `QSOptimize_person_visitation`.`person_id` IN (1, 4); SELECT `QSOptimize_province`.`id`, `QSOptimize_province`.`name`FROM `QSOptimize_province`WHERE `QSOptimize_province`.`id` IN (1, 2); |
获得的结果:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
+----+-----------+----------+-------------+-----------+| id | firstname | lastname | hometown_id | living_id |+----+-----------+----------+-------------+-----------+| 1 | 张 | 三 | 3 | 1 || 4 | 张 | 六 | 2 | 2 |+----+-----------+----------+-------------+-----------+2 rows in set (0.00 sec) +-----------------------+----+-----------+-------------+| _prefetch_related_val | id | name | province_id |+-----------------------+----+-----------+-------------+| 1 | 1 | 武汉市 | 1 || 1 | 2 | 广州市 | 2 || 4 | 2 | 广州市 | 2 || 1 | 3 | 十堰市 | 1 |+-----------------------+----+-----------+-------------+4 rows in set (0.00 sec) +----+-----------+| id | name |+----+-----------+| 1 | 湖北省 || 2 | 广东省 |+----+-----------+2 rows in set (0.00 sec) |
值得一提的是,链式prefetch_related会将这些查询添加起来,就像1.7中的select_related那样。
要注意的是,在使用QuerySet的时候,一旦在链式操作中改变了数据库请求,之前用prefetch_related缓存的数据将会被忽略掉。这会导致Django重新请求数据库来获得相应的数据,从而造成性能问题。这里提到的改变数据库请求指各种filter()、exclude()等等最终会改变SQL代码的操作。而all()并不会改变最终的数据库请求,因此是不会导致重新请求数据库的。
举个例子,要获取所有人访问过的城市中带有“市”字的城市,这样做会导致大量的SQL查询:
|
1
2
|
plist = Person.objects.prefetch_related('visitation')[p.visitation.filter(name__icontains=u"市") for p in plist] |
因为数据库中有4人,导致了2+4次SQL查询:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
SELECT `QSOptimize_person`.`id`, `QSOptimize_person`.`firstname`, `QSOptimize_person`.`lastname`,`QSOptimize_person`.`hometown_id`, `QSOptimize_person`.`living_id`FROM `QSOptimize_person`; SELECT (`QSOptimize_person_visitation`.`person_id`) AS `_prefetch_related_val`, `QSOptimize_city`.`id`,`QSOptimize_city`.`name`, `QSOptimize_city`.`province_id`FROM `QSOptimize_city`INNER JOIN `QSOptimize_person_visitation` ON (`QSOptimize_city`.`id` = `QSOptimize_person_visitation`.`city_id`)WHERE `QSOptimize_person_visitation`.`person_id` IN (1, 2, 3, 4); SELECT `QSOptimize_city`.`id`, `QSOptimize_city`.`name`, `QSOptimize_city`.`province_id`FROM `QSOptimize_city`INNER JOIN `QSOptimize_person_visitation` ON (`QSOptimize_city`.`id` = `QSOptimize_person_visitation`.`city_id`)WHERE(`QSOptimize_person_visitation`.`person_id` = 1 AND `QSOptimize_city`.`name` LIKE '%市%' ); SELECT `QSOptimize_city`.`id`, `QSOptimize_city`.`name`, `QSOptimize_city`.`province_id`FROM `QSOptimize_city`INNER JOIN `QSOptimize_person_visitation` ON (`QSOptimize_city`.`id` = `QSOptimize_person_visitation`.`city_id`)WHERE (`QSOptimize_person_visitation`.`person_id` = 2 AND `QSOptimize_city`.`name` LIKE '%市%' ); SELECT `QSOptimize_city`.`id`, `QSOptimize_city`.`name`, `QSOptimize_city`.`province_id`FROM `QSOptimize_city`INNER JOIN `QSOptimize_person_visitation` ON (`QSOptimize_city`.`id` = `QSOptimize_person_visitation`.`city_id`)WHERE (`QSOptimize_person_visitation`.`person_id` = 3 AND `QSOptimize_city`.`name` LIKE '%市%' ); SELECT `QSOptimize_city`.`id`, `QSOptimize_city`.`name`, `QSOptimize_city`.`province_id`FROM `QSOptimize_city`INNER JOIN `QSOptimize_person_visitation` ON (`QSOptimize_city`.`id` = `QSOptimize_person_visitation`.`city_id`)WHERE (`QSOptimize_person_visitation`.`person_id` = 4 AND `QSOptimize_city`.`name` LIKE '%市%' ); |
详细分析一下这些请求事件。
众所周知,QuerySet是lazy的,要用的时候才会去访问数据库。运行到第二行Python代码时,for循环将plist看做iterator,这会触发数据库查询。最初的两次SQL查询就是prefetch_related导致的。
虽然已经查询结果中包含所有所需的city的信息,但因为在循环体中对Person.visitation进行了filter操作,这显然改变了数据库请求。因此这些操作会忽略掉之前缓存到的数据,重新进行SQL查询。
但是如果有这样的需求了应该怎么办呢?在Django >= 1.7,可以通过下一节的Prefetch对象来实现,如果你的环境是Django < 1.7,可以在Python中完成这部分操作。
|
1
2
|
plist = Person.objects.prefetch_related('visitation')[[city for city in p.visitation.all() if u"市" in city.name] for p in plist] |
Prefetch 对象
在Django >= 1.7,可以用Prefetch对象来控制prefetch_related函数的行为。
注:由于我没有安装1.7版本的Django环境,本节内容是参考Django文档写的,没有进行实际的测试。
Prefetch对象的特征:
- 一个Prefetch对象只能指定一项prefetch操作。
- Prefetch对象对字段指定的方式和prefetch_related中的参数相同,都是通过双下划线连接的字段名完成的。
- 可以通过 queryset 参数手动指定prefetch使用的QuerySet。
- 可以通过 to_attr 参数指定prefetch到的属性名。
- Prefetch对象和字符串形式指定的lookups参数可以混用。
继续上面的例子,获取所有人访问过的城市中带有“武”字和“州”的城市:
|
1
2
3
4
5
6
7
|
wus = City.objects.filter(name__icontains = u"武")zhous = City.objects.filter(name__icontains = u"州")plist = Person.objects.prefetch_related( Prefetch('visitation', queryset = wus, to_attr = "wu_city"), Prefetch('visitation', queryset = zhous, to_attr = "zhou_city"),)[p.wu_city for p in plist][p.zhou_city for p in plist] |
注:这段代码没有在实际环境中测试过,若有不正确的地方请指正。
顺带一提,Prefetch对象和字符串参数可以混用。
None
可以通过传入一个None来清空之前的prefetch_related。就像这样:
|
1
|
>>> prefetch_cleared_qset = qset.prefetch_related(None) |
小结
- prefetch_related主要针一对多和多对多关系进行优化。
- prefetch_related通过分别获取各个表的内容,然后用Python处理他们之间的关系来进行优化。
- 可以通过可变长参数指定需要select_related的字段名。指定方式和特征与select_related是相同的。
- 在Django >= 1.7可以通过Prefetch对象来实现复杂查询,但低版本的Django好像只能自己实现。
- 作为prefetch_related的参数,Prefetch对象和字符串可以混用。
- prefetch_related的链式调用会将对应的prefetch添加进去,而非替换,似乎没有基于不同版本上区别。
- 可以通过传入None来清空之前的prefetch_related。
您可能感兴趣的文章:
Python中的Django框架中prefetch_related()函数对数据库查询的优化的更多相关文章
- Django框架详细介绍---ORM相关操作---select_related和prefetch_related函数对 QuerySet 查询的优化
Django的 select_related 和 prefetch_related 函数对 QuerySet 查询的优化 引言 在数据库存在外键的其情况下,使用select_related()和pre ...
- 这个贴子的内容值得好好学习--实例详解Django的 select_related 和 prefetch_related 函数对 QuerySet 查询的优化
感觉要DJANGO用得好,ORM必须要学好,不管理是内置的,还是第三方的ORM. 最最后还是要到SQL.....:( 这一关,慢慢练啦.. 实例详解Django的 select_related 和 p ...
- Django的 select_related 和 prefetch_related 函数对 QuerySet 查询的优化(二)
3. prefetch_related() 对于多对多字段(ManyToManyField)和一对多字段,可以使用prefetch_related()来进行优化.或许你会说,没有一个叫OneToMan ...
- 实例具体解释Django的 select_related 和 prefetch_related 函数对 QuerySet 查询的优化(二)
这是本系列的第二篇,内容是 prefetch_related() 函数的用途.实现途径.以及用法. 本系列的第一篇在这里 第三篇在这里 3. prefetch_related() 对于多对多字段(Ma ...
- Django的 select_related 和 prefetch_related 函数对 QuerySet 查询的优化
引言 在数据库存在外键的其情况下,使用select_related()和prefetch_related()很大程度上减少对数据库的请求次数以提高性能 1.实例准备 模型: from django.d ...
- 转 实例具体解释DJANGO的 SELECT_RELATED 和 PREFETCH_RELATED 函数对 QUERYSET 查询的优化(二)
https://blog.csdn.net/cugbabybear/article/details/38342793 这是本系列的第二篇,内容是 prefetch_related() 函数的用途.实现 ...
- Django的 select_related 和 prefetch_related 函数对 QuerySet 查询的优化(三)
4.一些实例 如果我们想要获得所有家乡是湖北的人,最无脑的做法是先获得湖北省,再获得湖北的所有城市,最后获得故乡是这个城市的人.就像这样: 1 2 3 4 5 >>> hb = Pr ...
- 转载 :实例详解Django的 select_related 和 prefetch_related 函数对 QuerySet 查询的优化(一)
在数据库有外键的时候,使用 select_related() 和 prefetch_related() 可以很好的减少数据库请求的次数,从而提高性能.本文通过一个简单的例子详解这两个函数的作用.虽然Q ...
- 转 实例详解Django的 select_related 和 prefetch_related 函数对 QuerySet 查询的优化(三)
这是本系列的最后一篇,主要是select_related() 和 prefetch_related() 的最佳实践. 第一篇在这里 讲例子和select_related() 第二篇在这里 讲prefe ...
随机推荐
- linux c 链接详解3-静态库
3静态库 摘自:Linux C编程一站式学习 透过本节可以学会编译静态链接库的shell脚本! 有时候需要把一组代码编译成一个库,这个库在很多项目中都要用到,例如libc就是这样一个库,我们在不同的程 ...
- 01.LNMP架构-Nginx源码包编译部署详细步骤
操作系统:CentOS_Server_7.5_x64_1804.iso 部署组件:Pcre+Zlib+Openssl+Nginx 操作步骤: 一.创建目录 [root@localhost ~]# mk ...
- 利用cmd运行java程序
在运行以下程序时,要确保正确配置java的环境变量!!! 此处仅仅使用“记事本”来写java程序!!! 1. 新建一个记事本文件,命名为HelloWorld.java 这里需要注意的是,要确保关闭了隐 ...
- exe 错误
1,NTVDM 是从 WINDOWS NT 架构开始引入的一个子系统进程,目的是虚拟一个DOS环境来运行以前的DOS 16bit 程序.2,只有当启动16位DOS程序时,才会启用 NTVDM 这个进程 ...
- zlib的压缩与解压
http://zlibnet.codeplex.com/releases/view/629717 using ZLibNet; string str = "ccc"; byte [ ...
- P1903 奖学金题解
众所周知,这是一道通过struct结构体进行排序的题目 思路:平常的输入.. 然后定义一个结构体grade,存放每个学生的学号.三科成绩.(也可以只存语文成绩和总分和学号) 自定义cmp函数,通过三层 ...
- Luogu P3170 [CQOI2015]标识设计 状态压缩,轮廓线,插头DP,动态规划
看到题目显然是插头\(dp\),但是\(n\)和\(m\)的范围似乎不是很小.我们先不考虑复杂度设一下状态试试: 一共有三个连通分量,我们按照\(1,2,3\)的顺序来表示一下.轮廓线上\(0\)代表 ...
- SSM三大框架详细整合流程
1.基本概念 1.1.Spring Spring是一个开源框架,Spring是于2003 年兴起的一个轻量级的Java 开发框架,由Rod Johnson 在其著作Expert One-On-One ...
- 系统命令模块subprocess
系统命令 可以执行shell命令的相关模块和函数有: os.system os.spawn* os.popen* --废弃 popen2.* --废弃 commands.* --废弃,3.x中被移除 ...
- VMware安装Ghost版Win10 失败的解决方法
第一个失败点,是分区之后,重启,提示alt+ctrl+del要求重启,然后就是无限提示,解决方案:在重启读条的时候,按Esc,或者F2调整系统启动优先级读取位置,设置为CD的那个,就可以进入到安装系统 ...